本文主要是介绍SpringCache和redis区别?什么是SpringCache?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、Redis介绍
- 1.1 Redis缓存
- 1.2 redis缓存使用前提
- 1.3 redis使用缓存的时机
- 二、实际操作案例
- 2.1 常规准备工作
- 2.2 引入配置redis
- 2.2.1 引入redis的启动依赖
- 2.2.2 在application.yml里面配置redis的地址信息等
- 2.2.3 创建redisTemplate的配置类,指定键值序列化方式
- 2.2.4 创建redis操作Brand的接口和实现类
- 2.2.5 缓存预热操作
- 2.2.6 测试
- 2.2.7 小案例总结
- 2.3 改进版案例
- 2.3.1 准备工作
- 2.3.2 修改Redis的配置
- 2.3.3 自定义注解
- 2.3.4 添加SpringAOP
- 2.3.5 测试
- 三、SpringCache
- 3.1 注解的介绍:
- 3.1.1 Cacheable注解
- 3.1.2 CachePut注解
- 3.1.3 CacheEvict注解
- 3.1.4 Caching注解
- 3.1.5 CacheConfig注解
- 3.2 SpringCache整合redis
- 3.2.1 添加依赖项,启动类添加@EnableCaching
- 3.2.2 配置yml文件
- 3.2.3 创建Redis的配置类
- 3.2.4 在方法上面使用缓存
- 3.2.5 自定义缓存管理器
- 3.2.6 小技巧
一、Redis介绍
1.1 Redis缓存
由于Redis的存取效率非常高,在开发实践中,通常会将一些数据从关系型数据库(例如MySQL)中读取出来,并写入到Redis中,后续当需要访问相关数据时,将优先从Redis中读取所需的数据,以此,可以提高数据的读取效率,并且,对一定程度的保护关系型数据库。
一旦使用Redis后,相关的数据就会同时存在于关系型数据和Redis中,即同一个数据有2份或更多(如果你使用了更多的Redis服务或其它数据处理技术),则可能出现数据不同步的问题!
如果最终出现了关系型数据库和Redis中的数据不同的问题,则称之为“数据一致性问题”。
-
更新数据库成功 -> 更新缓存失败 -> 数据不一致
-
更新缓存成功 -> 更新数据库失败 -> 数据不一致
-
更新数据库成功 -> 淘汰缓存失败 -> 数据不一致
-
淘汰缓存成功 -> 更新数据库失败 -> 查询缓存mis
1.2 redis缓存使用前提
-
高频率访问的数据
- 例如热门榜单
-
修改频率非常低的数
- 例如商品的类别
-
对于数据的“准确性”要求不高的
- 例如商品的库存余量(因为不管余量为多少,只有真正付款的时候才会去判断是否买到)
1.3 redis使用缓存的时机
关于在项目中应用Redis,首先考虑何时将MySQL中的数据读取出来并写入到Redis中!常见的策略有:
-
直接尝试从Redis中读取数据,如果Redis中无此数据,则从MySQL中读取并写入到Redis
- 从运行机制上,类似于单例模式中的懒汉式
-
当项目启动时,就直接从MySQL中读取数据并写入到Redis
-
从运行机制上,类似于单例模式中的饿汉式
-
这种做法通常称之为“缓存预热”
-
当使用缓存预热的处理机制时,需要使得某段代码是项目启动时就自动执行的,可以自定义组件类实现AppliacationRunner接口,重写其中的run( )方法,此方法将在项目启动完成之后自动调用。
二、实际操作案例
结合上面所述的,缓存应用的前提和时机,我们设定一个需求,假设:某电商网站的主页面需要显示很多的品牌信息,消费者可以点击品牌信息进入专栏,在大量用户的情况下,品牌信息无疑是需要缓存的。
品牌信息的特点:1)首先不会大量的更改,不会频繁的更改。2)因为在主页面,所以访问量特别大。
2.1 常规准备工作
常见的一些操作我这里就不演示了,代码上传至GitHub
1)创建一个spring boot的web项目
