本文主要是介绍企业微信 web 项目工业级蜕变,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作者:chriscai,腾讯 WXG 前端开发工程师
企业微信 web 项目从以前的小而简单的 web 项目,历经五载,蜕变成了平台级的项目。这几年伴随着前端工业化和前端技术变革,本文将介绍我们如何在高速迭代当中,对大型 web 项目进行高效代码管理,架构升级,编译优化等,最后完成工程化的工业级蜕变。
一、背景介绍
企业微信
企业微信是为用户提供企业 IT 管理的产品。目前有两大业务体系:“连接微信”和“效率与办公”。企业微信具体业务涉及非常广泛,主要有几大功能:客户联系、家校沟通、日程、OA、会议等等。企业微信还存多行业(教育、金融、零售等)、多角色(超级管理员、分级管理员、应用负责人、普通成员)等复杂场景,形成了一套极其复杂的系统。
其中 web 涉及的业务最为广泛,整体可以划分为两块业务:
B 端业务,实现企业微信功能:
企业微信 web 管理端(企业管理端 及 服务商管理端、官网等)
OA(打卡、审批、汇报 及相关自定义配套系统)
企业微信客户端内置的功能:数十个小程序和数量繁多的 h5 页面
C 端业务, 主要在微信端作为入口跟 B 端用户联动:
复杂的功能,以小程序承载。会议小程序/班级作业小程序/电子工牌小程序等等
运营推广等业务以 H5 承载。
企业微信 Web 项目
企业微信 web 项目是 nodejs 版本 web server 项目,除了小程序外,前端代码和 nodejs 代码会放在同一个仓库里面,所以我们开发人员需要具备全栈开发能力。
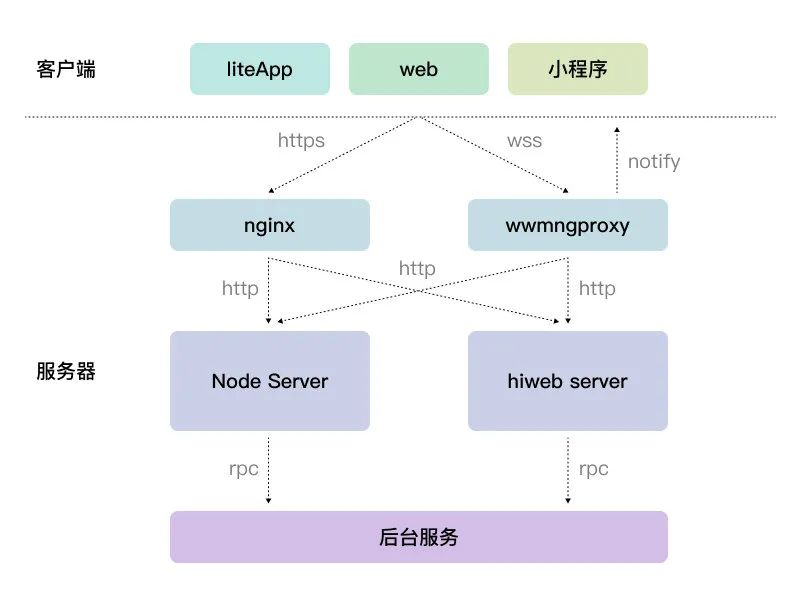
如上图,是我们企业微信 web 的全栈图 ,用户端以 liteApp/web/小程序呈现。以 https 或 wss 协议接入 ,接入层进行业务路径和负载均衡计算分发到不同的 web server ,web server 分成两块 :
node server 采用是 nodejs 实现的,由我们前端团队维护。
hiweb server 是由 c++实现的,由后台团队维护。
web server 以 RPC 方式调用后台服务。
面临挑战
随着业务不断的迭代和前端技术的变化,项目中包含了各样业务( 企业微信 web 管理端/独立的 h5 业务/oa 等)和各种技术栈(typescript/vue/jquery/backbone 等), 如此复杂的项目也给我们带来了不少挑战:
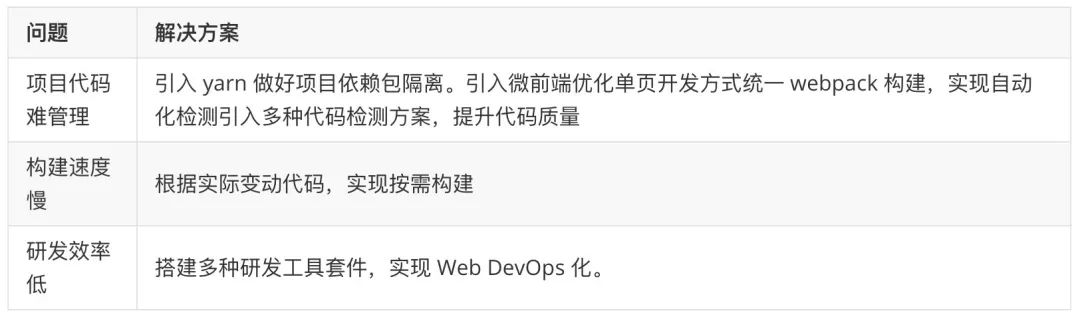
项目代码管理困难
构建速度缓慢
研发效率低下
我们从 2019 年开始关注 Monorepo 代码管理方式、微前端架构、DevOps 等一些列的前端工业化解决方案。结合我们业务特点和研发体系,我们开始了一条不平凡蜕变之路。
蜕变之路
蜕变之路漫漫其修远兮,我们制定了三个方向进行探索和实践:
代码高效管理
引入 Monorepo 思路,将代码仓库模块化管理,统一构建任务;引入微前端架构对大型单页进行功能隔离;增加多种方案提升代码质量的监控
大型项目构建优化
精确识别代码变化,按需构建,提升构建速度
Web DevOps 建设
建设持续的 CI/CD 能力,提高研发效率,提升持续交付的能力
二、代码高效管理
随着项目代码的不断增加,引入前端技术和类库越来越多,项目工程越来越难以驾驭。
我们通过重新规划项目目录结构、升级业务技术框架、统一化代码构建、完善代码质量控制等一系列措施,实现代码的高效管理。让项目保留引入新技术的可能性,并让业务代码继续保持高质量迭代。
1.Monorepo 管理
Monorepo(monolithic repository) 是管理项目代码的一个方式,一个项目仓库(repo) 中管理多个模块/包 (project)。
1.1 选择管理方式
在改造方向上,我们调研了两种前端项目的管理方式,分库管理和集中管理进行对比:
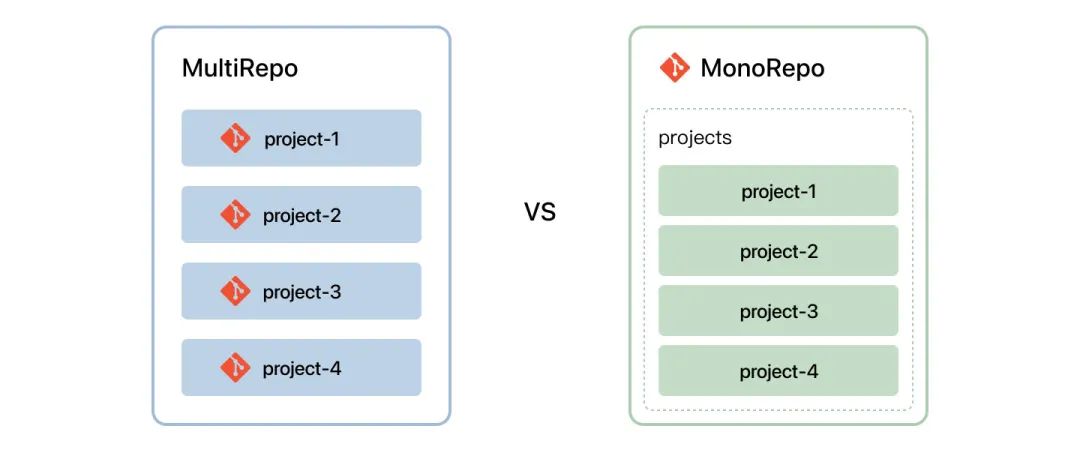

