本文主要是介绍File Organization Indexing文件组织与索引,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Introduction • DBMS has to store data somewhere • Choices: — Main memory ◦ Expensive – compared to secondary and tertiary storage ◦ Fast – in memory operations are fast ◦ Volatile – not possible to save data from one run to its next ◦ Used for storing current data (10 GBs) — Secondary storage (hard disk) ◦ Less expensive – compared to main memory ◦ Slower – compared to main memory, faster compared to tapes ◦ Persistent – data from one run can be saved to the disk to be used in the next run ◦ Used for storing the database (10 TBs, 2016) — Tertiary storage (tapes) ◦ Cheapest ◦ Slowest – sequential data access ◦ Used for data archives (Sony 185 TB tapes, 2014) DBMS 必须将数据存储在某个地方 主存储器 ◦昂贵◦快速--内存中的操作速度快 ◦易失--无法将数据从一次运行保存到下一次运行 ◦用于存储当前数据(10 GB)二级存储(硬盘) ◦较便宜 ◦较慢◦ 持久性--一次运行的数据可保存到磁盘,以便在下一次运行中使用 ◦ 用于存储数据库(10 TB)三级存储(磁带) ◦ 最便宜 ◦ 最慢--顺序数据访问 ◦ 用于数据存档(185 TB)
ORACLE StorageTek Tape ORACLE StorageTek 磁带
DBMS Stores Data on Hard Disks • This means that data needs to be — read from the hard disk into memory (RAM) — written from the memory onto the hard disk • Because I/O disk operations are slow query performance depends upon how data is stored on hard disks • The lowest component of the DBMS performs storage management activities • Other DBMS components need not know how these low level activities are performed DBMS 将数据存储在硬盘上 - 这意味着数据需要 从硬盘读入内存(RAM) 从内存写入硬盘 - 由于 I/O 磁盘操作速度较慢,查询性能取决于数据在硬盘上的存储方式 - DBMS 的最底层组件执行存储管理活动 - DBMS 的其他组件无需了解这些底层活动的执行方式
Basics of Data Storage on Hard Disk • A disk is organized into a number of blocks or pages • A page is the unit of exchange between the disk and the main memory • A collection of pages is known as a file • DBMS stores data in one or more files on the hard disk硬盘数据存储的基本原理 - 磁盘分为若干区块或页面 页面是磁盘和主存储器之间的交换单位 页面的集合称为文件 DBMS 将数据存储在硬盘上的一个或多个文件中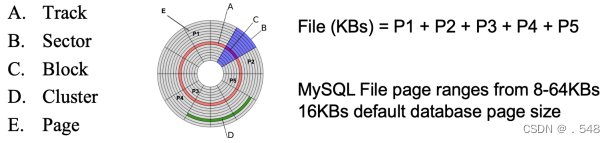
Database Tables on Hard Disk • Database tables are made up of one or more tuples (rows) • Each tuple has one or more attributes • One or more tuples from a table are written into a page on the hard disk — Larger tuples may need more than one page! — Tuples on the disk are known as records — Records are separated by record delimiter — Attributes on the hard disk are known as fields — Fields are separated by field delimiter硬盘上的数据库表 - 数据库表由一个或多个元组(行)组成 - 每个元组有一个或多个属性 - 表中的一个或多个元组被写入硬盘的一个页面 较大的元组可能需要多个页面!磁盘上的元组称为记录 记录由记录分隔符分隔 硬盘上的属性称为字段 字段由字段分隔符分隔
File Organization • The physical arrangement of data in a file into records and pages on the disk • File organization determines the set of access methods for — Storing and retrieving records from a file • Therefore, ‘file organization’ synonymous with ‘access method’ • We study three types of file organization — Unordered or Heap files — Ordered or sequential files — Hash files • We examine each of them in terms of the operations we perform on the database — Insert a new record — Search for a record (or update a record) — Delete a record文件组织 - 将文件中的数据物理排列成磁盘上的记录和页面 - 文件组织决定了用于存储和检索文件中记录的访问方法集 因此,"文件组织 "与 "访问方法 "同义 - 我们研究三种类型的文件组织 无序文件或堆文件 有序文件或顺序文件 哈希文件 - 我们根据在数据库中执行的操作来研究每种类型的文件组织 插入新记录 搜索记录(或更新记录)删除记录
