本文主要是介绍容器存储的今生来世,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
宽为限 紧用功 功夫到 滞塞通
容器生态现状
容器生态,对比2015年之前已经有重大变化,2015-2016年间,互联网、新兴企业都在将其Workload向容器环境迁。容器已不仅仅是两年前的部署工具,更是一种成熟的技术和平台,已经普遍的应用在公有云的运营和运维侧、PaaS的虚拟化主流技术中。伴随而来的容器持久化问题也必然会成为容器管理的核心之一。
近两年,特别是2016年容器持久化生态有很快的发展,例如EMC、NetAPP、Huawei的企业存储厂商积极拥抱容器生态,纷纷推出其Docker Volume-plugin实现,特别像EMC更是打造其开源社区EMC Code,并在今年5、6月陆续发布其容器管控面生态Polly和Libstorage,意图将其企业存储更好地融入Docker生态。新兴存储厂商更是抓住容器可能颠覆云基础设施的机会推出针对容器定制的存储,继2015年的Portworx,2016年CoreOS、StorageOS也纷纷发布其容器存储产品.
面对容器持久化生态,应该如何分类,未来趋势如何,我们不妨梳理并大胆预测下:
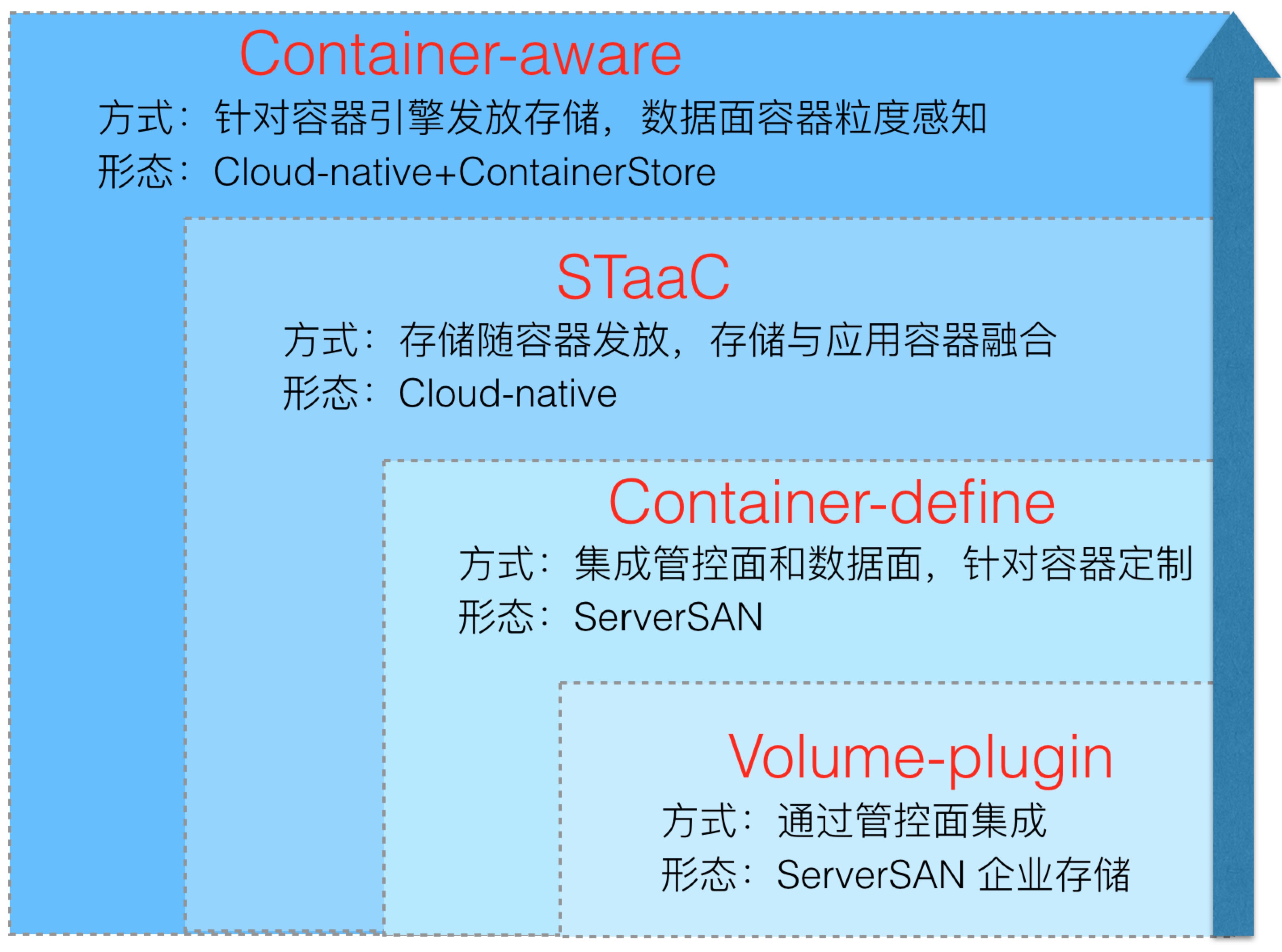
形态1: Data-volume + Volume-plugin
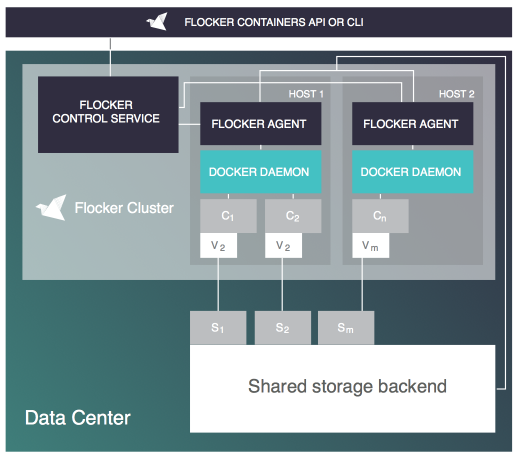
