本文主要是介绍Flink中任务(Tasks)和任务槽(Task Slots)详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flink中任务(Tasks)和任务槽(Task Slots)详解
任务槽(Task Slots)
Flink中每一个worker(也就是TaskManager)都是一个JVM进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。
所以如果想要执行5个任务,并不一定非要5个TaskManager,我们可以让TaskManager 多线程执行任务。如果可以同时运行5个线程,那么只要一个TaskManager就可以满足我们之前程序的运行需求了。
很显然,TaskManager的计算资源是有限的,并不是所有任务都可以放在一个TaskManager 上并行执行。并行的任务越多,每个线程的资源就会越少。那一个TaskManager到底能并行处理多少个任务呢?为了控制并发量,我们需要在TaskManager上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(taskslots)。
每个任务槽(task slot)其实表示了TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
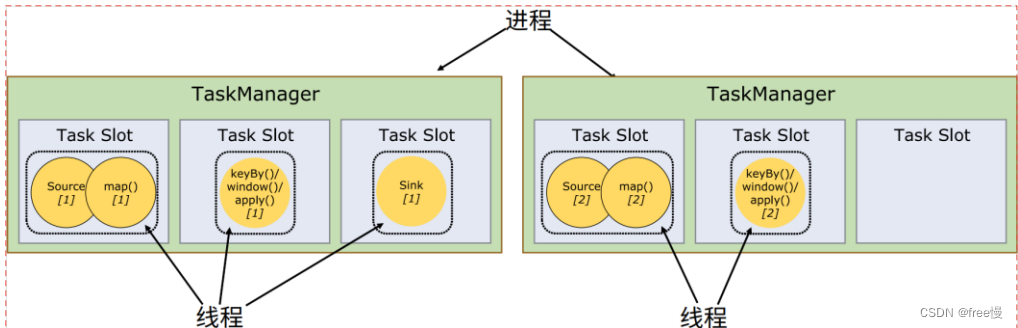
假如一个TaskManager有三个slot,那么它会将管理的内存平均分成三份,每个slot独自占据一份。这样一来,我们在slot上执行一个子任务时,相当于划定了一块内存“专款专用”,就不需要跟来自其他作业的任务去竞争内存资源了。
具体来说,如果一个TaskManager只有一个slot,那将意味着每个任务都会运行在独立的
JVM中(当然,该JVM可能是通过一个特定的容器启动的);而一个TaskManager设置多个
slot则意味着多个子任务可以共享同一个JVM。它们的区别在于:前者任务之间完全独立运行,隔离级别更高、彼此间的影响可以降到最小;而后者在同一个JVM进程中运行的任务,将共享TCP连接和心跳消息,也可能共享数据集和数据结构,这就减少了每个任务的运行开销,在降低隔离级别的同时提升了性能。