分库管理和集中管理各有优劣势,结合企业微信 web 项目特点。多个业务都是互相独立的,这些独立业务大部分会引用公共的业务组件,而且目前我们的项目已经积累了非常多的独立业务。
基于目前的现状和未来规划考虑,我们选择了 Monorepo 的管理方式。
1.2 如何改造
业内的开源项目大多基于 lerna+yarn 进行 Monorepo 管理。我们的基础库管理也是采用相同的方式,但是企业微信 web 项目没有发布 npm 需要,所以我们采用 yarn workspaces 的特性进行项目改造。下图为我们的改造前项目
├── public
| ├── 3rd_lib
| ├── lib
| ├── web-project
| | ├── common
| | ├── prg1
| | ├── prg2
| ├── assets
| | ├── style
| | ├── images
├── server
├── node_modules
├── package.json
项目架构已经划分比较合理了,但是随着业务安装 node_modules 越来越多,出现了组件版本混乱的局面。下图是我们使用 yarn workspaces 优化后的目录架构。
├── public
| ├── 3rd_lib
| ├── lib
| ├── web-project
| | ├── common
| | ├── prg1
| | | ├── node_modules // 有冲突,安装此目录下
| | | ├── package.json
| | ├── prg2
| | | ├── package.json
| | ├── node_modules // web-project 统一依赖
| | ├── yarn.lock // yarn 的依赖关系管理文件
| | ├── package.json
| ├── assets
| | ├── style
| | ├── images
├── server
├── node_modules
├── package.json
├── yarn.lock
改造的成本不高,首先在 web-project 新增 project.json ,并迁移前端所需要的依赖,其次增加下图的配置,即可让 web-project 变成 workspaces 。
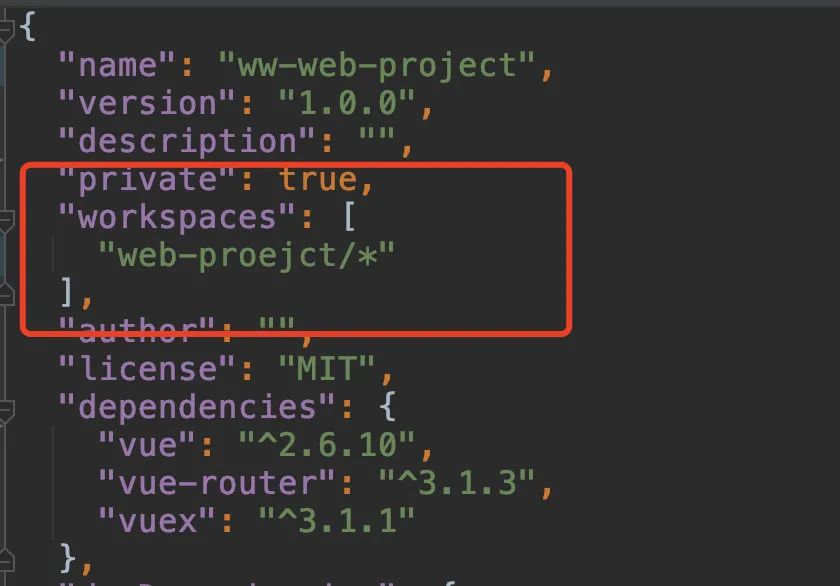
当在 web-project 下面执行 yarn install , yarn 会识别 workspaces 搜索对应的子目录,安装 node_modules,当多个项目有依赖版本不一致,会对应的安装在其子目录下面(如上图中的 prk1 中存在的 node_modules),否则所有的依赖关系都在 yarn.lock 这个文件里面。
2.微前端架构
微前端架构是一种类似于微服务的架构,它将微服务的理念应用于浏览器端,即将 Web 应用由单一的单体应用转变为多个小型前端应用聚合为一的应用。
对于企业微信管理端这种巨型单应用项目,路由配置多达 500 多条,技术栈多,是非常适合用微前端架构的。我们分析了业内对大型 web 项目架构方式:

singleSPA 虽然实现比较复杂,但是微前端架构领域比较成熟的框架,非常适合我们的场景。所以我们深入分析它的实现原理。

如上图是 singleSPA 的架构思想,类似加载一个异步 js 文件,但是这个异步 js 文件它有以下特点:
每个应用都是一个独立的单页应用,拥有完整的功能
应用生命周期接口标准化,可以实现与主框架的解耦
跟很多大型项目一样,我们的技术历史包袱重,直接引入新型框架的改造成本巨大。所以结合我们的技术特点和 singleSPA 的思想, 进行了微改造,达到无缝升级。我们分成了两个阶段进行改造升级:
新老模块加载兼容改造
子模块目录 Monorepo 化管理
2.1 新老应用加载器兼容改造
管理端的项目采用是 seajs +Backbone 搭建的单页架构。为了让我们的旧架构能适配新的子应用加载,我们通过文件的路径区分新老应用,如下图运行图:
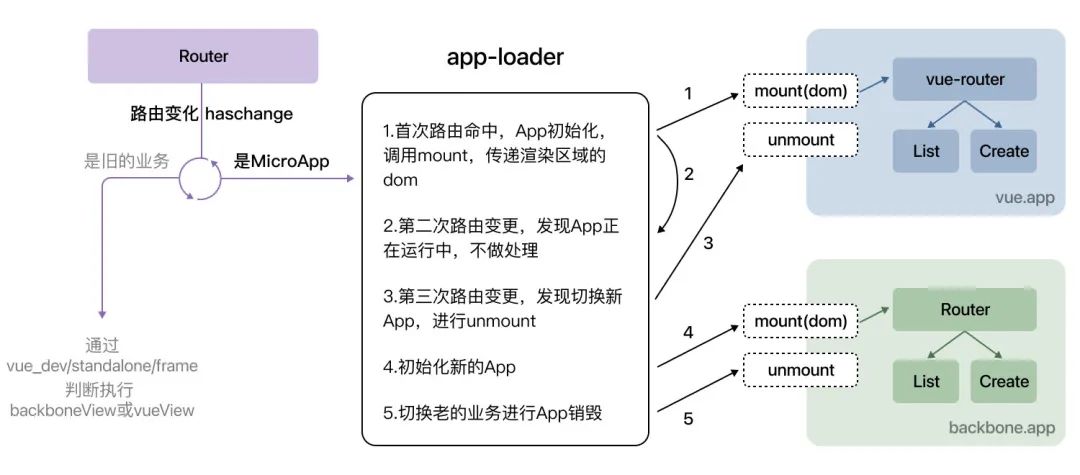
如果是新应用,则采用 app-loader 的方式驱动子应用。为了让新的子应用适配 seajs 加载且能引用主框架的代码,我们在子应用打包时候进行了 seajs 模块适配。如下图的 webpack 构建过程:
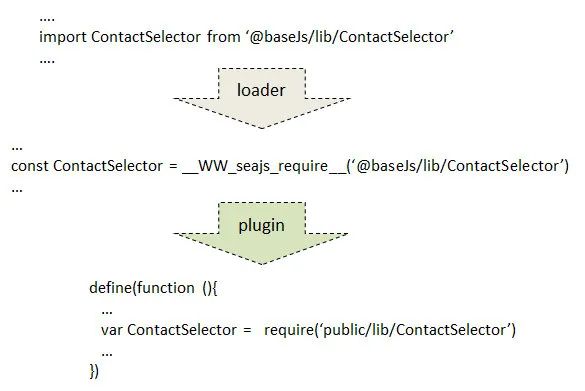
在 loader 过程,解析代码引用路径,若引用路径存在 @baseJs 的则转为 WW_seajs_require 绕开 webpack 后续解析。
在 plugin 阶段,将 __WW_seajs_require 转回为 require ,最后将生成的 bundle 进行 seajs 模块化处理,完成子应用的打包。
2.2 子应用 Monorepo 化管理
采用 singleSPA 思想,每个子功能都进行独立拆分部署会比较繁琐,所以我们针对这些中小型模块进行 Monorepo 化管理,让同一个工程也能实现微前端方式开发,如下代码:

在子应用的注册方式,我们采用类似 webpack entry 配置方式。在最后上线构建阶段, entry 会变成真正一个 CDN 地址。
针对大型子应用,我们采用的独立部署的方式,资源加载配置的是某个服务的绝对路径,如下:

3.统一构建管理
项目目录结构实现统一管理后,我们希望把 webpack 也统一起来,原因如下:
每个目录的 webpack 配置不一致
开发多个项目需要启动多个 webpack
为了让开发更方便的使用,进行了以下两个改造:
3.1 webpack entry 自动化引入
传统的 webpack 配置,需要人工配置 entry 入口实现构建。我们规范化了目录结构,每个项目目录必须提供 *.entry.js 结尾的文件。如下是优化后的目录结构:
├── public
| ├── web-project
| | ├── common
| | ├── prg1
| | | ├── index.entry.js // webpack 打包入口
| | ├── prg2
| | | ├── index.entry.js // webpack 打包入口
| | | ├── list.entry.js // webpack 打包入口
在 webpack 启动的时候,自动加载项目目录中 *.entry.js ,将其作为 webpack entry 配置,以此达到 entry 的动态化。如下代码:
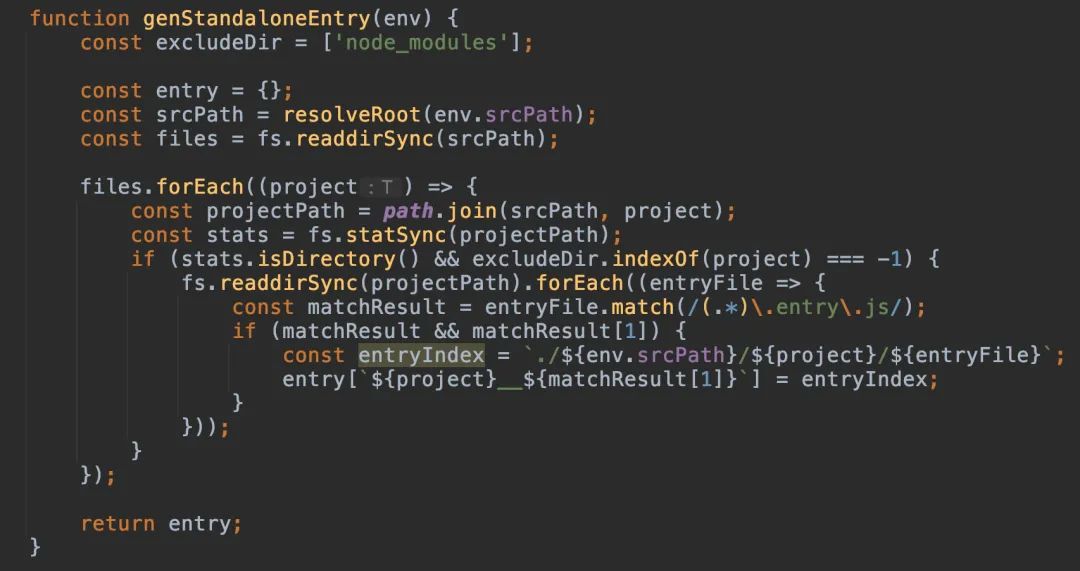
3.2 与 nodejs server 结合
实现了所有项目都统一 webpack 后, 我们就可以很轻松引入 webpack-dev-middleware,让本地启动 node server 即启动 webpack 编译。

