本文主要是介绍【直播笔记0505】涛哥的Mysql索引原理深入剖析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
涛哥的Mysql索引原理深入剖析
- 1. 索引到底是什么东西?
- 2. 建立索引的方式
- 3. 索引的类型:
- 4. 数据结构选型
- 4.1 二叉查找树
- 4.1 平衡二叉树(AVL树)
- B树
- B+树
- Hash索引
- 存储引擎
- 5.索引的使用以及创建
- 索引的使用原则
- 失效的场景
1.Mysql索引的本质是什么?
2.索引有哪些分类
3.为什么我们要选择B+树做为索引的数据结构
4.不同的存储引擎之间有什么差异
5.索引的使用到底应该遵循什么原则
创建索引效率提高。
键索引花费时间。
1. 索引到底是什么东西?
数据库的索引是i一个经过排序的数据结构。
目的:他就是为了让你的查询更快
只要是数据结构 必然会占用你的空间。
典型的空间换时间思想。
索引: KV形式
K:字段的值
V:地址指针
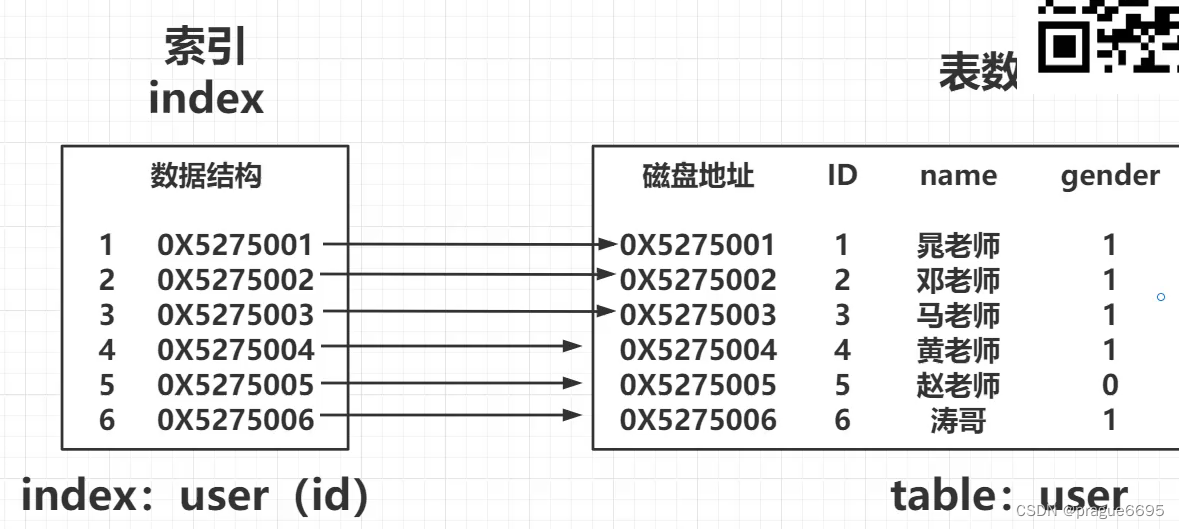
2. 建立索引的方式
建表的时候
通过sql语句
通过可视化界面
3. 索引的类型:
普通索引:就是经过特殊设计的数据结构
唯一索引:值不能重复
主键索引(特殊的唯一索引): 非空约束
全文索引:full text 全文匹配 对中文分词不太好,业务中推荐使用搜索引擎。
最左前缀原则
4. 数据结构选型
有序的数据结构 树 单链表 有序数组
有序数组:新增数据不方便,大量数据比对和角标移动.不适合修改比较多的这个场景
单链表:查询效率低,要把前面的每个格子都要查一遍
那种数据结构合适?