2)编写品牌类(Brand)和各个层级的基本操作(controller层、service层、mapper/dao层)
3)在浏览器上输入url测试,正常跑通就行
2.2 引入配置redis
2.2.1 引入redis的启动依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.2.2 在application.yml里面配置redis的地址信息等
spring:redis:host: 127.0.0.1port: 6379
2.2.3 创建redisTemplate的配置类,指定键值序列化方式
这里是创建了一个redisTemplate的配置类,然后value的序列化方式是json,因为我们这边需求是只对Brand进行缓存,所以泛型我直接指定了Brand。
@Configuration
public class RedisConfiguration {@Beanpublic RedisTemplate redisTemplate(RedisConnectionFactory factory){RedisTemplate<String, Brand> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(factory);
redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setValueSerializer(RedisSerializer.json());
return redisTemplate;}
}
2.2.4 创建redis操作Brand的接口和实现类
这里就是将缓存数据放入redis中,所以属于是dao层的操作,我这里命名为:IBrandRedisRepository。存入redis的前缀以brand开头,冒号分隔。
里面的操作有向redis保存单个数据,保存list数据,删除所有数据,查询数据等。
public interface IBrandRedisRepository {String BRAND_ITEM_KEY_PREFIX = "brand:item:";
String BRAND_LIST_KEY = "brand:list";
void save(Brand brand);
void save(List<Brand> brands);
Brand getById(Integer id);
List<Brand> list();
List<Brand> list(Integer start,Integer end);
Long deleteAll();
}
@Repository
public class BrandRedisRepository implements IBrandRedisRepository {
@AutowiredRedisTemplate<String,Brand> redisTemplate;
public BrandRedisRepository() {log.debug("创建处理缓存的数据访问对象");}
@Overridepublic void save(Brand brand) {redisTemplate.opsForValue().set(getKey(brand.getId()),brand);log.debug("成功向redis中写入数据:{}",brand);}
@Overridepublic void save(List<Brand> brands) {ListOperations<String, Brand> ops = redisTemplate.opsForList();for (Brand brand : brands) {ops.rightPush(BRAND_LIST_KEY,brand);}}
@Overridepublic Brand getById(Integer id) {Brand brand = redisTemplate.opsForValue().get(getKey(id));log.debug("从redis中读取的数据是{}",brand);return brand;}
