本文主要是介绍【C++初阶】第七站:string类的初识(万字详解、细节拉满),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
📍本文知识点:string的初识
本专栏:C++

目录
一、什么是STL
二、STL的六大组件
三、STL的缺陷
四、为什么学习string类?
五、标准库中的string类
1、string类(了解)
2、string类的常用接口说明(最常用的接口)
A. string类对象的常见构造
B.string类的成员函数的使用
1、for+operator [ ]
2、范围for遍历
3、迭代器遍历
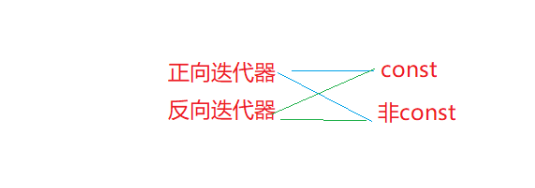
反向迭代器
const修饰的迭代器
4.💥取字符串💥
C.string类对象的容量操作
size、length、capacity、clear 、max_size,:
❓来写一道题:387. 字符串中的第一个唯一字符
reserve
resize
at 下标自增
D.string类对象的修改操作
push_back、append、+=、+:
assgin
insert
erase
replace
swap
find、rfind、substr
取出url协议、域名、uri:
find_first_of 和 find_first_not_of
一、什么是STL
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。
二、STL的六大组件

三、STL的缺陷
1. STL库的更新太慢了。这个得严重吐槽,上一版靠谱是C++98,中间的C++03基本一些修订。C++11出来已经相隔了13年,STL才进一步更新。
2. STL现在都没有支持线程安全。并发环境下需要我们自己加锁。且锁的粒度是比较大的。
3. STL极度的追求效率,导致内部比较复杂。比如类型萃取,迭代器萃取。
4. STL的使用会有代码膨胀的问题,比如使用vector/vector/vector这样会生成多份代码,当然这是模板语法本身导致的。
四、为什么学习string类?
1、C语言中的字符串
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
五、标准库中的string类
1、string类(了解)
string类的文档介绍
📌总结:
1. string是表示字符串的字符串类
2. 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
3. string在底层实际是:
basic_string模板类的别名,typedef basic_string<char, char_traits, allocator> string;
4. 不能操作多字节或者变长字符的序列。
在使用string类时,必须包含#include头文件以及using namespace std;
2、string类的常用接口说明(最常用的接口)
A. string类对象的常见构造
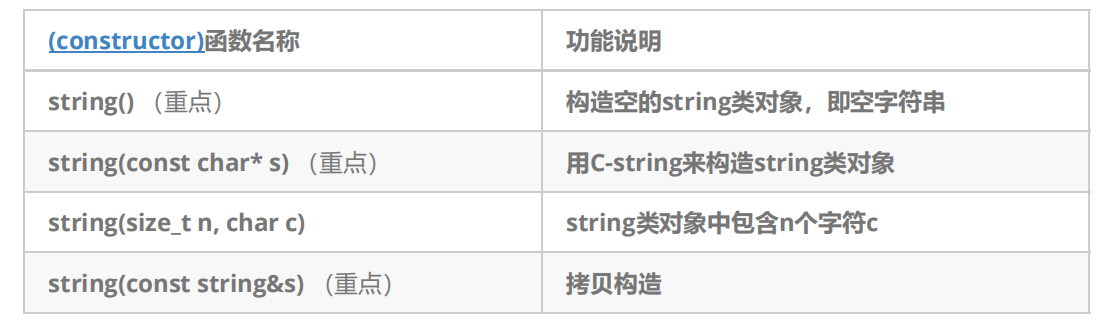
#include<iostream>
#include<string>
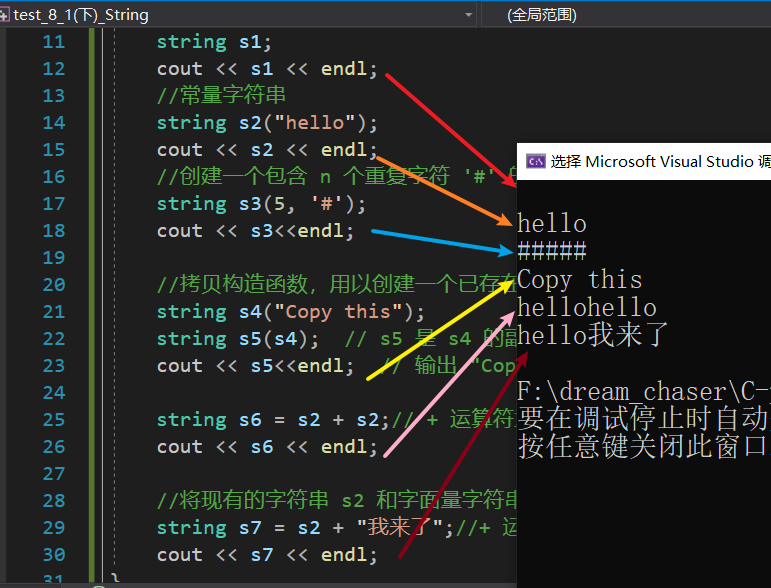
using namespace std;void test_string1()
{//空构造函数string s1;cout << s1 << endl; //常量字符串 //(优化成直接构造)string s2("hello");//等价<-->string s2 = "hello world";//构造+拷贝构造 cout << s2 << endl;//创建一个包含 n 个重复字符 '#' 的字符串string s3(5, '#');cout << s3<<endl;//拷贝构造函数,用以创建一个已存在字符串对象的副本string s4("Copy this");string s5(s4); // s5 是 s4 的副本cout << s5<<endl; // 输出 "Copy this"string s6 = s2 + s2;// + 运算符重载,构造,拷贝构造cout << s6 << endl;//将现有的字符串 s2 和字面量字符串 "我来了" 进行拼接string s7 = s2 + "我来了";//+ 运算符重载,字符串拼接,拷贝构造函数cout << s7 << endl;
}
int main()
{test_string1();
}
B.string类的成员函数的使用

1、for+operator [ ]
void test_string2()
