本文主要是介绍ForkJoinPool在生产环境中使用遇到的一个问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、背景
在我们的项目中有这么一个场景,需要消费kafka中的消息,并生成对应的工单数据。早些时候程序运行的好好的,但是有一天,我们升级了容器的配置,结果导致部分消息无法消费。而消费者的代码是使用CompletableFuture.runAsync(() -> {while (true){ ..... }}) 来实现的。
即:
- 需要消费Kafka topic的个数: 7个,每个线程消费一个topic
- 消费方式:使用线程池异步消费
- 消费池:默认的
ForkJoin线程池???,并且没有做任何配置 - 是否会释放线程池中的核心线程: 不会释放
- 没出问题时容器配置:
2核4G - 出问题时容器配置:
4核8G,影响的结果:只有3个topic的数据可以消费。
2、容器2核4G可以正常消费
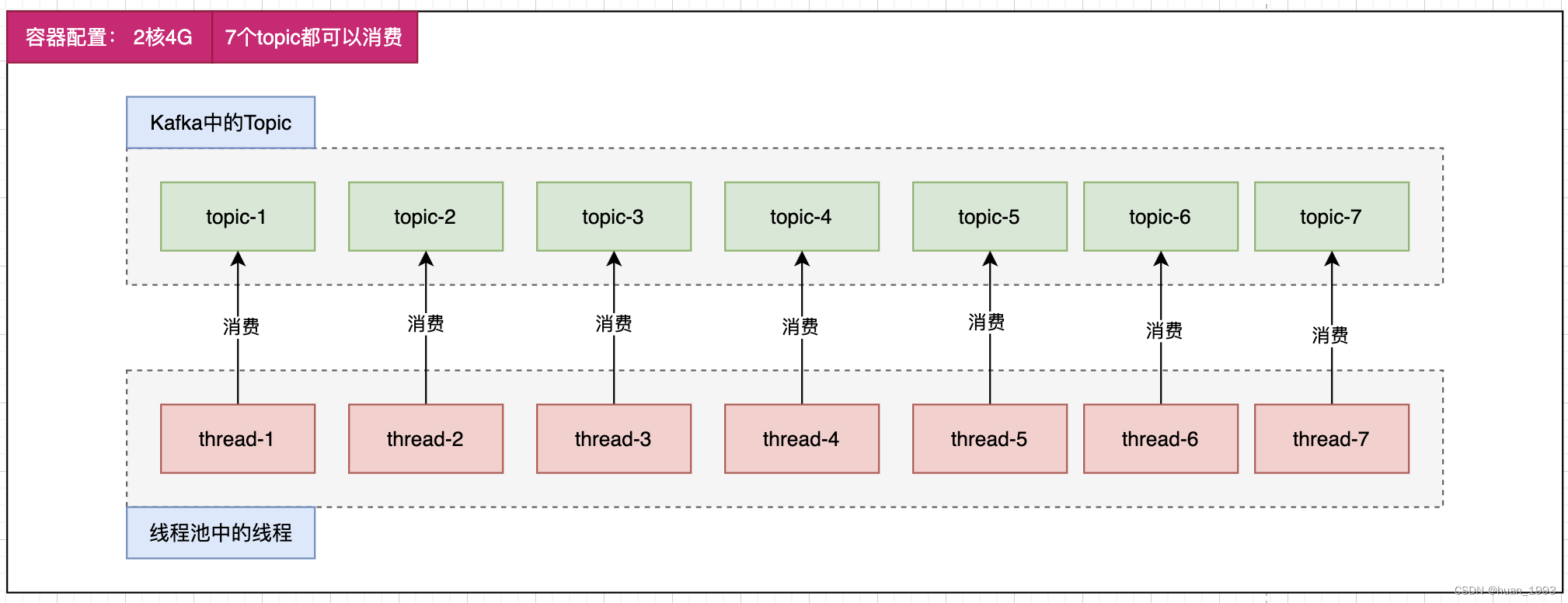
即:此时程序会启动7个线程来进行消费。
3、容器4核8G只有部分可以消费
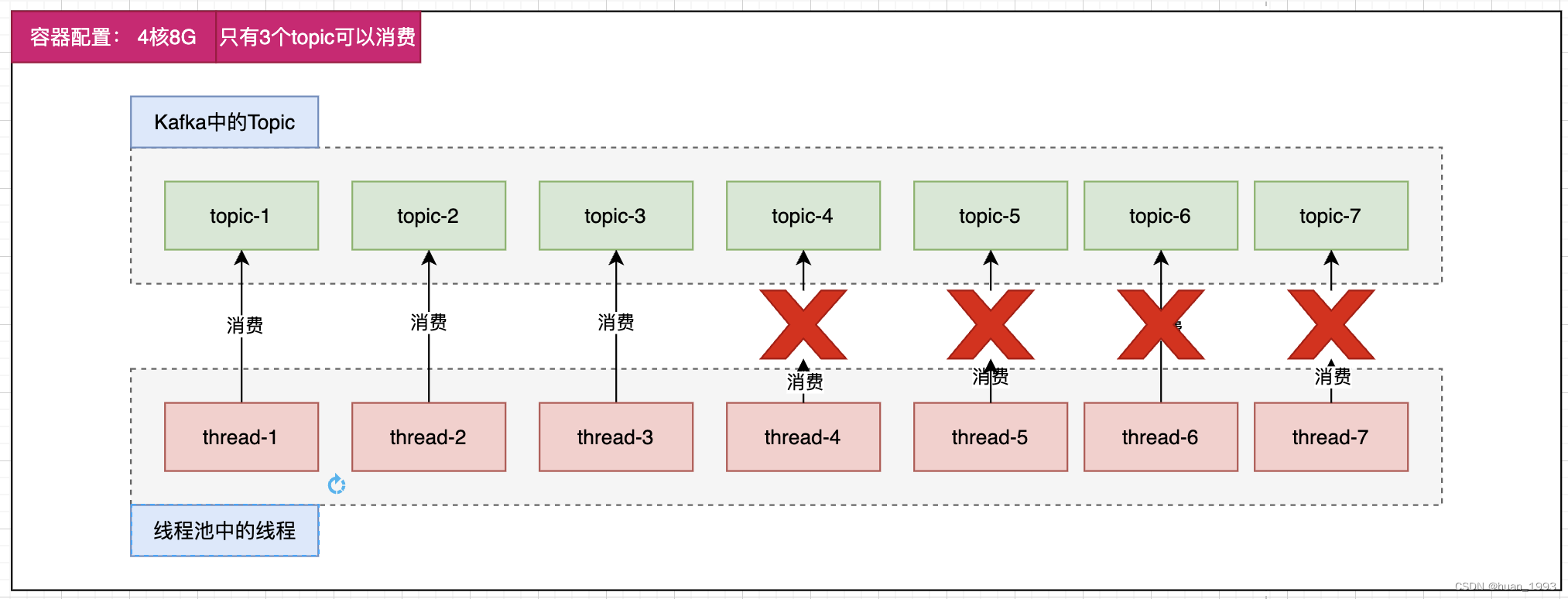
即:此时程序会启动3个线程来进行消费。
4、问题原因分析
1、通过上面的背景我们可以知道,是因为升级了容器的配置,才导致我们消费kafka中的消息失败了。
2、针对kafka中的每个topic,我们都会使用一个单独的线程来消费,并且不会释放这个线程。
3、而线程的启动方式是通过CompletableFuture.runAsync()方法来启动的,那么通过这种方式启动的线程,是每个任务一个启动一个线程,还是只启动固定的线程呢?.
