本文主要是介绍使用小皮【phpstudy】运行Vue+MySql项目,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现在的情况是我扒到了一个开源的项目,现在想要实现一下前端对应的功能,后端是完备的,但是需要调用数据库将数据跑起来,这里可以使用到MySql数据库,这里我还发现了一个比较好用的软件小皮【phpStudy】
官网
一 安装软件
到对应的官网进行安装
二 安装之后的操作
①进入页面之后打开MySQL 数据库
这里需要注意如果电脑安装了MySQL数据库可以直接使用MySql,并且电脑之前安装的MySql会和小皮冲突导致不能运行
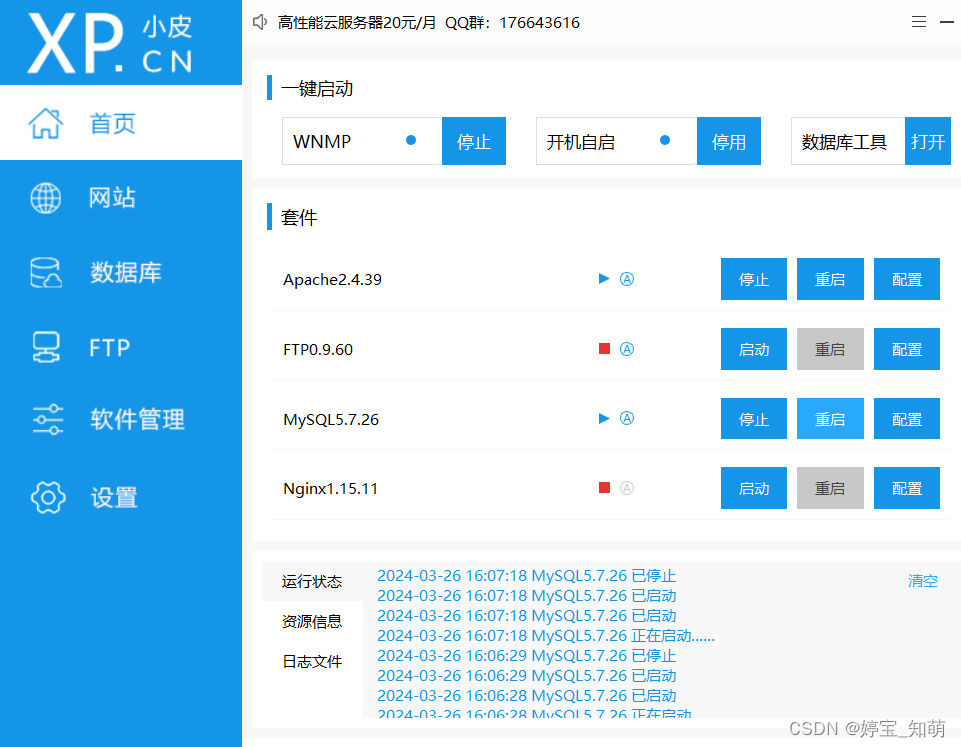