{string s1 = "hello world";//for形式遍历//遍历stringfor (size_t i = 0; i < s1.size(); i++){//读cout << s1[i] << " ";}cout << endl;//s1里面的每一个字符的对应的十进制都+1,之后原本字符会变成新字符for (size_t i = 0; i < s1.size(); i++){//写s1[i]++;}cout << s1 << endl;
}
2、范围for遍历

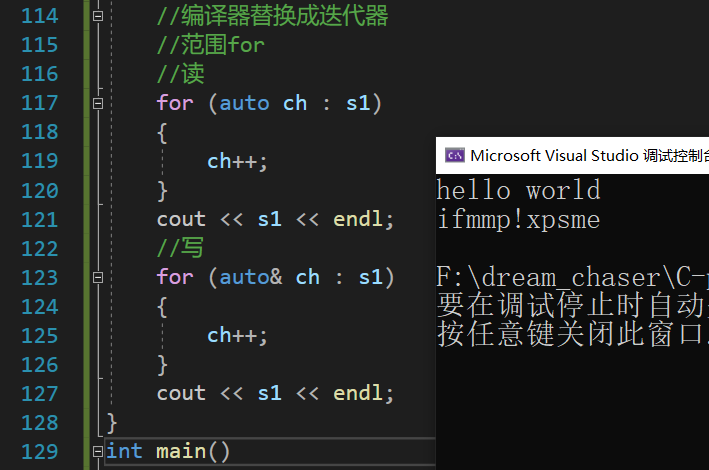
void test_string3()
{//编译时编译器替换成迭代器,范围for的底层跟迭代器是完全类似的//范围for//读for (auto ch : s1){ch++;}cout << endl; //写for (auto& ch : s1){ch++;}cout << endl;cout << s1 << endl;
}
3、迭代器遍历
使用迭代器遍历我们需要了解String中的Iterators成员函数:

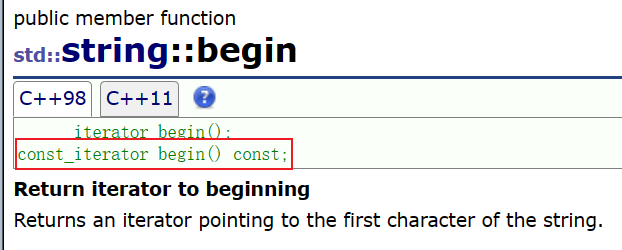
begin():返回一个指向字符串的第一个字符的迭代器
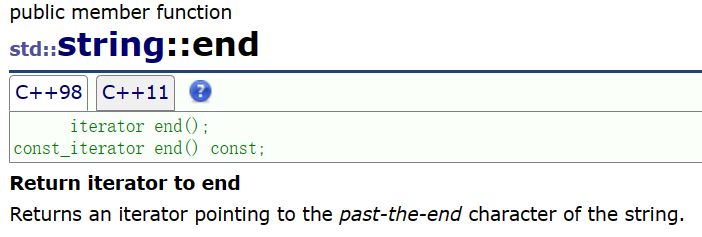
end():返回一个迭代器,该迭代器指向了字符串的最后一个字符的下一个位置( '\0' )

迭代器:像指针一样的东西,有可能是指针,也有可能不是指针,但使用方法是像指针一样的东西

void test_string2()
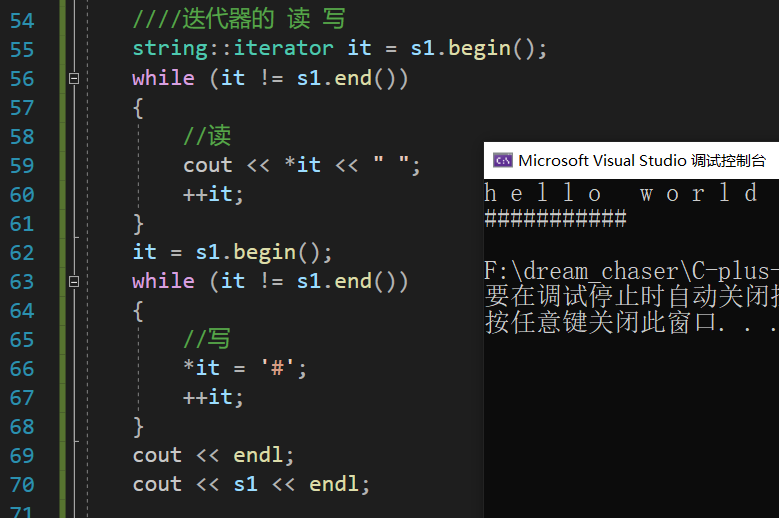
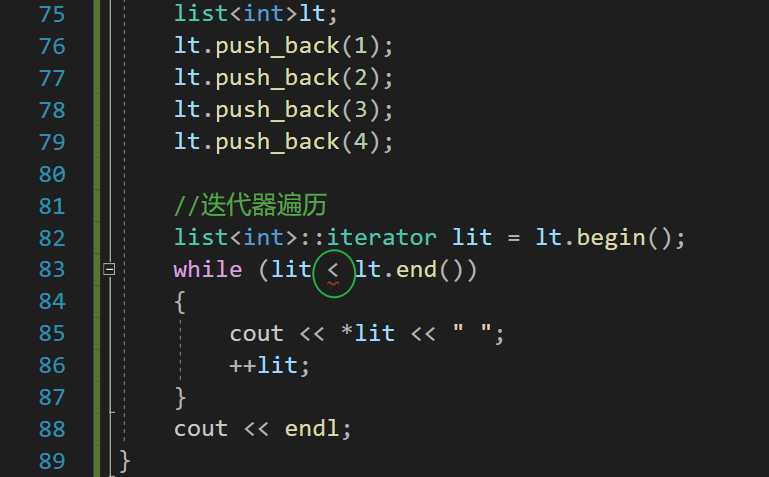
{string s1 = "hello world"//string不能省掉,省掉就报错string::iterator it = s1.begin();//返回一个迭代器,指向字符串的第一个字符//推荐玩法,通用--> !=while (it != s1.end())//返回一个指向字符串的最后一个字符的迭代器{//读cout << *it << " ";++it;}it = s1.begin();while (it != s1.end()){//写*it = '#';++it;}cout << endl;cout << s1 << endl;
}
💨注意:while循环条件这里可以用 < 吗?
