本文主要是介绍JPEG to PDF V3.7 汉化版,tek2y原创汉化!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载请注明出处,谢谢合作!首发于http://blog.csdn.net/tek2y
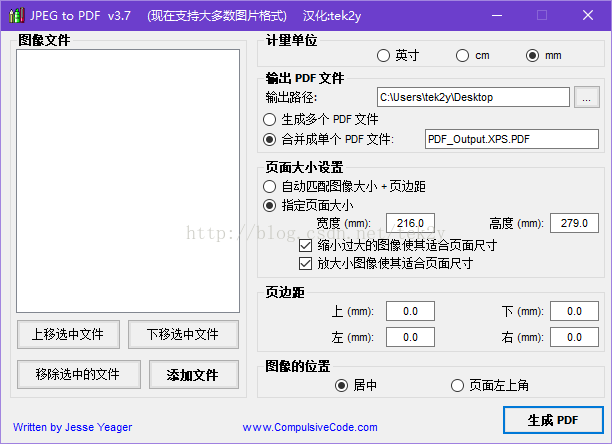
5年前,因为工作关系,本人需要将不少纸质文档扫描,并制作成PDF文件以便存档,于是本人就开始寻找能将图片批量转换成PDF文件的工具,经过一番寻找,发现了JPEG to PDF这个神器,支持多种图片格式,免安装,体积小巧,操作简单,转换速度快,功能单一却强大,而且是免费的,比那些动辄要几十块钱注册费转换速度却慢的要死的共享软件好太多了。
不过美中不足的是这款软件只有英文版,不熟悉英语的人使用起来会有些许不方便,于是本人决定自己动手将其汉化,经过一番折腾,终于是把JPEG to PDF给完全汉化了。
把JPEG to PDF汉化后,本人只是将汉化后的版本分发给朋友和同事使用,并没有在网络上分享出来,现在想想,好东西应该分享给大家,所以现在把本人亲手汉化的JPEG to PDF分享出来,供有同样需求的朋友使用,也算是回馈社会吧,哈哈哈!
如果您在使用过程中发现翻译错误或未完全翻译的情况,希望您能登录我的主页给我留言
这篇关于JPEG to PDF V3.7 汉化版,tek2y原创汉化!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