Unordered Or Heap File • Records are stored in the same order in which they are created • Insert operation — Fast – because the incoming record is written at the end of the last page of the file • Search (or update) operation — Slow – because linear search is performed on pages • Delete Operation — Slow – because the record to be deleted is first searched for — Deleting the record creates a hole in the page — Periodic file compacting work required to reclaim the wasted space无序或堆文件 - 记录的存储顺序与创建顺序相同 - 插入操作 快速 因为输入的记录写在文件最后一页的末尾 - 搜索(或更新)操作 慢速 因为是在页面上进行线性搜索 - 删除操作 慢速 因为要删除的记录首先要被搜索 删除记录会在页面上造成一个洞 需要定期压缩文件以收回浪费的空间
Ordered or Sequential File • Records are sorted on the values of one or more fields — Ordering field – the field on which the records are sorted — Ordering key – the key of the file when it is used for record sorting • Search (or update) Operation — Fast – because binary search is performed on sorted records — Update the ordering field? • Delete Operation — Fast – because searching the record is fast — Periodic file compacting work is, of course, required • Insert Operation — Poor – because if we insert the new record in the correct position we need to shift all the subsequent records in the file — Alternatively an ‘overflow file’ is created which contains all the new records as a heap — Periodically overflow file is merged with the main file — If overflow file is created search and delete operations for records in the overflow file have to be linear!排序或顺序文件 记录根据一个或多个字段的值排序 排序字段 记录排序所依据的字段 - 排序键 用于记录排序时的文件键 - 搜索(或更新)操作 快速 因为二进制搜索是在排序记录上进行的 - 更新排序字段? - 删除操作 快速 因为搜索记录的速度很快 当然需要定期压缩文件 - 插入操作 较差 因为如果我们在正确的位置插入新记录,就需要移动文件中的所有后续记录 或者创建一个 "溢出文件",以堆的形式包含所有新记录 定期将溢出文件与主文件合并 如果创建了溢出文件,对溢出文件中记录的搜索和删除操作必须是线性的!
Hash File • Is an array of buckets — Given a record, r a hash function, h(r) computes the index of the bucket in which record r belongs — h uses one or more fields in the record called hash fields — Hash key – the key of the file when it is used by the hash function • Example hash function — Assume that the staff last name is used as the hash field — Assume also that the hash file size is 26 buckets – each bucket corresponding to each of the letters from the alphabet — Then a hash function can be defined which computes the bucket address (index) based on the first letter in the last name哈希文件 - 是一个由桶组成的数组 给定一条记录,r 是一个哈希函数、 h(r)计算记录 r 所在的桶的索引 h 使用记录中的一个或多个字段,称为散列字段 散列键 文件的键,当它被散列函数使用时 - 散列函数示例 假设员工的姓氏被用作散列字段 还假设散列文件大小为 26 个桶 每个桶对应字母表中的每个字母 然后可以定义一个散列函数,根据姓氏中的第一个字母计算桶的地址(索引)
• Insert Operation — Fast – because the hash function computes the index of the bucket to which the record belongs ◦ If that bucket is full you go to the next free one • Search Operation — Fast – because the hash function computes the index of the bucket ◦ Performance may degrade if the record is not found in the bucket suggested by hash function • Delete Operation — Fast – once again for the same reason of hashing function being able to locate the record quick插入操作 快速 因为哈希函数会计算记录所属数据桶的索引 ◦如果该数据桶已满,则转到下一个空闲的数据桶 - 搜索操作 快速 因为哈希函数会计算数据桶的索引 ◦如果在哈希函数建议的数据桶中找不到记录,则性能可能会下降 - 删除操作 快速 同样是因为哈希函数能够快速定位记录的原因