②这里是服务器默认的数据库名称和密码可以进行修改,但是修改密码之后需要
到vue_api_server 里面的config文件里面修改登录密码为你x修改之后的密码
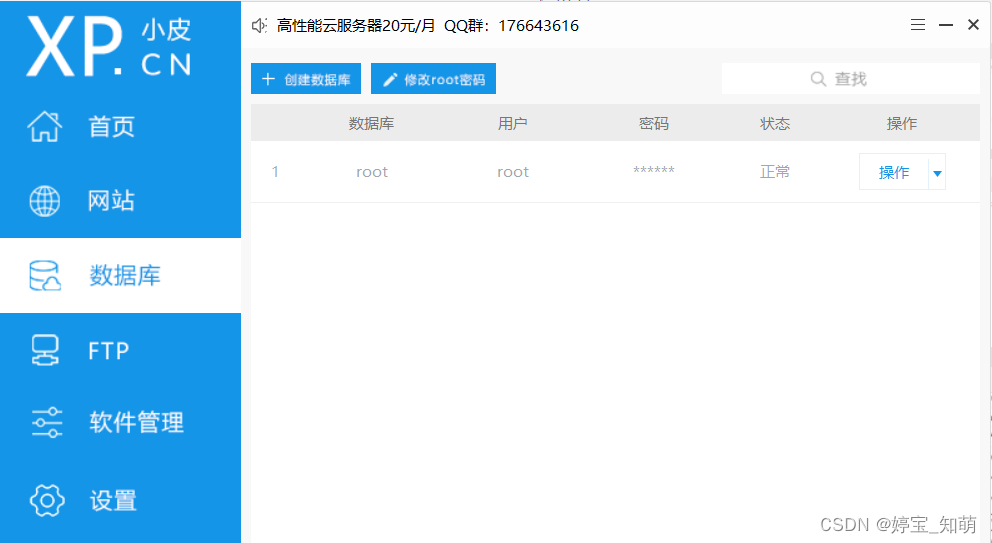
③ 点击管理之后进入在线的phpMyAdmin 网站,输入账号名和密码

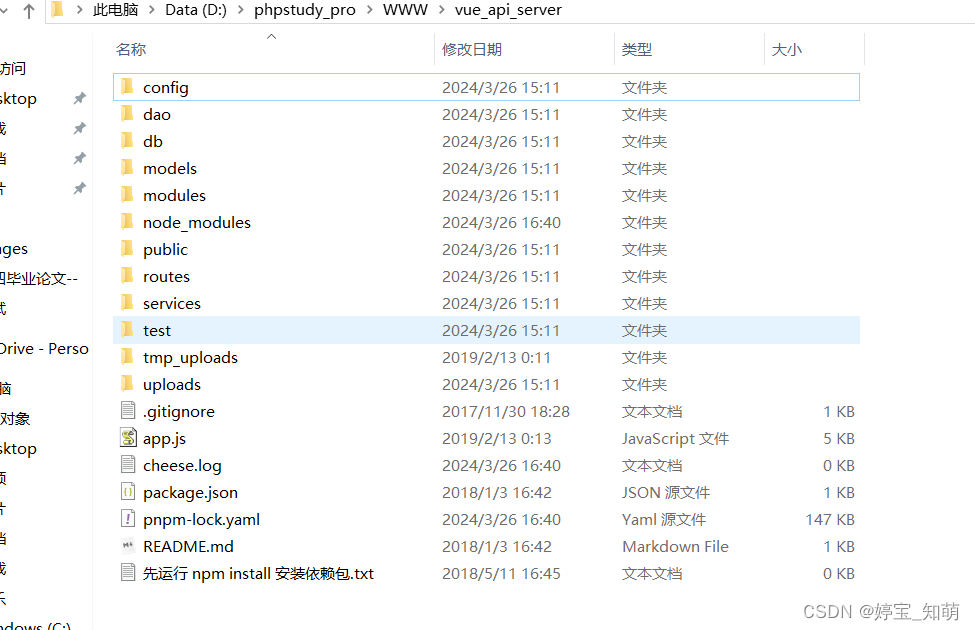
④ 在小皮的文件夹目录下的WWW文件夹,要把需要运行的源码放到这个目录下
⑤ 将Sql文件导入到数据库当中
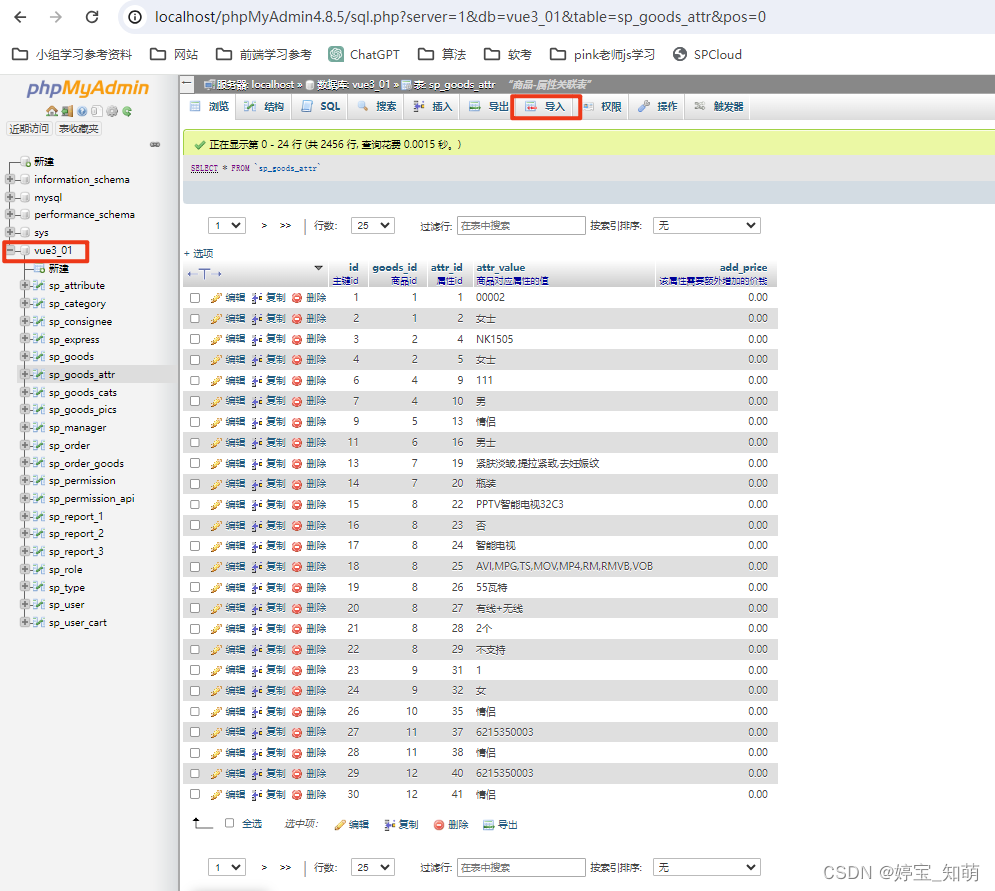
导入的数据是mydb.sql
⑥ 之后在
