本文主要是介绍Wear-Any-Way——可控虚拟试衣一键试穿,可自定义穿着方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
Wear-Any-Way 是阿里巴巴最新推出的虚拟试衣技术,它不仅可以让用户在虚拟环境中试穿衣服,还可以根据需要自定义衣服的样式,比如卷起袖子、打开或拖动外套等。这种技术的引入旨在帮助消费者更好地了解衣服在不同穿着方式下的效果,从而提高在线购物的体验。
使用 Wear-Any-Way 技术,消费者可以在虚拟试衣室中看到衣服穿在模特身上的效果,并且可以通过交互操作将衣服调整到自己喜欢的样式。这种交互式的试穿体验能够更直观地展示衣服的穿着效果,帮助消费者做出更准确的购买决策。
与传统的线下试衣相比,使用 Wear-Any-Way 技术试穿衣服的优势在于:
-
方便快捷:消费者无需前往实体店铺,可以在家中通过手机或电脑即可进行试穿。
-
可定制性:消费者可以根据个人喜好自定义衣服的穿着样式,比如调整袖子长度、解开外套等。
-
多样性:消费者可以在虚拟试衣室中尝试不同的衣服款式和颜色,帮助他们更好地选择适合自己的衣服。
项目主页:https://mengtingchen.github.io/wear-any-way-page/
论文地址:https://arxiv.org/abs/2403.12965
摘要
Wear-Any-Way 是一个虚拟试衣框架,其主要特点包括生成高保真度的试穿效果以及支持用户精确地操纵穿着风格。这个框架首先构建了一个强大的标准虚拟试衣流程,能够在复杂场景中进行单件或多件服装的试穿,并且支持模型之间的试穿。为了实现用户对穿着风格的精确操纵,Wear-Any-Way 提出了稀疏对应对齐的方法,其中包括基于点的控制来指导特定位置的生成。
在标准设置下,Wear-Any-Way 达到了最先进的性能水平,并且为定制穿着风格提供了一种新的交互形式。例如,它支持用户拖动袖子卷起、拖动外套打开,甚至可以利用点击来控制衣服的塞进风格等。通过这些交互方式,Wear-Any-Way 在时尚行业中实现了更自由和灵活的服装表达,具有深远的意义。
虚拟试衣技术旨在合成特定人穿着提供服装的图像,为消费者提供身临其境和互动的试衣体验,无需实际穿戴。然而,现有的虚拟试衣方案存在一些缺陷。首先,它们主要适用于简单情况,如单一服装、简单纹理等,未能解决现实世界应用中的挑战,如模型到模型的试衣、多服装试衣以及复杂的人体姿势和场景。其次,过去的方法无法精确控制穿戴风格,未能展示同一件衣服在不同风格下的表现,尤其是在时尚领域中样式选择的关键作用。
为解决上述挑战,我们提出了一种全新的虚拟试衣框架,名为Wear-Any-Way,可一次性解决这些问题,成为现实世界应用的通用解决方案。Wear-Any-Way支持各种子任务,包括模型到模型的试衣、多件服装试衣以及复杂场景下的试衣,如街道场景。此外,Wear-Any-Way还支持用户自定义穿着风格,用户可以通过简单的交互操作,如点击、拖动等,精确控制衣物的穿着方式,包括袖子的卷取、外套的开襟大小甚至tuck的款式。