@Overridepublic List<Brand> list() {int start = 0,end = -1;return list(start,end);}
@Overridepublic List<Brand> list(Integer start, Integer end) {ListOperations<String, Brand> ops = redisTemplate.opsForList();List<Brand> range = ops.range(BRAND_LIST_KEY, start, end);return range;}
@Overridepublic Long deleteAll() {Set<String> keys = redisTemplate.keys("brand:*");return redisTemplate.delete(keys);}
private String getKey(Integer id){return BRAND_ITEM_KEY_PREFIX + id;}
}
2.2.5 缓存预热操作
根据第一节的分析,缓存有一个预热的常规操作。就是在项目启动的时候,从关系型数据库中读取数据,放入缓存当中。就算是数据量很大的情况下,也只是启动的时候缓慢,是可以接受的。
创建类CachePreLoad并实现ApplicationRunner接口的run方法
@Slf4j
@Component
public class CachePreLoad implements ApplicationRunner {@AutowiredBrandService brandService;@AutowiredIBrandRedisRepository redisRepository;@Overridepublic void run(ApplicationArguments args) throws Exception {log.debug("开始缓存预热...");log.debug("从MySQL中读取品牌列表");List<Brand> brands = brandService.list();log.debug("删除Redis原有的数据");redisRepository.deleteAll();log.debug("将品牌列表写入到Redis");redisRepository.save(brands);for (Brand brand : brands) {redisRepository.save(brand);}log.debug("缓存预热完成");}
}
继承了ApplicationRunner之后,他的run方法会在项目启动之后,进行执行,达到初始化的一些功能。

根据日志输出我们可以看到,将MySQL中的数据写入了redis当中。写入过程是首先删除了redis的原始数据,然后进行单个写入和list的写入,单个写入是详细查询的时候使用,然后写入list是为了以后查询列表准备的,分页什么的。
redis中数据:
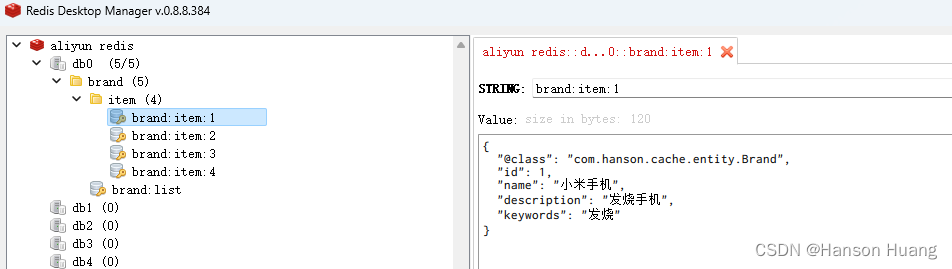
2.2.6 测试
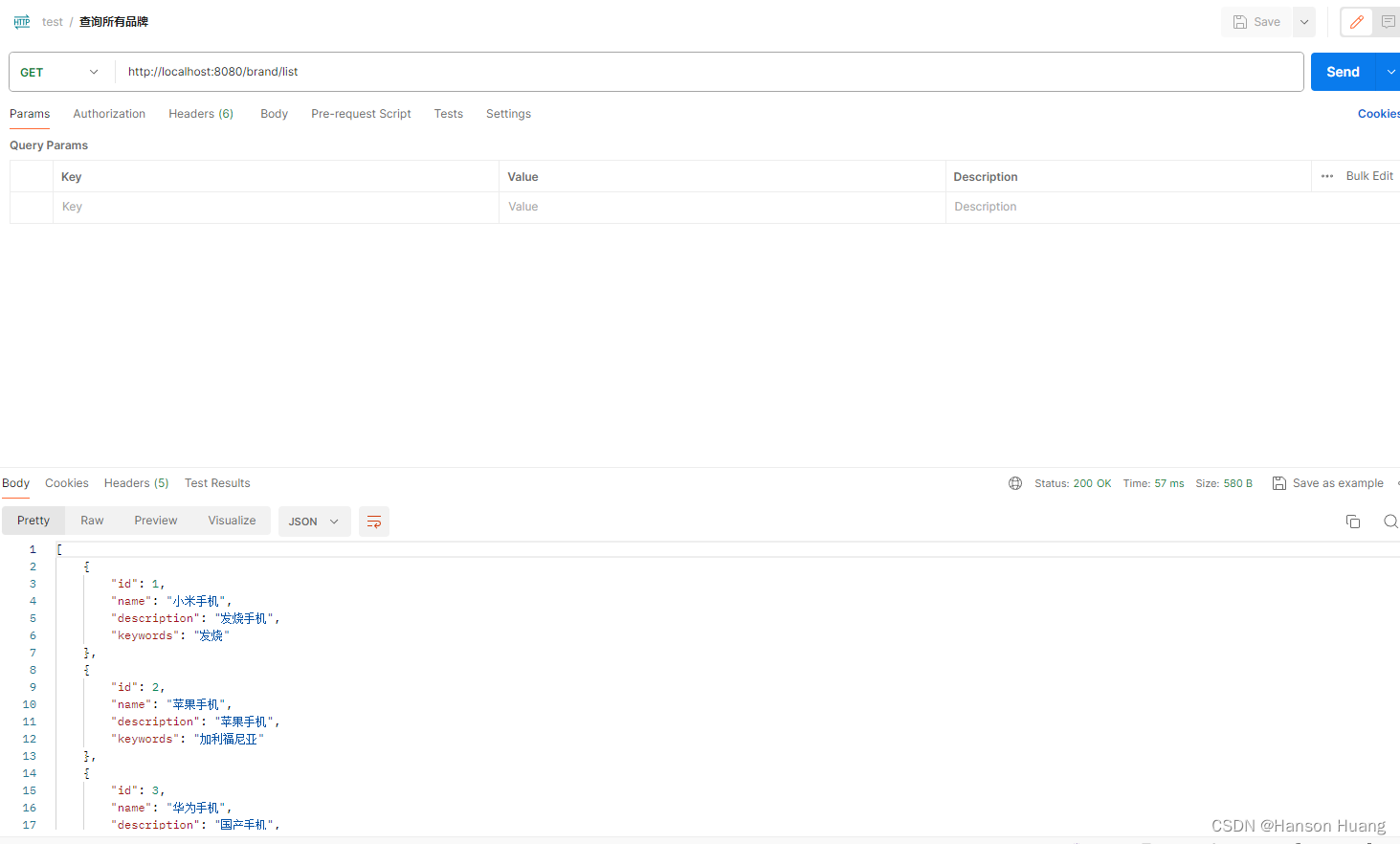
1)用浏览器或者postman请求查询接口:http://localhost:8080/brand/1,然后观察日志输出。
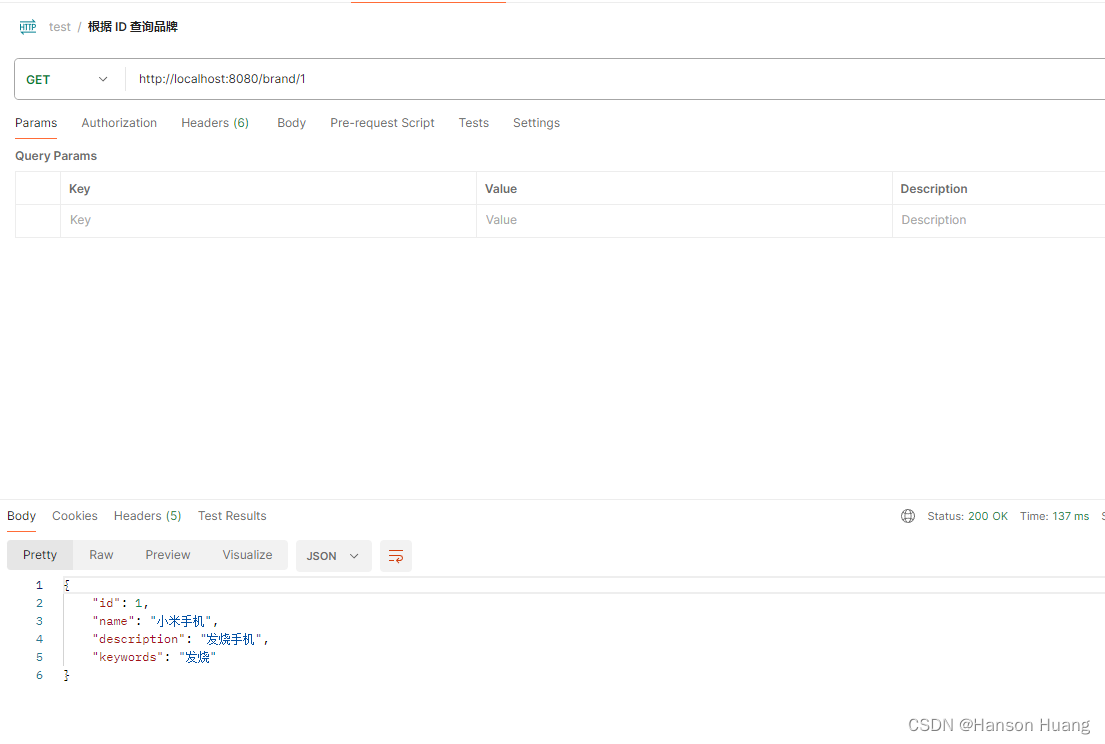
日志信息:

2)人为在数据库中新增一条数据,再访问最新数据,观察输出
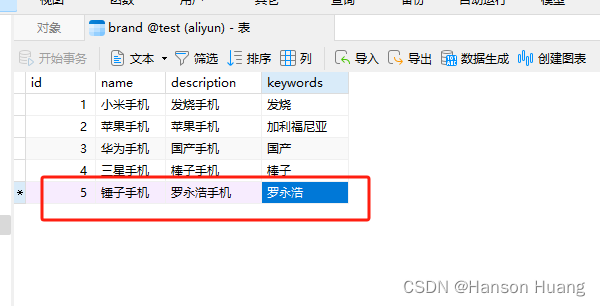

可以看到访问连续访问两次,第一次没走缓存,第二次走的是缓存
2.2.7 小案例总结
这个小案例是展示了缓存的最基本的使用原理,利用“牺牲空间,换取时间“的思想和保护数据库的目的,实现了这么一个小案例。
仍然有很多不足的地方:
- 缓存数据的淘汰策略可以使用指定过期时间的方法。
