本文主要是介绍腾讯容器云平台GaiaStack亮相kubeCon,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

KubeCon + CloudNativeCon 首次登陆中国上海。这意味着中国Kubernetes 爱好者们齐聚上海来参与这场全球范围内最大的 Kubernetes 技术盛会。数据平台部高级工程师宋盛博在大会上介绍了腾讯企业级容器云平台GaiaStack在机器学习场景的实践,即《Deep CustomizedKubernetes for Machine Learning in Tencent》
首先简单介绍一下GaiaStack。GaiaStack是腾讯基于kubernetes打造的容器私有云平台。服务于腾讯内部各个BG的业务,如广告、支付、游戏等业务,同时支持腾讯云的各行业客户做私有云部署。GaiaStack的目标是支持各种类型的应用,包括微服务、devops场景、大数据、有状态应用、AI平台、区块链、物联网等等,并从底层的网络、存储到docker、kubernetes,以及部署、监控的产品化等各方面完善了容器平台的企业级实现。
为了实现大规模企业级机器学习平台,我们对kubernetes做了不少定制化的优化,因为kubernetes的官方版本并不是专门为ML设计的,比如对GPU拓扑的感知,对一些应用的host devices的使用,对GPU资源的管理,已有的各种workload类型,比如deployment、statefulset、job,cronjob等都不能很好的适应ML等等。

时间关系,今天主要讲四个方面:
GPU通信方式有四种,分别是SOC、PXB、PHB和PIX,他们的通信代价依次降低,由拓扑关系决定。为了让GPU卡之间的通信开销占比减小,以下图为例,运行在GPU-0和GPU-1上的app的运行时间会比运行在GPU0上和GPU3上小很多。因此,Gaia Scheduler实现了GPU集群资源-访问代价树算法,来对GPU的拓扑关系进行感知,并且在调度中充分考虑该拓扑关系。具体的实现可以参考我们即将在The IEEE ISPA 2018发表的论文《GaiaScheduler: A Kubernetes-based Scheduler Framework》。