4.代码质量控制
在编码阶段,目前我们采用 eslint + typescript ,提升我们编码质量。但是在测试或 MR 阶段,缺乏数据帮助我们衡量代码是有保证的,所以我们进行了三个方向探索:
4.1 方案一:单元测试
采用 mocha + karma 编写测试用例,但是实践中捉襟见肘。
1. 变化快的代码,不利于用单元测试
2. 不能高内聚的代码,不能使用单元测试
总体来说业务代码还是比较难使用单元测试的,而我们大部分做的就是业务代码,迭代速度快。但是针对于通用组件还是比较适用的,所以针对 UI 组件、基础组件,我们都有进行了单元测试处理。
4.2 方案二:代码覆盖率
引入代码覆盖率,使代码测试情况可以被衡量。我们在每个分支的变更文件进行代码覆盖率插装。在 MR 阶段也强制性将代码覆盖率标准纳入合并的检测条件之一。

这个限制不仅仅让合并代码单更加可控,而且也让开发更多参与到自测当中,提升交付质量。
4.3 方案三:依赖关系分析
当一个公用代码文件或组件发生变动的时候,会影响很多业务。而测试和开发在这种场景下面很难做出准确评估。
对于测试同学,只能覆盖一个入口。 验证一个业务入口覆盖率就能达标,无法发现还有其他业务受到影响
对于开发,评估成本高。 通过搜索代码引用,然后一层层递归寻找业务入口。
我们思考是否可以通过计算依赖关系,让测试和开发都能可视化衡量?
所以我们实现了基于 git MR 时候文件变更列表,从源头一路追溯到代码的起始点,配合代码头部的注释,生成影响面报表,帮助测试和开发更有效评估影响面,实现的大致思路:

在 MR 阶段,当检测到有公共代码变化的时候,会有拦截告知开发需要影响面评估:

开发同学点击触发生成报告,即可看到如下的流水线构建结果地址:

开发人员点开链接即可看到计算出来的列表和依赖链拓扑图,可以很清晰看到哪些代码受到了影响:


通过报告作出决策:
对于测试,可以通过列表描述查看是否符合测试用例,当发现超出用例范围外,反馈开发进行 review。
对于开发,通过列表和拓扑图排查影响到了哪些业务,针对性进行 review 和反馈给测试需要补充用例。
4.4 如何选择
综上的几个代码质量控制的方案,哪个方案都不是万金油,而是要根据不同的场景采用不同的方案:
基础组件, 采用方案一和方案二。质量可以得到严格保证,长期可维护性高,依赖开发同学编写测试用例。
业务开发,采用方案二和方案三。可以提升测试人员和 code review 效率,做到有数据衡量。
三、大型项目构建优化
随着业务代码不断增加,项目深度不断延伸,我们的构建时长也会因此不断增加。我们分别对本地开发构建和线上部署构建做了深入的构建优化。
1.本地开发构建优化
运行在 nodejs 上的 webpack 是单进程模型,编译如此多的 entry 文件是相当吃力的。针对大型项目场景, webpack 官方推荐优化方案 cache-loader +hard-source-webpack-plugin 和 thread-loader
| 耗时 | |
|---|---|
| 首次编译 | 96s |
| 引入 cache-loader + hard-source-webpack-plugin | 21s |
| 引入 thread loader | 19s |
引入缓存后效果比较明显,但是引入 thread-loader 效果不是很明显,我们查阅了官方的说明:
thread-loader 官方介绍: 放置在 thread-loader 之后的 loader 会在一个独立的 worker 池中运行。每个 worker 都是一个独立的 node.js 进程,其开销大约为 600ms 左右。同时会限制跨进程的数据交换。
从介绍可以看出,thread-loader 虽然提供了并发处理文件能力,但是多了进程通信开销。而我们的每个项目已经拆的足够简单,文件数量不多,所以 thread-loader 在这种场景下面效果不明显。
但是由于启动的 entry 非常多, webpack-dev-server 占用内存也非常高,当跑的比较久时候,内存会出现溢出造成主进程直接停掉,如下:
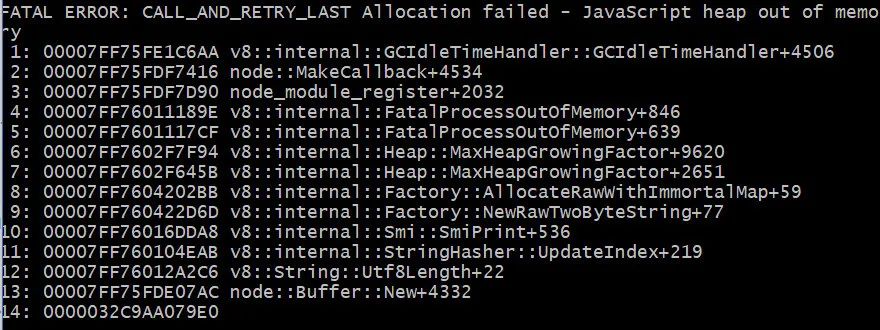
我们思考优化的手段是如何减少 entry 列表。考虑我们的项目特点,每个开发同学同时开发几个项目的情况一般是 1- 4 个。我们思考是不是可以根据资源请求动态生成 entry 列表?
但是深入研究发现,webpack 是不支持 entry 动态化的。所以我们转为为每个 entry 生成一个独立的 webpack 进程的思路。如下图的思路:
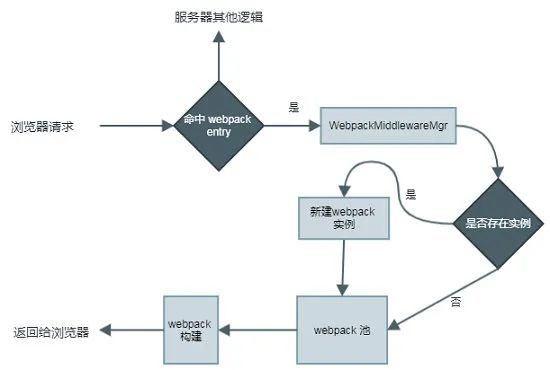
当有资源请求,会根据 entry 路径,在进程池中寻找对应的 webpack 实例,如果没有则进行初始化,如下图代码:

当然也需要为每个 webpack 实例配置独立的持久化缓存路径,避免后续再启动的时候被其他进程覆盖。

如此一来,我们的整套 webpack 构建流程就能实现了真正的按需构建。优化过后的效果对比:
| 耗时 | |
|---|---|
| 首次编译 | 13s |
| 引入 cache-loader + hard-source-webpack-plugin | 3s |
现在 webpack 5 已经将 hard-source-webpack-plugin 作为了内置的功能,配置更加简单。
2.部署构建优化

上图为我们的构建流程,构建任务我们是采用 gulp 编写的构建任务,最后将构建结果 rsync 编译机器上。
每次的构建会运行在 docker ,而优化所需要的 cache 每次都需要拉取和归档,随着项目越来越大,cache 越来越大,拉取和归档平均耗时超过了 5 分钟。
我们项目是一个全栈的项目结构,代码类型比较多,如下图:
├── public
| ├── 3rd_lib
| ├── web-project
| | ├── common
| | ├── pkg1
| | ├── pkg2
| ├── assets
| | ├── style
| | ├── images
├── server
| ├── common
| ├── controller
所以我们基于每次 git push 代码变更列表,对代码类型分类和处理,编排出具体的构建任务,最后并行处理多任务,如下图:
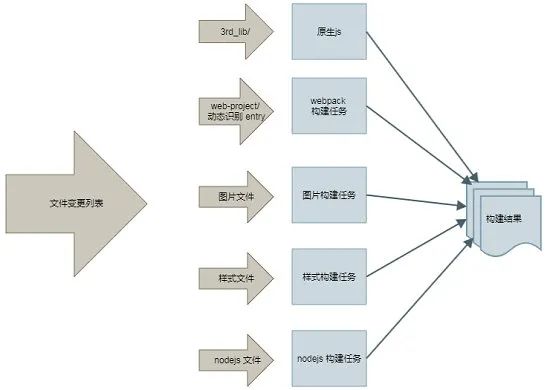
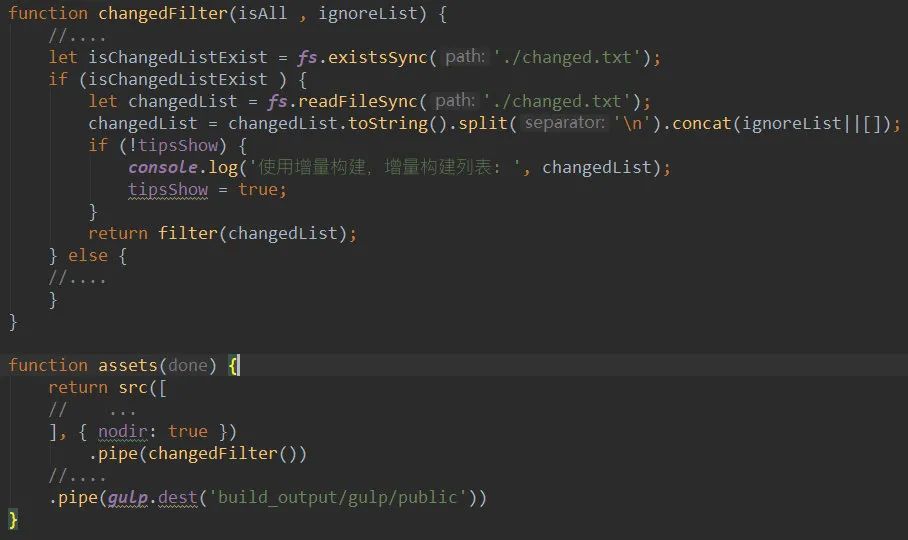
每个 gulp 在运行的时候,会加载 changed.txt (CI 平台注入变更列表)用于过滤哪些是变化的代码,然后进行 pipe 构建,最后输入到构建结果目录。
构建任务完成后,统一将 build_output rsync 到编译机器。
通过优化后的效果对比:
| 耗时 | |
|---|---|
| 优化前 | 9 分钟 |
| 优化后 | 2 分钟 |
测试和产品再也不会追着我问,构建好了吗 ?
Web DevOps 建设
伴随的项目团队成员越来越多和项目复杂度的增加,频繁成员间沟通和缺少配套自动化工具,阻碍了项目的高速迭代。搭建我们自己的 Web DevOps 迫在眉睫。
1.DevOps 流程
伴随着腾讯的 DevOps 工具越来越丰富,我们基于自身项目特点和运营体系,形成了自己的 Web DevOps 最佳实践,如下图:

每个需求都需要从 master 拉取分支 feature 。每个 feature 测试和体验都会在 feature docker 里面闭环。当 feature 完成后,发起合 master , 然后团队的 teach leader(类似架构师)会对你的代码进行 Code Review ,并提出意见, 直到评审没有问题后即可合入 master 并进行部署上线。
2.我们的研发套件
除了前面提到的研发流程外,我们还有很多的辅助的配套研发套件,帮助开发人员提升效率
Freego
传统的 web 项目需要体验都需要配置本地 host ,特别对于产品和测试童靴来说,每次切换不同功能体验成本都很高。
我们所有项目都会经过 nginx 进行分发到不同的 web server ,所以我们提出了基于 cookie 识别的环境分发的概念 ------ Freego (一键切换 docker 环境),如下图的流程图:
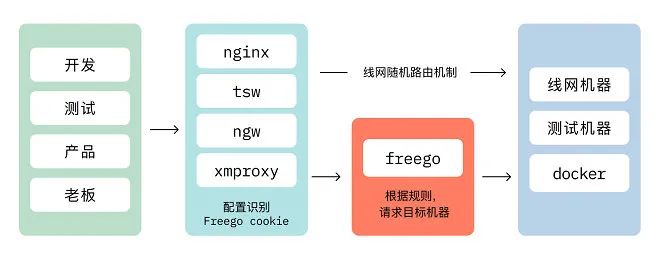
当产品或测试需要访问哪个 feature docker 时候,即可在网页进行一键切换,如下图:
Design-Compare
我们基于 Resemble.js 开发了一个让视觉稿和页面截图对比的分析工具,让开发者可以快速识别还原程度。但是对于时间比较紧的需求,后续再来处理视觉还原问题会耗费不少功夫。
我们的研发模式是在页面的设计稿工具(figma)中查看视觉,然后在 chrome 开发者工具进行开发。我们思考能否让两者结合在一起?在开发时候就能对比出实现有问题。
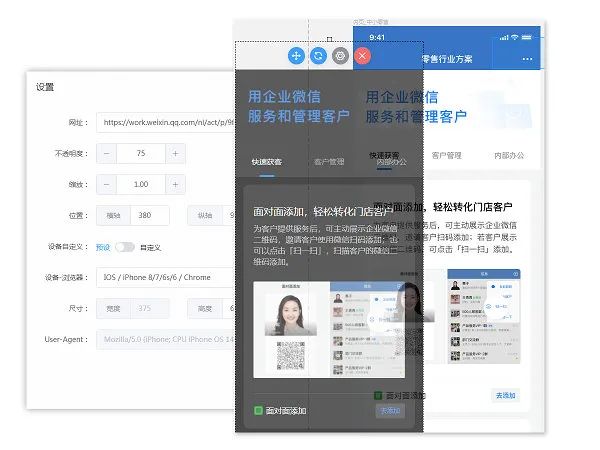
所以我们开发了一个 chrome 插件,可以注入类似 chrome 开发者调试工具,实现边写代码边对比视觉稿,如下图的效果图:
低码平台
我们内部有两种低码平台:
组件化页面。适合页面比较固化的,可以让产品拖拖拽生成页面。
资源管理页面。适合页面图片/文字比较多,提供页面编辑器让产品可以编辑图片和文字。
组件化页面
页面相对比较固化,平台提供多种组件,让产品可以让拖拖拽拽就能组成页面
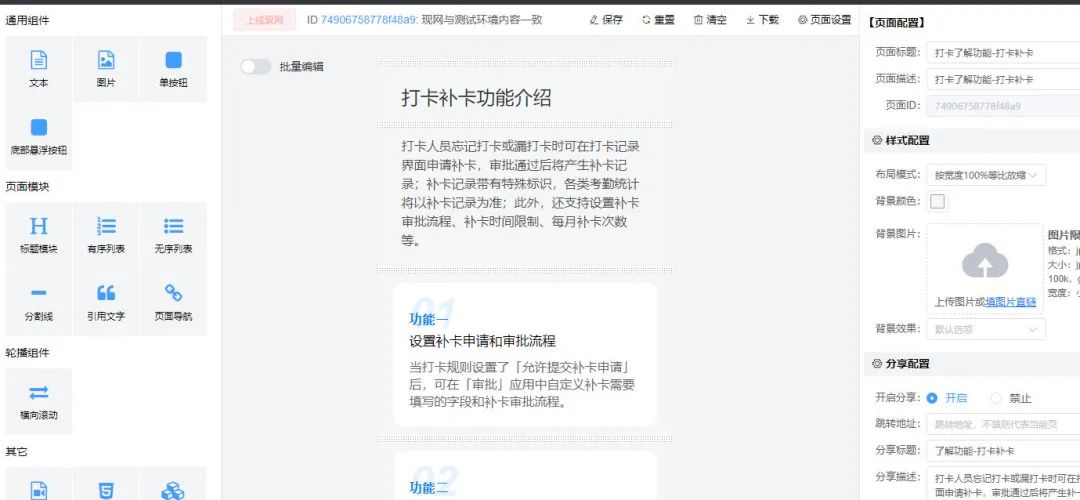
实现的思路是配置完成页面后,页面由 json schema 描述并进行存储,当用户真正请求页面时候才组装成页面。
资源页面
页面需要开发进行开发,但是图片和文字特别多,产品和设计经常会变更图片或则文字。如下图