通过以上分析,那么问题肯定是出现在线程池身上,那么我们默认使用的是什么线程池呢?查看CompletableFuture.runAsync()的源码可知,有一定的几率是ForkJoinPool。那么我们一起看下源码。
5、源码分析
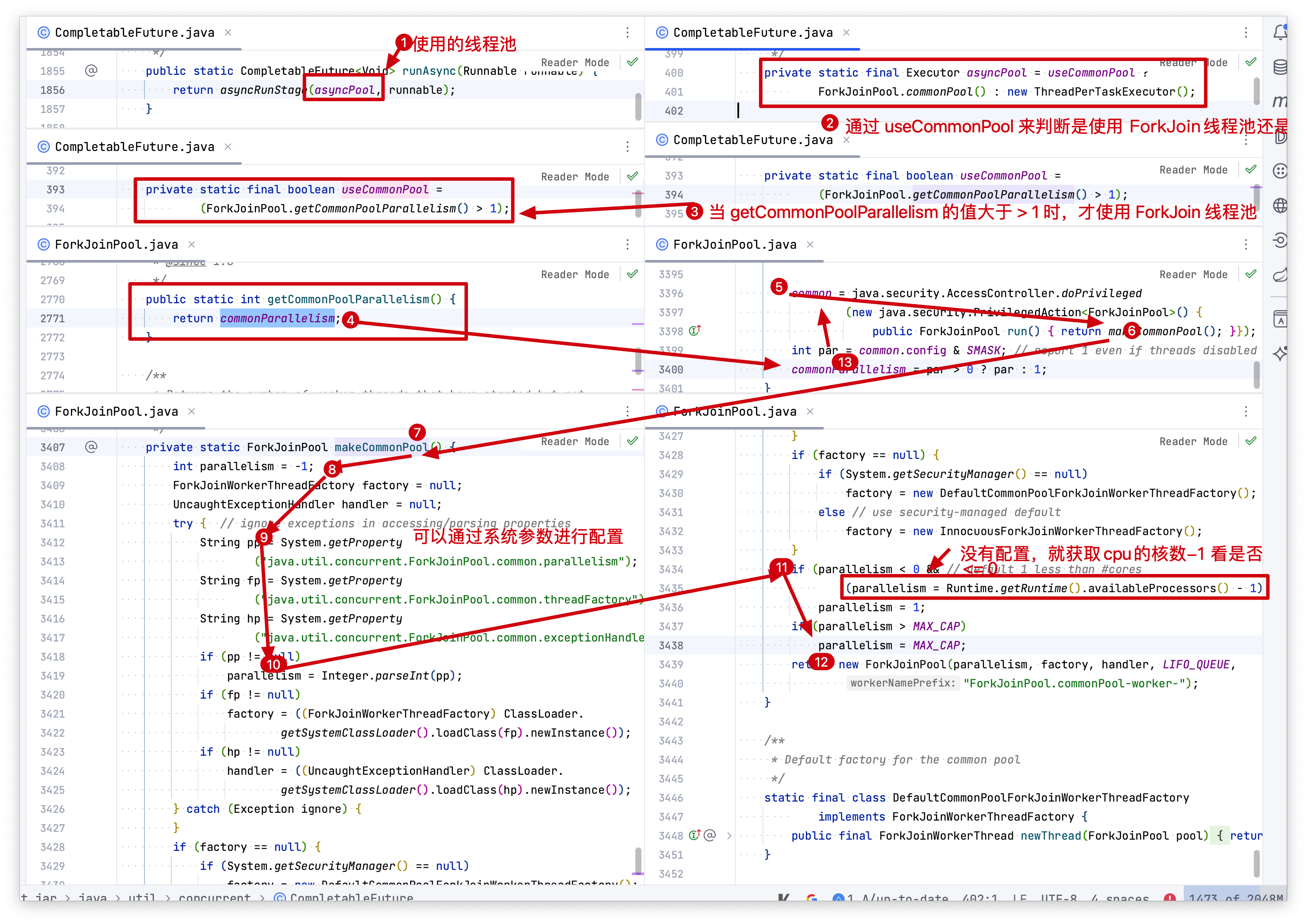
1、确认使用什么线程池
public static CompletableFuture<Void> runAsync(Runnable runnable) {return asyncRunStage(asyncPool, runnable);
}
private static final Executor asyncPool = useCommonPool ?ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
通过上述源码可知,我们可能使用的ForkJoin线程池,也可能使用的是ThreadPerTaskExecutor线程池。
ThreadPerTaskExecutor这个是每个任务,一个线程。ForkJoinPool那么就需要确定启动了多少个线程。
2、确认是否使用 ForkJoin 线程池
需要确定 useCommonPool 字段是如何赋值的。
