本文主要是介绍记一次Docker/Kubernetes上无法解释的连接超时原因探寻之旅,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

摘要

这个资源竞争问题在Linux内核代码中有提及,但是没有太多相关的文档。虽然Linux内核已经支持设置一个flag来规避这个问题,但直到最近iptables的masquerade规则才支持。
同样的资源竞争情况也存在于DNAT(目的地址转换)。在Kubernetes中,这意味着访问ClusterIP时可能会丢包。当你从Pod发送一个请求到ClusterIP,kube-proxy(通过iptables)默认将ClsuterIP替换成你要访问的Service的某个Pod IP。DNS是Kubernetes最常见的Service之一,这个资源竞争问题可能使DNS解析域名时产生间歇性的延时,参见Kubernetes社区Issue 56903。
这篇文章尝试解释是我们怎样研究这个问题的,在容器网络的场景下解释这个资源竞争包含什么问题以及我们怎样规避它。
我们搭建的平台依赖于运行在Ubuntu Xenial虚机上的Kubernetes 1.8,其中使用的Docker版本为17.06,并以host-gateway模式运行Flannel 1.9.0。
迁移过程中我们注意到,应用在Kubernetes运行之后,连接超时有增加。在我们把第一个基于Scala的应用迁移上来后,这个现象变得更加明显。几乎每一秒都有一个请求的响应变得非常慢,而不是通常的几百微秒。这是个普通的RESTful应用,查询平台上的其它服务,收集、处理数据,然后返回数据到客户端,并没有什么不寻常之处。
响应慢的请求的响应时间很奇怪。几乎全部都被延迟了整整1秒或者3秒!我们决定是时候研究这个问题了。
缩小问题的范围
下一步首先理解那些超时真正意味着什么。负责这个Scala应用的团队做了些改动使得响应慢的请求在后台继续发送,并且记录它抛出超时错误给客户端之后的持续时间。我们在这个应用运行的Kubernetes节点上做了些网络追踪,并尝试将响应慢的请求和网络转储的内容进行匹配。
 Fig.1 容器的视角,10.244.38.20尝试连接10.16.46.24的80端口
Fig.1 容器的视角,10.244.38.20尝试连接10.16.46.24的80端口 结果表明超时是用来初始化连接的第一个网络包(包带有SYN标记)的重传输导致的。这很好解释了响应慢的请求的持续时间,因为这种类型的包的重传输的延时,第二次尝试是1秒之后,第三次是3秒,然后6秒,12秒,24秒等等。
这是一个有趣的发现,因为只丢失SYN标记的包排除了是随机的网络故障的原因,说明更可能是某个网络设备或者SYN洪泛保护算法主动丢弃新连接。
按默认方式安装Docker后,每一个容器在虚拟网络接口(veth)的IP连接到Docker主机上的一个Linux网桥(例如:cni0,docker0),主接口(例如eth0)同样也连接着这个网桥。容器之间通过这个网桥互相通信。如果一个容器尝试访问Docker主机外部的地址,这个包经过这个网桥,通过eth0路由到服务器外部。
以下的例子改编自一个默认的Docker配置来匹配网络捕获结果中的网络设置:
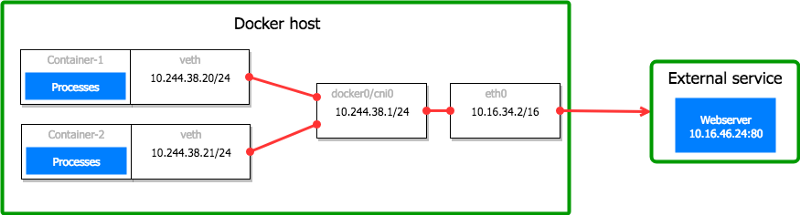 Fig.2 现实中veth接口以对的形式出现,但在我们的场景中这关系不大
Fig.2 现实中veth接口以对的形式出现,但在我们的场景中这关系不大 我们已经随机选择查看在这个网桥上的包,接下来继续查看虚机的主网络接口eth0。然后根据结果集中看网络基础设施或者虚机。
 Fig.3 从veth0,cni0和eth0捕获的结果,10.244.38.20尝试连接10.16.46.24的80端口