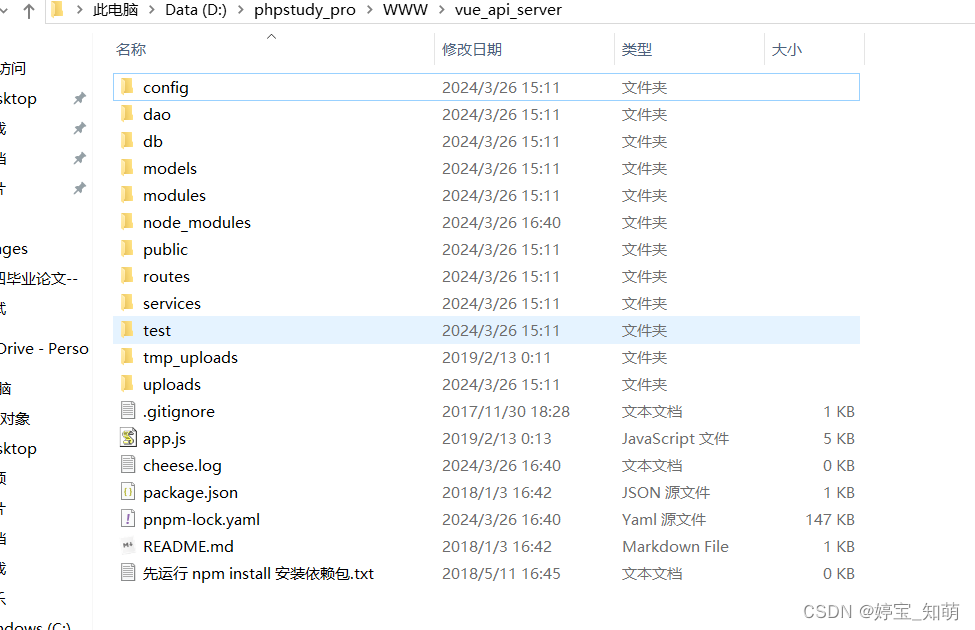
中打开黑窗口或者在VScode中打开,运行 npm install 命令
并且根据
中的运行命令运行 npm run start 命令就能够成功运行项目拿到接口了
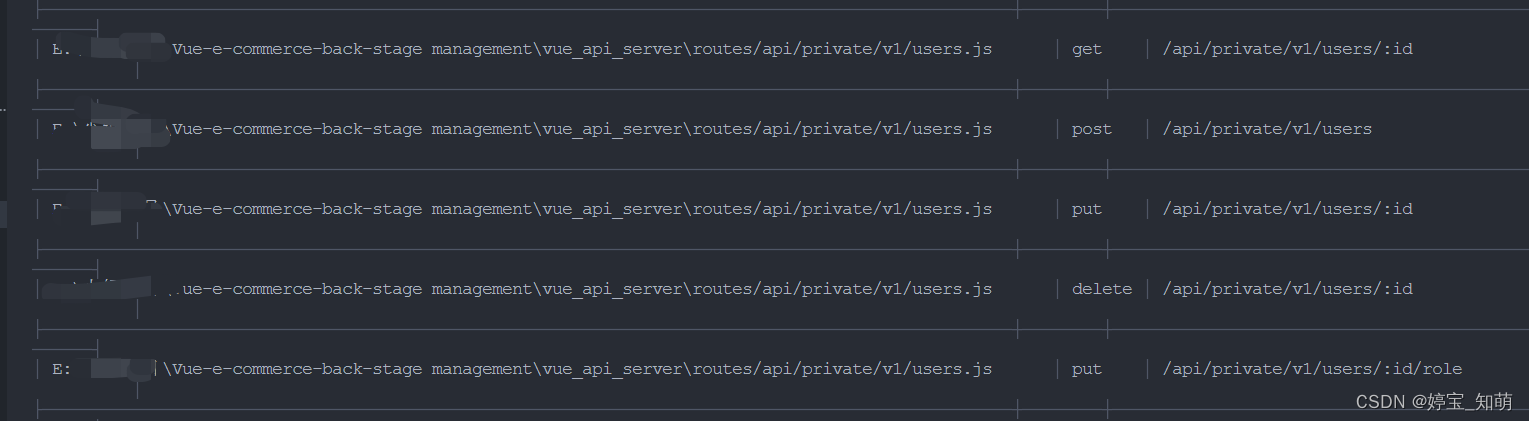
这就是启动成功之后获取到的内容,并且可以在postMan中执行相应的代码
这样就成功启动了服务器,前端也可以调用接口获取数据了!!
参考:
参考1
参考2
参考3
这篇关于使用小皮【phpstudy】运行Vue+MySql项目的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