private static final boolean useCommonPool =(ForkJoinPool.getCommonPoolParallelism() > 1);
通过上面代码可知,是否使用ForkJoin线程池,是由 ForkJoinPool.getCommonPoolParallelism()的值确定的。(即并行度是否大于1,大于则使用ForkJoin线程池)
public static int getCommonPoolParallelism() {return commonParallelism;
}
3、commonParallelism 的赋值
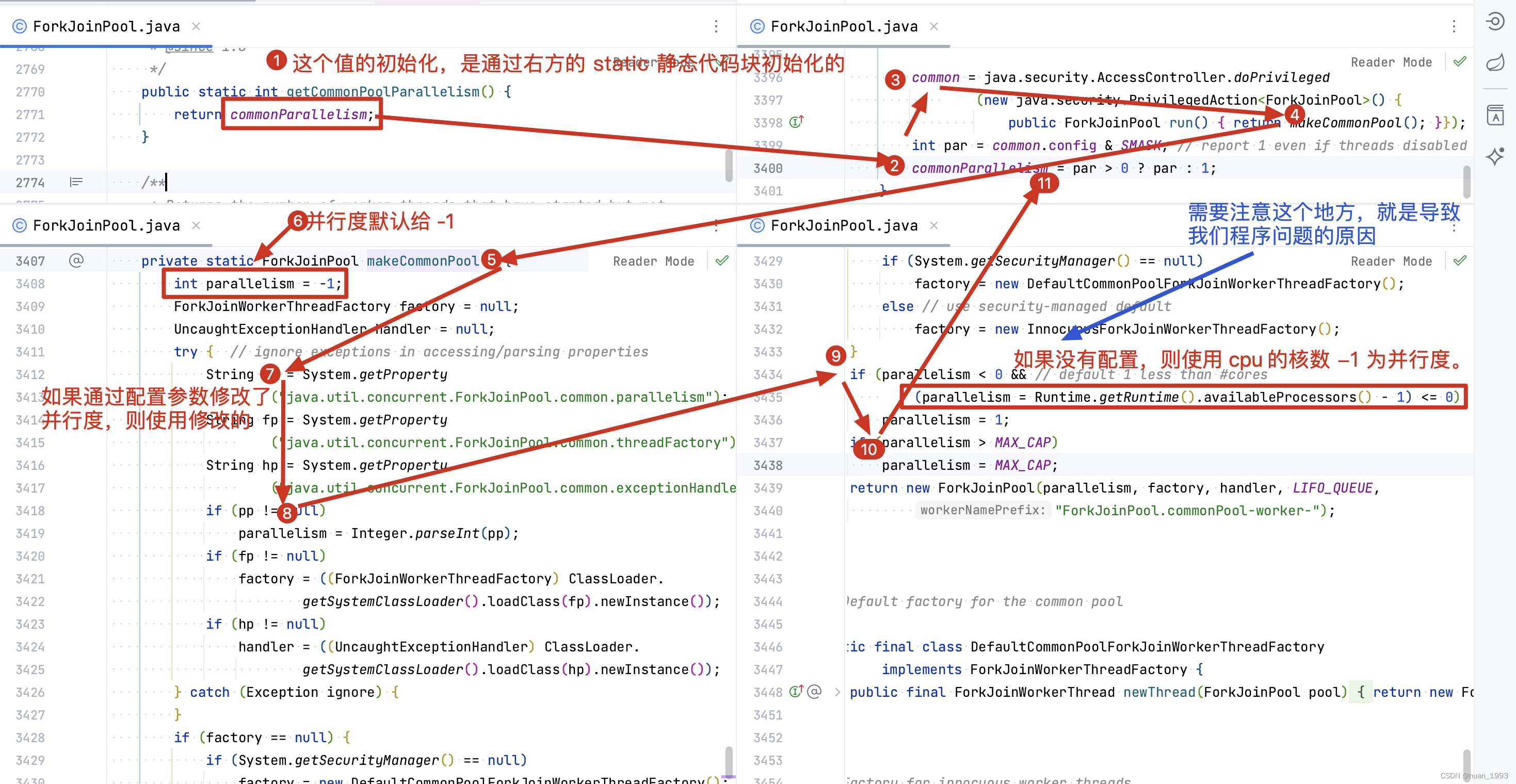
1、从上图中可知parallelism的设置有2种方式
- 通过Jvm的启动参数
java.util.concurrent.ForkJoinPool.common.parallelism进行设置,且这个值最大为MAX_CAP即32727。 - 若没有通过Jvm的参数配置,则有
2种情况,若cpu的核数<=1,则返回1,否则返回cpu的核数-1
2、commonParallelism的取值
common = java.security.AccessController.doPrivileged(new java.security.PrivilegedAction<ForkJoinPool>() {public ForkJoinPool run() { return makeCommonPool(); }});
