本文主要是介绍DialoGPT遇到的相关问题及解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇博客主要记录了参考DialoGPT官方说明复现所踩的一些坑,持续更新
目录
- 一、创建anaconda环境LSP
- 问题1
- 直接conda env create -f LSP-linux.yml -n LSP导致安装的pytorch和cudatoolkit版本错误
- 问题2
- conda activate LSP 没有激活成功导致python版本不一致
- 二、apex相关
- 问题3
- Cuda extensions are being compiled with a version of Cuda that does not...
- 问题4
- 报错 ImportError: Please install apex from https://www.github.com/nvidia/apex to use distributed and fp16 training.
- 问题5
- **ModuleNotFoundError: No module named 'fused_adam_cuda'**
- 问题6
- 提示This fp16_optimizer is designed to only work with apex.contrib.optimizers.*To update, use updated optimizers with AMP.
- 问题7
- 报错TypeError: __init__() got an unexpected keyword argument 'max_grad_norm'
- 其他
一、创建anaconda环境LSP
和官网差不多描述差不多,先git clone项目,然后进入DialoGPT项目目录,按照要求创建anaconda环境LSP,之后激活LSP
git clone https://github.com/microsoft/DialoGPT.git
cd DialoGPT
conda env create -f LSP-linux.yml -n LSP
conda activate LSP
有两个地方会可能对后续造成影响:
问题1
直接conda env create -f LSP-linux.yml -n LSP导致安装的pytorch和cudatoolkit版本错误
他给的环境应该是作者根据自己的GPU版本来下载的相应pytorch、cudatoolkit、nvcc等,可能和我们本地的版本是不一致的,在使用apex时可能会出问题,
所以可以先卸载pytorch,卸载的时候可以pip uninstall pytorch或者conda uninstall pytorch都试试,一般是其中一个可以
然后根据自己机器的情况,参考https://zhuanlan.zhihu.com/p/80386137
找到对应版本,在https://pytorch.org/找到对应命令下载(这里关于如何使用镜像等就不详写了,很多教程)
问题2
conda activate LSP 没有激活成功导致python版本不一致
第一次创建成功后应该使用
conda source activate LSP来激活而不是直接conda activate LSP,否则可能会导致LSP里的python版本为3.6.9,但是实际的python --version得到的还是本地的python版本
激活前还可以使用conda deactivate来退出之前的conda环境
二、apex相关
问题3
Cuda extensions are being compiled with a version of Cuda that does not…
主要参考https://zhuanlan.zhihu.com/p/80386137
前面也提到了,多半是版本不匹配问题
问题4
报错 ImportError: Please install apex from https://www.github.com/nvidia/apex to use distributed and fp16 training.
Traceback (most recent call last):File "LSP_train.py", line 223, in <module>"Please install apex from https://www.github.com/nvidia/apex "
ImportError: Please install apex from https://www.github.com/nvidia/apex to use distributed and fp16 training.定位到LSP_train.py文件中,主要是这一段
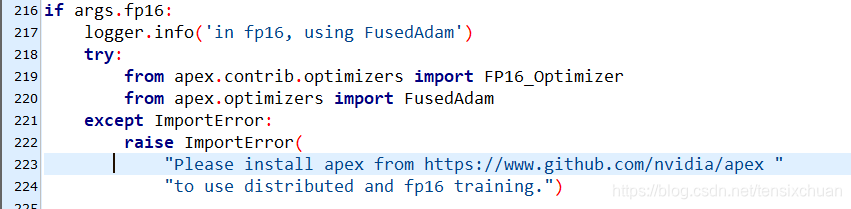
try:from apex.optimizers import FP16_Optimizerfrom apex.optimizers import FusedAdam
except ImportError:raise ImportError("Please install apex from https://www.github.com/nvidia/apex ""to use distributed and fp16 training.")
主要是在from apex.optimizers import FP16_Optimizer这里
报错:ImportError:"Please install apex from https://www.github.com/nvidia/apex " “to use distributed and fp16 training.”
原因是:最新版的apex中,FP16_Optimizer已经被移到contrib/optimizers下面了
参考linux安装apex时的一些问题
因此,把219,220行由
from apex.optimizers import FP16_Optimizer
from apex.optimizers import FusedAdam
修改为:
from apex.fp16_utils import FP16_Optimizer
from apex.optimizers import FusedAdam
注1:
如果把 from apex.optimizers import FusedAdam也同样改成from apex.contrib.optimizers import FusedAdam的话会报新的错:
问题5
ModuleNotFoundError: No module named 'fused_adam_cuda’
参考https://github.com/NVIDIA/apex/issues/633
ModuleNotFoundError: No module named 'fused_adam_cuda'
所以这一行还是保持原状, from apex.optimizers import FusedAdam
注2:
有的教程比如NVIDIA apex安装,是把from apex.optimizers import FP16_Optimizer改为from apex.contrib.optimizers import FP16_Optimizer
亲测可以暂时解决现在报的错,但是后面还是会出现问题6
问题6
提示This fp16_optimizer is designed to only work with apex.contrib.optimizers.*To update, use updated optimizers with AMP.
参见apex readme
FP16_Optimize已经被弃用,import的时候得用from apex.fp16_utils import FP16_Optimizer,而不是from apex.contrib.optimizers import FP16_Optimizer或者from apex.contrib.optimizers import FP16_Optimizer
最后log如下信息就表示FP16_Optimizer和FusedAdam可以正常使用

