本文主要是介绍search_everything中几个重要的工具类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、拼音工具类
- 二、数据库工具类
- 三、数据库初始化
一、拼音工具类
我们要实现一个拼音搜索的功能,就要把汉字转换成拼音,我们已经导入了汉语拼音处理的jar包,首先需要创建一个拼音工具类,进行一些简单的配置:
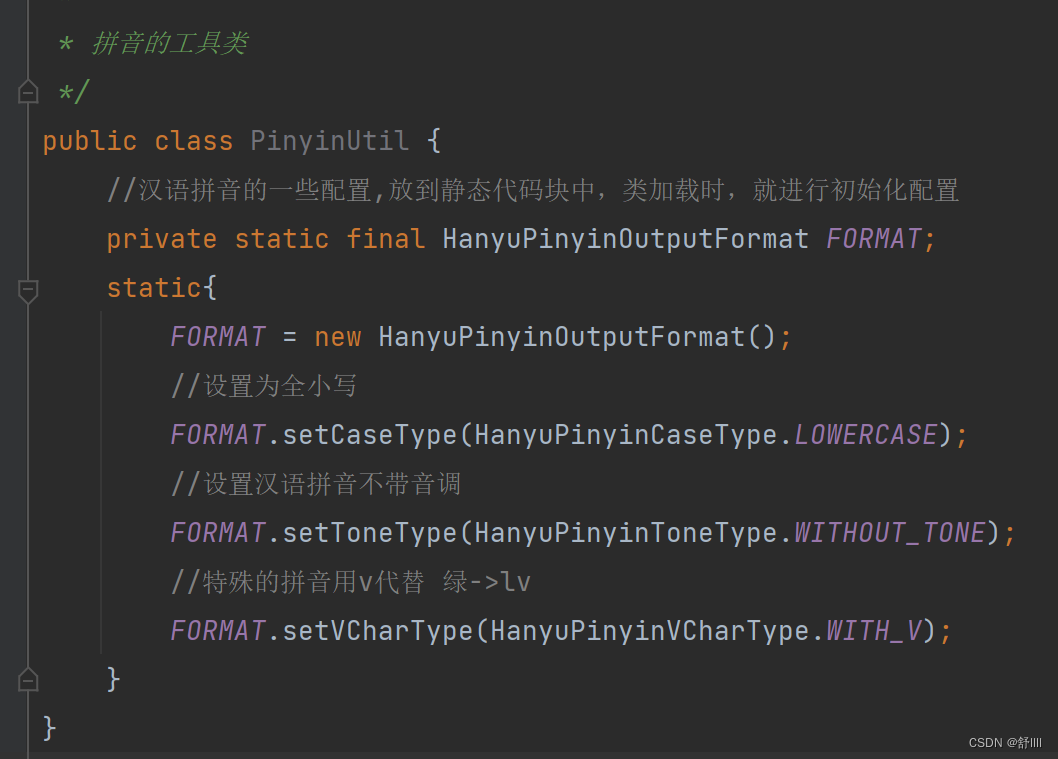
既然我们要实现能进行汉语拼音全拼和拼音缩写的搜索的话,我们就需要实现一个方法,来获取文件名中汉字的全拼和缩写:
/*** @param fileName 传入的文件名* @return {@link String[]}** 该方法的作用是:传入一个文件名,返回一个包含拼音全拼和拼音缩写的字符串数组* 若文件名中包含其它字符(英文,数字,符号等)不做处理*/public static String[] getPinyinByFileName(String fileName){//返回一个字符串数组,数组中有两个元素:拼音全拼,拼音缩写String[] ret = new String[2];//遍历文件名中的每个字符,碰到汉字,将其转换为拼音,非汉字直接拼接StringBuilder allPinyinAppender = new StringBuilder();StringBuilder firstPinyinAppender = new StringBuilder();for (char c : fileName.toCharArray()){try {String[] pinyin = PinyinHelper.toHanyuPinyinStringArray(c,FORMAT);if (pinyin == null || pinyin.length == 0){//此时说明该字符不是汉字,对其进行直接拼接allPinyinAppender.append(c);firstPinyinAppender.append(c);}else {//是汉字,取字符串数组中的第一个元素及第一个元素的第一个字符allPinyinAppender.append(pinyin[0]);firstPinyinAppender.append(pinyin[0].charAt(0));}} catch (BadHanyuPinyinOutputFormatCombination e) {//报错的话可能是其它情况,也直接保留allPinyinAppender.append(c);firstPinyinAppender.append(c);}}ret[0] = allPinyinAppender.toString();ret[1] = firstPinyinAppender.toString();return ret;}
此外,当我们把文件信息存储到数据库中时,需要通过判断文件名中是否包含汉字来决定是否保存拼音全拼和拼音首字母缩写,故此时需要一个方法来帮助我们判断文件名中是否包含汉字:
我们知道,字符串在存储时都是转为单个字符进行存储的,而Java中所有的字符都对应唯一的Unicode编码,故我们只要确定汉字的编码范围就可以判断是否包含汉字:
//Unicode中汉字的编码值范围private static final String CHINESE_PATTERN = "[\\u4E00-\\u9FA5]";/*** @return boolean** 判断文件名中是否包含汉字* 在Java中所有字符都对应不同的Unicode编码值,我们只需要中文编码的起止区间即可*/public static boolean containsChinese(String fileName) {//此处的.*就表示0-N个字符,只要包含中文就能识别出来,相当于一个模糊匹配return fileName.matches(".*" + CHINESE_PATTERN + ".*");}
二、数据库工具类
在选择完文件夹后,会启动文件扫描任务,我们可以将当前选择的文件夹下的所有文件和子文件夹信息保存到SQLite数据库中,在搜索框中进行查询时,直接在数据库中查询,不用再次进行扫描,提升查询效率。
为什么用SQLite数据库?
