本文主要是介绍Macbook pro M3 Max 128G使用体验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

好久没写文章了,今天来谈谈M3 Max的使用感受。
Stable Diffusion:
使用ComfyUI来完成绘图任务,使用ByteDance/SDXL-Lightning模型微调版本

参数设置:
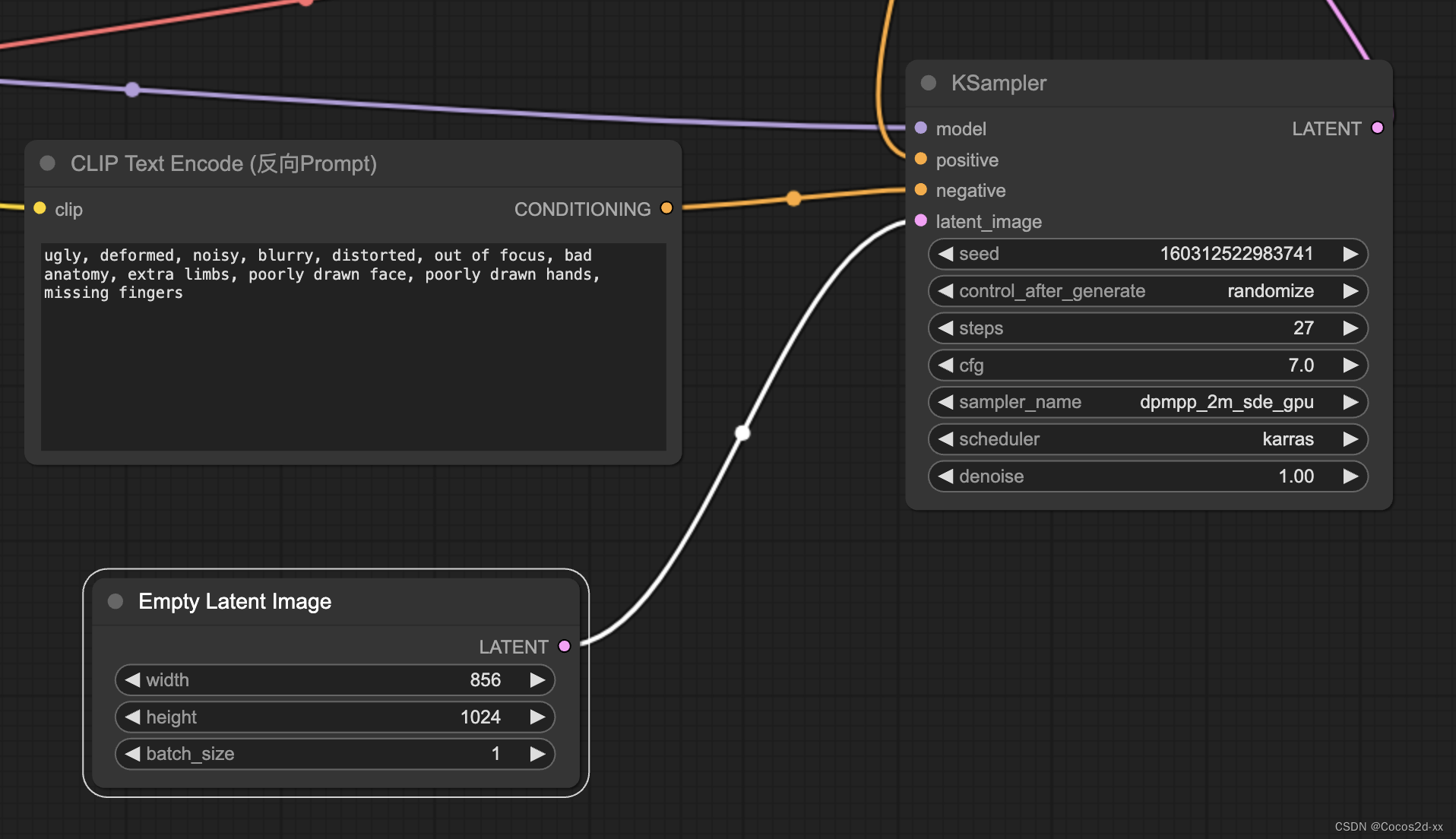
运行日志:
[2024-03-24 17:11]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 27/27 [00:40<00:00, 1.72s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 27/27 [00:40<00:00, 1.50s/it]
[2024-03-24 17:11] Prompt executed in 41.75 seconds
40秒推理生成完成,还不错。
附安装过程:
# https://developer.apple.com/metal/pytorch/
pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
python -m pip install -r requirements.txt
python -m pip uninstall mpmath
python -m pip install mpmath==1.3.0LLM大语言模型
1. Mixtral 8x7b 混合专家模型
mistralai/Mixtral-8x7B-Instruct-v0.1