问题7
报错TypeError: init() got an unexpected keyword argument ‘max_grad_norm’
Traceback (most recent call last):File "LSP_train.py", line 229, in <module>max_grad_norm=1.0)
TypeError: __init__() got an unexpected keyword argument 'max_grad_norm'
定位到原文在这一段

参考链接apex readme quick-start
可能是因为apex省略了apex.normalization.FusedLayerNorm,max_grad_norm是一个多余的参数,所以删除,max_grad_norm=1.0试试(后面几处用到了max_grad_norm的也删除)
其他
1、训练时间很长,可能会提示network error:software caused connectiopn abort

参考解决ssh 连接报错 network error software caused connection abort 自动中断,可能是由于软件原因导致长时间未操作时会自动中断,按照教程设置就好。
2、训练完会有警告
Warning: FP16_Optimizer is deprecated and dangerous, and will be deleted soon. If it still works, you're probably getting lucky. For mixed precision, use the documented API https://nvidia.github.io/apex/amp.html, with opt_level=O1.
大意是说FP16_Optimizer 已弃用且危险,即将被删除。 运气好的话还有效。 对于混合精度,请使用已记录的 API https://nvidia.github.io/apex/amp.html,并带有 opt_level=O1。
所以感觉虽然前面修修补补的也解决了一部分因为DialoGPT太老而产生了一些问题,但是治标不治本,应该还是会试着更新一下代码,用更新后的优化器
3、训练时长
在1块16GB内存的Tesla V100上用原本的reddiet微调,medium版模型大概两个小时跑完
样例设置的一些参数如下:
06/27/2021 11:30:11 - INFO - __main__ - train batch size = 512, new train batch size (after gradient accumulation) = 64
06/27/2021 11:30:11 - INFO - __main__ - CUDA available? True
06/27/2021 11:30:11 - INFO - __main__ - Input Argument Information
06/27/2021 11:30:11 - INFO - __main__ - model_name_or_path /data/wd/DialoGPT/models/medium
06/27/2021 11:30:11 - INFO - __main__ - seed 42
06/27/2021 11:30:11 - INFO - __main__ - max_seq_length 128
06/27/2021 11:30:11 - INFO - __main__ - skip_eval False
06/27/2021 11:30:11 - INFO - __main__ - init_checkpoint /data/wd/DialoGPT/models/medium/pytorch_model.bin
06/27/2021 11:30:11 - INFO - __main__ - train_input_file /data/wd/DialoGPT/data/train.128len.db
06/27/2021 11:30:11 - INFO - __main__ - eval_input_file ./data/dummy_data.tsv
06/27/2021 11:30:11 - INFO - __main__ - continue_from 0
06/27/2021 11:30:11 - INFO - __main__ - train_batch_size 64
06/27/2021 11:30:11 - INFO - __main__ - gradient_accumulation_steps 8
06/27/2021 11:30:11 - INFO - __main__ - eval_batch_size 64
06/27/2021 11:30:11 - INFO - __main__ - learning_rate 1e-05
06/27/2021 11:30:11 - INFO - __main__ - num_optim_steps 10000
06/27/2021 11:30:11 - INFO - __main__ - valid_step 5000
06/27/2021 11:30:11 - INFO - __main__ - warmup_proportion 0.1
06/27/2021 11:30:11 - INFO - __main__ - warmup_steps 4000
06/27/2021 11:30:11 - INFO - __main__ - normalize_data True
06/27/2021 11:30:11 - INFO - __main__ - fp16 True
06/27/2021 11:30:11 - INFO - __main__ - lr_schedule noam
06/27/2021 11:30:11 - INFO - __main__ - loss_scale 0.0
06/27/2021 11:30:11 - INFO - __main__ - no_token_id True
06/27/2021 11:30:11 - INFO - __main__ - output_dir /data/wd/DialoGPT/models/output_model
06/27/2021 11:30:11 - INFO - __main__ - log_dir None
06/27/2021 11:30:11 - INFO - __main__ - pbar True
06/27/2021 11:30:11 - INFO - __main__ - local_rank -1
06/27/2021 11:30:11 - INFO - __main__ - config None
06/27/2021 11:30:11 - INFO - __main__ - device cuda
06/27/2021 11:30:11 - INFO - __main__ - n_gpu 1
06/27/2021 11:30:11 - INFO - pytorch_pretrained_bert.tokenization_gpt2 - loading vocabulary file /data/wd/DialoGPT/models/medium/vocab.json
06/27/2021 11:30:11 - INFO - pytorch_pretrained_bert.tokenization_gpt2 - loading merges file /data/wd/DialoGPT/models/medium/merges.txt
06/27/2021 11:30:16 - INFO - gpt2_training.train_utils - loading finetuned model from /data/wd/DialoGPT/models/medium/pytorch_model.bin
06/27/2021 11:30:17 - INFO - gpt2_training.train_utils - loading transfomer only
06/27/2021 11:30:17 - INFO - gpt2_training.train_utils - in fp16, model.half() activated
06/27/2021 11:30:20 - INFO - __main__ - Number of parameter = 354823168
06/27/2021 11:30:20 - INFO - __main__ - in fp16, using FusedAdam这篇关于DialoGPT遇到的相关问题及解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