- 对于某些数据,例如:销售榜单,热搜榜等可以使用定时操作进行缓存更新,这些数据不一定要完全实时
- 操作太繁琐,每个接口都需要手动去添加一部分代码
2.3 改进版案例
针对上面的操作繁琐的问题,我这边结合Spring的AOP进行了改造。(对AOP、注解、反射不熟悉的同学可以直接看文章后面的SpringCache)
目的是:将缓存的操作抽离出来,只需要给方法添加注解,就能够自动的进行缓存的读写操作,让项目的业务操作和缓存操作进行解耦。
思路是:通过AOP编程、自定义注解和反射的机制对业务层的方法进行切面,然后在AOP中针对业务层的方法名进行缓存。
PS:
另外,在缓存淘汰策略上面我这边设置的是一分钟时间自动淘汰数据,也可以提供一个思路,在每次向Redis存入缓存数据的时候,可以使用一个HashSet记录缓存的key值,然后用一些算法自定义缓存淘汰策略,这里就不展开说了。
这也从另外一个角度说明,利用Redis进行缓存的技术是非常灵活的,可以结合自己的实际项目进行定制操作。
2.3.1 准备工作
还是使用上面那个品牌的案例,需求保持不变。上面案例的初始情况保持一致。
2.3.2 修改Redis的配置
Redis的配置是针对Brand数据类型的,不利于扩展,这里将值修改为Object类型,让任何数据类型都能进行缓存
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory factory){RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(factory);
redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setValueSerializer(RedisSerializer.json());
return redisTemplate;
}
2.3.3 自定义注解
这里自定义一个注解CacheAnnotation,让注解能够被添加到方法上并且在运行时期也能继续生效
ps:这里可以给注解添加参数,达到缓存使用的多样性,或者是通过配置文件传值的方式进行缓存的控制。
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface CacheAnnotation {
}
2.3.4 添加SpringAOP
我们创建一个类CacheAOP,在类上添加@Aspect注解,用来专门对缓存进行AOP操作。对AOP不熟悉的同学要先学习一下AOP相关的操作。
1)创建CacheAOP类
2)自动注入RedisTemplate
3)定义好切入点(这里切入的是项目中的service层
4)定义好切面,进行缓存的处理
@Slf4j
@Aspect
@Component
public class CacheAOP {/*** 自动注入RedisTemplate*/@AutowiredRedisTemplate redisTemplate;/*** 定义切入点:返回值任意,service包下所有的方法,参数值任意*/@Pointcut("execution(* com.hanson.cache.service..*(..))")public void pointCut() {}/*** 定义切面:* 1.获得方法的类对象-->通过Class对象获得方法的Method对象* 2.获得方法的签名-->通过签名拿到方法的名称,参数类型-->获得方法的Method对象* 3.获得方法的参数的值-->作为缓存数据读写的key值** @param pjp* @return* @throws Throwable*/@Around("pointCut()")public Object cacheOption(ProceedingJoinPoint pjp) throws Throwable {// 拿到该方法的类对象Class<?