需要注意的是,slot目前仅仅用来隔离内存,不会涉及CPU的隔离。在具体应用时,可以将slot数量配置为机器的CPU核心数,尽量避免不同任务之间对CPU的竞争。这也是开发环境默认并行度设为机器CPU数量的原因。
任务(Tasks)和任务槽(Tasks Slot)共享
默认情况下,Slot是支持多个任务共享资源的。
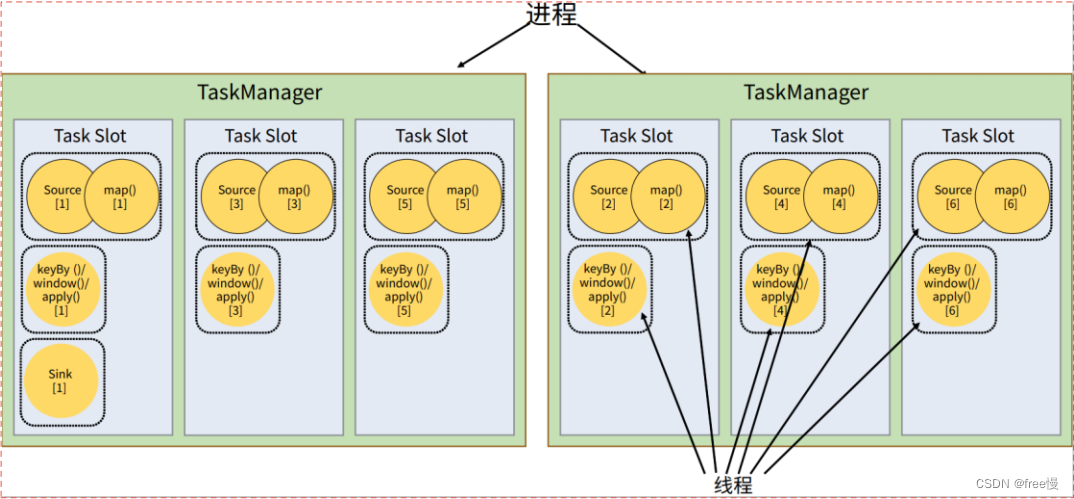
如下图所示。只要属于同一个作业,那么对于不同任务节点的并行子任务,就可以放到同一个slot上执行。所以对于第一个任务节点source→map,它的6个并行子任务必须分到不同的slot上(如果在同一slot就没法数据并行了),而第二个任务节点keyBy/window/apply的并行子任务却可以和第一个任务节点共享slot。
于是最终结果就变成了:每个任务节点的并行子任务一字排开,占据不同的slot;而不同的任务节点的子任务可以共享slot。一个slot中,可以将程序处理的所有任务都放在这里执行,我们把它叫作保存了整个作业的运行管道。
这个特性看起来有点奇怪:我们不是希望并行处理、任务之间相互隔离吗,为什么这里又允许共享slot呢?
我们知道,一个slot对应了一组独立的计算资源。在之前不做共享的时候,每个任务都平等地占据了一个slot,但其实不同的任务对资源的占用是不同的。例如这里的前两个任务,source/map尽管是两个算子合并算子链得到的,但它只是基本的数据读取和简单转换,计算耗时极短,一般也不需要太大的内存空间;而window算子所做的窗口操作,往往会涉及大量的数据、状态存储和计算,我们一般把这类任务叫作“资源密集型”(intensive)任务。当它们被平等地分配到独立的slot上时,实际运行我们就会发现,大量数据到来时source/map和sink 任务很快就可以完成,但window任务却耗时很久;于是下游的sink任务占据的slot就会等待闲置,而上游的source/map任务受限于下游的处理能力,也会在快速处理完一部分数据后阻塞对应的资源开始等待(相当于处理背压)。这样资源的利用就出现了极大的不平衡,“忙的忙死,闲的闲死”。
解决这一问题的思路就是允许slot共享。当我们将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的TaskManager。