针对这种页面,开发同学在开发的时候文字和图片将采用资源文件进行编写,如下图:
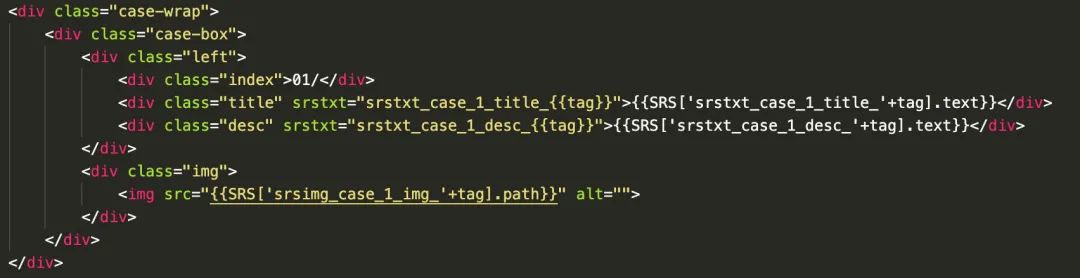

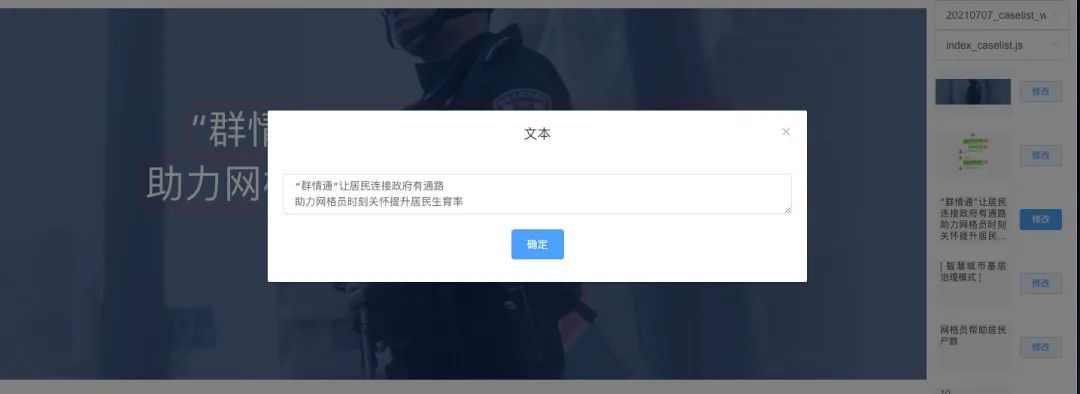
我们提供 chrome 插件可以识别这种类型的页面,让页面中的文字和图片变成可编辑和替换,就犹豫在在富文本编辑器一样,产品可以自由编辑和替换,最后保存发布到 git 仓库里面。
回顾&展望
前端的技术变革比较快,每次变革都会带来一次不同的体验,我们在不同的阶段去探索不同的技术,用新的技术逐步解决项目问题:
现在随着前端工具配套越来越成熟,前端团队关注点不再为页面性能问题、浏览器兼容性等问题耗费精力,而是更为关注产业规模、产品能力。
我们依然保持初心,不断探索新的技术和新的领域,接下来列举一下我们团队未来一些重点探索方向:
低码。企业微信今年致力让更多的企业融入我们的生态。
跨端开发。小程序/移动端/h5 ,多端一体化的开发方式探索。
no webpack 。随着越来越多的浏览器支持 es-module ,我们可以不再启动又重又大的 webpack ,让本地开发速度快。
serverless 。这个领域已经有很多前端团队探索,在开发方式上可以让开发者不再关注服务端运维,转而更加的专注业务。
>>华丽的广告位<<
企业微信前端团队,担负着企业微信复杂的各类前端业务。技术施展空间大,场景丰富,行业竞争激烈,也重视研发效率,技术氛围,是不错的个人成长之地。企业微信团队同时还招聘优秀的后台,客户端和产品等人才,岗位分布成都、广州、深圳。
可在 hr.tencent.com 搜索企业微信相关岗位.
最近热文:
为什么都开始搞研发效能?
主流图嵌入模型的原理和应用
腾讯程序员视频号最新视频
这篇关于企业微信 web 项目工业级蜕变的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







