本文主要是介绍如何在Ubuntu使用宝塔面板搭建hadsky轻论坛并发布到公网可随时访问,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 推荐
- 前言
- 1. 网站搭建
- 1.1 网页下载和安装
- 1.2 网页测试
- 1.3 cpolar的安装和注册
- 2. 本地网页发布
- 2.1 Cpolar临时数据隧道
- 2.2 Cpolar稳定隧道(云端设置)
- 2.3 Cpolar稳定隧道(本地设置)
- 2.4 公网访问测试
- 总结
推荐
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击跳转到网站】
前言
经过多年的基础设施建设和科技发展,网络已经成为我们生活中不可缺少的“必需品”。在大部分情况下,我们都可以在网络上找到需要的信息,并且能够通过特定方式(如论坛、留言、评论等)与众网友们交换意见和见解。不过,在别人的地盘呆久了,总会有自己建立交互空间吸引大家来畅聊的想法。今天,笔者就为大家介绍,如何在自家电脑的ubuntu系统上,建立轻量化的HadSky论坛,并让其能够为大家所访问( 注意:面向公共的论坛网站,必须向当地监管部门申请备案!)。
1. 网站搭建
HadSky是一款开源的PHP轻论坛系统,依托常用的php和MySQL运行。由于其轻量化的特点,因此即便服务器设备性能不高,也能轻松运行。对于笔者这样将退居二线的过时电脑,是很合适的选择。现在,就让我们开始吧。
1.1 网页下载和安装
HadSky作为一款有一定知名度的软件,自然有自己的官网(www.hadsky.com),我们可以在这里找到hadsky网站程序的下载,也能看到hadsky网站的安装要求和问题解答。
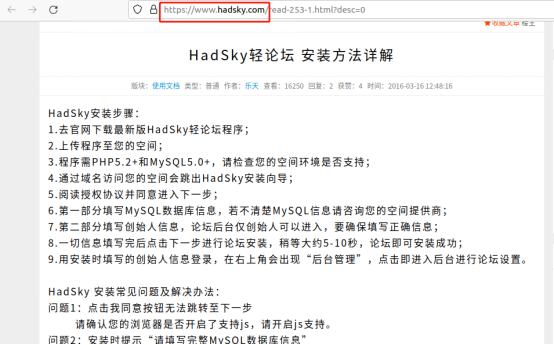
根据安装要求,我们需要在本地ubuntu系统上安装PHP5.2和MySQL5.0,当然Apache(或Nginx)也是必不可少的。为了方便起见,笔者在ubuntu系统上安装了宝塔面板,方便快速安装和设置网站运行所需的各种程序。