首先有序,支持二分查找法,
4.1 二叉查找树
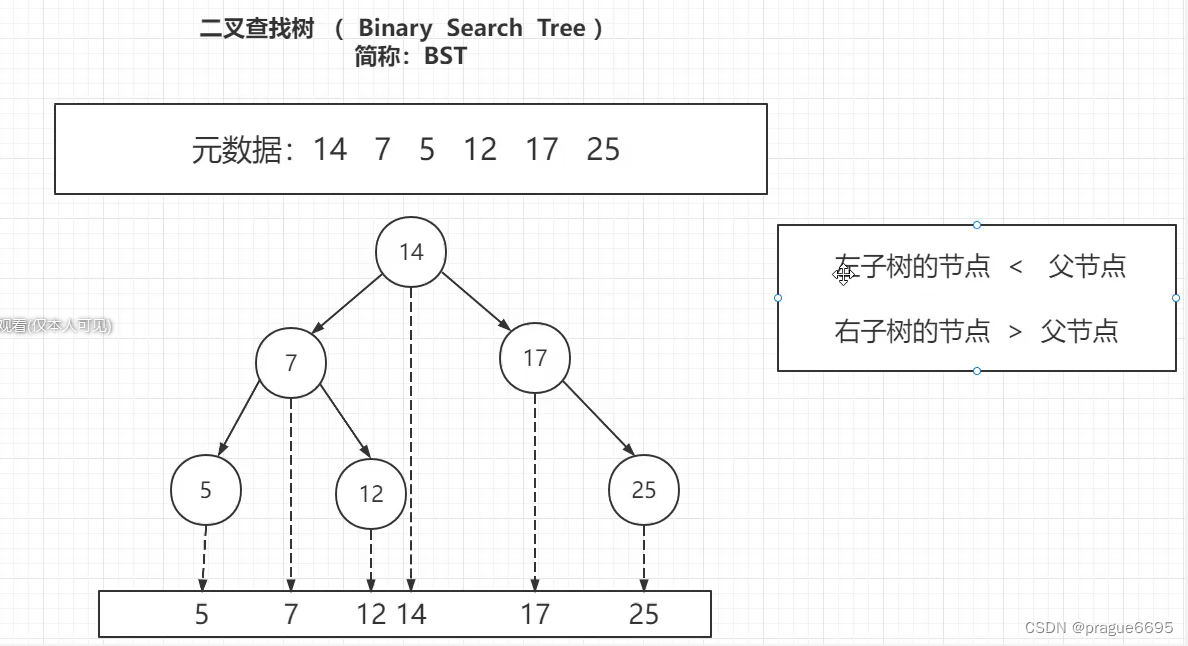
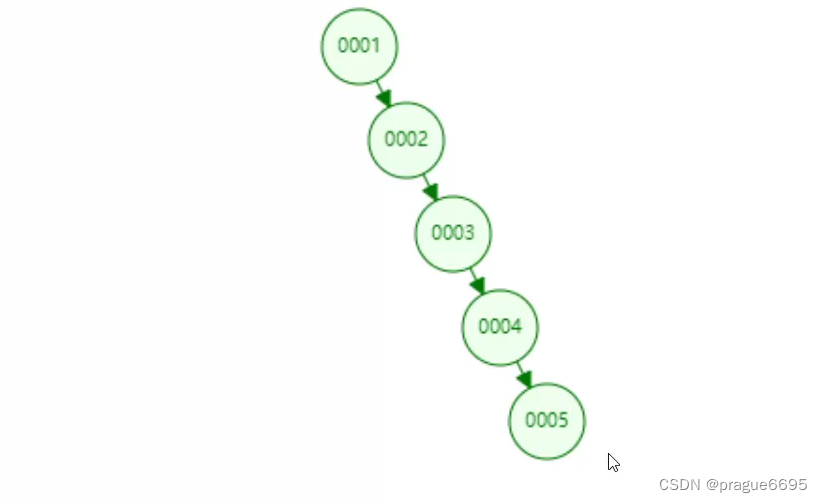
但是有个问题: 最坏情况,会存在一条链表,无法进行二分查找。
4.1 平衡二叉树(AVL树)
