本文主要是介绍论文阅读:UniFormer和UniFormerV2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- UNIFormer
- 动机
- 方法
- 动态位置嵌入(DPE)
- 多头关系聚合器(MHRA)
- 模型代码
- 总结
- UniFormerV2
- 动机
- 方法
- 整体框架
- 实现细节
- 总结
UNIFormer
本文主要介绍了UniFormer: Unified Transformer for Efficient Spatial-Temporal Representation Learning
代码:https://github.com/Sense-X/UniFormer/tree/main/video_classification
动机
由于视频具有大量的局部冗余和复杂的全局依赖关系,因此从视频中学习丰富的、多尺度的时空语义是一项具有挑战性的任务。
最近的研究主要是由三维卷积神经网络和Vision Transformer驱动的。虽然三维卷积可以有效地聚集局部上下文来抑制来自小三维邻域的局部冗余,但由于感受域有限,它缺乏捕获全局依赖的能力。另外,vision Transformer通过自注意机制可以有效地捕获长时间依赖,但由于各层tokens之间存在盲目的相似性比较,限制了减少局部冗余。

视频transformer对浅层的局部特征编码比较低效,在时空上都只能学习到临近的信息
方法
提出了一种新型的统一Transformer(UniFormer),它以一种简洁的形式,将三维卷积和时空自注意的优点集成在一起,并在计算和精度之间取得了较好的平衡。与传统的Transformer不同的是,关系聚合器通过在浅层和深层中分别局部和全局tokens相关性来处理时空冗余和依赖关系。

由上图可知,UniFormer模型其中的特色组件是:动态位置嵌入(DPE)、多头关系聚合器(MHRA)和前馈网络(FFN)

动态位置嵌入(DPE)
之前的方法主要采用图像任务的绝对或相对位置嵌入。然而,当测试较长的输入帧时,绝对位置嵌入应该通过微调插值到目标输入大小。相对位置嵌入由于缺乏绝对位置信息而修改了自注意,表现较差。为了克服上述问题,扩展了条件位置编码(CPE)来设计DPE。

其中DWConv表示简单的三维深度卷积与零填充。由于卷积的共享参数和局部性,DPE可以克服置换不变性,并且对任意输入长度都很友好。此外,在CPE中已经证明,零填充可以帮助边界上的token意识到自己的绝对位置,因此所有token都可以通过查询其邻居来逐步编码自己的绝对时空位置信息
class SpeicalPatchEmbed(nn.Module):""" Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):super().__init__()img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])self.img_size = img_sizeself.patch_size = patch_sizeself.num_patches = num_patchesself.norm = nn.LayerNorm(embed_dim)self.proj = conv_3xnxn(in_chans, embed_dim, kernel_size=patch_size[0], stride=patch_size[0])def forward(self, x):B, C, T, H, W = x.shape# FIXME look at relaxing size constraints# assert H == self.img_size[0] and W == self.img_size[1], \# f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."x = self.proj(x)B, C, T, H, W = x.shapex = x.flatten(2).transpose(1, 2 #B*(THW)*Cx = self.norm(x)x = x.reshape(B, T, H, W, -1).permute(0, 4, 1, 2, 3).contiguous()return x
多头关系聚合器(MHRA)
设计了一种替代的关系聚合器(RA),它可以将三维卷积和时空自注意灵活地统一在一个简洁的Transformer中,分别解决了浅层和深层的视频冗余和依赖问题。具体来说,MHRA通过多头融合进行tokens关系学习:

- 输入张量为 X ∈ R C × T × H × W , r e s h a p e 为 X ∈ R L × C X \in \mathbb{R}^{C \times T \times H \times W} , reshape为 \mathbf{X} \in \mathbb{R}^{L \times C} X∈RC×T×H×W,reshape为X∈RL×C , L = T × H × W L=T \times H \times W L=T×H×W。
- 通过线性转换,可以将 X \mathbf{X} X 转换为上下文信息 V n ( X ) ∈ R L × C N , n \mathrm{V}_{n}(\mathbf{X}) \in \mathbb{R}^{L \times \frac{C}{N}} , \mathrm{n} Vn(X)∈RL×NC,n 表示第几个head。
- 然后关系聚合器 RA通过token affinity A n ∈ R L × L \mathrm{A}_{n} \in \mathbb{R}^{L \times L} An∈RL×L 来融合上下文信息得到 R n ( X ) ∈ R L × C N \mathbf{R}_{n}(\mathbf{X}) \in \mathbb{R}^{L \times \frac{C}{N}} Rn(X)∈RL×NC。
- 最后concat所有的head信息,并通过 U ∈ C L × C \mathbf{U} \in \mathbb{C}^{L \times C} U∈CL×C聚合所有head的信息。
根据上下文的域大小,可以将MHRA分为 local MHRA 和global MHRA
在网络浅层中,目标是学习小三维时空中局部时空背景下的详细视频表示:值仅依赖于token之间的相对3D位置