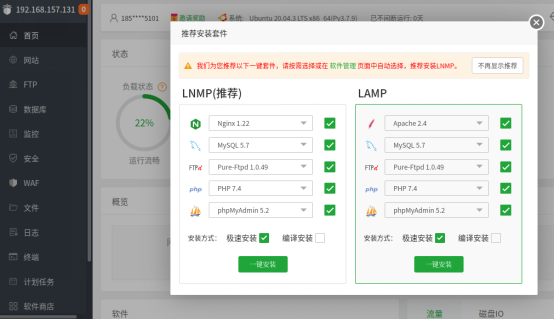
我们也可以在宝塔面板的主页(可以在浏览器中输入本地地址:宝塔面板输出端口号)左侧,找到“软件商店”按钮,点击进入软件商店页面。在这个页面,我们可以找到常用的网站运行支持程序,包括Nginx、Apache、MySQL、PHP、phpMyadmin、Tomcat、Docker管理器、Redis等等。我们找到所需的软件,点击该软件条目右侧的“安装”,即可将其安装至ubuntu系统上。
依照hadsky官方给出的安装要求,我们需要使用PHP5.2+和MySQL5.0+,我们可以在这里选择对应PHP版本安装即可。
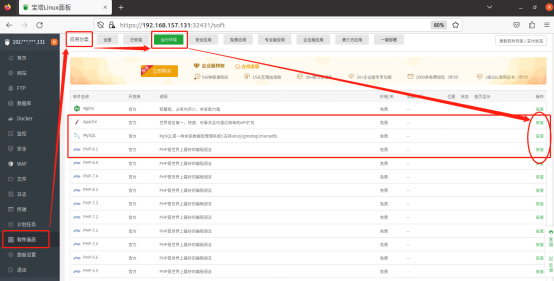
完成Apache、MySQL、PHP几项软件的安装后,我们可以点击软件商店页面上方的“已安装”按钮,查看已经安装的软件。同时,也可以在这里切换每个软件的版本。
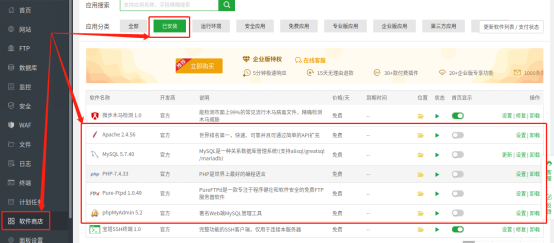
接着,我们就可以进行下一步的hadsky网站部署。通常网站部署的步骤是将下载的网站源代码,放置到宝塔面板的wwwroot文件夹下,不过好在hadsky在宝塔面板中提供了“一键部署”模式,又为笔者省了不少事。
点击宝塔面板主界面左侧的“软件商店”。进入软件商店后,在页面上方找到“一键部署”按钮,进入可以一键部署的网站分页,从中选取“hadsky”条目,点击该条目右侧的“一键部署”按钮,
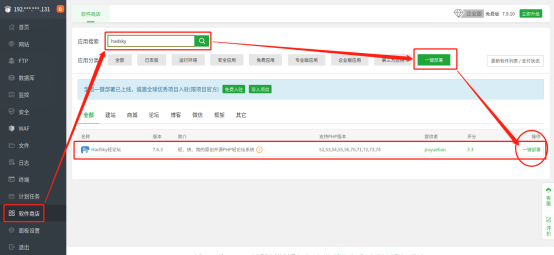
接下来会弹出网站基本设置窗口,在这里我们可以指定网站的基本信息,这些信息包括:
输出端口号 - 在“域名”栏位,通过“打算设置的域名:打算使用的端口”形式设置;
根目录 – 这个栏位可改可不改,但这个根目录内容会与“域名”栏位联动,为防止混淆,笔者还是将其更改为hadsky
数据库 – 这里填入我们之前设置的数据库信息即可;
PHP版本 – 对于某些网站可能会要求使用特定版本的PHP,我们就可以在PHP版本栏位修改(前提是已经安装了对应版本的PHP软件)
完成这些设置后,就可以点击窗口下方的“提交”按钮,创建hadsky网站。