最原始的方式不一定是最有效的,Docker发布之初便考虑到数据持久化问题,提供了Data-volume的支持,但最初的数据卷只是本地卷,不支持外置存储,直到1.8版本才提供了数据卷插件。原因可能是Docker最早的定位只是Stateless,但后来发现本地无法满足有状态服务的需求,又或者是Docker考虑过于超前,认为Cloud-native的应用应该向无状态存储API迁移,数据卷不应该作为主存储吧。总之卷插件来的很晚,但这并不妨碍存储厂商趋之若鹜,大量的卷插件雨后春笋,2016年上半年统计就有40余个,如ClusterHQ的Flocker、Rancher的Convoy、EMC的REX-Ray,以及华为的Fuxi等等。
卷插件最大的问题在于,它只是Docker公司解决持久化的简单方案,卷插件仅提供几个简单的卷管理接口(当然你可以扩展,但那不是标准),让存储管控面对接,但并未在数据面上做任何优化。当然这解决了有无问题,传统存储可以通过卷插件给容器发放数据卷了,但问题还在后面,存储发放的效率、如何适配Cloud-native的高弹性要求,如何在数据提供主机高密度的容器存储发放,以及更高的并发性能,这些问题还是原地踏步。
— 典型卷插件实现-Flocker:
形态2: Container-define
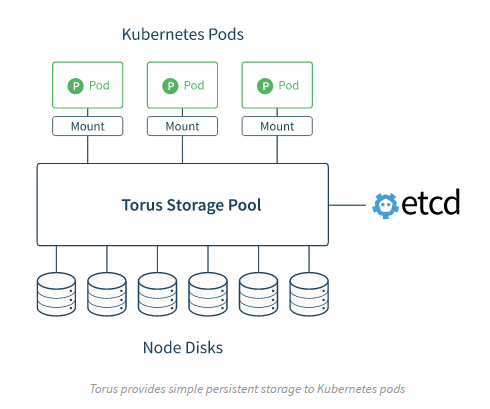
显然有些容器生态的厂商意识到了卷插件的局限,便有了后面的第二阶段,不能仅依靠Docker的Volume-plugin,还需要结合存储数据面的能力,针对容器的特征定制管控面和数据面特性,或者充分发挥企业存储的高级特性,都是打破卷插件束缚的思路。这里面我们看到有CoreOS,基于ServerSAN和容器生态的kv-store etcd打造的容器定义存储torus,相比单纯的控制面,torus能够更好的与k8s调度集成,并且具有更快的发放和伸缩能力。 容器定义存储最大的特点在于融合了控制面和数据面能力,并且结合容器特点定制,相对单纯控制面更具优势,产品形态以ServerSAN为主。不足在于存储本身不是cloud-native的,与容器本身还是在两个层面,仍需要解决两层间的调度联动,适配cloud-native的能力。