改进后,会有平衡二叉树
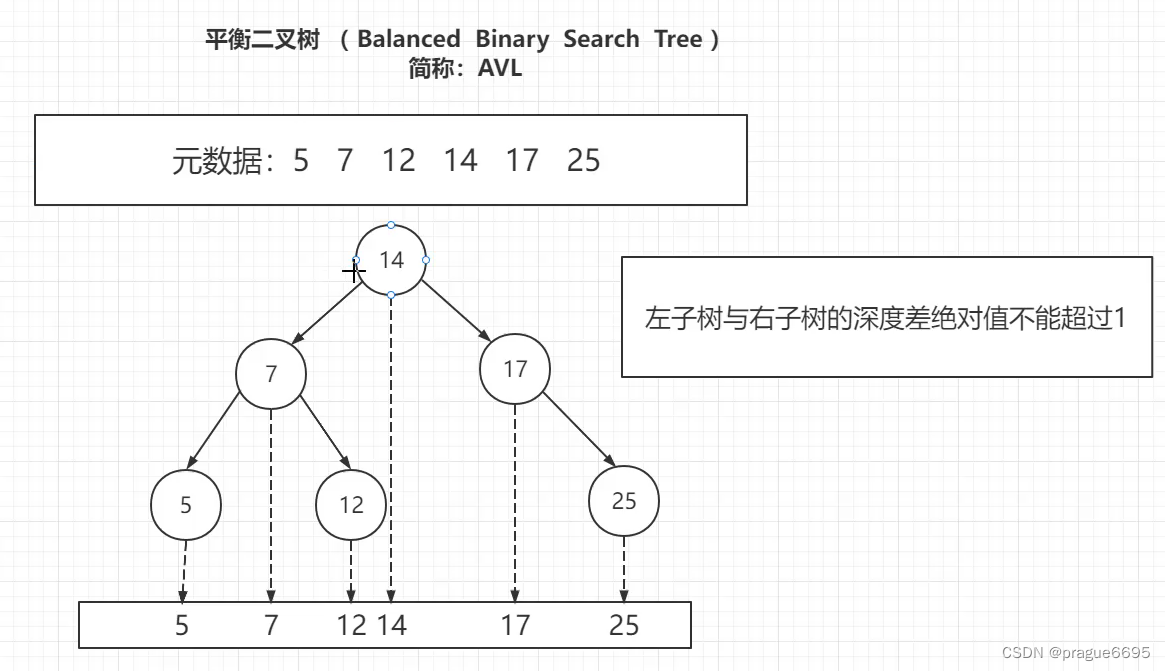
会存在旋转
节点指向改变
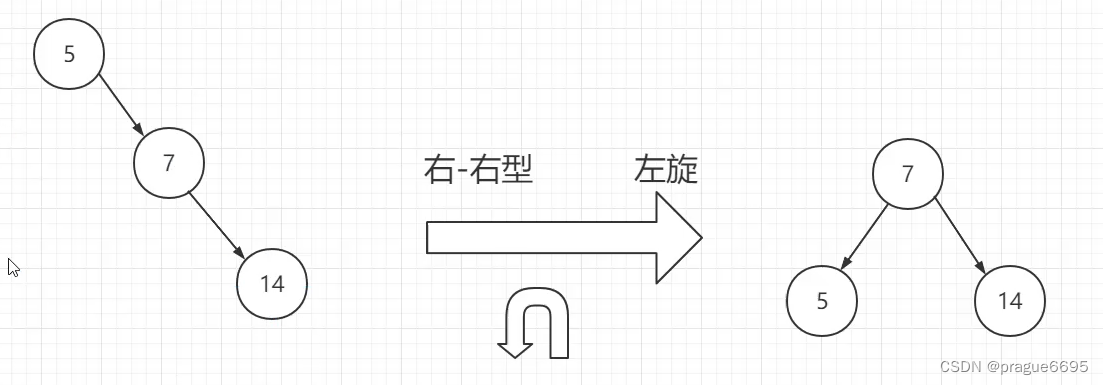
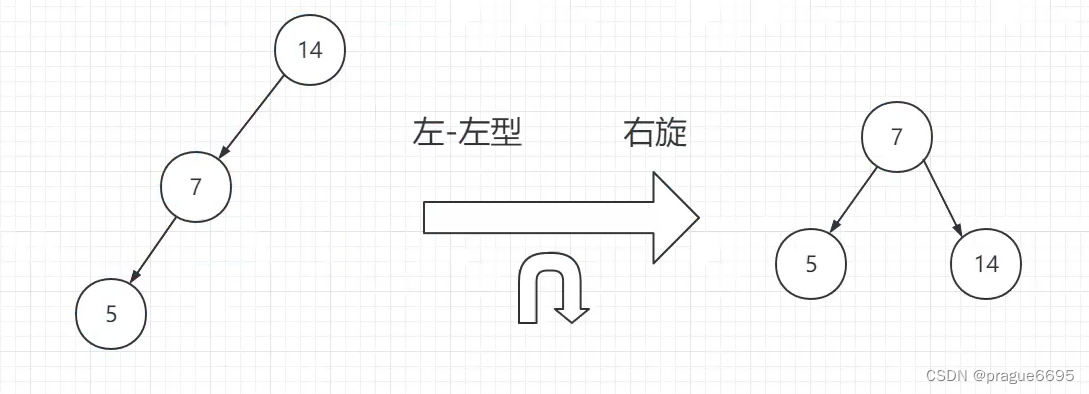