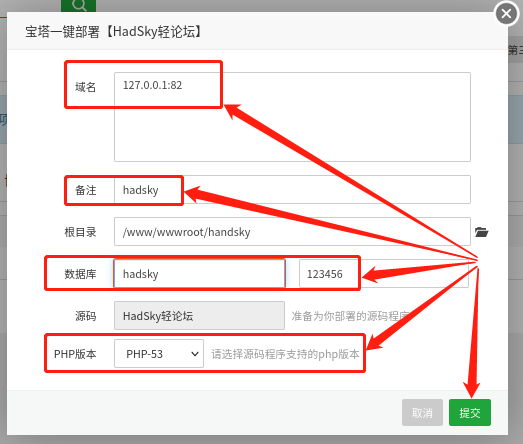
网站创建完成后(一瞬间的事),宝塔面板会弹出已创建网站的地址,重要的网站信息(可能是数据库信息,或是网站后台登录信息)。
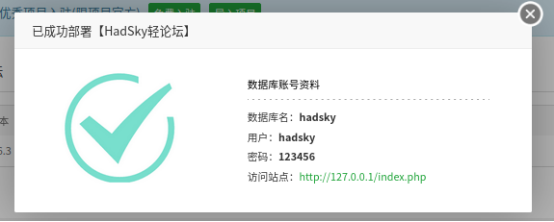
下一步打开ubuntu的宝塔面板,在软件主界面左侧点击“网站”按钮,进入网站列表页面,就能看到刚刚安装上线的hadsky网站。

此时我们在ubuntu的浏览器地址栏输入设置好的hadsky网站地址,就能看到haddsky的设置页面。我们继续根据网站显示页面的提示,进行具体的网站设置工作。
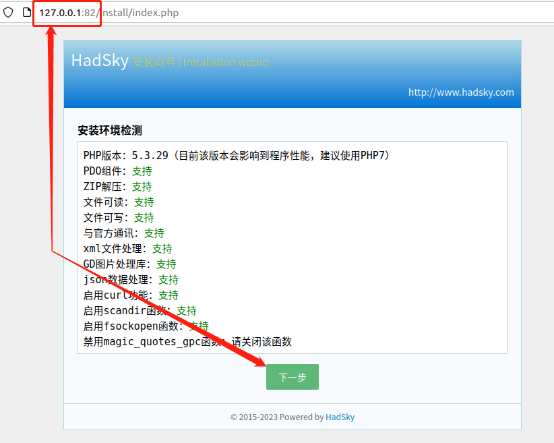
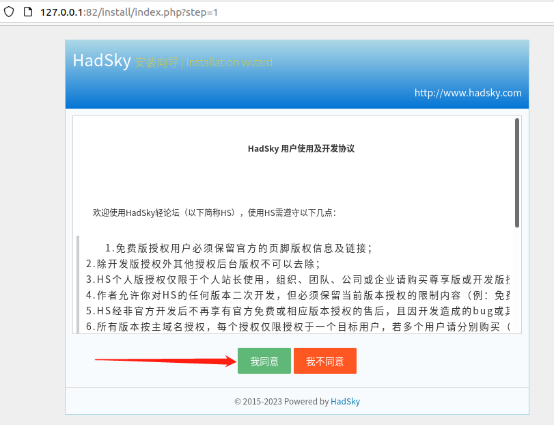
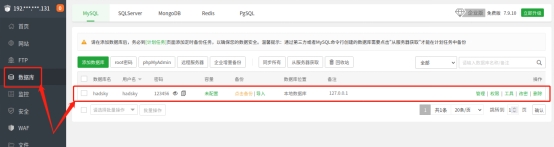
在hadsky网站安装过程中,会要求填写数据库相关信息(也就是在一键部署网站时设置的数据库信息),如果记不得网站数据库信息,则可以在宝塔面板左侧的“数据库”页面中找到有关内容。
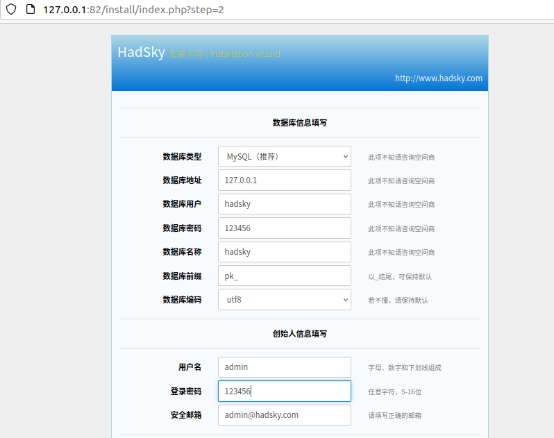
1.2 网页测试
数据库设置完成后,hadsky网站就会显示出网站安装完成的提示,我们可以在这里选择进入hadsky网站后台,或者直接进入已安装的论坛进行查看。
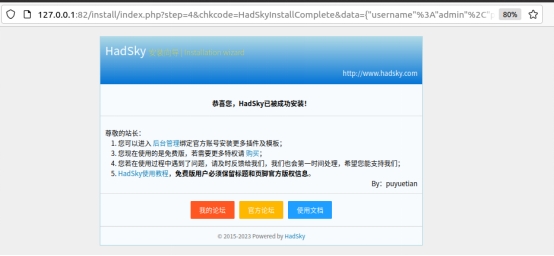
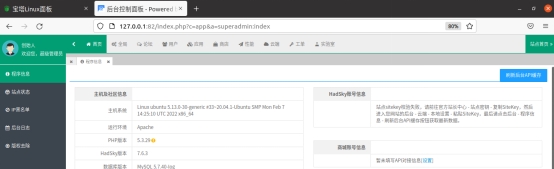
Hadsky论坛后台页面
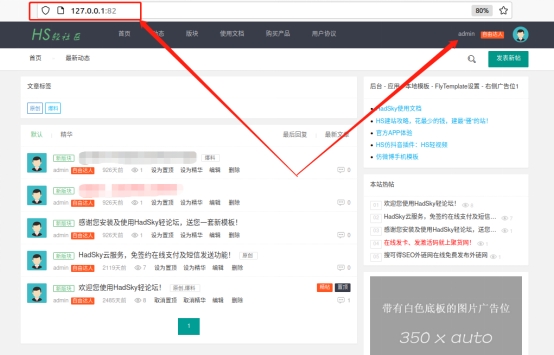
Hadsky论坛主页面
1.3 cpolar的安装和注册
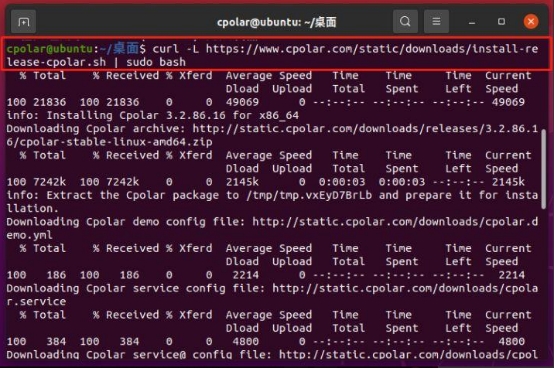