我们之所以用SQLite嵌入式数据库,是因为我们这个项目本身是比较轻量的,属于一个工具类的项目,如果用MySQL这个数据库的话体积过大,显得比较笨重,故选择了SQLite这样一个轻量级的嵌入式数据库。
要在Java程序中对数据库进行操作,需要进行JDBC:
1.获取数据源,设置账号密码,链接地址
2.获取数据库连接,Statement对象
3.执行Statement的查询或更新方法
4.关闭连接和Statement、ResultSet对象,关闭资源操作。
创建一个数据库的工具类,用来创建数据源,建立连接,关闭连接:
因为该项目会用到多线程,所有我们需要保证,我们的数据源在多线程场景下是唯一的,所有的线程都只能操作这一个数据源,此时需要用到单例模式:
/*** @author Shu* @date 2022/08/22** SQLite数据库的工具类,用来创建数据源,创建数据库的连接* 只提供数据库连接,不提供数据源,数据源封装在类的内部*/
public class DBUtil {//此处volatile关键字相当于内存屏障,当有多个线程操作getDataSource()方法时//t1正在对DATASOURCE进行初始化,但初始化还未完成,//此时t2读取到DATASOURCE != null,获取了尚未初始化完成的DATASOURCE对象//而使用volatile进行修饰,能保证只有当t1初始化操作完全完成时,t2才能获取到对象private volatile static DataSource DATASOURCE;/*** @return {@link DataSource}** 使用double-check单例模式来创建数据源*/private static DataSource getDataSource(){if (DATASOURCE == null){//锁的是DBUtil这个类//保证只有一个线程能进入同步代码块,创建对象.synchronized (DBUtil.class){//进入同步代码块后需要再次确认DATASOURCE是否为空,防止其它线程进入同步代码块后多次创建对象if (DATASOURCE == null){//SQLite没有账号密码,只需要配置日期格式SQLiteConfig config = new SQLiteConfig();config.setDateStringFormat(Util.DATE_PATTERN);DATASOURCE = new SQLiteDataSource();//配置SQLite的URL是SQLiteDataSource类独有的方法,需要向下转型((SQLiteDataSource)DATASOURCE).setUrl(getUrl());}}}return DATASOURCE;}/*** @return {@link String}** 配置SQLite数据库的地址* 对于SQLite而言,它其实就相当于一个文件夹,没有服务端和客户端,只需要配置地址*/public static String getUrl(){//我们创建的数据源会放在当前项目的target目录下String path = "D:\\项目\\search_everything\\target";String url = "jdbc:sqlite://" + path + File.separator + "search_everything.db";return url;}/*** @return {@link Connection}* @throws SQLException** 获取数据库的连接*/public static Connection getConnection() throws SQLException {return getDataSource().getConnection();}
}
注意:以上代码都是适用于单线程下的,当我们要在多线程下执行时,因为SQLite是一个单文件的数据库,在多线程场景下操作SQLite,必须保证多线程使用的是同一个数据库连接,此前我们直接使用数据源的getConnection()方法,但它的内部其实是会创建一个新的连接,在单线程模式下能保证只操作一个连接,但多线程使可能会创建多个不同的连接,此时getConnection()方法需要做一定改动,使数据库连接为单例模式,使每个线程获取的都是同一个连接:
private volatile static Connection CONNECTION;