> cls = pjp.getTarget().getClass();// 拿到方法签名MethodSignature signature = (MethodSignature) pjp.getSignature();// 拿到方法名称String methodName = signature.getName();// 拿到参数类型Class[] parameterTypes = signature.getParameterTypes();// 获取方法类对象Method method = cls.getMethod(methodName, parameterTypes);if (!method.isAnnotationPresent(CacheAnnotation.class)) {Object proceed = pjp.proceed();return proceed;}//如果被自定义的注解标注,调用getRedisKey,获得key值String redisKey = getRedisKey(signature, pjp, cls, methodName);log.debug("最后的RedisKey值是:{}", redisKey);//通过redisTemplate查询redis对应key的值Object result = redisTemplate.opsForValue().get(redisKey);//如果不为空:直接返回这个值,不执行调用的方法if (result != null){log.debug("从redis中拿到的数据:{}",result);return result;}// 执行方法 获取返回值Object proceed = pjp.proceed();log.debug("从数据库中拿到的数据:{}",proceed);//将返回值存入redis当中作为缓存数据,过期时间为一分钟redisTemplate.opsForValue().set(redisKey,proceed,1L, TimeUnit.MINUTES);return proceed;}/*** 拿到类名,方法名,参数名,参数值;然后拼接成一个字符串,类似于:BrandServiceImpl:getById:id{6}* 这个字符串作为缓存数据的key值** @param signature* @param pjp* @param cls* @param methodName* @return 返回缓存数据的key值*/public String getRedisKey(MethodSignature signature, ProceedingJoinPoint pjp, Class cls, String methodName) {// 获取传进来的参数名称String[] parameterNames = signature.getParameterNames();log.debug("参数名称:{}", parameterNames);// 获取传进来的参数值Object[] args = pjp.getArgs();log.debug("args的值是:{}", args);// 获取类名String clsName = cls.getName();log.info("className的值是:{}", clsName);StringBuilder redisKey = new StringBuilder(clsName.substring(clsName.lastIndexOf(".") + 1, clsName.length()));redisKey.append(":" + methodName);for (int i = 0; i < parameterNames.length; i++) {redisKey.append(":");redisKey.append(parameterNames[i]);redisKey.append("{");redisKey.append(args[i]);redisKey.append("}");}if (parameterNames.length == 0) {redisKey.append(":NoArgs");}return redisKey.toString();}
}