完成hadsky论坛的部署后,就可以转入cpolar的安装。想要在ubuntu系统上安装cpolar,可以使用简便的一键安装脚本进行安装。只要在ubuntu的命令行界面输入以下命令,就可以自动执行安装程序(需要注意的是,可能有的ubuntu版本没有安装curl工具,因此最好先执行命令“sudo aptinstall curl”安装curl工具)。
Cpolar一键安装脚本:
“curl -L
https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash”
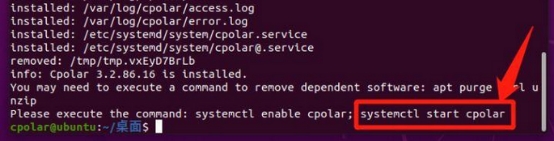
Cpolar安装完成后,就可以再输入命令“systemctl start cpolar”,启动cpolar。
这时ubuntu系统会跳出启动服务的认证框,我们输入ubuntu系统的密码即可。
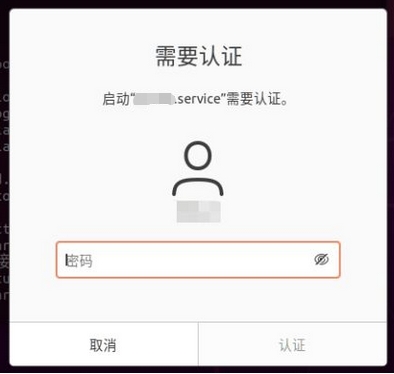
当然,我们也可以不使用systemctl级别命令,而是输入“cpolar version”查询本地cpolar的版本号,只要能显示出版本信息,就说明cpolar安装完成。
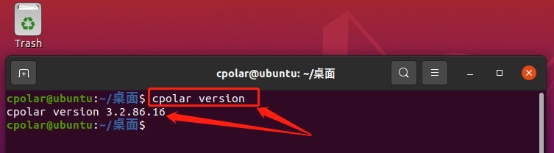
为保证cpolar能在ubuntu系统上长期运行,以此保证数据隧道的稳定存续,最好将cpolar添加进ubuntu开机自启列表。只要在ubuntu的命令行界面,输入命令“sudo systemctl status cpolar”,就能将cpolar添加进自启列表中。
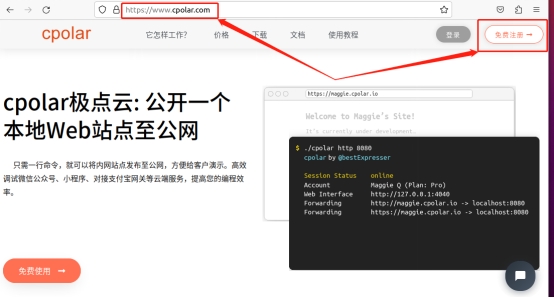
为保证每位用户的数据安全,并为每位客户创建单独的数据隧道,cpolar以用户密码和token码进行用户验证,因此我们在使用cpolar之前,需要进行用户注册。注册过程非常简单,只要在cpolar主页右上角点击“用户注册”,在注册页面填入必要信息,就能完成注册。
完成cpolar用户注册后,我们就可以使用每位用户唯一的token码,激活cpolar的客户端。只要在cpolar官网登录后,就可以在“验证”页面(或是“连接您的账户”窗口),找到用户唯一的token码。
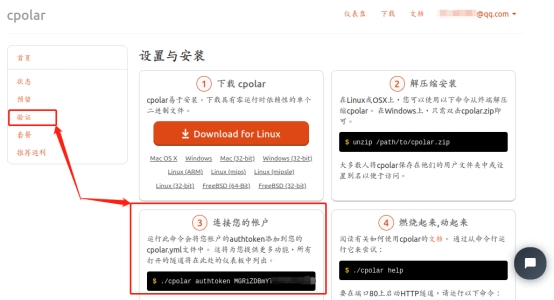