Fig.3 从veth0,cni0和eth0捕获的结果,10.244.38.20尝试连接10.16.46.24的80端口 网络的捕获结果显示第一个SYN包在时刻13:42:23.828339从容器网络接口(veth)离开,经过网桥(cni0)(在13:42:23.828339的重复的行)。经过1秒在时刻13:42:24.826211,源容器没有从10.16.46.24得到响应,便重传输这个包。重复地,这个包会先出现在容器的网络接口,然后是网桥。在下一行,我们可以看到这个包在时刻13:42:24.826263,IP地址和端口从10.244.38.20:38050转换成10.16.34.2:10011之后,离开eth0。下面的几行抓包显示了远端的服务是怎样响应的。
这个地址转换意味着什么将会在这篇文章的后面部分详细解释。因为我们没看到在13:42:23时刻的第一次尝试连接的SYN包离开eth0,此时可以认为该包已经在cni0和eth0之间的某个地方丢失。那些包就这样丢失相当让人惊讶,因为虚机的负载和请求速率都低。我们重复进行了多次测试,但得到的结果都一样。
Netfilter和SNAT
容器IP和数据中心的网络结构
按默认方式安装Docker后,容器有自己的IP,并且如果在同一个Docker主机网络,能够使用它们的IP互相通信。然而,从主机外部你无法通过容器的IP来访问它。外部的机器要想与容器通信,你通常需要在主机网络接口暴露容器的端口,然后使用主机IP来访问。这是因为容器IP没有到外部的路由,但主机IP有。网络基础设施不清楚每一个Docker主机网络内部的IP,因此位于不同主机网络的容器之间的通信是不可能的(Swarm或者其他网络后端的情况可能不一样)。
通过host-gateway模式的Flannel和一些其它的Kubernetes网络插件,Pod能够访问在同一个集群的其它主机上的Pod。你可以从一个pod访问另一个pod,无论它运行在哪个节点,但是不能从集群外的虚机访问Pod。可以使用Calico等来实现这个,但使用以host-gw模式运行的Flannel无法实现。
SNAT
如果从外部主机无法直接访问容器,容器也就不可能和外部服务通信。如果一个容器请求外部的服务,由于容器IP是不可路由的,远程服务器不知道应该把响应发到哪里。但事实上只要每个主机对容器到外部的连接做一次SNAT就能实现。
我们的Docker主机能够和数据中心的其它机器通信,它们有可路由的IP。当一个容器尝试访问一个外部服务时,运行容器的主机将网络包中的容器IP用用它本身的IP替换。对于外部服务,看起来像是和主机建立了连接。当响应返回到主机的时候,它进行一个逆转换(把网络包中的主机IP替换成容器IP)。对于容器,这个操作完全是透明的,它不知道发生了这样的一个转换。
例如:一个Docker主机10.0.0.1上运行着一个名为container-1的容器,它的IP为172.16.1.8。容器内部的进程初始化一个访问10.0.0.99:80的连接。它绑定本地容器端口32000。
这个包离开容器到达Docker主机,源地址为172.16.1.8:32000。
Docker主机将源地址由172.16.1.8:32000替换为10.0.0.1:32000,并把包转发给10.0.0.99:80。Linux用一个表格追踪转换过程,以便在包的响应中能够进行逆向转换。
远程服务10.0.0.99:80处理这个请求并返回响应给主机。
响应返回到主机的32000端口。Linux看到这是一个已经转换的连接的响应,便把目的地址从10.0.0.1:32000修改为172.16.1.8:32000,把包转发给容器。
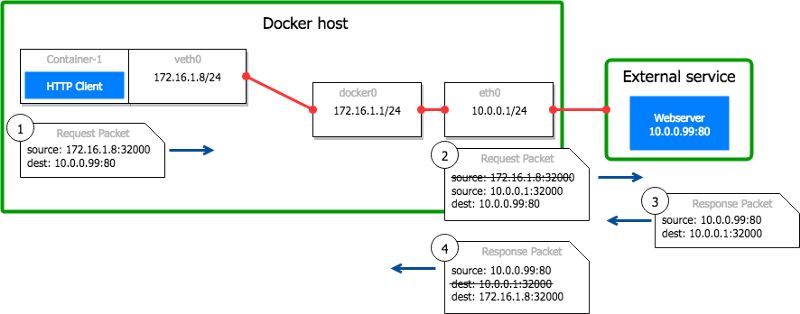 Fig.4 容器访问外部服务示意图
Fig.4 容器访问外部服务示意图 iptables和netfilter
Linux的netfilter框架能够在内核网络栈的不同地方进行许多的网络操作,例如:包过滤等操作。但对我们来说更感兴趣的是IP地址和端口的转换。Iptables是一个可以让我们用命令行来配置netfilter的工具。默认的Docker安装会添加一些iptables规则,来对向外的连接做SNAT。在我们的Kubernetes集群,Flannel做同样的事(实际上,它们都配置iptables来做masqurade(地址伪装,SNAT的一种))。