class CBlock(nn.Module):def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.pos_embed = conv_3x3x3(dim, dim, groups=dim)self.norm1 = bn_3d(dim)self.conv1 = conv_1x1x1(dim, dim, 1)self.conv2 = conv_1x1x1(dim, dim, 1)self.attn = conv_5x5x5(dim, dim, groups=dim)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = bn_3d(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def forward(self, x):x = x + self.pos_embed(x)x = x + self.drop_path(self.conv2(self.attn(self.conv1(self.norm1(x)))))x = x + self.drop_path(self.mlp(self.norm2(x)))return x
在网络深层中,关注于在全局视频帧中捕获长远token依赖关系:通过比较全局视图中所有token的内容相似性

class SABlock(nn.Module):def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.pos_embed = conv_3x3x3(dim, dim, groups=dim)self.norm1 = norm_layer(dim)self.attn = Attention(dim,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop=attn_drop, proj_drop=drop)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def forward(self, x):x = x + self.pos_embed(x)B, C, T, H, W = x.shapex = x.flatten(2).transpose(1, 2)x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))x = x.transpose(1, 2).reshape(B, C, T, H, W)return x
模型代码
class Uniformer(nn.Module):"""Vision Transformer一个PyTorch实现:`一个图像值16x16词:大规模图像识别的Transformer` - https://arxiv.org/abs/2010.11929"""def __init__(self, cfg):super().__init__()# 从配置中提取各种参数depth = cfg.UNIFORMER.DEPTH # 模型深度num_classes = cfg.MODEL.NUM_CLASSES # 类别数量img_size = cfg.DATA.TRAIN_CROP_SIZE # 图像尺寸in_chans = cfg.DATA.INPUT_CHANNEL_NUM[0] # 输入通道数embed_dim = cfg.UNIFORMER.EMBED_DIM # 嵌入维度head_dim = cfg.UNIFORMER.HEAD_DIM # 头部维度mlp_ratio = cfg.UNIFORMER.MLP_RATIO # MLP比例qkv_bias = cfg.UNIFORMER.QKV_BIAS # QKV偏置qk_scale = cfg.UNIFORMER.QKV_SCALE # QKV缩放representation_size = cfg.UNIFORMER.REPRESENTATION_SIZE # 表示维度drop_rate = cfg.UNIFORMER.DROPOUT_RATE # Dropout率attn_drop_rate = cfg.UNIFORMER.ATTENTION_DROPOUT_RATE # 注意力Dropout率drop_path_rate = cfg.UNIFORMER.DROP_DEPTH_RATE # 随机深度衰减率split = cfg.UNIFORMER.SPLIT # 是否分裂std = cfg.UNIFORMER.STD # 是否标准化self.use_checkpoint = cfg.MODEL.USE_CHECKPOINT # 使用检查点self.checkpoint_num = cfg.MODEL.CHECKPOINT_NUM # 检查点数量logger.info(f'Use checkpoint: {self.use_checkpoint}') # 日志:使用检查点logger.info(f'Checkpoint number: {self.checkpoint_num}') # 日志:检查点数量self.num_classes = num_classesself.num_features = self.embed_dim = embed_dim # 为了与其他模型保持一致,设置特征数量和嵌入维度norm_layer = partial(nn.LayerNorm, eps=1e-6) # 层标准化函数# 创建不同尺寸的Patch嵌入层self.patch_embed1 = SpeicalPatchEmbed(img_size=img_size, patch_size=4, in_chans=in_chans, embed_dim=embed_dim[0]) # Patch嵌入层1self.patch_embed2 = PatchEmbed(img_size=img_size // 4, patch_size=2, in_chans=embed_dim[0], embed_dim=embed_dim[1], std=std) # Patch嵌入层2self.patch_embed3 = PatchEmbed(img_size=img_size // 8, patch_size=2, in_chans=embed_dim[1], embed_dim=embed_dim[2], std=std) # Patch嵌入层3self.patch_embed4 = PatchEmbed(img_size=img_size // 16, patch_size=2, in_chans=embed_dim[2], embed_dim=embed_dim[3], std=std) # Patch嵌入层4self.pos_drop = nn.Dropout(p=drop_rate) # 