假设使用avl作为索引的话,会存储四个值(kv,左右孩子)
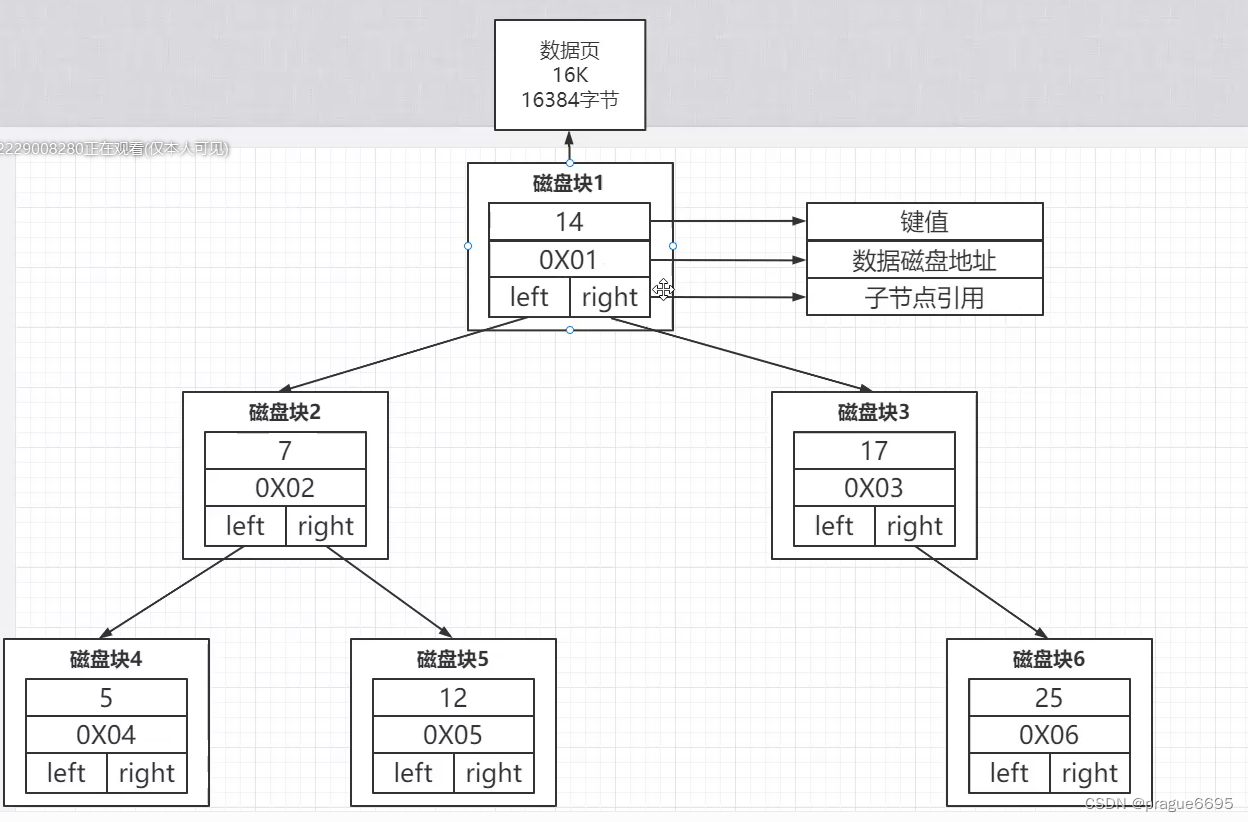
放不了多少。
一个磁盘块存放多个数据。
B树
二叉变为多叉。
减少io次数,不管前中后序都会回到父节点。
查询效率不稳定,可能查到父节点,也可能查到子节点。