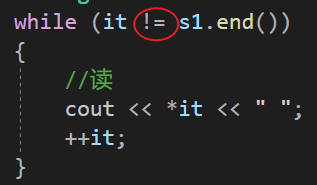
可以但是不建议:
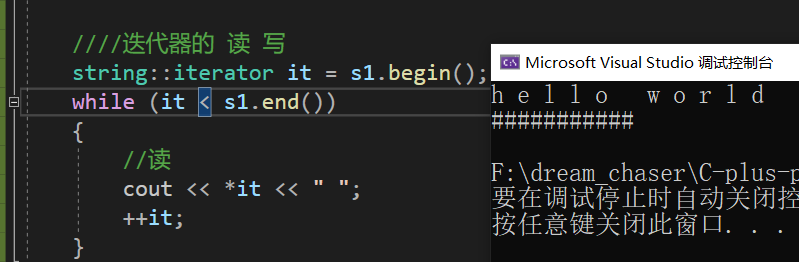
(为什么可以,因为string的物理空间是连续的,说明地址是从小到大变化的,当然可以使用< 比较) 所以说,list、vector这样的连续的物理空间的数据结构,可以使用数组的方式遍历
关于迭代器:
而string、list、vector的迭代器都是通用的 ,都可以用迭代器遍历的方式遍历元素,包括以后的树形结构、哈希结构,都可以使用迭代器遍历
总结:在C++标准模板库(STL)中,所有标准容器均支持迭代器
🎯但是对于list来说,它的物理空间并不一定是连续的,它是由一个带哨兵位的头节点,外加一个个的小节点构成:
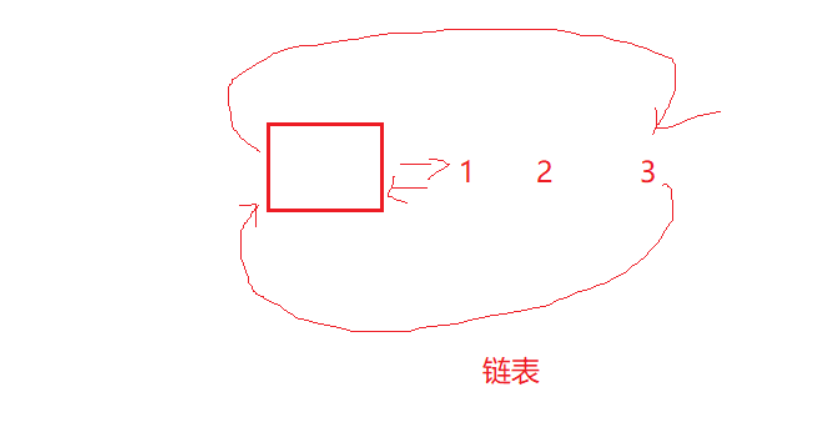
所以list的物理空间不一定是连续的,lit指向的字符串开头的地址不一定小于end指向的地址:
总结:🚩
所以!=才是通用的。
示范代码:
void test_string2()
{list表示使用STL中的list容器模板类。<int> 是模板参数,表明列表中存储的数据类型是整数(int)。lt 是声明的list对象名称,即创建了一个可以存放整数的双向链表。list<int>lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);//迭代器遍历list<int>::iterator lit = lt.begin();while (lit != lt.end()){cout << *lit << " ";++lit;}cout << endl;
}
反向迭代器
- 有正向迭代器,那么有反向迭代器吗?