位置Dropout层dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depth))] # 随机深度衰减规则num_heads = [dim // head_dim for dim in embed_dim] # 头部数量# 创建Transformer块并组成模型的不同部分self.blocks1 = nn.ModuleList([CBlock(dim=embed_dim[0], num_heads=num_heads[0], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer) for i in range(depth[0])]) # 第一个部分的Transformer块self.blocks2 = nn.ModuleList([CBlock(dim=embed_dim[1], num_heads=num_heads[1], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]], norm_layer=norm_layer) for i in range(depth[1])]) # 第二个部分的Transformer块if split:self.blocks3 = nn.ModuleList([SplitSABlock(dim=embed_dim[2], num_heads=num_heads[2], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]], norm_layer=norm_layer)for i in range(depth[2])]) # 如果拆分,创建第三个部分的Split Self-Attention块self.blocks4 = nn.ModuleList([SplitSABlock(dim=embed_dim[3], num_heads=num_heads[3], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]+depth[2]], norm_layer=norm_layer)for i in range(depth[3])]) # 如果拆分,创建第四个部分的Split Self-Attention块else:self.blocks3 = nn.ModuleList([SABlock(dim=embed_dim[2], num_heads=num_heads[2], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]], norm_layer=norm_layer)for i in range(depth[2])]) # 创建第三个部分的Self-Attention块self.blocks4 = nn.ModuleList([SABlock(dim=embed_dim[3], num_heads=num_heads[3], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]+depth[2]], norm_layer=norm_layer)for i in range(depth[3])]) # 创建第四个部分的Self-Attention块self.norm = bn_3d(embed_dim[-1]) # 3D批标准化层# 表示层if representation_size:self.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([('fc', nn.Linear(embed_dim, representation_size)), # 全连接层('act', nn.Tanh()) # Tanh激活函数]))else:self.pre_logits = nn.Identity() # 如果没有设置表示维度,则为恒等映射# 分类器头部self.head = nn.Linear(embed_dim[-1], num_classes) if num_classes > 0 else nn.Identity() # 分类器线性层或恒等映射self.apply(self._init_weights) # 初始化权重# 初始化某些参数的权重for name, p in self.named_parameters():if 't_attn.qkv.weight' in name:nn.init.constant_(p, 0) # 初始化t_attn.qkv.weight为常数0if 't_attn.qkv.bias' in name:nn.init.constant_(p, 0) # 初始化t_attn.qkv.bias为常数0if 't_attn.proj.weight' in name:nn.init.constant_(p, 1) # 初始化t_attn.proj.weight为常数1if 't_attn.proj.bias' in name:nn.init.constant_(p, 0) # 初始化t_attn.proj.bias为常数0def _init_weights(self, m):"""初始化权重函数"""if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02) # 使用截断正态分布初始化权重if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0) # 初始化偏置为常数0elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0) # 初始化偏置为常数0nn.init.constant_(m.weight, 1.0) # 初始化权重为常数1.0@torch.jit.ignoredef no_weight_decay(self):"""指定不进行权重衰减的参数"""return {'pos_embed', 'cls_token'}def get_classifier(self):"""获取分类器头部"""return self.headdef reset_classifier(self, num_classes, global_pool=''):"""重置分类器Args:num_classes (int): 新的类别数量global_pool (str): 全局池化方式"""self.num_classes = num_classesself.