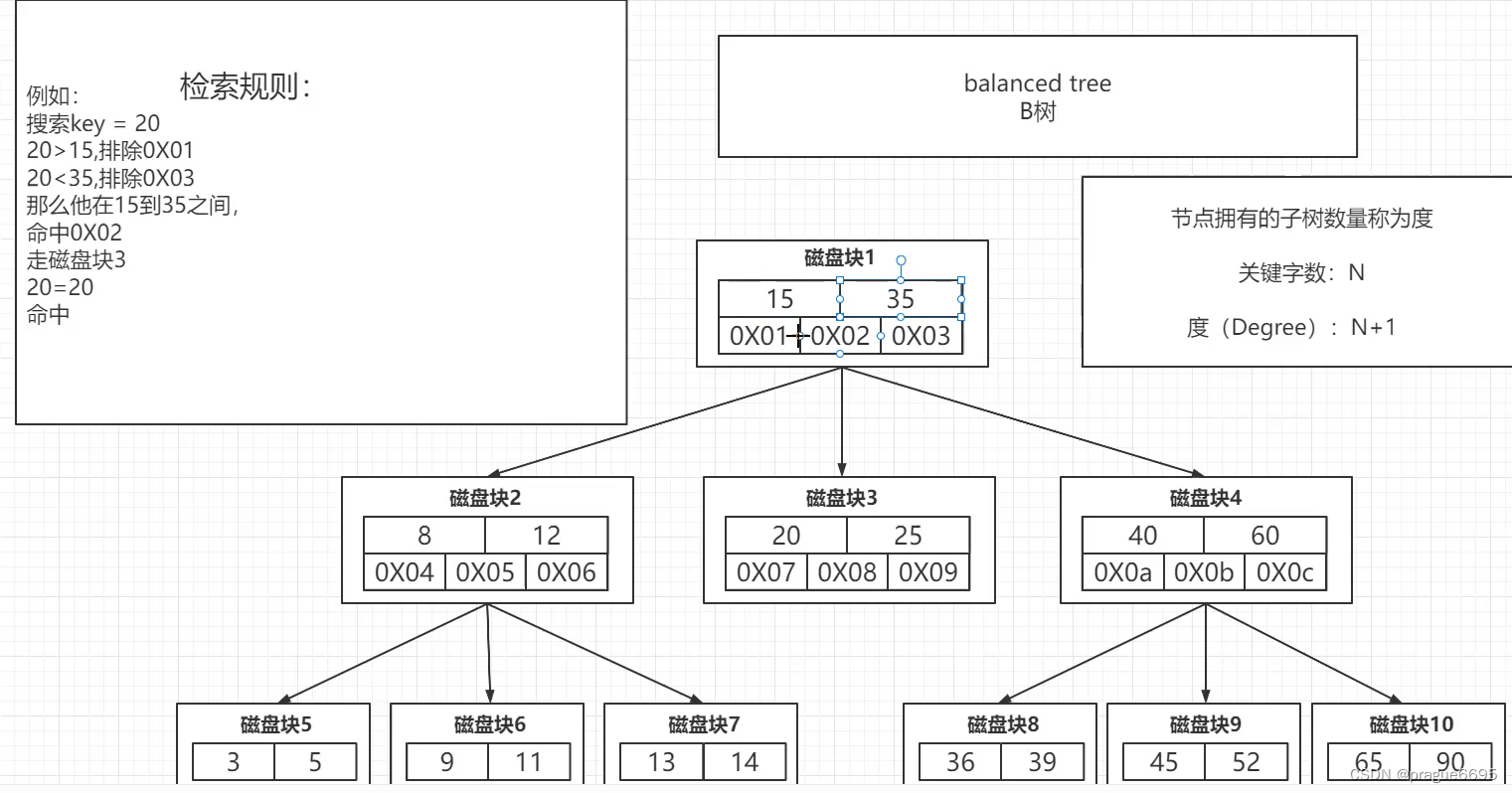
关键字越小 同一个磁盘块容纳的关键字越多
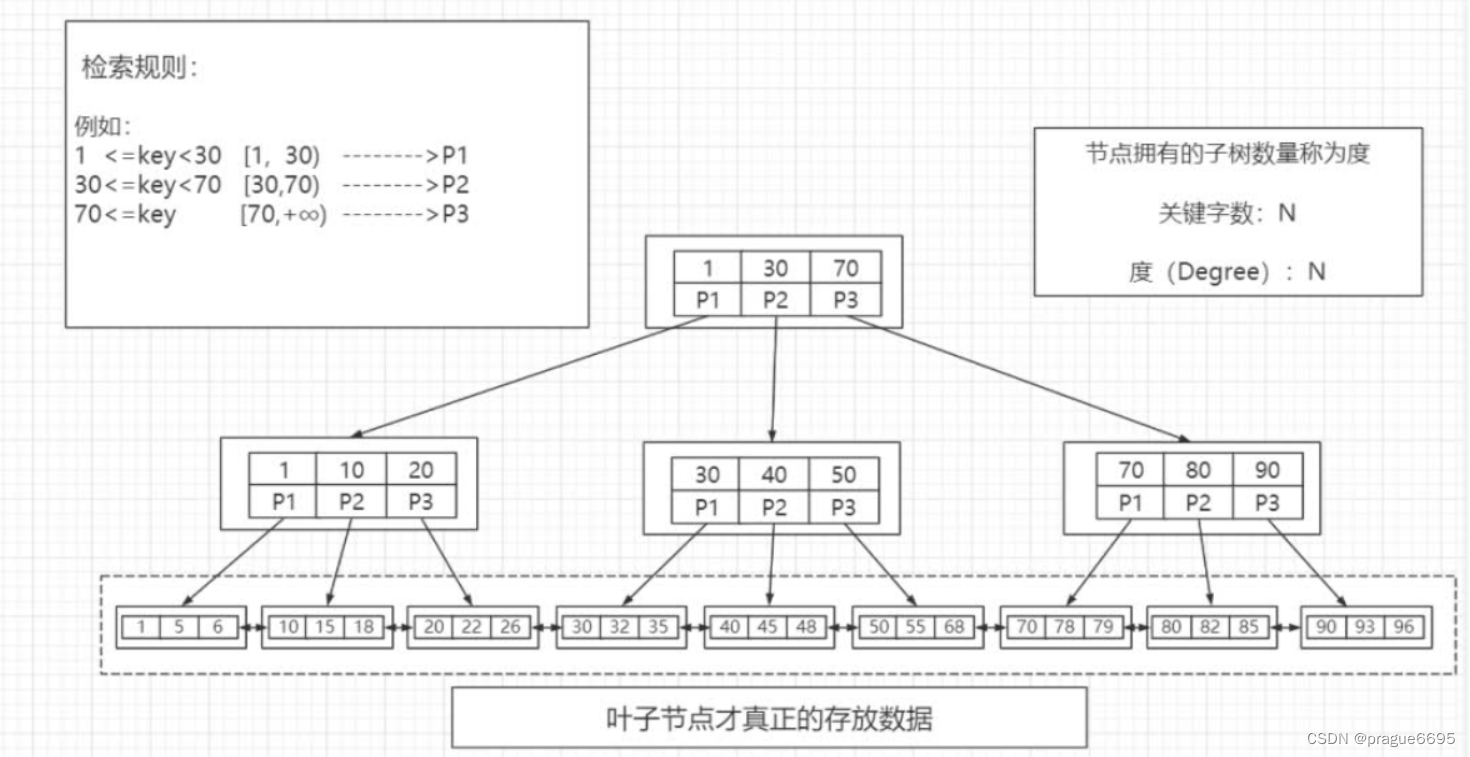
B+树
在叶子节点上 才会存储数据
叶子节点间也有指针。
三个特性:减少io次数,磁盘读写能力更强,效率会更加稳定(查的都是子节点)。
