本文主要是介绍阅读笔记(ICIP2023)Rectangular-Output Image Stitching,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
“矩形输出”图像拼接
Zhou, H., Zhu, Y., Lv, X., Liu, Q., & Zhang, S. (2023, October). Rectangular-Output Image Stitching. In 2023 IEEE International Conference on Image Processing (ICIP) (pp. 2800-2804). IEEE.
0. 摘要
图像拼接的目的是将两幅视场重叠的图像进行拼接,以扩大视场(FoV)。 然而,现有的拼接方法拼接的图像不规则,需要进行矩形化处理,耗时且容易出现不自然的现象。 本文提出了第一个端到端框架--矩形输出深度图像拼接网络(RDISNet),该框架可以将两幅图像直接拼接成一幅标准的矩形图像,同时学习图像对之间的颜色一致性并保持内容的真实性。 为了进一步保留拼接图像中大对象的结构,我们设计了一个扩张的BN-RCU块来扩展RDISNet的感受野,以提取丰富的空间上下文。 在此基础上,设计了一种新的数据合成流水线,构建了第一个矩形输出的深度图像拼接数据集(RDIS-D),实现了图像拼接与矩形化的连接。 实验结果表明,RDISNet的求解质量明显优于对比已有的求解方法。
1. 引言
图像拼接的目的是通过拼接多个具有重叠区域的图像来扩展原始视场(FoV)[1, 2, 3]。然而,将拼接结果应用于其他图像处理任务是困难的,因为结果中缺失的区域对网络特征的识别和梯度的计算有严重影响。因此,现有方法通常使用矩形化方法[4, 5]进行图像后处理,如图1所示,这是既耗时又劳神的。此外,传统的矩形化方法,如裁剪、合成[6, 7]和变形[4],无法达到保留图像内容和真实性的目的。Nie等人提出的最新深度学习方法[5]可以维持线性和非线性结构,但他们使用深度学习模型强行学习初始网格,这导致了网格之间的像素错位和更大尺度上的直线结构畸变。
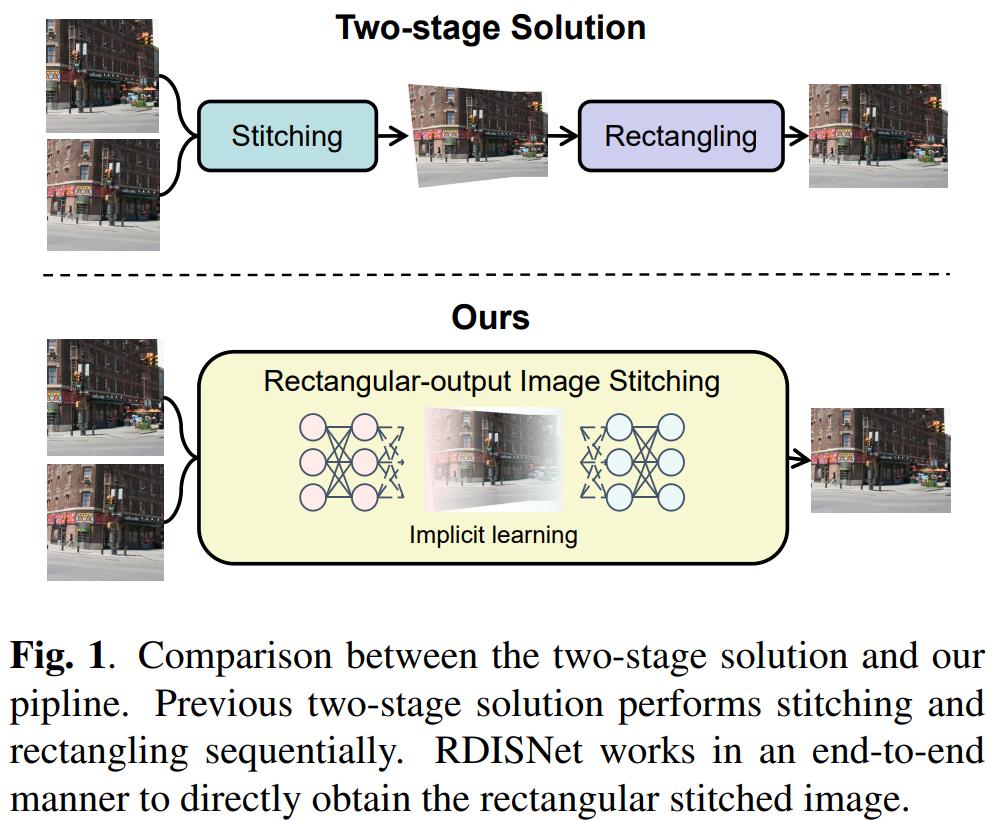
另一方面,缺乏高质量图像拼接数据集限制了现有基于学习方法的性能[8, 9]。Dai等人[10]使用现有的拼接方法创建伪真实标签(pseudo-GT labels),但这样的图像质量受到拼接方法性能的限制。Song等人[11]在GARLA上模拟真实场景,但对真实世界图像的影响有限。Nie等人[12]使用随机几何变换从自然图像中裁剪子图像作为输入和真实标签对,实现了作为自然存在图像的真实标签,但这无法涵盖自然图像的丰富内容信息。图像拼接中的另一个大挑战是在图像对的重叠区域保持颜色一致性。现有方法[13, 14, 15]通常设计特殊算法或模型来实现全局颜色优化,这增加了拼接方法的复杂性。在本文中,我们提出了一个新的任务,称为矩形输出图像拼接,旨在直接将两幅图像拼接成一个标准的矩形图像,同时保持颜色一致性和真实性。为了解决这些问题,我们设计了一个矩形输出深度图像拼接网络(RDISNet),这是第一次尝试以端到端的方式而不是两阶段设计来解决将图像拼接成矩形输出的问题。为了进一步保持拼接图像中大型物体的结构特征,我们设计了一个扩张的BN-RCU模块来扩展RDISNet的感受野。此外,我们设计了一个新的数据合成流程,并构建了第一个矩形输出深度图像拼接数据集(RDIS-D),包含52000个图像对。我们的贡献总结如下:
- 我们提出了一个矩形输出深度图像拼接网络(RDISNet),这是第一次将图像拼接和矩形化统一为一个端到端的过程,同时学习图像对之间的颜色一致性。
- 我们设计了一个扩张的BN-RCU模块来增加RDISNet的感受野,并保持大型物体的结构特征。
- 我们设计了一个新的数据合成流程,并构建了一个矩形输出深度图像拼接数据集(RDISD),包含52000个图像对。
2. 相关工作
这篇关于阅读笔记(ICIP2023)Rectangular-Output Image Stitching的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