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity() # 重新设置分类器头部def inflate_weight(self, weight_2d, time_dim, center=False):"""权重膨胀Args:weight_2d: 二维权重张量time_dim: 时间维度center (bool): 是否中心化Returns:Tensor: 膨胀后的三维权重张量"""if center:weight_3d = torch.zeros(*weight_2d.shape)weight_3d = weight_3d.unsqueeze(2).repeat(1, 1, time_dim, 1, 1)middle_idx = time_dim // 2weight_3d[:, :, middle_idx, :, :] = weight_2delse:weight_3d = weight_2d.unsqueeze(2).repeat(1, 1, time_dim, 1, 1)weight_3d = weight_3d / time_dimreturn weight_3ddef get_pretrained_model(self, cfg):"""获取预训练模型Args:cfg: 配置文件Returns:dict: 预训练模型参数字典"""if cfg.UNIFORMER.PRETRAIN_NAME:checkpoint = torch.load(model_path[cfg.UNIFORMER.PRETRAIN_NAME], map_location='cpu')if 'model' in checkpoint:checkpoint = checkpoint['model']elif 'model_state' in checkpoint:checkpoint = checkpoint['model_state']state_dict_3d = self.state_dict()for k in checkpoint.keys():if checkpoint[k].shape != state_dict_3d[k].shape:if len(state_dict_3d[k].shape) <= 2:logger.info(f'Ignore: {k}') # 忽略不匹配的参数continuelogger.info(f'Inflate: {k}, {checkpoint[k].shape} => {state_dict_3d[k].shape}') # 膨胀参数形状time_dim = state_dict_3d[k].shape[2]checkpoint[k] = self.inflate_weight(checkpoint[k], time_dim)if self.num_classes != checkpoint['head.weight'].shape[0]:del checkpoint['head.weight'] del checkpoint['head.bias'] return checkpointelse:return Nonedef forward_features(self, x):"""前向传播特征提取Args:x (tensor): 输入张量Returns:tensor: 特征提取结果"""x = self.patch_embed1(x)x = self.pos_drop(x)for i, blk in enumerate(self.blocks1):if self.use_checkpoint and i < self.checkpoint_num[0]:x = checkpoint.checkpoint(blk, x)else:x = blk(x)x = self.patch_embed2(x)for i, blk in enumerate(self.blocks2):if self.use_checkpoint and i < self.checkpoint_num[1]:x = checkpoint.checkpoint(blk, x)else:x = blk(x)x = self.patch_embed3(x)for i, blk in enumerate(self.blocks3):if self.use_checkpoint and i < self.checkpoint_num[2]:x = checkpoint.checkpoint(blk, x)else:x = blk(x)x = self.patch_embed4(x)for i, blk in enumerate(self.blocks4):if self.use_checkpoint and i < self.checkpoint_num[3]:x = checkpoint.checkpoint(blk, x)else:x = blk(x)x = self.norm(x)x = self.pre_logits(x)return xdef forward(self, x):"""前向传播Args:x (tensor): 输入张量Returns:tensor: 输出结果"""x = x[0]x = self.forward_features(x)x = x.flatten(2).mean(-1)x = self.head(x)return x
总结
原文提出了一种新的UniFormer,它可以有效地统一3D卷积和时空自注意力在一个简洁的Transformer格式,以克服视频冗余和依赖。我们在浅层采用局部MHRA,大大减少了计算负担,在深层采用全局MHRA,学习全局令牌关系。大量的实验表明,我们的UniFormer在流行的视频基准测试Kinetics-400/600和Something-Something V1/V2上实现了准确性和效率之间的较好平衡。
UniFormerV2
论文:https://arxiv.org/abs/2211.09552
代码:https://github.com/OpenGVLab/UniFormerV2
动机
由于UniFormer是全新的框架,每次调整结构,我们都需要先经过一轮ImageNet图像预训练,之后将模型展开后,在Kinetics等视频数据集进行二次微调。根据结果反馈,再进行结构的改进。尽管这能更仔细地设计对视频任务友好的高效框架,在相同FLOPs的确远超同期基于ViT的一些列工作。(如TimeSformer、ViViT和Mformer),但二次训练的代价高昂。
时间来到2022年,更多样预训练的ViT模型开源,如有监督的Deit III、对比学习的CLIP和DINO,以及掩码学习的MAE和BeiT,规模也日益增长。我们可以充分利用上这些开源的预训练图像大模型,设计轻量的时序建模模块,以较小的训练代价迁移到视频任务中!