public static Connection getConnection() throws SQLException {if (CONNECTION == null){synchronized (DBUtil.class){if (CONNECTION == null){CONNECTION = getDataSource().getConnection();}}}return CONNECTION;}
多线程下还需要注意的一点是:此时连接使用完后不能直接关闭了,因为多个线程使用的是同一个连接:
/*** 多线程模式下,每个线程获取的都是同一个连接,此时我们就不能使用完连接之后就直接关闭了*/public static void close(Statement statement) {if (statement != null){try {statement.close();} catch (SQLException e) {System.err.println("statement资源关闭失败");e.printStackTrace();}}}public static void close(Statement statement, ResultSet resultSet){close(statement);if (resultSet != null){try {resultSet.close();} catch (SQLException e) {System.err.println("resultSet资源关闭失败");e.printStackTrace();}}}
三、数据库初始化
既然数据库已经创建了,我们就需要创建一张表来存储我们需要展示的信息:

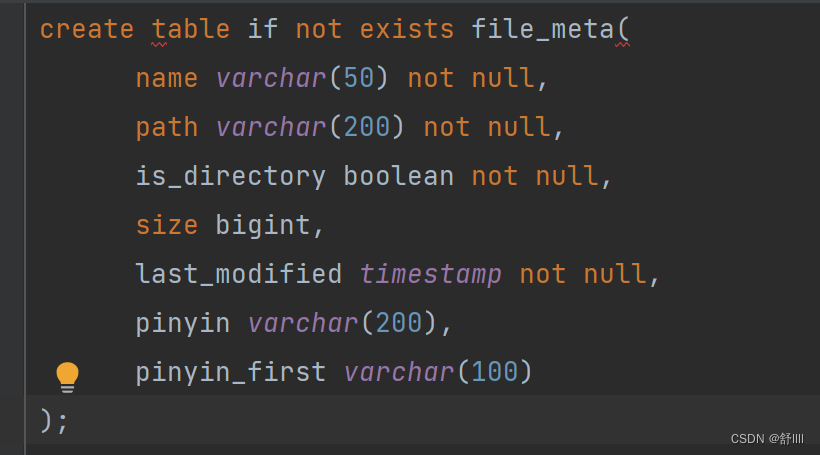
此时我们需要创建一个数据库初始化的类,在界面初始化时创建文件信息数据表
/*** @author Shu* @date 2022/08/23** 界面初始化时初始化我们的数据表*/
public class DBInit {/*** 从resources路径下的init.sql文件中读取sql语句到程序中* @return {@link List}<{@link String}>*/public static List<String> readSQL(){List<String> ret = new ArrayList<>();//拿到init.sql文件的输入流//此处首先考虑的是使用绝对路径读取到sql文件,但若是项目位置改变了的话,就会找不到该文件//于是考虑使用相对路径,但当把项目打成jar包时,编译依然报错//因为编译之后就不存在资源文件夹了,所有资源文件都放在target目录下classes文件夹中//最终解决方案:采用类加载其的方式引入资源文件,这是处理相对路径的通用写法InputStream in = DBInit.class.getClassLoader().getResourceAsStream("init.sql");Scanner sc = new Scanner(in);//此处我们需要自定义分隔符,因为sql语句它是以;作为结尾sc.useDelimiter(";");while (sc.hasNext()){String str = sc.next();if (str.equals(" ") || str.equals("\n")){continue;}ret.add(str);}return ret;}
}
之后再使用JDBC执行我们读取到的sql语句,创建数据表
public static void init(){Connection connection = null;Statement statement = null;try {connection = DBUtil.getConnection();List<String> list = readSQL();statement = connection.createStatement();for (String s : list) {System.out.println("执行sql语句: " + s);statement.executeUpdate(s);}} catch (SQLException e) {System.err.println("数据库初始化失败");e.printStackTrace();}finally {DBUtil.close(connection,statement);}}
执行该方法后,就可以看到我们创建的数据表了:
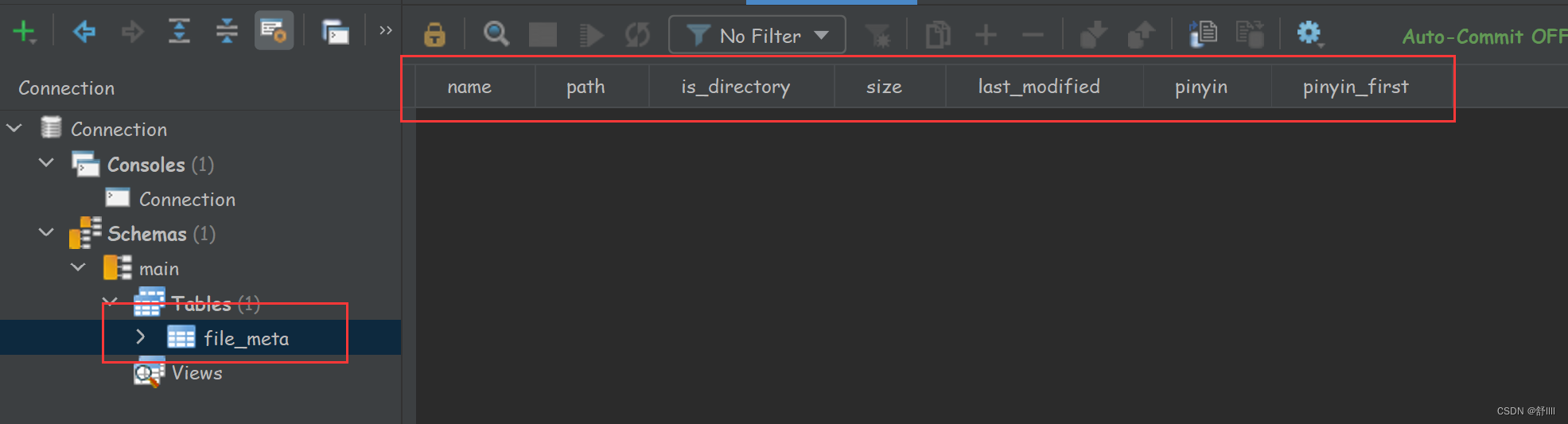
这篇关于search_everything中几个重要的工具类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