— 典型容器定义存储-torus:
形态3:STaaC
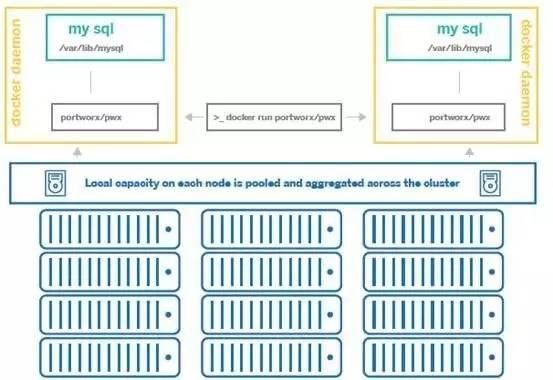
STaaC(Storage as a Container),存储即容器。应该是目前最贴合容器的存储了,集数据面、控制面与一身,更重要的是存储自身也是容器化的,可以随应用容器一起发布,这也天然的解决了Cloud-native应用业务变化不可预期,弹性要求高的问题,相比容器定义存储更具优势。一些典型的STaaC如:Portworx、StorageOS、BlockBridge等。特点是控制面+数据面,并且自身是Cloud-native形态。缺点可以认为暂无,但下个形态中我们会看到还有优化的空间。
— 典型STaaC-Portworx:
形态4: Container-aware
之前的3个形态,虽然都有不同程度的演进,但没有本质的改变,即仍是以传统的存储形态给容器使用:将卷、文件挂载到容器宿主机,再通过Docker引擎将挂载目录映射给容器数据卷,对于具有高密部署、微服务架构的Cloud-native应用来说,单主机会挂载非常多的容器,更重要的是宿主机的卷会变得越来越难于管理,数据卷的放速度也很难保证,要知道容器毫秒级的启动速度可能因为存储的发放而变成秒或数十秒,那么应用如果是几百或上千个容器的启动那问题是不能容忍的,便会丧失容器相对虚拟化敏捷的优势。
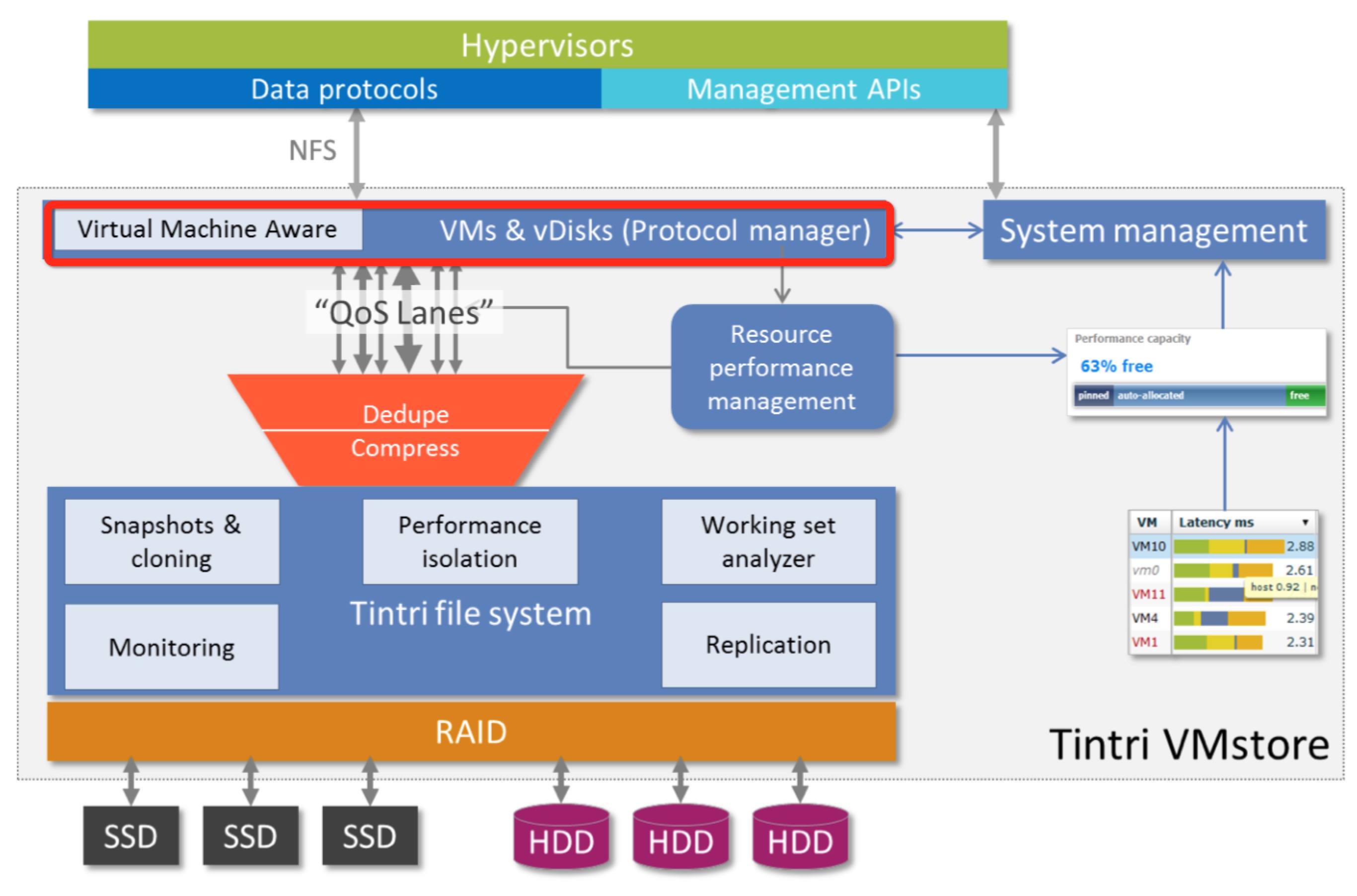