一般情况下,三层就足够了。
Innodb的数据页是16K
1000100010=1千万
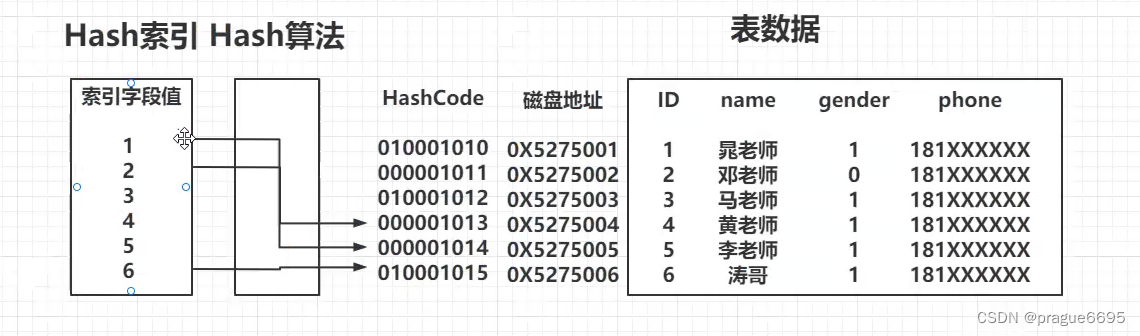
Hash索引
比树要快
生成键值直接去找。
映射的地址值是不连续的,不能做范围查询。
Innodb不支持hash索引。
存储引擎
存储引擎有什么用?