将这个token码复制粘贴到ubuntu的命令行界面,cpolar客户端就会将这个token码写入本地cpolar.yml文件中(token码激活只需要进行一次即可),以此作为用户数据隧道的识别信息。具体命令格式为“cpolar authtoken 用户唯一的token码”。
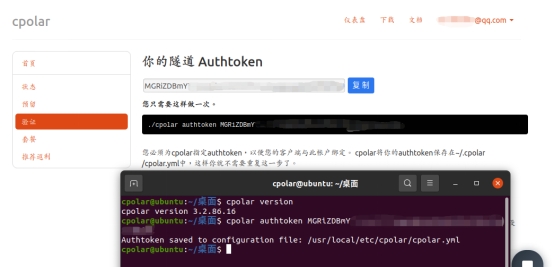
2. 本地网页发布
到这里,我们在本地设备上安装了网页,也安装了cpolar内网穿透程序,接下来我们就可以使用cpolar,为本地网页创建一个安全高效的数据隧道,让我们本地的网页能够在公共互联网上访问到。
2.1 Cpolar临时数据隧道
为满足部分客户需要的网页临时测试功能,cpolar可以直接在cpolar户端创建临时数据隧道(每隔24小时重置一次公共互联网地址,)。要创建临时数据隧道,我们直接在本地设备上登录cpolar客户端(在浏览器地址栏输入localhost:9200),并在cpolar客户端主界面点击“隧道管理”项下的“创建隧道”按钮,进入创建隧道设置页面。
在“创建隧道”页面,我们需要设置几项信息,这些信息包括:
隧道名称 – 可以看做cpolar客户端的隧道信息注释,只要方便我们分辨即可;
协议 –hadsky论坛是网页形式,因此选择http协议;
本地地址 – 本地地址即为本地网站的输出端口号,此处依照我们的设置,填入;
域名类型 –这里我们可以区分数据隧道是临时使用,或是长期存续。由于我们只是先进行临时测试,因此选择“随机域名”(二级子域名和自定义域名都是长期稳定隧道,需要在cpolar云端预留公共互联网地址)。
地区 – 即服务器所在位置,我们依照实际使用地就近填写即可;
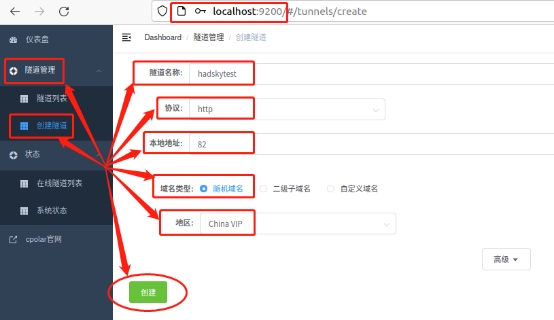
完成这些设置后,就可以点击页面下方的“创建”按钮,建立起一条临时数据隧道。临时数据隧道创建完成后,cpolar客户端会自动跳转至“隧道管理”项下的“隧道列表”页面,在这里我们可以看到cpolar本地的所有数据隧道(无论临时还是长期)。我们也可以在这里,对数据隧道进行管理,包括开启、关闭或删除这条隧道,也可以点击“编辑”按钮,最这条数据隧道的信息进行修改。