2.3.5 测试
1)连续访问两次同一个接口,先从数据库拿到,再从redis缓存中拿到

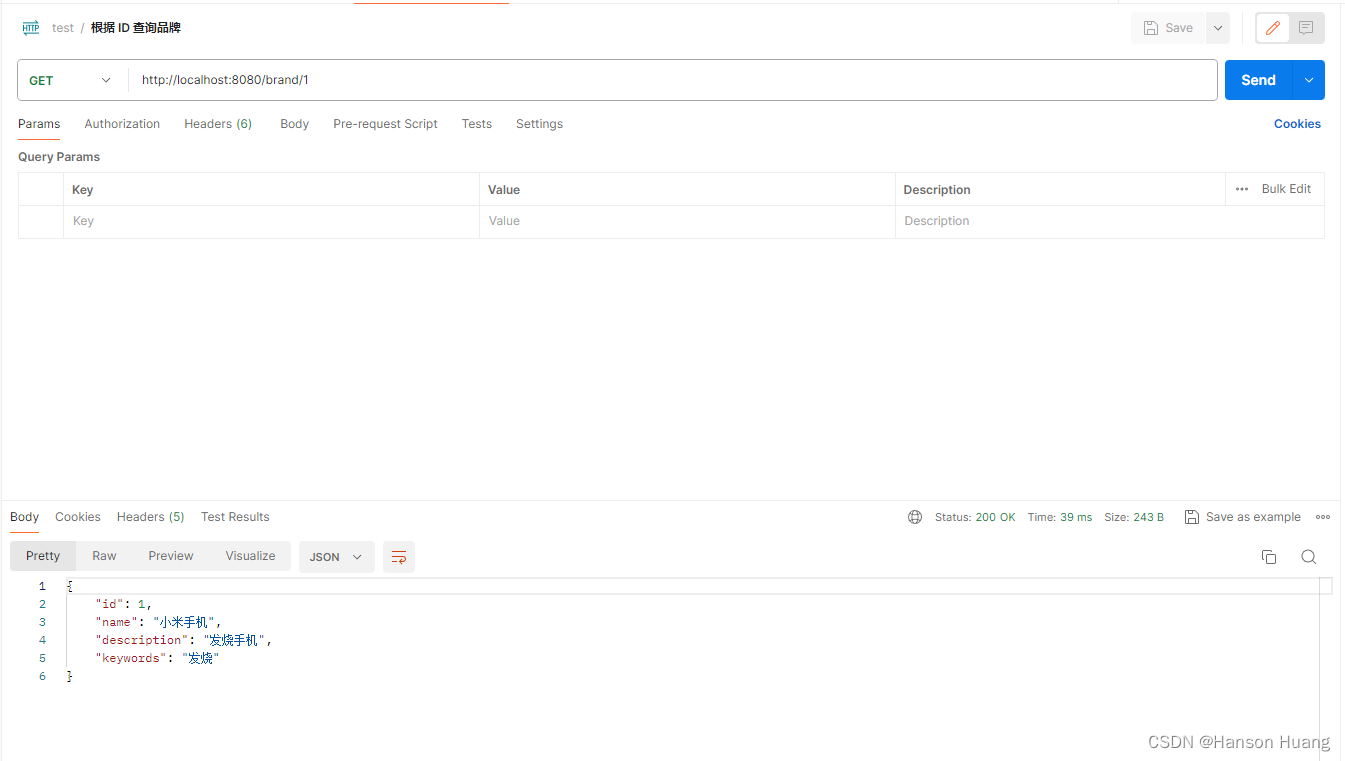
2)访问不同的接口(数据类型不一致)测试通用性
可以看到这样操作缓存的健壮性和可扩展性是很好的,可以在此基础上进行功能的添加,功能一旦完善了,那就是下一个缓存框架的问世了。
三、SpringCache
做了很多的铺垫,其实Spring给我们提供了一个开箱即用的缓存机制,SpringCache提供几个少量的注解,就能实现多种缓存的实现,例如Caffeine、Redis等。这里介绍的是结合Redis使用。
3.1 注解的介绍:
只要了解相应的配置和注解就能够举一反三,不一定使用redis作为你项目的缓存。
3.1.1 Cacheable注解
将方法返回值加入缓存。同时在查询时,会先从缓存中取,若不存在才再发起对数据库的访问。在后续调用时(使用相同的参数),返回缓存中的值,而不必实际调用该方法。
注解参数:
1)value:指定缓存的名称,也可以说是缓存的prefix
例如:@Cacheable(value=”mycache”)
2)key:缓存的 key,可以为空,如果指定要按照 SpringEL 表达式编写,如果不指定,则缺省按照方法的所有参数进行组合
例如:@Cacheable(value=”mycache”,key=”#user.id”);表示方法传入的参数User对象的id作为Key
3)condition:缓存的条件,可以为空,使用 SpringEL 编写,返回 true 或者 false,只有为 true 才进行缓存
例如:@Cacheable(value=”mycache”,condition=”#user.age>18”);表示方法传入的参数User对象,如果User
4)cacheManager:缓存管理器,可以为不同的方法使用不同的缓存策略,例如缓存数据的保存时间为一分钟,或者是保存时间为一天。
3.1.2 CachePut注解
能够根据方法的请求参数对其结果进行缓存,和 @Cacheable 不同的是,它每次都会触发真实方法的调用。当需要在不干扰方法执行的情况下更新缓存时,可以使用@CachePut注释。也就是说,始终调用该方法,并将其结果放入缓存。它支持与@Cacheable相同的选项,应该用于缓存填充。
用人话来说:就是你在更新数据库的时候,要同步更新缓存数据,就用这个注解。
3.1.3 CacheEvict注解
能够根据一定的条件对缓存进行清空,对于从缓存中删除过时或未使用的数据非常有用。与@Cacheable相反,@CacheEvict 定义了执行缓存逐出的方法(即充当从缓存中删除数据的触发器的方法)。
注解参数:
跟Cacheable一样,拥有那三属性,同时还有一个allEntries属性,该属性默认为false,当为true时,删除该value所有缓存。
3.1.4 Caching注解
有时候我们可能组合多个Cache注解使用;比如用户新增成功后,我们要添加id–>user;username—>user;email—>user的缓存;此时就需要@Caching组合多个注解标签了。
@Caching(put = {
@CachePut(value = "user", key = "#user.id"),
@CachePut(value = "user", key = "#user.username"),
@CachePut(value = "user", key = "#user.email")
})
public User save(User user) {
}
3.1.5 CacheConfig注解
CacheConfig是一个类级别的注解。
所有的@Cacheable里面都有一个value的属性,这个注解能够指定该类下面所有@Cacheable的value值。
假设我在UserService类上面添加了这个注解,并且指定了value值,那么UserService类下的所有需要缓存的方法(例如:getById( )方法)都不需要添加value值了。
3.2 SpringCache整合redis