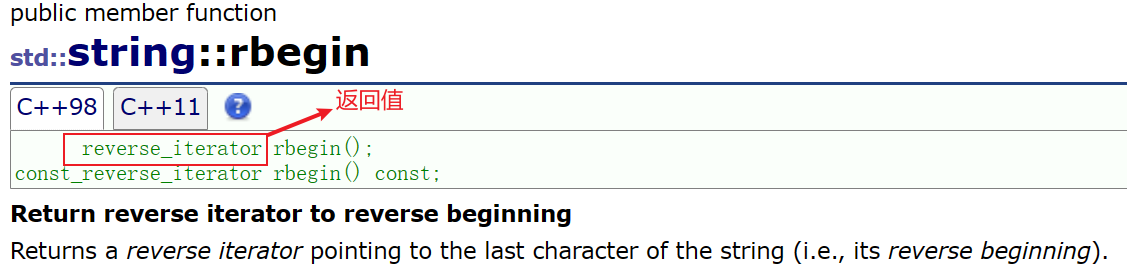
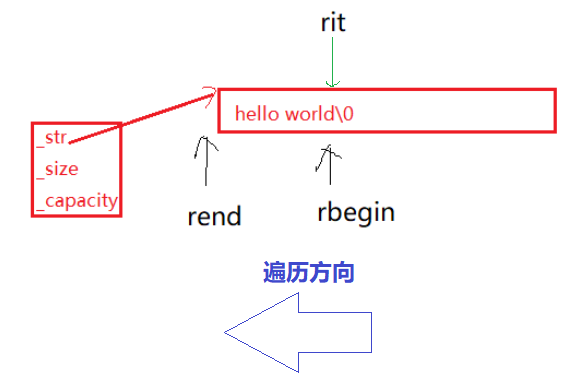
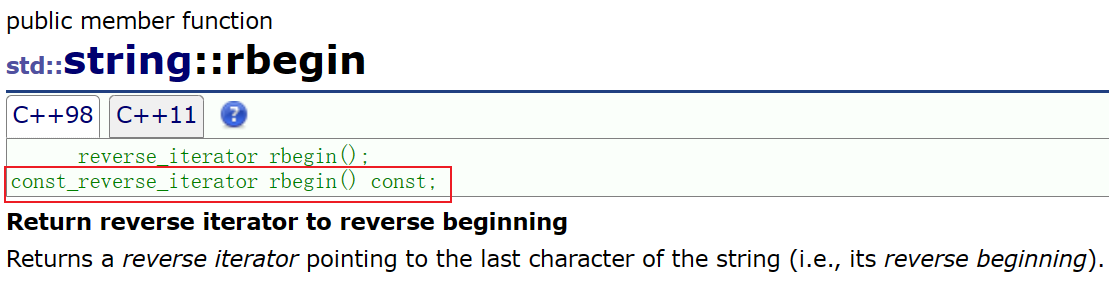
rebegin():返回一个反向的迭代器,该迭代器指向字符串的最后一个字符
rend():返回一个反向迭代器,该迭代器指向字符串的第一个字符前面的理论元素(下标为-1)。

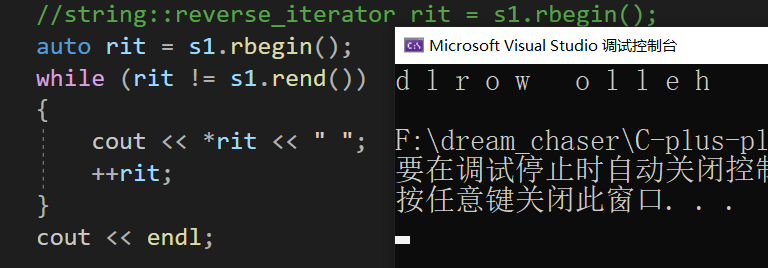
void test_string3()
{string s1("hello world");string::reverse_iterator rit = s1.rbegin();//等价 👇//auto rit = s1.rbegin();while (rit != s1.rend()){cout << *rit << " ";++rit;}cout << endl;}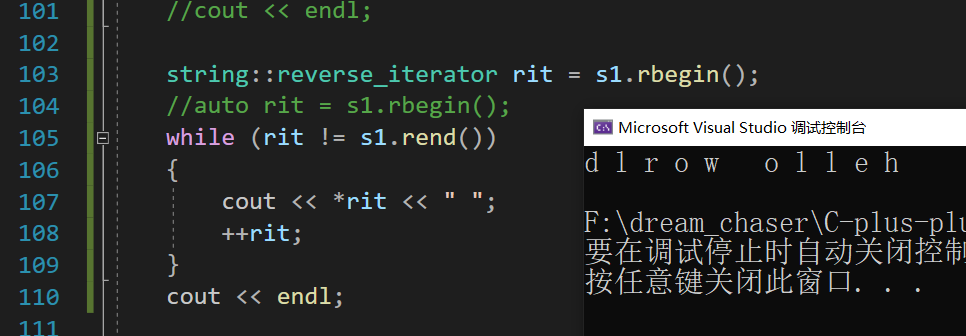
我们也可以使用auto来自动判断类型:
const修饰的迭代器
被const修饰的迭代器 -- 只能读,不能写,因为它是给const对象访问的
//const string
void func(const string& s)
{//string::const_iterator it = s.begin();auto it = s.begin();while (it != s.end()){//不支持写//*it = 'a';//读cout << *it << " ";++it;}cout << endl;//string::const_reverse_iterator