本文主要是介绍Hive SQL必刷练习题:留存率问题(*****),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
留存率:
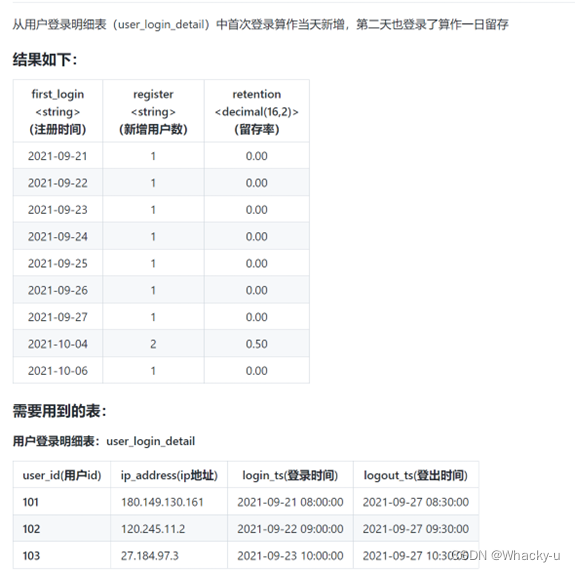
首次登录算作当天新增,第二天也登录了算作一日留存。可以理解为,在10月1号登陆了。在10月2号也登陆了,那这个人就可以算是在1号留存
今日留存率 = (今日登录且明天也登录的用户数) / 今日登录的总用户数 * 100%
解决思路:
这类问题主要借助left join,根据原表的数据,先去找到每个用户最先登录的时间,这个就是通过对用户group by,然后搜索date_format(min(login_ts),‘yyyy-MM-dd’)。这样就得到一个表,第一列是用户id,第二列就是每一个用户第一次登录的日期。
之后用这个新表,left join原表数据,但是这个条件不仅是id相等,还要有个t1.user_id=t2.user_id and datediff(date_format(t2.login_ts,‘yyyy-MM-dd’),t1.first_login)=1
说实话,这个多条件join的还确实没遇到过。这样符合条件的就会被增加到后面,不符合的赋空值。【当然也可以不多条件join,直接就是两个表的user_id一样,那这样再计算新增人数和留存人数的时候,就不能直接通过count(列名字)来计算了,还需要去重和判断天数关系】比如下图这样

这样就可以根据first_login分组group by计算count(t1.id),就是每日新增人数,然后count(连接上的表的列信息),就是后续一天也登陆的人数。
代码:
selectt3.first_login,t3.register,t3.remain_1/t3.register retention
from(selectt1.first_login,count(t1.user_id) register,count(t2.user_id) remain_1from(selectuser_id,date_format(min(login_ts),'yyyy-MM-dd') first_loginfromuser_login_detailgroup byuser_id)t1left joinuser_login_detail t2ont1.user_id=t2.user_id and datediff(date_format(t2.login_ts,'yyyy-MM-dd'),t1.first_login)=1group byt1.first_login
)t3总结一下:
其实这类问题的关键在于,你要想办法将每个用户的最初登录时间和第二天登录时间这两个信息,放到一行中。这就是先求出来初次登陆时间后,然后借助这个表进行left join,之后再此基础上以最初登录时间进行分组group by,再用聚合函数即可。
但是还有一种思路,就是直接进行开窗排序,然后用row_number排序,找到前两名的日期,这个用where筛选,并且在查询条件里面用max,和min聚合函数可以找到首日和第二日,第一个日期就是首日,第二个就是第二次登录日期,只要看这个第二次登录日期是不是首日的第二天就行
上代码:
SELECTconcat(round(sum(if(datediff(f2, f1) = 1, 1, 0)) / count(*) * 100, 1), '%') percentage -- 注意round保留一位小数的用法
from(
selectuser_id,min(create_date) f1,max(create_date) f2from(
SELECTuser_id,create_date,row_number() over(partition by user_id order by create_date) num
from(selectuser_id,create_dateFROM order_infogroup by user_id,create_date
)t1)t2where num<=2group by user_id
)t3
这篇关于Hive SQL必刷练习题:留存率问题(*****)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