3.2.1 添加依赖项,启动类添加@EnableCaching
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency>
@EnableCaching
@SpringBootApplication
public class RedisCacheApplication {public static void main(String[] args) {SpringApplication.run(RedisCacheApplication.class,args);}
}
3.2.2 配置yml文件
spring:datasource:url: jdbc:mysql://localhost:3306/testusername: rootpassword: rootdriver-class-name: com.mysql.cj.jdbc.Driverredis:host: localhostport: 6379cache:type: redismybatis:mapper-locations: classpath:mappers/*xmltype-aliases-package: com.hanson.cache.mybatis.entity
重点是 spring.cache.type 这个配置,SpringCache是提供了多种缓存的实现方式,redis只是其中一种。
3.2.3 创建Redis的配置类
注意:需要被缓存类(这里是Brand类)实现Serializable接口。
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<Object, Object> template = new RedisTemplate<>();template.setConnectionFactory(redisConnectionFactory);// 创建一个JSON格式序列化对象,对缓存数据的key和value进行转换Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
// 解决查询缓存转换异常的问题ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);jackson2JsonRedisSerializer.setObjectMapper(om);
template.setValueSerializer(jackson2JsonRedisSerializer);//使用StringRedisSerializer来序列化和反序列化redis的key值template.setKeySerializer(new StringRedisSerializer());
return template;
}
这个就是一个简单的RedisTemplate,只是配置了键值对的序列化方式而已,
你其实也可以这样做:都是配置一下redisTemplate
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory factory){RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(factory);
redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setValueSerializer(RedisSerializer.json());
return redisTemplate;
}
3.2.4 在方法上面使用缓存
这里代表的是:
根据Id查询品牌数据,然后开启缓存;
缓存的名称的头部是brands开头,例如:brands:xx:xx
缓存的key使用传入进来的id进行设置;
开启条件缓存,只有id是2的倍数,redis才进行缓存
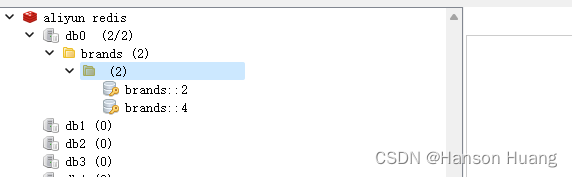
@Cacheable(value = "brands",key = "#id",condition = "#id%2==0")