 Fig.5 从容器(在这个例子中是172.17.0.0/16)发出的包到除网桥(docker0)之外的地方都会进行masqurade
Fig.5 从容器(在这个例子中是172.17.0.0/16)发出的包到除网桥(docker0)之外的地方都会进行masqurade 当一个从容器到外部服务的连接发出后,因为Docker/Flannel添加的iptables规则它会被netfilter处理。netfilter的NAT模块进行SNAT的操作,它将向外传输的包中的源地址替换主机IP,并且在内核中添加一个条目来记录这个转换。这个条目确保同一个连接后续的包会用同样的方式修改以保持一致性。它也确保外部服务的响应到达主机的时候,内核知道如何相应地修改包地址。
这些条目存储在内核的conntrack表(conntrack是netfilter的另一个模块)中。你可以通过命令sudo conntrack -L来查看这个表的内容。
 Fig.6 主机10.0.0.1上从容器172.16.1.8:32000到10.0.0.99:80的连接
Fig.6 主机10.0.0.1上从容器172.16.1.8:32000到10.0.0.99:80的连接 端口转换
服务器能够使用三元组{IP, 端口, 协议}来与其他主机通信,而且一次只能使用一个三元组。如果你的SNAT池只有一个IP,并且使用HTTP(底层TCP协议)连接到同一个远程服务,这意味着两个向外的连接允许变化的只有源端口。
如果一个端口被已经建立的连接占用,另一个容器尝试使用相同的本地端口访问同一个服务,netfilter不仅要改变该容器的源IP,还包括源端口。
两个并发的连接的例子:Docker主机10.0.0.1上运行着另外一个名为container-2的容器,其IP是172.16.1.9。
container-1 以IP 172.16.1.8,使用本地端口32000,尝试建立到 10.0.0.99:80的连接。
container-2 以IP 172.16.1.9,使用本地端口32000,尝试建立到 10.0.0.99:80的连接。
来自container-1的包到达主机,源IP为172.16.1.8:32000。在表中没有10.0.0.1:32000的条目,所以端口32000可以被保留。主机将源IP从172.16.1.8:32000替换为10.0.0.1:32000。它在conntrack表格中增加了一个条目,来记录从172.16.1.8:32000到10.0.0.99:80的TCP连接,源地址被转换成了10.0.0.1:32000。
来自container-2的包到达主机,源IP为172.16.1.9:32000。由于10.0.0.1:32000已经被用来与10.0.0.99:80的TCP通信,主机使用第一个可用的端口(1024),把源IP从172.16.1.8:32000替换为10.0.0.1:1024。在conntrack表格中增加了一个条目,来记录从172.16.1.9:32000到10.0.0.99:80的TCP连接,源地址被转换成了10.0.0.1:1024。
远程服务响应来自10.0.0.1:32000和10.0.0.1:1024的连接。
Docker主机接收到端口32000的响应,将目标地址改为172.16.1.8:32000。
Docker主机接收到端口1024的响应,将目标地址改为172.16.1.9:32000。
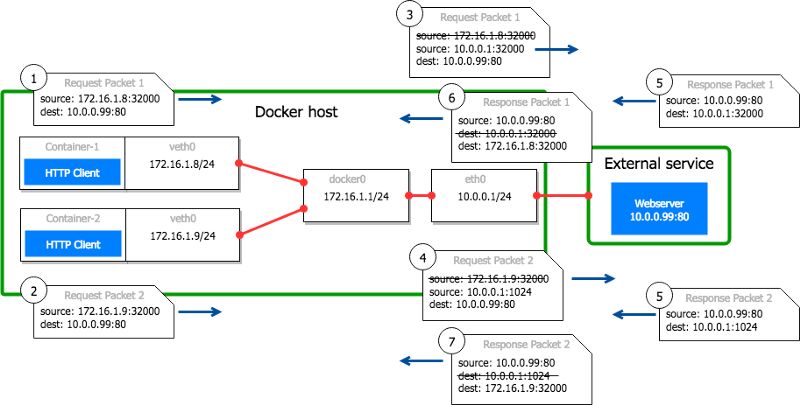 Fig.7 两个并发连接的端口转换示意图
Fig.7 两个并发连接的端口转换示意图  Fig.8 conntrack表的大概情况
Fig.8 conntrack表的大概情况 注意:当一个主机有多个IP可以用来SNAT操作时,这些IP可视为SNAT池的一部分。这不是我们这个例子的情况。
返回原来的问题
我们必须更加深入看下conntrack!