Container-aware应该是什么?除了应该具备前3种形态的特点之外,应该还具备感知容器的能力,容器粒度的能力,而不是将这部分能力卸载到主机侧,可以参考虚拟化存储的例子:Tintri。Tintri定位于虚拟化感知,不同于传统虚拟化存储大LUN,小LUN的方式,Tintri直接将整个存储集群定义为一个VMstore,并且映射给vmware的一个Datastore,后面在这个Datastore创建的虚拟机不需要在关注卷,Tintri摒弃了卷的概念,而是通过自身数据面去感知VM,并实现了VM-Level的管理、分析、保护和迁移能力,这才是真正面向一种虚拟化技术的存储最佳方式。容器生态也是同理的,若能实现面向容器引擎甚至Pod集群的ContainerStore,而不是在Container这一级,将大大减少容器存储的粒度,并实现数据面的容器感知能力,基于感知容器数据卷实现Container-level的管理、分析、保护、迁移,才是容器存储的最佳形态。 Container-aware兼具之前3种形态的特点,管控面+数据面,形态上兼具Cloud-native+ContainerStore。
— Tintri的VM-aware参考:
4个形态的演进总结:
尽头?
IT云技术瞬息万变,伴随着IoT、AI、VR\AR这些新兴应用的未来我们不得而知,或许未来的应用存储都像无状态转型,S3、MQ、NoSQL、EventHub,这些将成为主存储也未尝不可,存储则只是一个数据总线或共享数据池,非结构化数据完全替代结构化数据,那时候可能不再需要不需要容器存储了。
-
站在巨人的肩膀上
本文转载的网络地址
http://mervinsun.github.io/2016/11/26/container-storage-trend/
这篇关于容器存储的今生来世的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