public Brand getById(Integer id) {Brand brand = brandMapper.selectById(id);return brand;
}
可以看到实现效果是只有2,4,6这种偶数才进行了缓存
3.2.5 自定义缓存管理器
除了上面的这种简单做法,我们还可以自己添加一些缓存规则,这就需要用到缓存管理器了。
@Bean("cacheManager")
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory){//通过下面的instanceConfig()方法获得一个RedisCacheConfiguration;RedisCacheConfiguration configuration = instanceConfig();return RedisCacheManager.builder(connectionFactory).cacheDefaults(configuration)//设置默认参数.transactionAware()//事务感知.build();
}
private RedisCacheConfiguration instanceConfig(){return RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(60L))//设置过期时间为60秒.disableCachingNullValues();//不缓存空对象
}
然后有了缓存管理器之后,你也就可以在代码中运用他了,通过给@EnableCache的manager属性添加值就行了
@Override
@Cacheable(value = "brands",key = "#id",condition = "#id%2==0",cacheManager = "cacheManager")
public Brand getById(Integer id) {Brand brand = brandMapper.selectById(id);return brand;
}
3.2.6 小技巧
在你一定使用缓存管理器的情况下,如果你觉得给每个类都添加Serializable接口太麻烦了,可以在构建RedisCacheConfiguration的时候添上这么一句话:
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(RedisSerializer.json()))
这句话的意思就是:将Redis缓存配置的值序列化方式设置成JSON格式,最终的效果如下
@Bean("cacheManager")
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory){//通过下面的instanceConfig()方法获得一个RedisCacheConfiguration;RedisCacheConfiguration configuration = instanceConfig();return RedisCacheManager.builder(connectionFactory).cacheDefaults(configuration)//设置默认参数.transactionAware()//事务感知.build();
}
private RedisCacheConfiguration instanceConfig(){return RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(60L))//设置过期时间为60秒.disableCachingNullValues();//不缓存空对象
}
测试结果:第一次走数据库,第二次就没有数据库输出,redis里面正常保存数据
这篇关于SpringCache和redis区别?什么是SpringCache?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