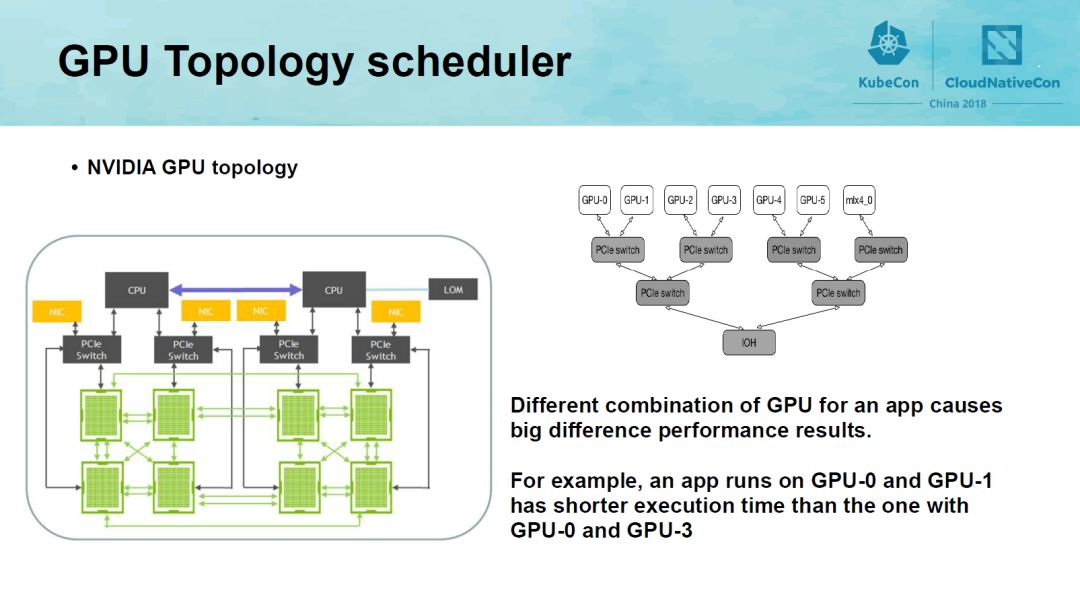
如下图这个例子,GaiaStack scheduler实现的对GPU卡的分配是GPU0,1,相对于默认分配到GPU0,2,data transmit speed提升了200%。

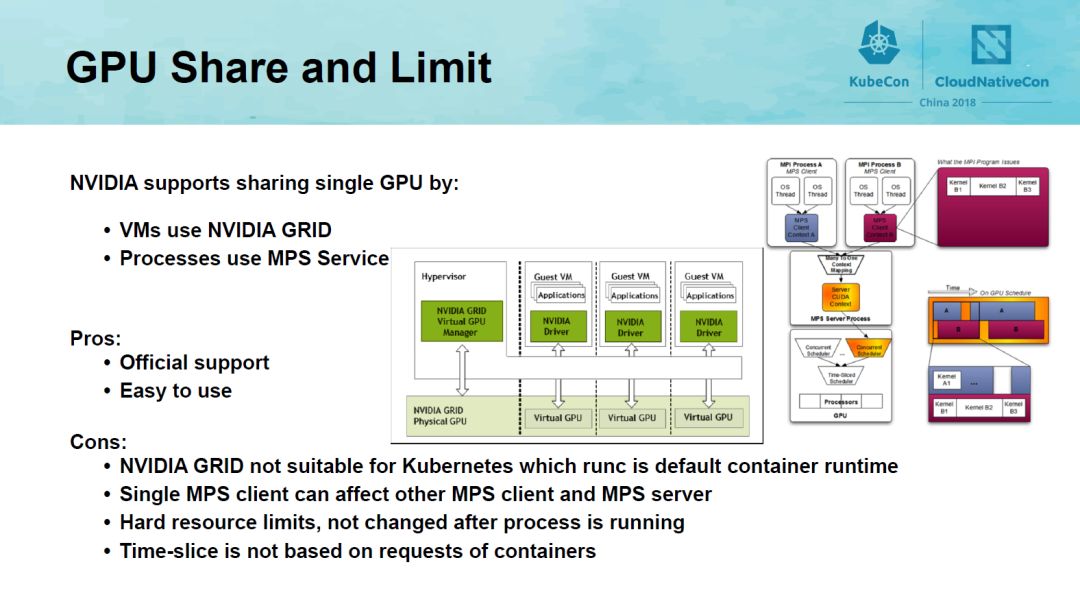
第二部分是GPU的资源管理。我们知道NVIDIA对单个GPU的共享有两种方式:VM使用的NVIDIA GRID以及进程使用的MPS Service。NVIDIA GRID并不适合Kubernetes的container Runtime场景。MPS Service未实现隔离,且对每个进程使用的GPU资源采用了硬限制的方式,在程序运行中无法修改。分时调度也不是基于容器的资源请求,总之,对GPU是无法实现基于容器级的软件虚拟化。但由于GPU价格昂贵,对GPU资源的容器级别的软件虚拟化具有巨大的意义。
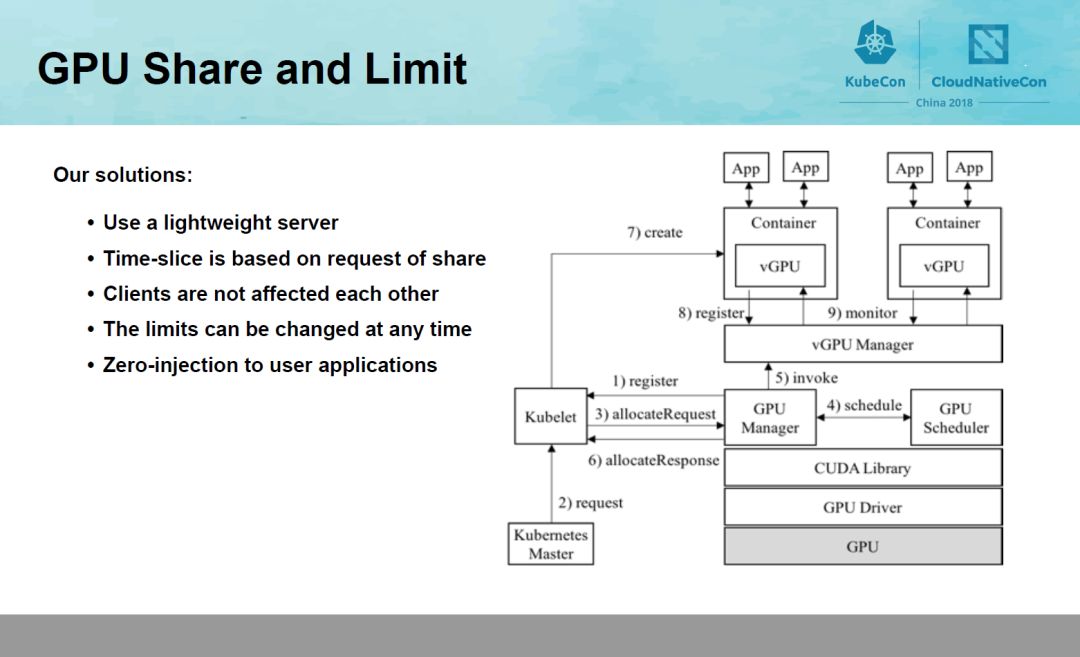
实现GPU虚拟化有三个挑战:第一是Transparency,不对k8s以及用户的应用程序做入侵,第二是性能,第三是隔离。为了实现对k8s的透明,GaiaStack使用了deviceplugin,来做GPU资源的发现以及为任务分配相应的硬件资源及配置容器运行时环境。在具体实现中,引入了四个核心组件,GPU Manager,GPU Scheduler,vGPU Manager和vGPU Library,如图所示,实现了双层资源管理,在主机层,GPU Manager负责创建vGPU,GPUScheduler负责为vGPU分配物理GPU资源。在容器层,vGPU Library负责管理具体容器的GPU资源。