UniFormerV2也便是在这种想法下产生,我们沿用了UniFormerV1中的结构设计思想,设计了高效的局部与全局时空学习模块,可无缝插入到强预训练的图像ViT中,实现强大的视频建模。
方法
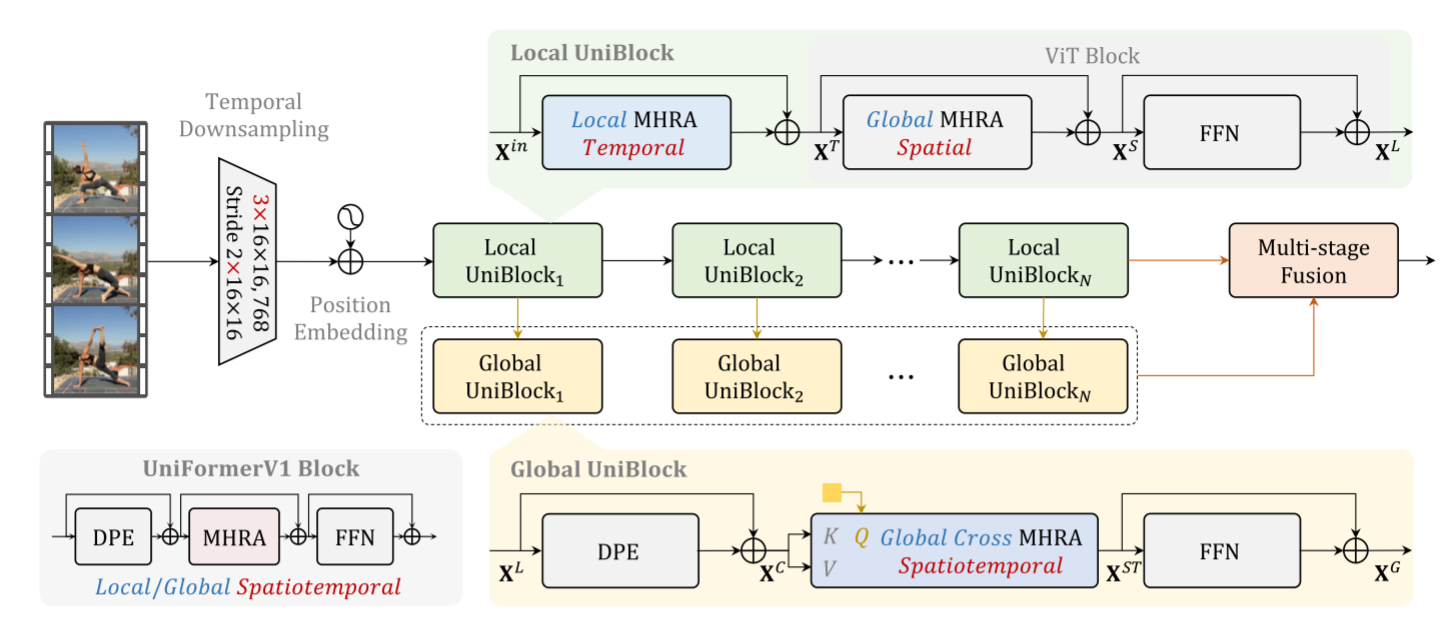
整体框架
模型的整体框架如上图所示,主要包含四个主要改进:
- Temporal Downsampling: 在Patch Embedding层进行时序下采样,该操作将Patch Embedding拓展为3D卷积,在时序上下采样,变相在相同计算量的前提下,可输入两倍的帧数,可明显提升模型对强时序相关行为的判别能力。
- Local UniBlock: 在保留原始ViT对空间的全局建模的前提下,我们额外引入局部时间建模,该模块遵循UniFormer局部模块的设计,但depth-wise卷积仅在时间维度操作。在较小计算量的前提下提升骨架网络的时序建模能力。
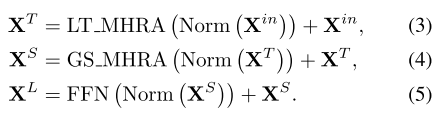

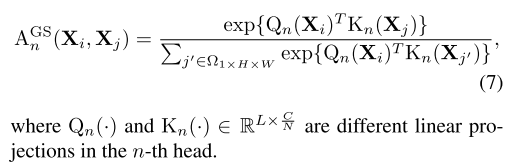
class Local_MHRA(nn.Module):def __init__(self, d_model, dw_reduction=1.5, pos_kernel_size=3):super().__init__() padding = pos_kernel_size // 2re_d_model = int(d_model // dw_reduction)self.pos_embed = nn.Sequential(nn.BatchNorm3d(d_model),nn.Conv3d(d_model, re_d_model, kernel_size=1, stride=1, padding=0),nn.Conv3d(re_d_model, re_d_model, kernel_size=(pos_kernel_size, 1, 1), stride=(1, 1, 1), padding=(padding, 0, 0), groups=re_d_model),nn.Conv3d(re_d_model, d_model, kernel_size=1, stride=1, padding=0),)# init zerologger.info('Init zero for Conv in pos_emb')nn.init.constant_(self.pos_embed[3].weight, 0)nn.init.constant_(self.pos_embed[3].bias, 0)def forward(self, x):return self.pos_embed(x)