- 存储引擎怎么来的?
- 这个东西能改吗?
- 不同的存储引擎,有什么区别?
默认的存储引擎: InnoDB, mysql 5.5版本以上。
需求:
- 我有一张表,希望有很快的访问速度, 不关心持久化问题(放在 内存当中)
- 存历史数据,能够去支持压缩
- 支持读写并发的操作, 提供较高的一致性
不同的需求,所以有不同的存储引擎。



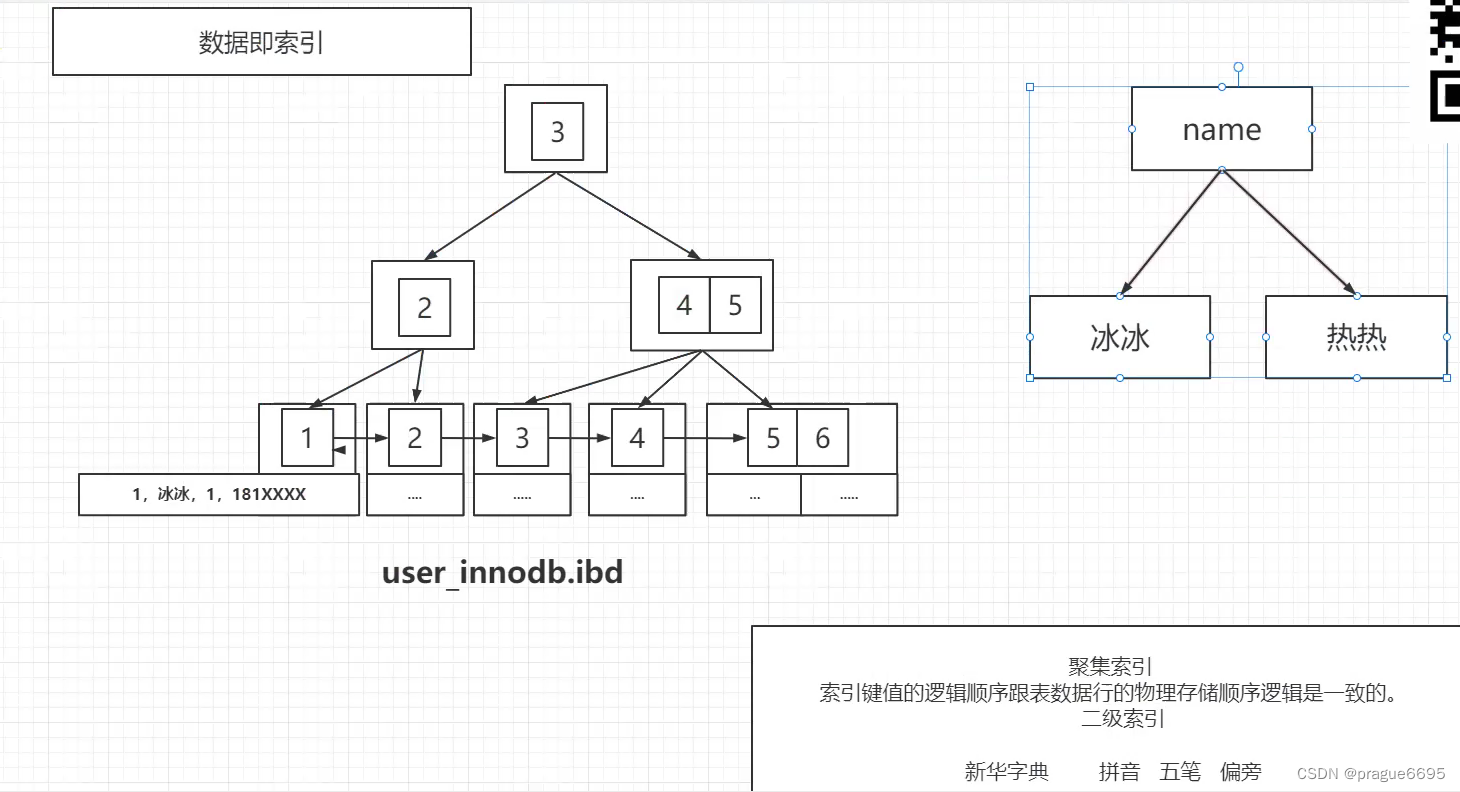
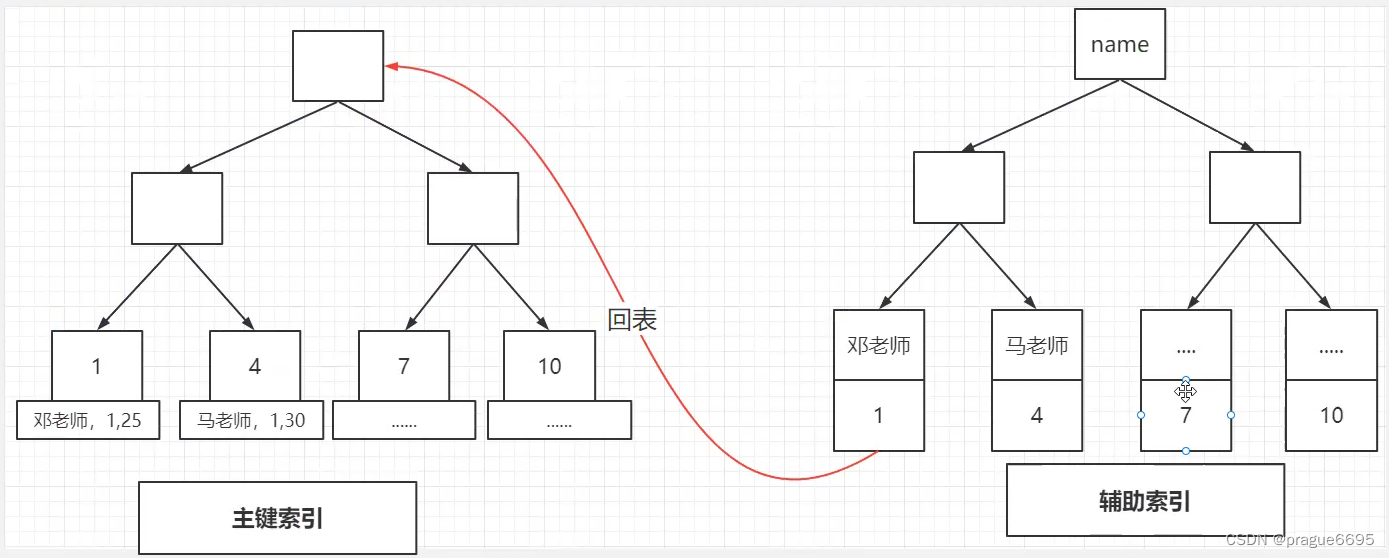
其他索引不应该存完整数据
聚集索引:存放的是完整数据,索引键值的逻辑顺序跟表数据行的物理存储顺序逻辑是一致的。
二级索引:存主键索引
5.索引的使用以及创建
- 不要给每个字段建立索引,因为会浪费空间
- 列的离散度 当你的离散度过低没有办法对比
字段值 : 男女/500W = 越接近0, 说明离散度越低
500W/500W = 越接近1, 说明离散度越高
- 联合索引的最左匹配
联合索引:
当第一索引一样的时候,才查第二个索引

- 覆盖索引
使用索引的概念,直接查的是索引的值。不需要查聚集索引,在辅助索引上就可一查的出来
索引的使用原则
1.你的索引不应该在select里面创建where join
2.索引个数不要太多
3.散列度低的数据不要建立索引
4.随机的或者无序的数据 不适合作为主键
5.创建复合索引避免冗余
失效的场景
1.索引上使用函数表达式
2.出现类型的隐式转换
3.like条件字符前模糊
4.负向查询 xxx!=NOT IN
这篇关于【直播笔记0505】涛哥的Mysql索引原理深入剖析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