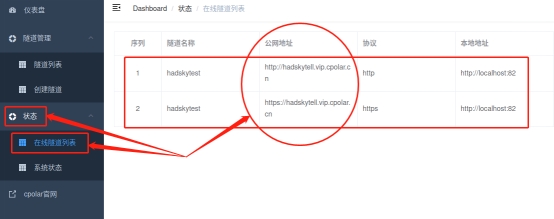
而我们创建的能够连接本地hadsky论坛的临时公共互联网网址,则可以在“状态”项下的“在线隧道列表”中找到。
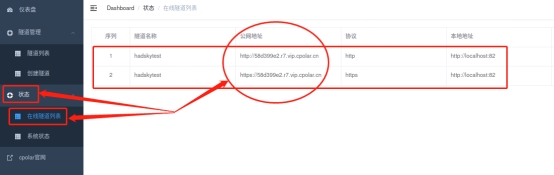
将这里显示的公共互联网地址粘贴到浏览器地址栏,就能访问到本地的网页页面。
需要注意的是,此时的数据隧道只是临时数据隧道,每24小时就会重置一次。数据隧道重置后,cpolar生成的公共互联网地址就会变化,如果打算再次访问这个网页,就需要使用新生成的地址。
2.2 Cpolar稳定隧道(云端设置)
如果想要为本地网站设置能长期稳定存在的数据隧道,我们需要先将cpolar升级至VIP版。
Cpolar升级至付费版后,就可以登录cpolar的官网,并在用户主页面左侧找到“预留”按钮,点击进入cpolar的数据隧道预留页面,在这里生成一个公共互联网地址(或称为数据隧道的入口)。此时这个地址没有连接本地的软件输出端口,因此可以看做是一条空白的数据隧道。

在预留页面,我们可以保留使用多种协议的数据隧道,这里我们选择“保留二级子域名”栏位。
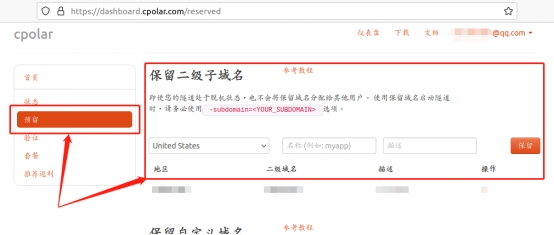
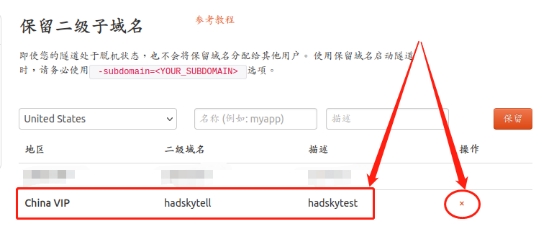
在“保留二级子域名”栏位,需要进行几项信息的简单设置,即“地区”(服务器所在区域,就近选择即可)、“二级域名”(会最终出现在生成的公共互联网地址中,作为网络地址的标识之一)和“描述”(可以看做这条数据隧道的描述,能够与其他隧道区分开即可)。完成这几项设置后,就可以点击右侧的“保留”按钮,将这条数据隧道保留下来。

当然,如果这条数据隧道不打算再使用,还可以点击右侧的“x”将其轻松删除,节约宝贵的隧道名额。
2.3 Cpolar稳定隧道(本地设置)
完成cpolar云端的设置,并保留了空白数据隧道后,我们回到本地的cpolar客户端,将云端生成的空白数据隧道与本地的测试页面连接起来。