slot共享另一个好处就是允许我们保存完整的作业管道。这样一来,即使某个TaskManager 出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行。
另外,同一个任务节点的并行子任务是不能共享slot的,所以允许slot共享之后,运行作业所需的slot数量正好就是作业中所有算子并行度的最大值。这样一来,我们考虑当前集群需要配置多少slot资源时,就不需要再去详细计算一个作业总共包含多少个并行子任务了,只看最大的并行度就够了。
任务槽和并行度的关系
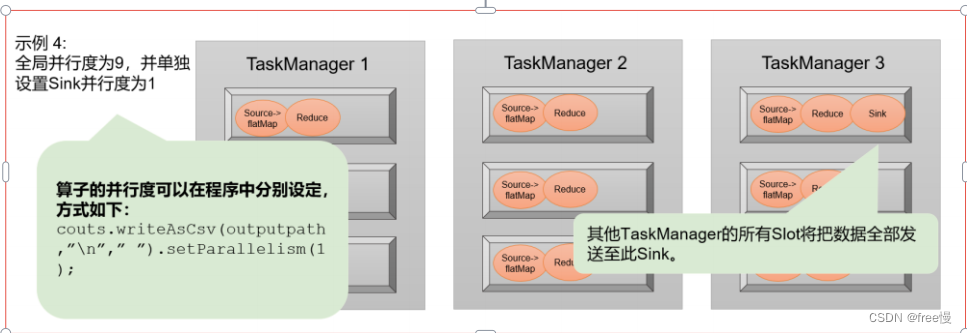
Slot和并行度确实都跟程序的并行执行有关,但两者是完全不同的概念。简单来说,task slot是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度(parallelism)是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。换句话说,并行度如果小于等于集群中可用slot的总数,程序是可以正常执行的,因为slot不一定要全部占用,有十分力气可以只用八分;而如果并行度大于可用slot总数,导致超出了并行能力上限,那么心有余力不足,程序就只好等待资源管理器分配更多的资源了。
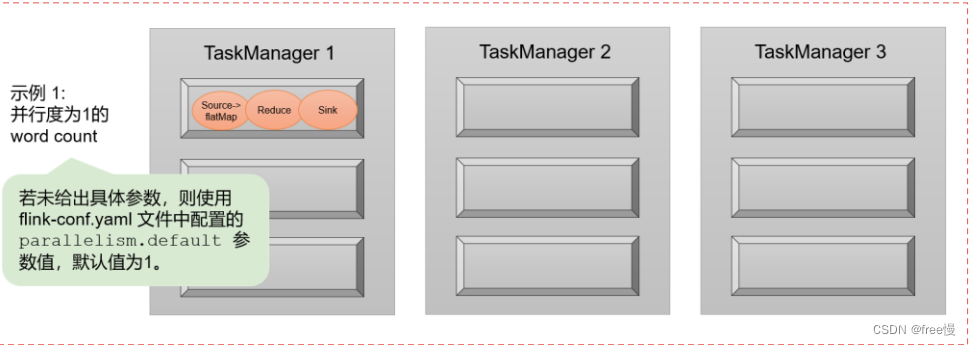
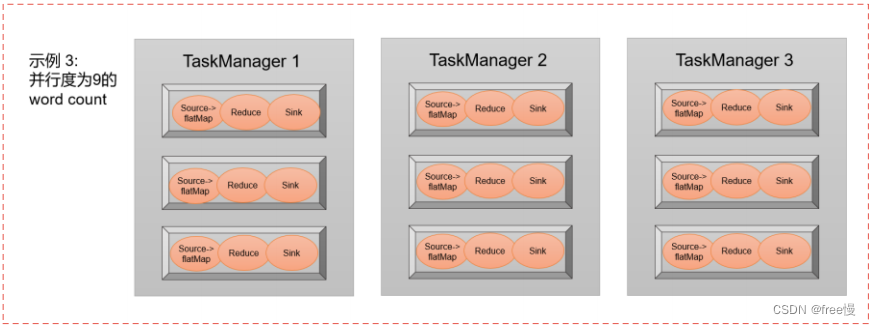
例如,我们现在搭建了一个Flink集群,3台机器(3个TaskManager),每个TaskManager的Slot数量设置为3,则我们现在有9个Slot。

现在我们在集群上运行一个Job,并行度设置为1,这个时候如果开启了Slot共享,则只会使用一个Slot,其余八个Slot空闲。
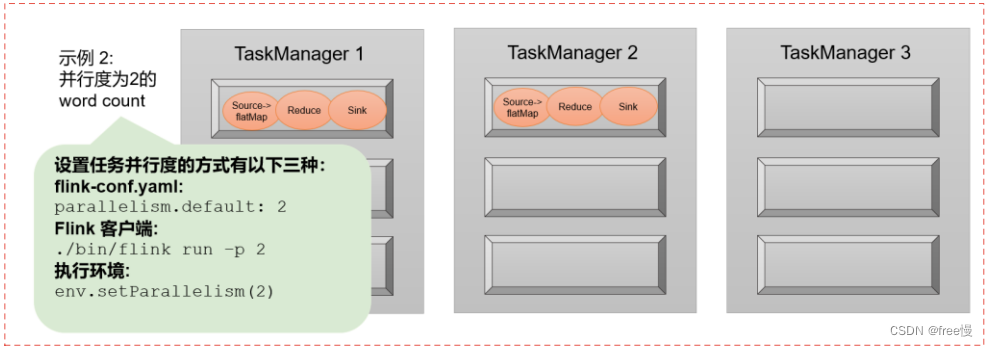
如果并行度设置为2,这个时候JobManage会分配2个Slot用于执行任务。
如果并行度设置为9,这个时候JobManage会分配9个Slot用于执行任务。
这篇关于Flink中任务(Tasks)和任务槽(Task Slots)详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







