本文主要是介绍关于Count,FPKM,TPM,RPKM等表达量的计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:关于Count,FPKM,TPM,RPKM等表达量的计算及转换 | 干货
写在前面
今天使用count值转化TPM,或是使用FPKM转换成TPM。这样的教程,我们在前面已经出国一起相对比较详细的教程了,一文了解Count、FPKM、RPKM、TPM | 相互间的转化,在这个教程中,我们也归纳了各个数值的含义。但是,也许你看到后,会添加到自己的收藏夹中,但是,后面就没有看了。自己也是这样的,一个人的时间和精力是有限的,我们不可能有那么多的精力。因此,做学习笔记就有很大的帮助,当自己使用的时候有地方找寻。


本教程涉及的数据、代码和文件等在社群中可获得!!
回顾一下知识点
Count
**定义:**高通量测序中比对到exon上的reads数。可以使用featureCounts、HTseq-count等软件进行计算。
**优点:**可以有效说明该区域是否真的有表达及真实的表达丰度。能够近似呈现真实的表达情况。
**缺点:**由于exon长度不同,难以进行不同exon丰度比较;由于测序总数不同,难以对不同测序样本间比较。
FPKM
FPKM: FPKM的全称为Fragments Per Kilobase Million,Fragments Per Kilobase of exon model per Million mapped fragments(每千个碱基的转录每百万映射读取的fragments)。通俗讲,把比对到的某个基因的Fragment数目,除以基因的长度,其比值再除以所有基因的总长度。注意,这里的基因长度是指基因外显子的总长度。
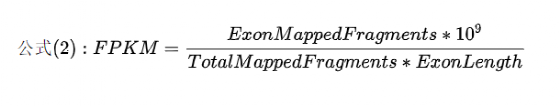
RPKM
RPKM: Reads Per Kilobase of exon model per Million mapped reads (每千个碱基的转录每百万映射读取的reads);

FPKM与RPKM的区别
RPKM通常用于单端测序,FPKM常用于双端测序

如果是单端测序,那么一个fragmetns就对应了一条read,如下所示:

如果是双端测序,那么一条fragments就对应两条reads,当然,有时候双端测序也有可能出现一条fragment对应一条read(另外一条read有可能会因为质量低而被剔除),FPKM就保证了,一条fragment的两条reads不会被统计2次,如下所示:

FPKM是以fragment为准,而不是以reads数为准,它们的计算方式是一样的。
RPM
**定义:**RPM/CPM: Reads/Counts of exon model per Million mapped reads (每百万映射读取的reads)
**公式:**RPM = ExonMappedReads * 10^6 /TotalMappedReads
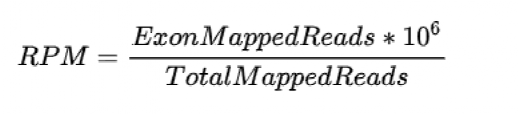
**优点:**利于进行样本间比较。根据比对到基因组上的总reads count,进行标准化。即:不论比对到基因组上的总reads count是多少,都将总reads count标准化为10^6。sRNA_seq等测序长度较短的高通量测序经常采用RPM进行标准化,因为sRNA长度差异较小,18-35 nt较多,所以长度对不同的small RNAs相互比较影响较小 (优点:计算简单、方便。)
缺点:未消除exon长度造成的表达差异,难以进行样本内exon差异表达的比较。
TPM
**定义:**TPM的全称为Transcripts per million,Transcripts Per Kilobase of exon model per Million mapped reads (每千个碱基的转录每百万映射读取的Transcripts)。
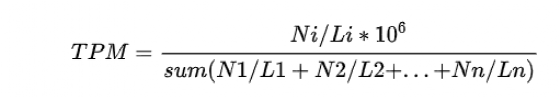
解释: Ni为比对到第i个exon的reads数;Li为第i个exon的长度;sum(N1/L1+N2/L2 + … + Nn/Ln)为所有 (n个)exon按长度进行标准化之后数值的和。
如何准换呢??
方法一
使用GenomicFeature包导入对应的gtf文件或gff文件,获得基因外显子长度。
**优点:**方便,快捷。
**缺点:**对与gtf或gff文件的要求比较高,我自己使用stringtie组装的注释文件,是无法获得导入的。此外,这个方法只能获得是gene的表达量,若你想获得transcript的表达量,自己未成功。
library(GenomicFeatures)
## 导入gff3文件
txdb <- makeTxDbFromGFF("ITAG4.1_gene_models.gff", format = "gff")
## 获取外显子位置
exons_gene <- exonsBy(txdb, by = "gene")
## 去除外显子重叠部分,计算外显子长度
exons_gene_len <- lapply(exons_gene,function(x){sum(width(reduce(x)))})
exons_gene_len <- as.matrix(t(exons_gene_len))
write.csv(exons_gene_len,"tomato_gene_length_4.1.csv", row.names = T)
countToTpm <- function(counts, effLen)
{
rate <- log(counts) - log(effLen)
denom <- log(sum(exp(rate)))
exp(rate - denom + log(1e6))
}countToFpkm <- function(counts, effLen)
{
N <- sum(counts)
exp( log(counts) + log(1e9) - log(effLen) - log(N) )
}fpkmToTpm <- function(fpkm)
{
exp(log(fpkm) - log(sum(fpkm)) + log(1e6))
}countToEffCounts <- function(counts, len, effLen)
{
counts * (len / effLen)
}# An example
################################################################################
cnts <- c(4250, 3300, 200, 1750, 50, 0)
lens <- c(900, 1020, 2000, 770, 3000, 1777)
countDf <- data.frame(count = cnts, length = lens)# assume a mean(FLD) = 203.7
countDf$effLength <- countDf$length - 203.7 + 1
countDf$tpm <- with(countDf, countToTpm(count, effLength))
countDf$fpkm <- with(countDf, countToFpkm(count, effLength))
with(countDf, all.equal(tpm, fpkmToTpm(fpkm)))
countDf$effCounts <- with(countDf, countToEffCounts(count, length, effLength))
方法二
使用featureCount等计算出Count值,获得结果中就有对应的外显子长度,因此,你可以直接使用其进行转化。
- 导入数据
##
count_df <- read.csv("count.csv",header = T, row.names = 1)
dim(count_df)
names(count_df)