int par = common.config & SMASK; // report 1 even if threads disabled
commonParallelism = par > 0 ? par : 1;
SMASK 的值是 65535。
common.config 的值就是 (parallelism & SMASK) | 0的值,即最大为65535,若parallelism的值为0,则返回0。
int par = common.config & SMASK ,即最大为 65535
commonParallelism = par > 0 ? par : 1 的值就为 parallelism的值或1
6、结论
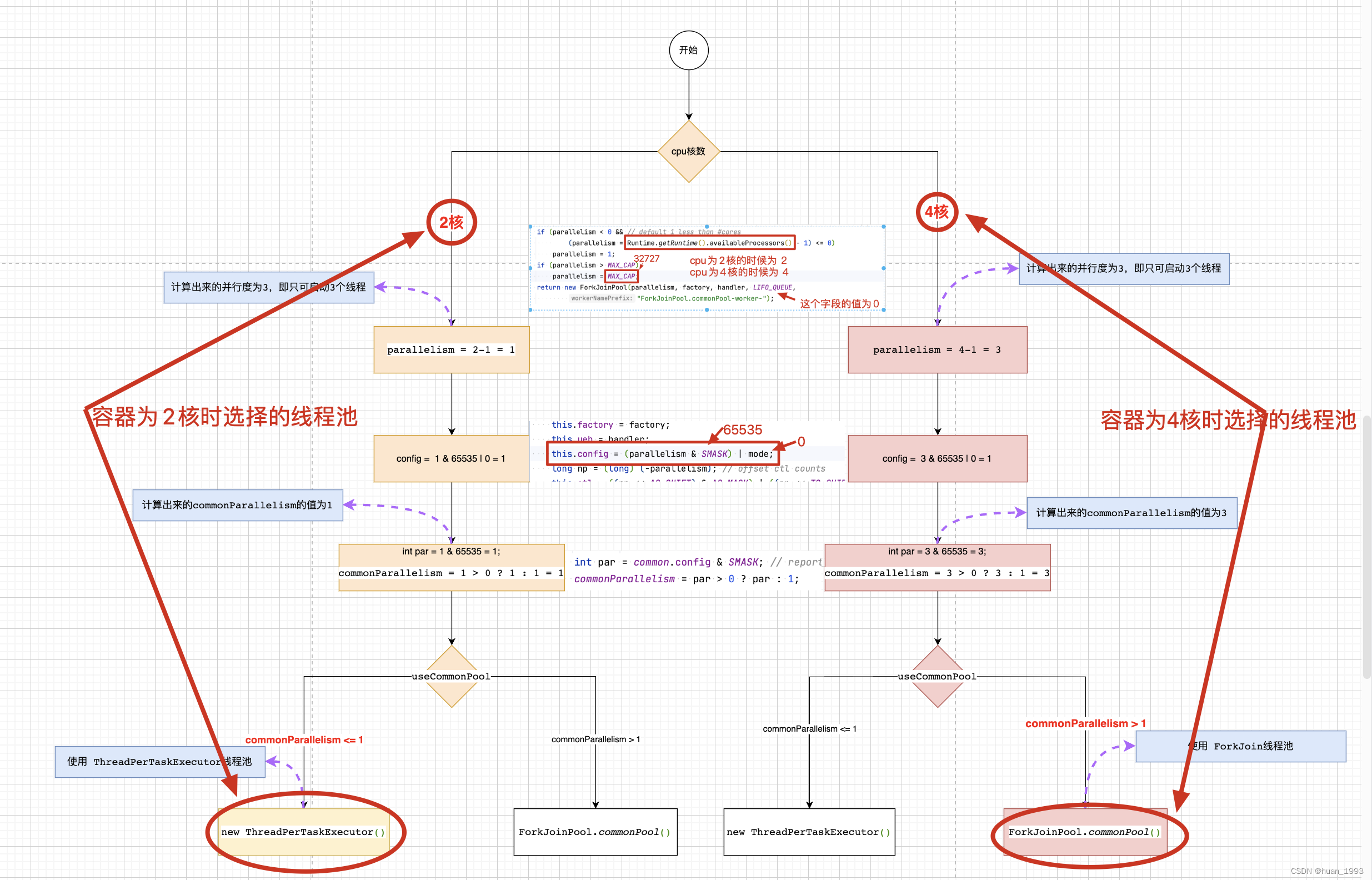
结论:
由上面的知识点,我们可以得出,当我们的容器是2核4G时,程序选择的线程池是ThreadPerTaskExecutor,当我们的容器是4核8G时,程序选择的线程池是ForkJoinPool。
这篇关于ForkJoinPool在生产环境中使用遇到的一个问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