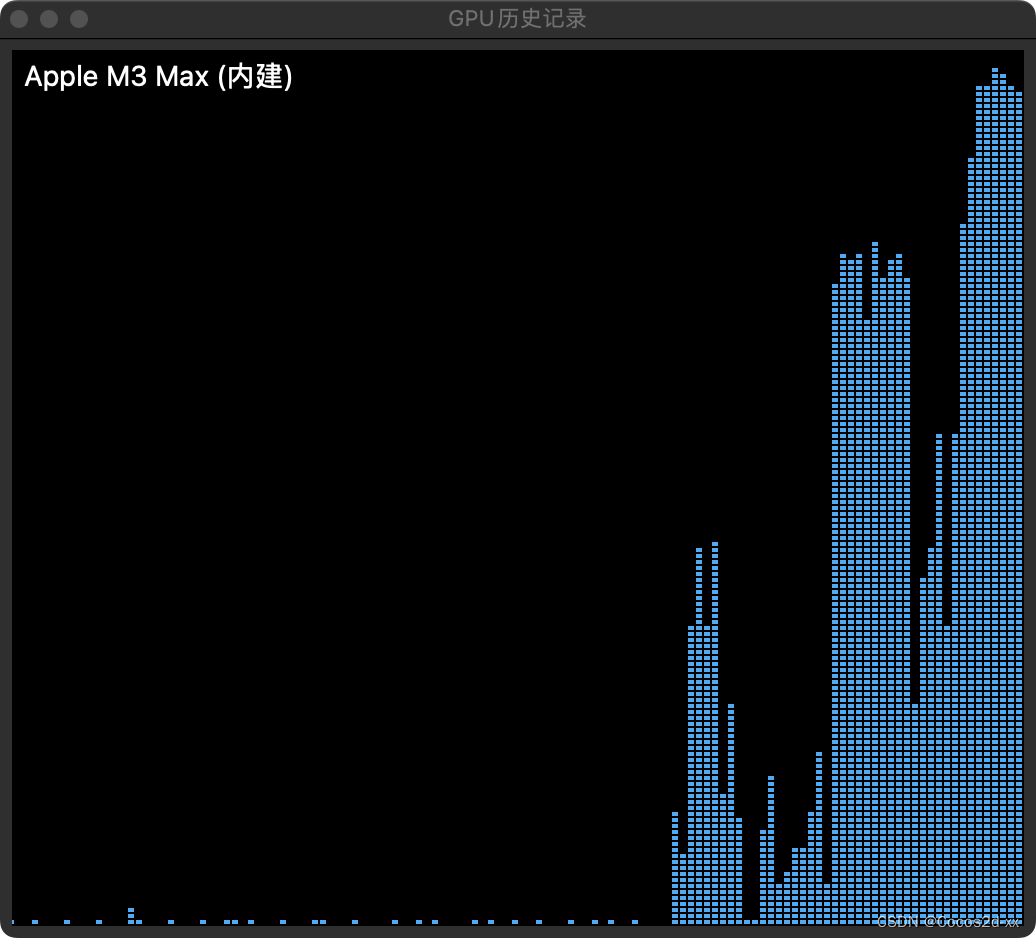
有一定的内存压力,不过每秒依然可以保证10个token的输出。
a_cpu = torch.rand(1000, device='cpu')
b_cpu = torch.rand((1000, 1000), device='cpu')
a_mps = torch.rand(1000, device='mps')
b_mps = torch.rand((1000, 1000), device='mps')print('cpu', timeit.timeit(lambda: a_cpu @ b_cpu, number=100_000))
print('mps', timeit.timeit(lambda: a_mps @ b_mps, number=100_000))cpu 1.9363472090335563
mps 1.4238181249820627
感觉mps并没有提升多少的感觉,这是为什么呢?
def test_cpu():a_cpu = torch.rand(1000, device='cpu')b_cpu = torch.rand((1000, 1000), device='cpu')a_cpu @ b_cpu
def test_mps():a_mps = torch.rand(1000, device='mps')b_mps = torch.rand((1000, 1000), device='mps')a_mps @ b_mpsprint('cpu', timeit.timeit(lambda: test_cpu(), number=1000))
print('mps', timeit.timeit(lambda: test_mps(), number=1000))cpu 2.2735738750197925
mps 0.4514276669942774
mps有更好的caching表现,所以比较节省时间
我后面将会对Finetuning,RAG检索增强,大语言模型处理Instructions性能这块进行分析。
这篇关于Macbook pro M3 Max 128G使用体验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