用户的资源请求会通过Manager控制,但程序运行起来后,所有的数据读写就不再经过Manager,最大限度的减少overhead。我们选取了不同的深度学习框架进行测试,分别在物理机和容器内使用每一个框架运行MNIST应用,并测试执行时间。Overhead都不超过1%。具体的实现可以参考我们即将在TheIEEE ISPA 2018发表的论文《GaiaGPU: Sharing GPUs inContainer Clouds》。
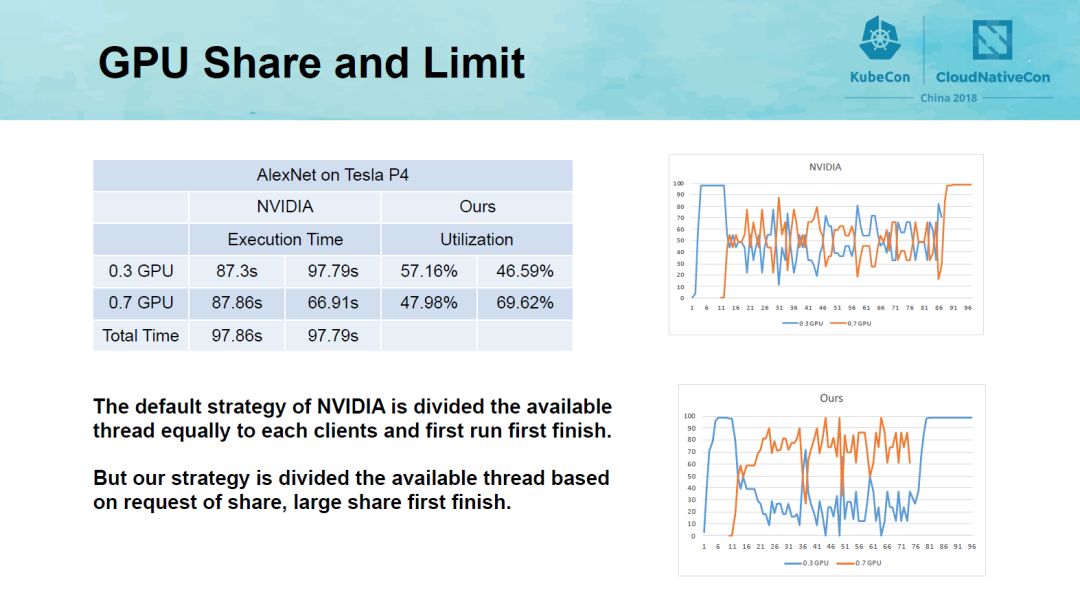
为评估GPU资源管理方法的有效性,我们在Tesla P4机器上进行了实验。如图所示我们在一个GPU上运行了两个Tensorflow的AlexNet应用,分别为两个进程分配30%和70%的GPU资源。NVIDIA默认分配策略将资源均等的分给两个进程,因此先开始的进程先结束。而我们的分配策略是基于进程资源的,因此拥有较多资源的进程先结束。
应用管理方面方面, Kubernetes提供了deployment、statefulset、job等应用类型各司其职,分别运行微服务,有状态服务和离线作业。这些应用类型看似美好,但是实际使用时会遇到各种各样的问题,比如在缩容时deployment无法支持按照指定的策略进行,statefulset的升级只能按标号顺序依次进行,且一个statefulset不能同时灰度两个以上的镜像版本,而所谓的支持离线的job类型,Spark on Kubernetes的实现甚至都没有用job来运行。
腾讯内部很多业务都是存量业务,需要能按照运维人员的策略控制每个实例的状态,比如灰度升级场景,和statefulset提供的灰度功能不太一样,业务可能希望今天对某个联通VIP的业务实例进行升级,这个VIP下的业务实例的id不一定是有序的,升级完一周后,如果运行稳定,再对其他VIP的实例分批次进行升级,中间可能长时间维持运行多个版本的稳定状态。Statefulset的功能无法达到这样的效果,所以我们开发了TApp(Tencent App)的应用类型。