我们首先建立了一个强大的虚拟试衣基线,然后通过进一步的研究使其具备可定制性。我们提出了一种基于点的控制方法,通过稀疏对应对齐,将服装图像上的特定点与生成结果中人体图像上的目标点匹配,实现精确的穿戴方式控制。同时,我们还设计了几种策略,如条件丢弃、零初始化和点加权损失,以增强可控性。
算法架构
算法流程
我们的流程由两个分支组成。主干是使用预训练的Stable Diffusion初始化的修复模型。该模型以一个9通道的张量作为输入,其中包括4个通道的潜在噪声,4个通道的潜在背景(即修复背景),以及一个通道用于掩模(表示用于修复的区域)。原始的Stable Diffusion接收文本嵌入作为条件来指导扩散过程。相反,我们将文本嵌入替换为由CLIP图像编码器提取的服装图像的图像嵌入。
CLIP图像嵌入可以确保服装的整体颜色和纹理,但无法保留服装的细节。因此,我们还使用一个参考U-Net来提取服装的细节特征。我们的参考U-Net是一个标准的文本到图像扩散模型,具有4个通道的输入。在每个块之后,我们通过连接参考U-Net的“key”和“value”到主U-Net之后来进行特征融合。
为了进一步增强生成的效果,我们添加了姿态图作为额外的控制因素。我们构建了一个微小的卷积网络来提取姿态图的特征,并直接将其添加到主U-Net的潜在噪声中。我们使用DW-Pose从提供的行人图像中提取姿态图。
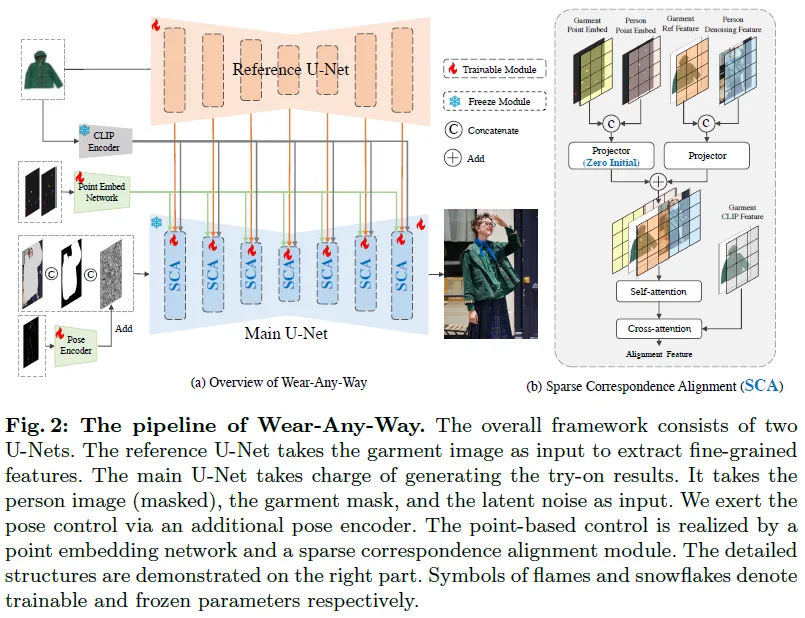
稀疏对应对齐
为了实现穿着风格的精确控制,在扩散过程中引入了稀疏对应对齐机制。具体来说,我们使用pointpair来标记一对控制点,其中一个点在服装图像上标记,另一个点在人物图像上给出。通过利用这两点之间的对应关系,我们可以控制生成结果:服装的标记位置将与人物图像上的目标位置匹配。通过这种方式,用户可以通过操纵多个点对来精确控制穿着风格。
首先,我们学习了一系列点嵌入来表示控制点对。然后,我们将这些控制信号注入到主U-Net和参考U-Net中。为了辅助模型学习对应关系,我们提出了条件丢弃、零初始化和点引导损失等策略。
点嵌入方面,假设我们采样了N对点,我们使用disk maps来分别表示服装和人物图像上的点。我们将服装图像上的点不重复地随机填充1到K之间的值,而人物图像上的点采用相应的值。这种随机赋值解耦了语义和点,因此使点表示可置换。这为支持任意位置和数量的点控制提供了基础。
我们设计了一个具有堆叠卷积层的点嵌入网络,将disk maps映射到高维嵌入空间。该网络在端到端训练中与扩散模型一起进行优化。
嵌入注入方面,通过将点嵌入注入到注意力层中,我们能够在控制方面表现出色。在我们的基线模型中,来自参考U-Net的特征被连接到自注意力的“键”和“值”上,其中m和r的下标表示主U-Net和参考U-Net。