- Global UniBlock: 对于视频任务而言,对全局时空token学习long-term dependencies尤其关键,为压缩全局模块的计算量,我们引入交叉注意力,使用单个可学的token作为query,不同层的输出token作为keys和values,设计。并且我们引入UniFormer中的DPE,增强token的时空位置信息。这样,每个全局模块会将对应层的时空信息压缩成单个informative token。
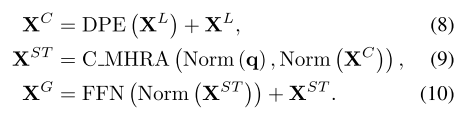
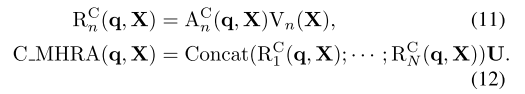 ``
``
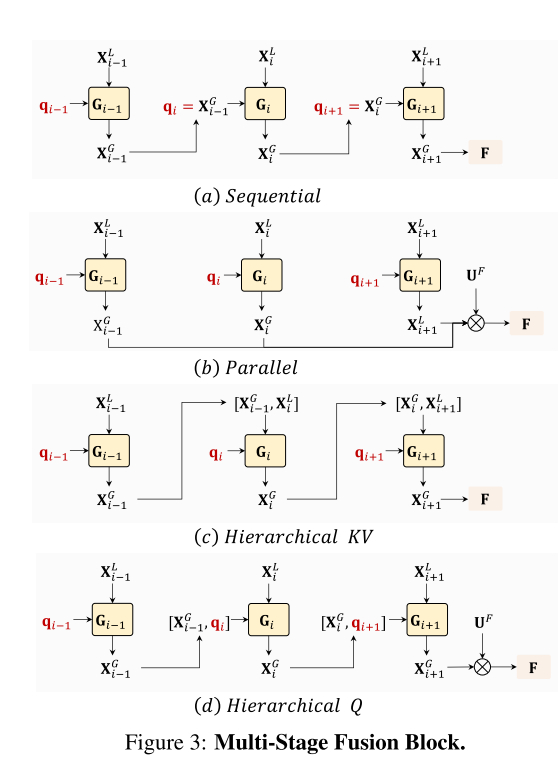
- Multi-stage Fusion: 为了将不同层的informative token融合,得到更复杂的表征,我们探索了包括串行、并行、层次化等几种融合方式,并最终采用最简单的串行设计。即前面层出来的informative token会作为下一层的query token,不断迭代融合多层信息。最后,这些来自多层融合的时空表征会与骨架网络的输入表征进行加权融合,得到最终送入分类层的判别表征。
实现细节
对于结构,经过消融实验我们发现:
- 对于Kinetics系列等场景相关视频,也即单图即可较好判断行为的前提下,模型只需要在深层额外插入Global UniBlock,便可以满足这一大类数据的需求。
- 对于Something-Something这类强时序相关视频,对模型的时序建模能力要求极高,除了在Patch Embedding引入temporal downsampling之外,我们还在每层插入Local UniBlock,在网络的中层和深层插入Global UniBlock,方能实现强大的时序判别。
训练时需要一些超参的设计保证模型正常收敛
- 模型初始化:为了保证模型初始训练与原图像模型输出一致,我们对插入的部分模块进行了零初始化,包括Local UniBlock输出的linear层、可学query、Global UniBlock中FFN的输出linear层,以及加权注意力的可学权重。
- 训练超参数:对强预训练模型,在视频任务上进行full-tuning迁移,需要使用较小的学习率,并且在数据规模较小是,需要引入额外的正则化如droppath等。
总结
在UniFormerV2中,我们探索设计了更高效更通用的时空建模模块,可以无缝适配图像预训练ViT,显著增强对视频任务的处理效果。开源模型和K710的加持,让整个模型的训练谱系的训练十分高效。仅利用开源的CLIP预训练和开源的有监督数据,UniFormerV2可在8个流行benchmark上超越以往SOTA。
这篇关于论文阅读:UniFormer和UniFormerV2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)