我们想到的第二个事情是端口复用。如果端口资源耗尽,没有可用的端口来做SNAT 操作,包很可能被丢弃或者被拒绝。我们决定研究下conntrack表。这没带来太大的帮助,因为这个表格并未被充分使用。但是我们发现conntrack软件包有一个命令来显示一些统计信息(conntrack -S)。有一个字段立刻引起我们的注意,当运行那个命令时“insert_field”的值是一个非零值。
我们再一次运行测试程序,同时密切关注那个字段值的变化。发现这个值的增加与丢失的包数量相同。
帮助页面关于那个字段的描述很清楚,但不是很有帮助:“尝试插入表但失败的条目数(在相同的条目已经存在的情况下)。”
在哪种情形下插入表会失败?在一个低负载的服务器上包被丢弃听起来不像是一个正常行为。
从netfilter的用户邮件列表中获取帮助的尝试无功而返后,我们决定自己弄清这个问题。
Netfilter NAT以及Conntrack内核模块
NAT代码在POSTROUTING链上被调用两次。首先是通过修改源地址和/或端口来修改包的结构,然后如果包在这这个过程中间没有丢失的话,内核在conntrack表中记录这个转换。这意味着在SNAT端口分配和插入conntrack表之间有一个时延,如果有冲突的话可能最终导致插入失败以及丢包。这正是我们所看到的。
当在TCP连接上做SNAT的时候,NAT模块会做以下尝试:
如果包的源地址是在目标NAT池中,且{IP, 端口,协议}三元组是可用的,返回(包没有改变)。
找到池中最少使用的IP,用之来替换包中的源IP。
检查端口是否在允许的范围(默认1024-64512),并且带这个端口的三元组是否可用。如果可用则返回(源IP已经改变,端口未改变)。(注意:SNAT的端口范围不受内核参数net.ipv4.ip_local_port_range的影响。)
端口不可用,内核通过通过调用 nf_nat_l4proto_unique_tuple()请求TCP层找到一个未使用的端口来做SNAT。
默认的端口分配做以下的事:
从一个初始位置开始搜索并复制最近一次分配的端口。
递增1。
调用nf_nat_used_tuple()检查端口是否已被使用。如果已被使用,重复上一步。
用刚分配的端口更新最近一次分配的端口并返回。
netfilter也支持两种其它的算法来找到可用的端口:
使用部分随机来选择端口搜索的初始位置。当SNAT规则带有flag NF_NAT_RANGE_PROTO_RANDOM时这种模式被使用。
完全随机来选择端口搜索的初始位置。带有 flag NF_NAT_RANGE_PROTO_RANDOM_FULLY时使用。
NF_NAT_RANGE_PROTO_RANDOM降低了两个线程以同一个初始端口开始搜索的次数,但是仍然有很多的错误。只有使用NF_NAT_RANGE_PROTO_RANDOM_FULLY才能显著减少conntrack表插入错误的次数。在一台Docker测试虚机,使用默认的masquerade规则,10到80个线程并发请求连接同一个主机有2%-4%的插入错误。
当在内核强制使用完全随机时,错误降到了0(后来在真真实的集群中也接近0)。
Kubernetes激活完全随机的端口选择
我们现在使用一个修改后的打了这个补丁的flannel版本,在masquerade规则中增加了flag --ramdom-fully。我们使用一个简单的Daemonset从每一个节点上获取conntrack的统计结并发送到InfluxDB来监控conntrack表的插入错误。我们已经使用这补丁将近一个月了,整个集群中的错误的数目从每几秒一次下降到每几个小时一次。
尽管Kubernetes被大量地使用,但是我们非常惊讶于这个资源竞争问题却没有充分地被讨论。我们的多数应用连接到相同的服务后端的事实使得这个问题变得更加明显。
可以采取一些其它的措施来缓解这一问题,例如:为这些服务配置DNS轮询,或者多增加一些IP到主机的NAT池。
在接下来的几个月里,我们将研究一个service mesh怎样才能不发送如此多的流量到中心服务后端。我们很可能会研究下Kubernetes网络的可路由Pod IP能否完全摆脱SNAT,这也能帮助我们在Kubernetes上大量部署Akka和Elixir集群。
原文链接:https://tech.xing.com/a-reason-for-unexplained-connection-timeouts-on-kubernetes-docker-abd041cf7e02
本文转载自公众号:容器魔方, 点击查看原文。


这篇关于记一次Docker/Kubernetes上无法解释的连接超时原因探寻之旅的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