TApp是利用Kubernetes CRD功能定义的扩展API,TAppSpec对PodSpec进行了封装,支持指定每个实例的PodSpec模版和期望的状态。正是基于这样的设计,TApp相比Statefulset优势有:支持指定若干实例多次进行启动、停止、删除、原地灰度升级、回退等操作;灰度升级功能不只是修改镜像版本,甚至可以多加一个容器;单个TAPP应用的Pod支持N个版本。此外TApp与Statefulset应用类型具有一些相同点:Pod具有唯一自增ID;绑定单独云盘,迁移时数据盘跟随迁移。
在后来的推广中我们发现TApp不仅仅是腾讯的需求,很多企业都有类似的需求,因此我们现在称TApp为“通用服务”。目前GaiaStack上运行的绝大多数任务,不论是在线服务,离线业务,都使用的我们自研的通用服务类型。


存量业务往往要求IP端口固定,而微服务对这些没有要求。在线服务相比离线业务一般单台服务器的虚拟化比低,但是对网络性能的要求高。为支持这些不同的需求,GaiaStack自研的Galaxy网络插件为用户提供两种网络类型:Underlay 网络,即基于宿主机物理网络环境的方案。这种方案下容器与现有网络可以直接互通,不需要经过封包解包或是NAT,其性能最好。但是缺点也很明显,其普适性较差,且受宿主机网络架构的制约,比如IP可能不够用。Overlay 网络,即通用的虚拟化网络方案。这种方案不依赖于宿主机底层网络架构,可以适应任何的应用场景,方便快速体验。因为在原有网络的基础上叠加了一层Overlay网络,封包解包或者NAT对网络性能都是有一定损耗的。
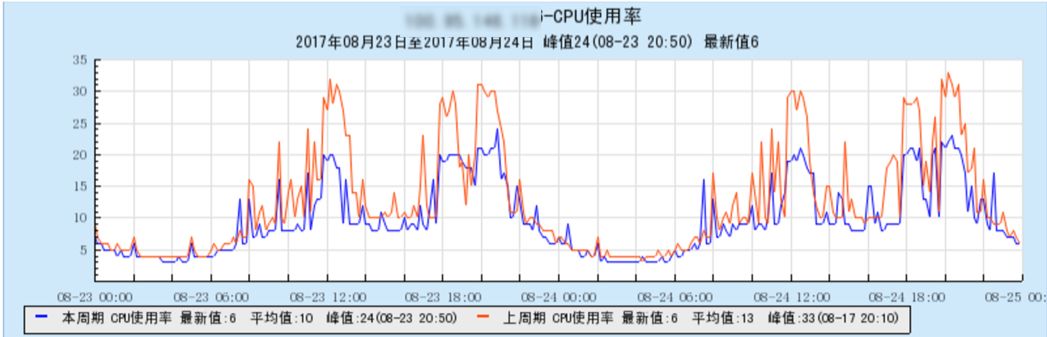
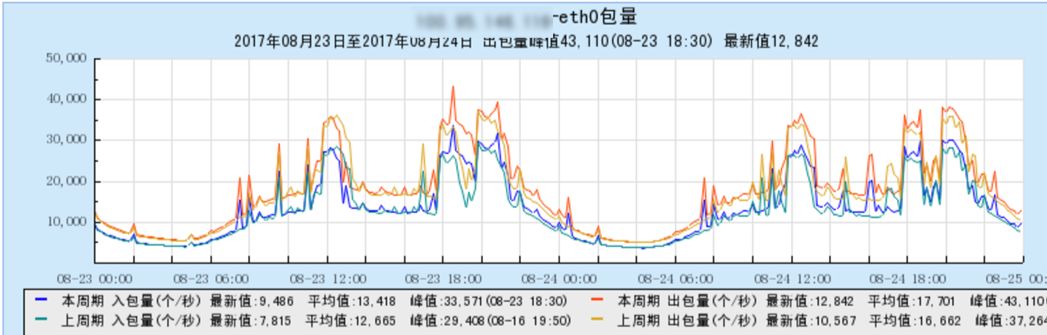
在实现Underlay网络方案时,考虑到GaiaStack面临腾讯内部场景,共有云场景和外部企业客户私有化场景,而每个场景的底层网络架构都是不一样的,所以我们的Underlay方案不会对底层网络有入侵。我们目前支持了Linuxbridge/MacVlan和SRIOV,根据业务场景和硬件环境,具体选择使用哪种网桥。下面这两幅图就是生产环境使用SRIOV替换bridge网桥后带来的性能提升,CPU使用降低约1/3,包量反而增加6%。