Indexing • Can we do anything else to improve query performance other than selecting a good file organization? • Yes, the answer lies in indexing • Index – a data structure that allows the DBMS to locate particular records in a file more quickly — Very similar to the index at the end of a book to locate various topics covered in the book • Types of Index — Primary index – one primary index per file — Clustering index – one clustering index per file – data file is ordered on a non-key field and the index file is built on that non-key field — Secondary index – many secondary indexes per file • Sparse index – has only some of the search key values in the file • Dense index – has an index corresponding to every search key value in the file 索引 一种数据结构,允许 DBMS 更快地定位文件中的特定记录 与书末的索引非常相似,用于定位书中涉及的各种主题 - 索引类型 主索引:每个文件一个主索引 聚类索引:每个文件一个聚类索引 数据文件根据非关键字段排序,索引文件根据该非关键字段建立 二级索引:每个文件许多二级索引 稀疏索引 :每个文件一个稀疏索引 数据文件根据非关键字段排序,索引文件根据该非关键字段建立。 二级索引 每个文件有多个二级索引 - 稀疏索引 文件中只有部分搜索键值 - 密集索引 文件中的每个搜索键值都对应一个索引
Primary Indexes • The data file is sequentially ordered on the key field • Index file stores all (dense) or some (sparse) values of the key field and the page number of the data file in which the corresponding record is stored 主索引 数据文件按关键字段顺序排序 - 索引文件存储关键字段的全部(密集)或部分(稀疏)值,以及存储相应记录的数据文件页码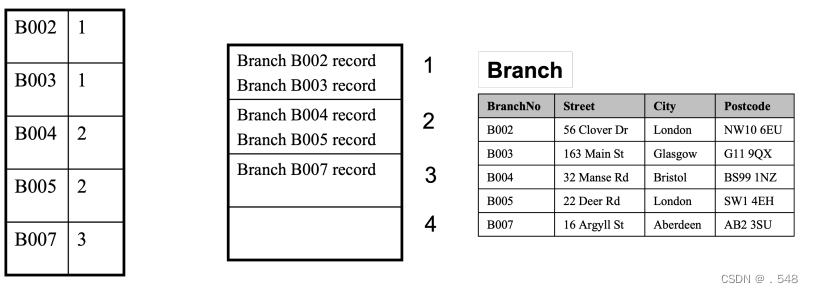 Indexed Sequential Access Method • ISAM – Indexed sequential access method is based on primary index • MyISAM table type in MySQL, is an extension of ISAM • Insert and delete operations disturb the sorting — You need an overflow file which periodically needs to be merged with the main file 索引顺序访问方法 ISAM:索引顺序访问方法基于主索引 - MySQL 中的 MyISAM 表类型是 ISAM 的扩展 - 插入和删除操作会干扰排序 - 需要一个溢出文件,该文件需要定期与主文件合并
Indexed Sequential Access Method • ISAM – Indexed sequential access method is based on primary index • MyISAM table type in MySQL, is an extension of ISAM • Insert and delete operations disturb the sorting — You need an overflow file which periodically needs to be merged with the main file 索引顺序访问方法 ISAM:索引顺序访问方法基于主索引 - MySQL 中的 MyISAM 表类型是 ISAM 的扩展 - 插入和删除操作会干扰排序 - 需要一个溢出文件,该文件需要定期与主文件合并
Secondary Indexes • An index file that uses a non primary field as an index e.g., City field in the branch table • They improve the performance of queries that use attributes other than the primary key • You can use a separate index for every attribute you wish to use in the WHERE clause of your select query • But there is the overhead of maintaining a large number of these indexes 二级索引 一种使用非主字段作为索引的索引文件,如分支表中的城市字段 - 它们可提高使用主键以外的属性进行查询的性能 - 可以在选择查询的 WHERE 子句中使用的每个属性使用单独的索引 - 但维护大量索引成本高。
Creating indexes in SQL • You can create an index for every table you create in SQL • For example 可以为 SQL 中创建的每个表创建索引
Summary • File organization or access method determines the performance of search, insert and delete operations — Access methods are the primary means to achieve improved performance • Index structures help to improve the performance further — More index structures in the next lecture 文件组织或访问方法决定了搜索、插入和删除操作的性能 - 访问方法是提高性能的主要手段 - 索引结构有助于进一步提高性能 - 下一讲将介绍更多索引结构
这篇关于File Organization Indexing文件组织与索引的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