##'@提取Count值
expr_df <- count_df[,2:ncol(count_df)]
head(expr_df)
###'@基因表达量之和大于0
expr_df <- expr_df[rowSums(expr_df) > 0,]
dim(expr_df)
##'@保存count值矩阵
write.csv(expr_df,"过滤后_count.csv")
计算TPM
##'@计算的TPM
##'@提取基因长度,基因长度需要转化成kb
gene_length_kb <- count_df$Length / 1000
head(gene_length_kb)### 每千碱基reads(per million scaling factor)长度标准化
data_rpk <- expr_df /gene_length_kb
##'@每百万
TPM <- t(t(data_rpk) / colSums(data_rpk) * 1000000)
head(TPM)
## 求均值
avg_tmp <- data.frame(avg_tmp = rowMeans(TPM))
head(avg_tmp)
##'@保存数据
write.csv(TPM,"Tomato_TPM.csv")
计算FPKM
FPKM <- t(t(data_rpk) / colSums(expr_df) * 10^6)
##'@保存数据
write.csv(TPM,"Tomato_FPKM.csv")
参考:
- https://mp.weixin.qq.com/s/JOVYGh7pO8SiW-9iIeMO6Q
- https://www.jianshu.com/p/aec488f358d2
- https://www.jianshu.com/p/6b6bb306b76e
- https://www.bioinfo-scrounger.com/archives/407/
方法三
我们直接使用的perl脚本进行转化,很是方便。
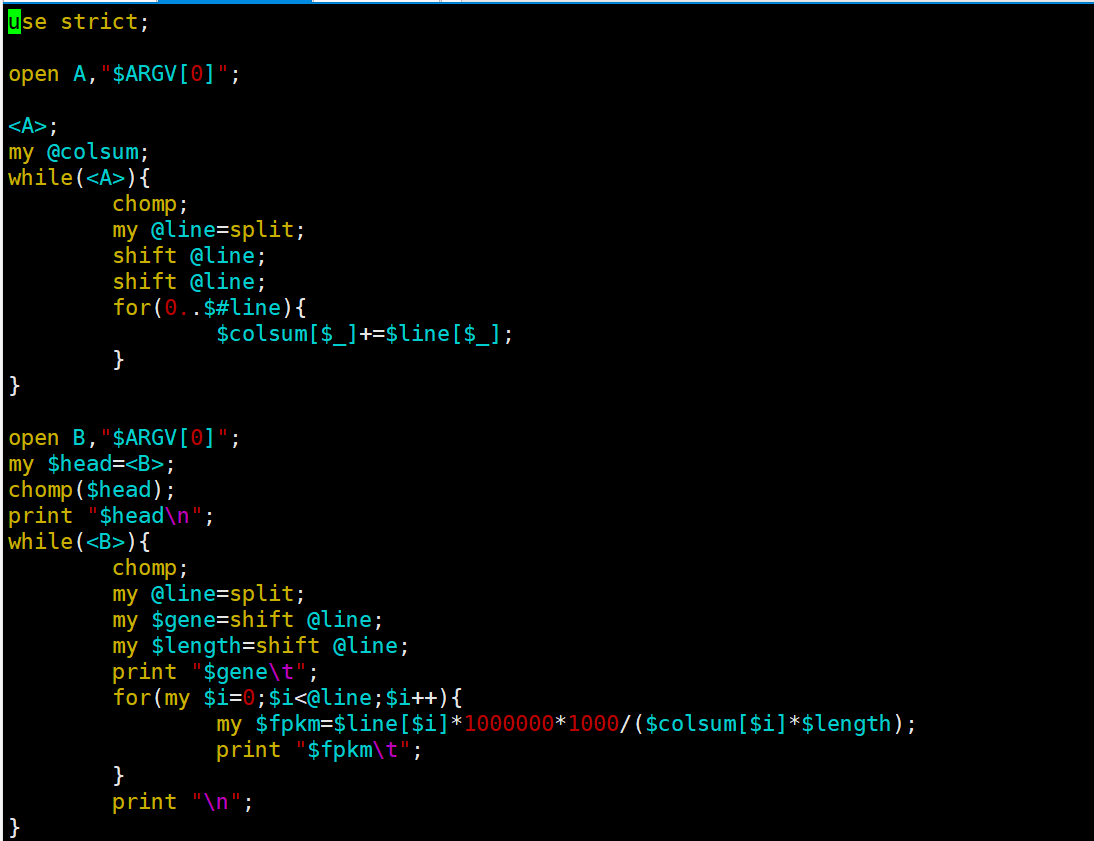
perl CountToFPKM.pl Count.txt > FPKM.txt
原文链接:关于Count,FPKM,TPM,RPKM等表达量的计算及转换 | 干货
代码和数据链接:
本教程涉及的数据、代码和文件等在社群中可获得!!
若我们的分享对你有用,希望您可以点赞+收藏+转发,这是对小杜最大的支持。
往期文章:
1. 复现SCI文章系列专栏
2. 《生信知识库订阅须知》,同步更新,易于搜索与管理。
3. 最全WGCNA教程(替换数据即可出全部结果与图形)
-
WGCNA分析 | 全流程分析代码 | 代码一
-
WGCNA分析 | 全流程分析代码 | 代码二
-
WGCNA分析 | 全流程代码分享 | 代码三
-
WGCNA分析 | 全流程分析代码 | 代码四
-
WGCNA分析 | 全流程分析代码 | 代码五(最新版本)
4. 精美图形绘制教程
- 精美图形绘制教程
5. 转录组分析教程
转录组上游分析教程[零基础]
一个转录组上游分析流程 | Hisat2-Stringtie
小杜的生信筆記 ,主要发表或收录生物信息学的教程,以及基于R的分析和可视化(包括数据分析,图形绘制等);分享感兴趣的文献和学习资料!!
这篇关于关于Count,FPKM,TPM,RPKM等表达量的计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