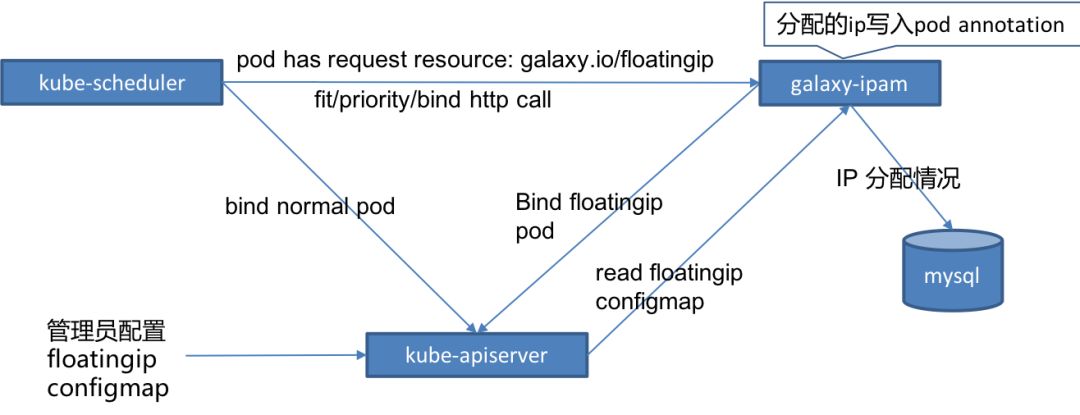
我们通过实现Kubernetes调度器插件galaxy-ipam,支持了存量业务使用Underlay网络IP不变的功能,图中Floatingip即指Underlay IP。
另外我们最开始就希望能够将在线和离线混部以节省服务器资源,事实上也运营着这样的集群,所以网络最开始就被设计为:不同的应用可以选择不同的网络模式;同一主机的不同容器可以选择不同的网络模式。
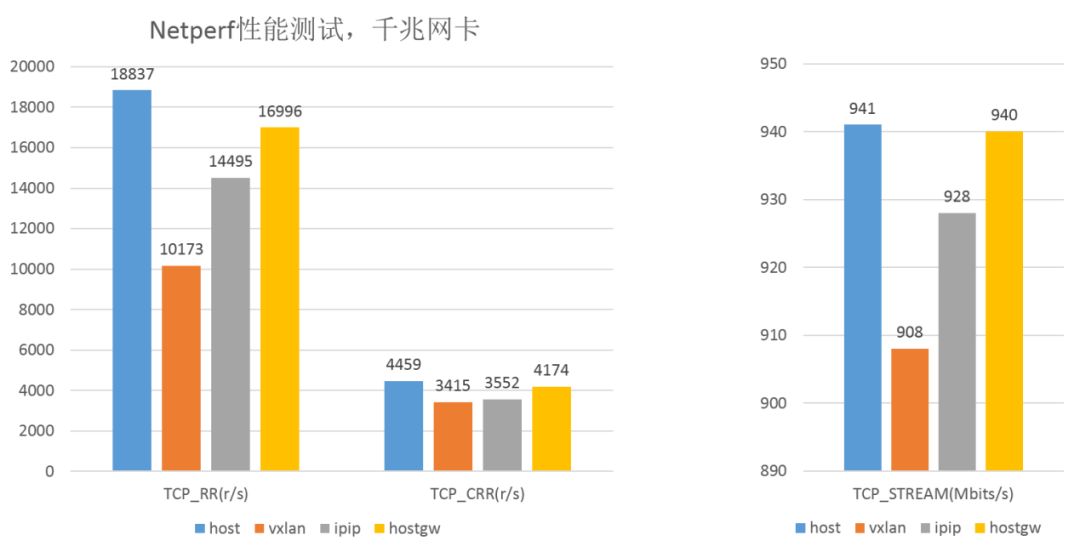
对于Overlay网络,我们调研了很多开源容器网络项目,发现其各有利弊。在综合考虑上述各方案优缺点后,我们汲取了flannel/calico容器网络开源项目的优处,实现了基于IPIP和Host Gateway的混合方案。同节点的容器报文无桥接方式,利用主机路由表进行转发,避免跨主机容器访问时bridge的二层端口查询。二层相连节点的容器报文无封包,利用主机路由表进行转发,因为无封包所以性能最优。跨网段节点容器报文利用IPIP协议封包,IPIP外层额外包头仅20字节,开销较vxlan 50字节更小,所以性能好于vxlan。我们的方案提交到了flannel官方,并被社区合并
https://github.com/coreos/flannel/pull/842。
下面的柱状图是在千兆网卡的环境使用netperf对这种方案进行了测试,图中长连接和短连接都是64字节,从图中可以看出IPIP和Hostgateway相比Vxlan带来14%到40%的性能提升。
网络隔离方面,我们基于iptables和ipset实现了Kubernetes网络策略,为业务提供了细粒度的隔离能力。网络策略的设计如下图所示,充分利用ipset和iptables multiport extension减少iptables规则条数。