A t t e n t i o n = s o f t m a x ( Q m ⋅ c a t ( K m , K r ) T d k ) ⋅ c a t ( V m , V r ) {\mathrm{Attention}}={\mathrm{softmax}}({\frac{Q_{m}\cdot{\mathrm{cat}}(K_{m},K_{r})^{T}}{\sqrt{d_{k}}}})\cdot{\mathrm{cat}}(V_{m},V_{r}) Attention=softmax(dkQm⋅cat(Km,Kr)T)⋅cat(Vm,Vr)
该注意力层使参考UNet提取的服装特征能够集成到主U-Net中。为了实现点引导的对应控制,我们修改这个注意层,通过使用公式(4)中的“query”和“key”添加人和服装的点嵌入。
A t t e n t i o n = s o f t m a x ( ( Q m + E p ) ⋅ c a t ( K m + E p , K r + E g ) T d k ) ⋅ c a t ( V m , V r ) {\mathrm{Attention}}={\mathrm{softmax}}{\bigl(}{\frac{(Q_{m}+E_{p})\cdot{\mathrm{cat}}(K_{m}+E_{p},K_{r}+E_{g})^{T}}{\sqrt{d_{k}}}{\bigr)}\cdot\mathrm{cat}}(V_{m},V_{r}) Attention=softmax(dk(Qm+Ep)⋅cat(Km+Ep,Kr+Eg)T)⋅cat(Vm,Vr)
这样,在将服装特征集成到主U-Net中时,特征聚合将考虑点对的对应关系。将服装上的点定位到的特征点与人物图像上的特征点位置进行对齐。因此,用户可以指定控制点,通过单击和拖动操作穿着样式。
训练策略
除了模型结构的设计,我们还制定了多种训练策略来辅助穿戴学习对应对齐。
-
Condition dropping(条件丢弃):分析表明,修复模型和人体姿态图可以在一定程度上反映训练样本的佩戴风格。为了强制模型从控制点学习,我们增加了删除姿态映射并将修复掩码退化为地面真值掩码周围的框的可能性。
-
Zero-initialization(零初始化):在“key”和“value”的注意力上添加点嵌入会导致训练优化的不稳定。为了实现渐进集成,我们在点嵌入网络的输出端添加了一个初始化为零的卷积层。这种零初始化带来了更好的收敛性。
-
Point-weighted损失(点加权损失):增强配对点的可控性。我们增加了人物图像上采样点周围的损失权重。磨损监督是用于预测噪声的均方误差损失。
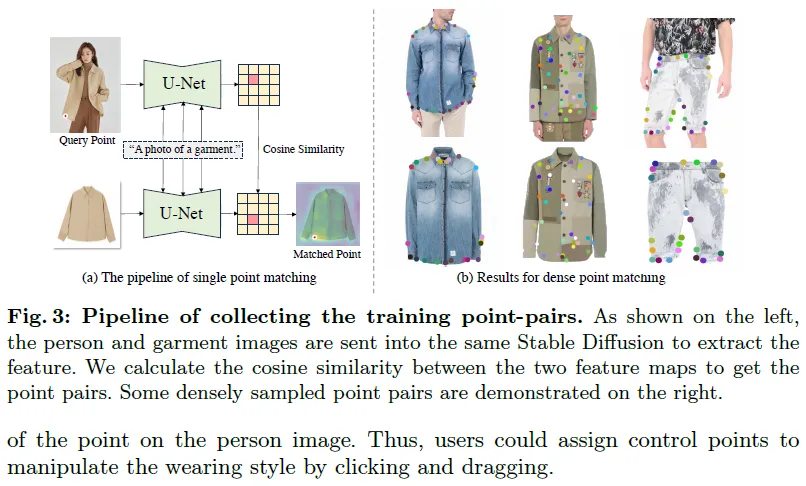
收集训练点对
在实际穿戴过程中,衣服并不像钢铁一样坚硬,而会发生变形。为了处理这种情况,我们利用siamese text-to-video扩散模型分别从人体和服装图像中提取特征。然后,我们将最后一个预测结果在多个时间步上进行集成,以获得一个鲁棒的匹配。具体来说,给定人物图像上的某一点,我们选择其在服装图像上的最大余弦相似度对应点。我们首先从人物图像中提取穿着衣服的区域,并将其作为模板。然后,在模板的内部和边界区域随机采样点作为查询,并利用匹配流水线提取服装图像上的对应点。针对复杂姿态下服装图像上的一些点无法与人体图像匹配的问题,我们选择从人物图像到服装图像的映射方向,以解决这一问题。