在本地设备上打开并登录cpolar客户端(可以在浏览器中输入localhost:9200直接访问,也可以在开始菜单中点击cpolar客户端的快捷方式)。
点击客户端主界面左侧“隧道管理”项下的“隧道列表”按钮,进入本地隧道的页面,再点击对应隧道的“编辑”按钮。
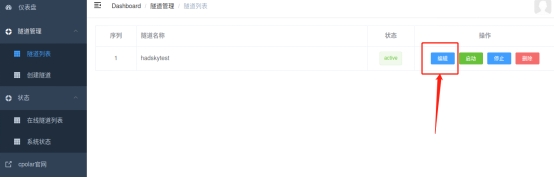
在本地隧道的“编辑”页面(与创建本地临时隧道的页面一样),我们只要对“域名类型”进行修改,就能将cpolar云端设保留的公共互联网地址,与本地cpolar创建的hadsky网站数据隧道连接起来。
由于我们已经在cpolar云端预留了hadsky的二级子域名数据隧道,因此改选为“二级子域名”(如果预留的是自定义域名,则勾选自定义域名),并在下一行“Sub Domain”栏中填入预留的二级子域名,这里我们填入“hadskytell”。
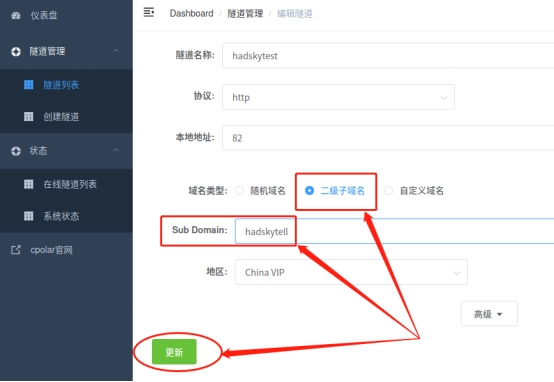
完成“域名类型”的更改后,就可以点击页面下方的“更新”按钮,将cpolar云端的空白数据隧道与本地hadsky网站隧道连接起来,即生成了能够长期稳定存在的hadsky论坛数据隧道。
2.4 公网访问测试
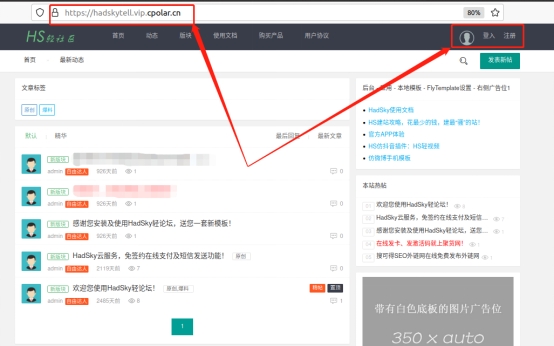
最后,我们再次 进入“在线隧道列表”页面,就会发现本地hadsky论坛的公共互联网地址已经发生了变化。我们将更新后的hadsky网站公共互联网地址粘贴到浏览器中,就能看到能够使用新地址访问到Imagewheel网站,也就意味着本地的hadsky网站已经能够长期稳定的访问到。
总结
从步骤上看,hadsky论坛在ubuntu系统上的部署并不复杂,而有了cpolar软件的加持,让我们的选择更加灵活,我们可以选择安装其他形式的网站,再通过cpolar创建的内网穿透数据隧道,将本地电脑上的网站发布到公共互联网上,让我们为自己的数码生活添加新的色彩。
这篇关于如何在Ubuntu使用宝塔面板搭建hadsky轻论坛并发布到公网可随时访问的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