除了上面讲的这几个方面之外,为了更好的支持ML,我们对底层的分布式存储也做了大量的优化,比如对ceph引入了quota管理,优化了挂载权限,并可以动态修改规则,实现了回收站的功能,对大目录的优化、多mds的优化等等。更好的保证了ML类型业务对底层存储性能要求。
另外,由于很多ML作业运行时间较长,而且GaiaStack还要同时支持在线应用,所以对可用性要求更高,因此GaiaStack实现了完全的热升级,即GaiaStack系统本身的跨版本升级对上面运行的应用完全没有影响,不但pod不会丢失,而且也不会重启。
在资源管理方面,除了这里讲的对GPU资源的优化,我们还增加了多磁盘的本地磁盘容量管理、网络带宽管理,并且将所有的资源维度都纳入quota管理,以及资源调度等,更好的完善了容器云的资源管理能力。
对于大规模的ML集群,我们也实现了零入侵的P2P registry,大大提升了镜像下载的效率,并且通过优化算法,大大减少了registry流量的比例,详细可以参考《FID: A Faster Image Distribution System for Docker Platform》2017 IEEE2nd International Workshops on FASW。
目前,GaiaStack在腾讯内部服务于所有BG,在公司外部,GaiaStack已经落地了多家标杆客户,比如建行、招行、数字广东、公安部等。除了作为独立的容器私有云产品之外,还和腾讯内的很多重量级平台一起对接出海,强强联合,比如专有云TCE,GaiaStack不但支持腾讯专有云TCE上六十多个基础产品,300多个应用,本身也是TCE的一个子产品,此外,GaiaStack还对接了微服务治理框架TSF,机器学习平台TiOne,虚拟机私有云Tstack等重要产品。

这篇关于腾讯容器云平台GaiaStack亮相kubeCon的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!