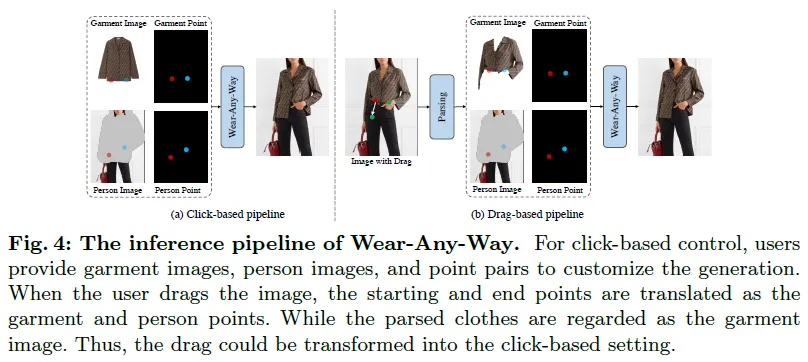
推理操作
推理流程如图4所示。在点击设置中,用户除了提供服装图像和人物图像外,还可以在这两幅图像上指定多个点对作为控制信号。将服装点表示的服装图像上的坐标与生成结果中人物点的对应位置进行对齐。对于基于拖拽的控件,将其起点和终点分别处理为服装点和人物点,并将解析后的服装作为服装图像。这样,基于拖动的操作就可以转换为基于点击的控件。
实验
实现细节
详细配置: 我们采用了Stable Diffusion-1.5的预训练权重来初始化主U-Net和参考U-Net。我们收集了30万个高质量的试衣数据。为了与其他作品进行公平的比较,我们分别在VITON-HD和Dresscode数据集上训练Wear-Any-Way来进行定量和定性比较。
评估指标:
-
标准虚拟试衣: 我们首先评估了在标准虚拟试衣基准(即VITON-HD、Dresscode)上的穿着性能,以报告定性结果。同时,与现有方法进行了定性比较,证明了所提方法的有效性。
-
点控制评估: 我们使用FashionAI检测器在服装图像和人物图像上检测landmark的距离。然后,我们使用成对的landmark作为控制点来生成试衣图像。接下来,我们再次使用相同的检测器在新生成的图像上定位landmark。通过计算他们之间的欧氏距离来评价控制能力。理想情况下,如果生成过程能很好地由点控制,那么landmark距离应该较小。
与现有方法比较:
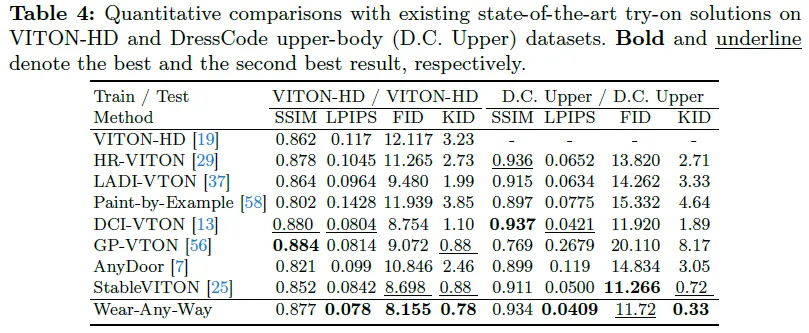
- 标准虚拟试衣: 我们在表4中报告了VITON-HD和Dresscode数据集的定性结果。我们的模型在FID和KID上取得了最好的结果,在SSIM和LPIPS上取得了有竞争力的性能。考虑到量化结果不能完全反映真实生成质量。我们在图6中与之前的最先进的解决方案进行了定性比较。与其他作品相比,Wear-Any-Way在生成质量和细节保持方面具有明显的优势。
可控生成: 通过与基于拖动的图像编辑方法(如DragDiffusion和DragonDiffusion)进行对比,我们证明了该模型的可控性。DragDiffusion不能准确地遵循drag的指令,而DragonDiffusion通常会破坏人体和服装的结构。

定性分析
实验表明,Wear-Any-Way支持对各种类型的服装(包括外套、t恤、裤子、卫衣等)的操纵。此外,用户可以指定任意数量的控制点,以得到定制的生成结果。在精确的点控辅助下,Wear-Any-Way可以对外套进行“连续”编辑,逐步拆分外套。穿着的高度可控性使它能够实现许多奇妙的穿着风格,如卷起袖子或油漆,以及不同类型的褶。


这篇关于Wear-Any-Way——可控虚拟试衣一键试穿,可自定义穿着方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