rit = s.rbegin();auto rit = s.rbegin();while (rit != s.rend()){cout << *rit << " ";++rit;}cout << endl;
}
void test_string4()
{string s1("apple pie");func(s1);
}执行:
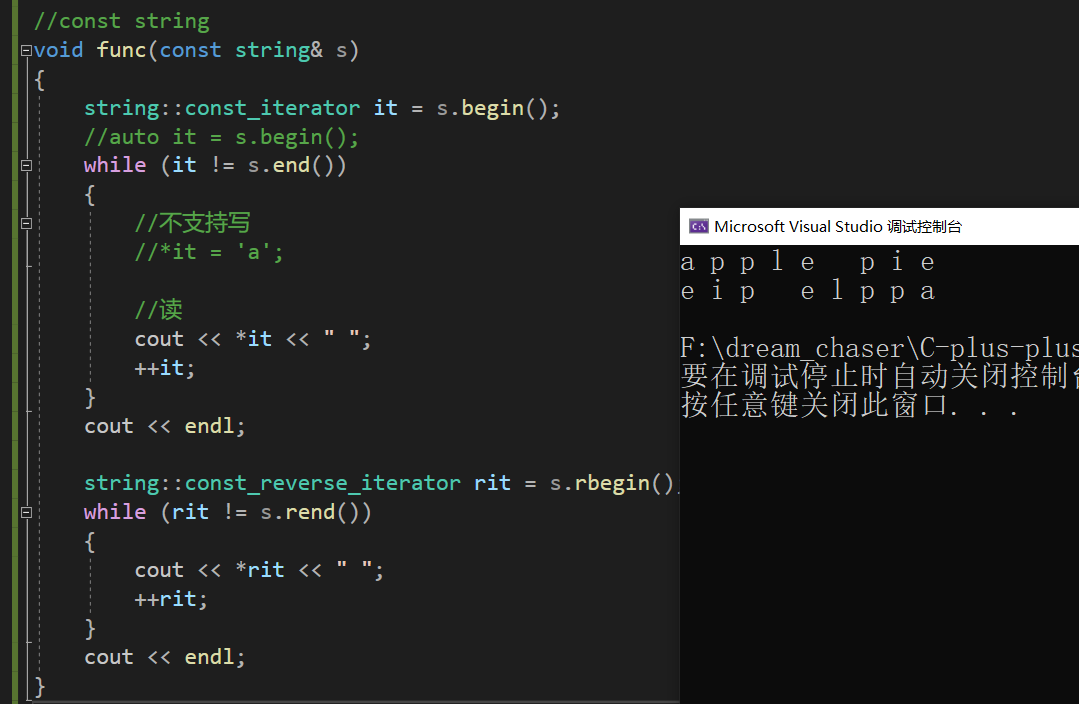
我们当然也可以使用auto简化代码:
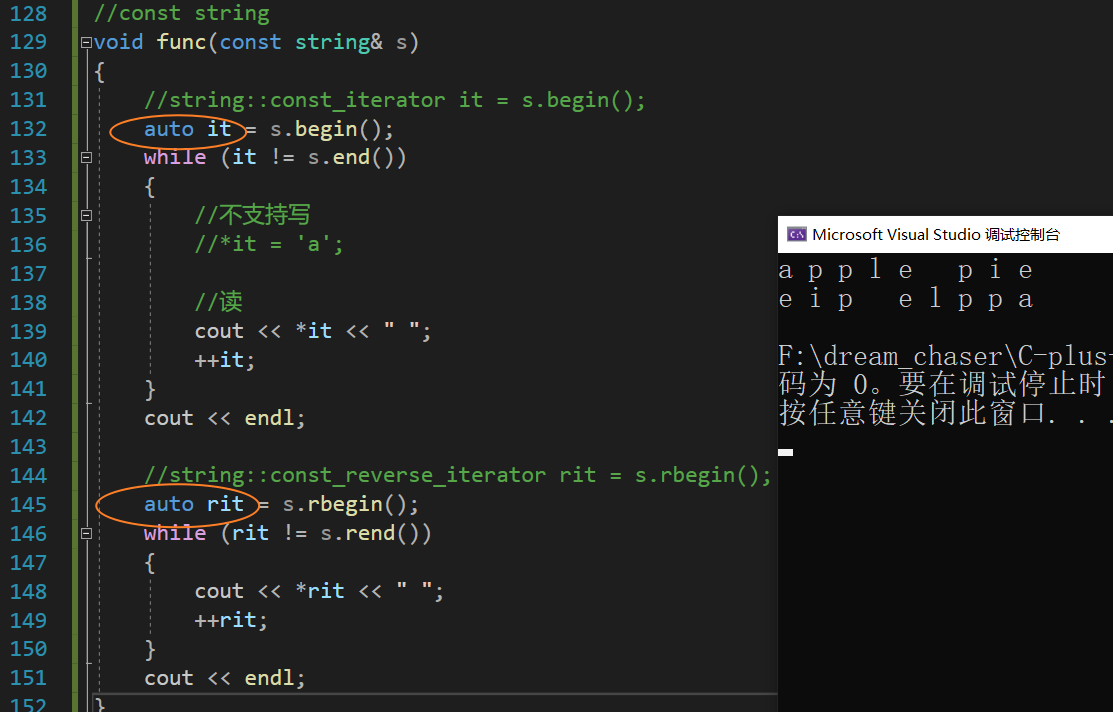
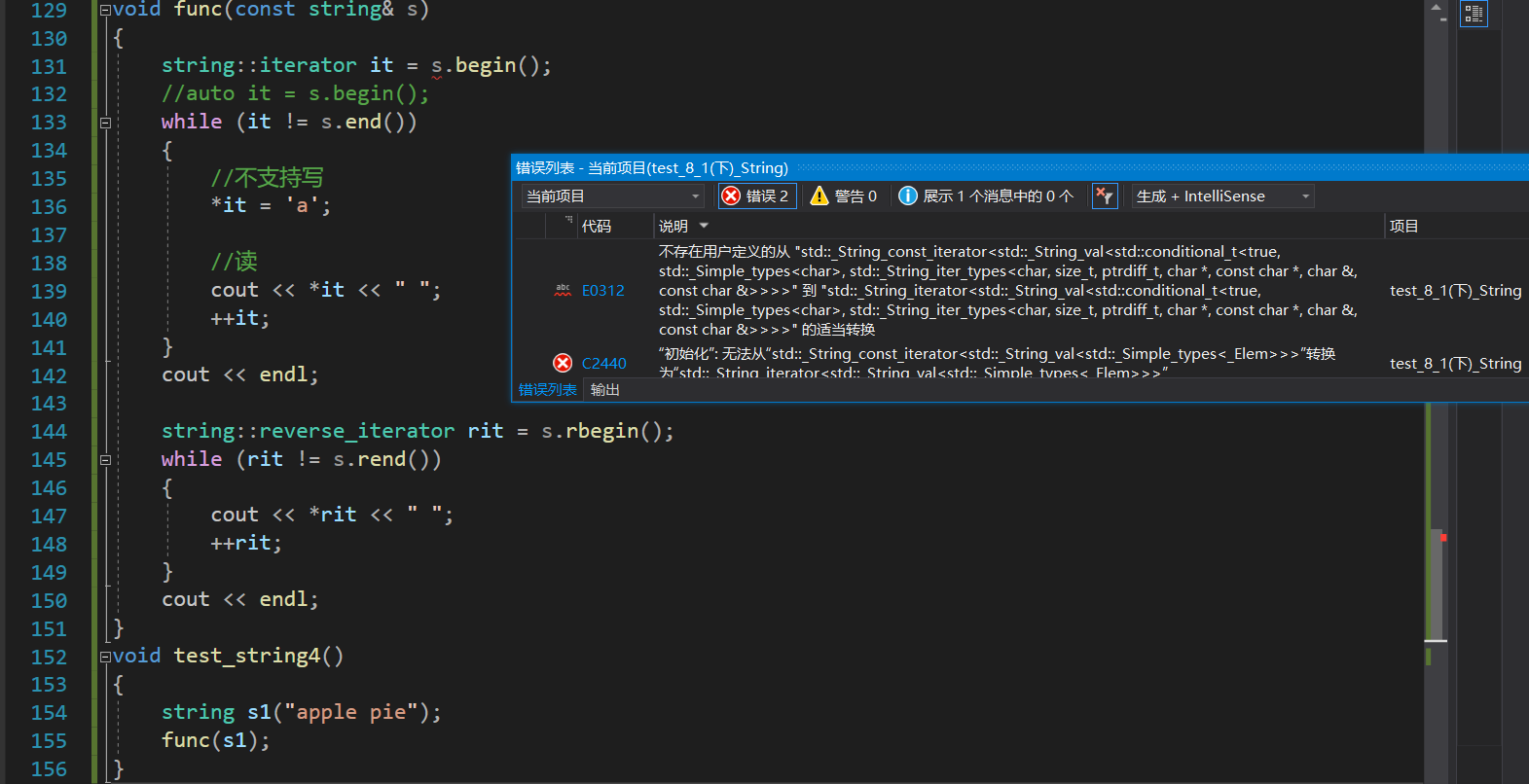
以下均是不能通过的情况:
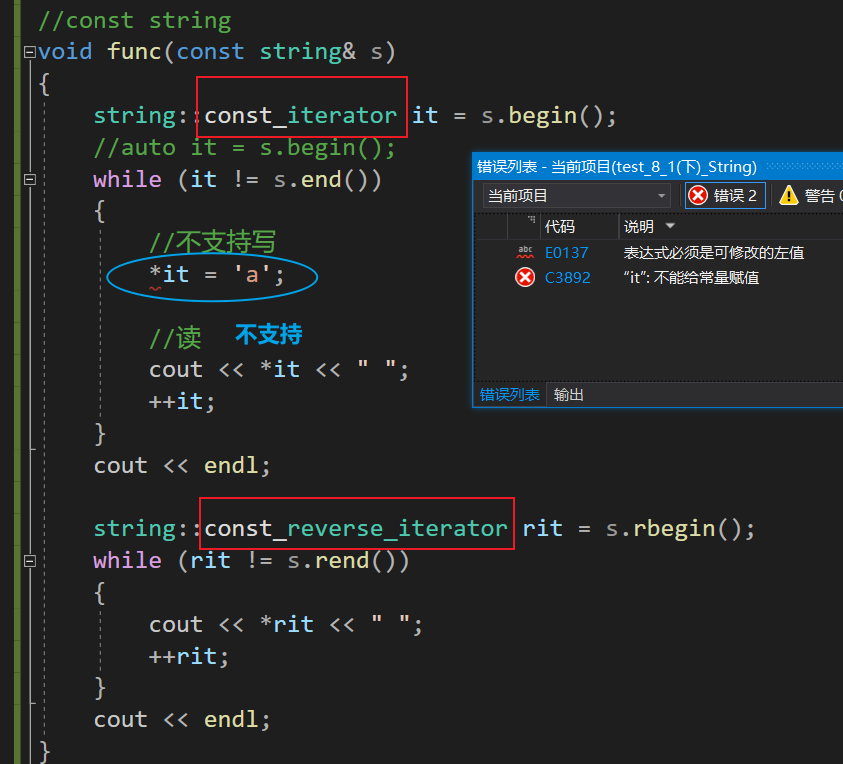
如果传参的时候写成被const修饰的参数,其他代码不改动,那么编译就不会通过了:
因为s1传参到s是const对象,const对象要用const迭代器,只读,不能写
红色框是修改之后的结果,蓝色框说明该迭代器只能读不能写
总计:四种迭代器
4.💥取字符串💥
假设这时候我要从一个字符串里面取需要的字符串,我们需要用到打红色√(重点)
需要注意的:以及横线划着那条成员函数,蓝色打勾

但如果我这个字符串很长,那需要我从头到尾去数这个字符串的长度,然后把大小填到参数位那吗?这样的处理方法未免太繁琐。这时候引入了一个参数npos:

比如说以下这个,直接从主串的第6个字符的后一个字符开始取子串,不填入参数,默认就帮你把后面的子串都取完,以下这两种写法的功能都十分相似:
另外还有需要注意的知识点是:
赋值运算符重载:
举例的代码:
void test_string4()
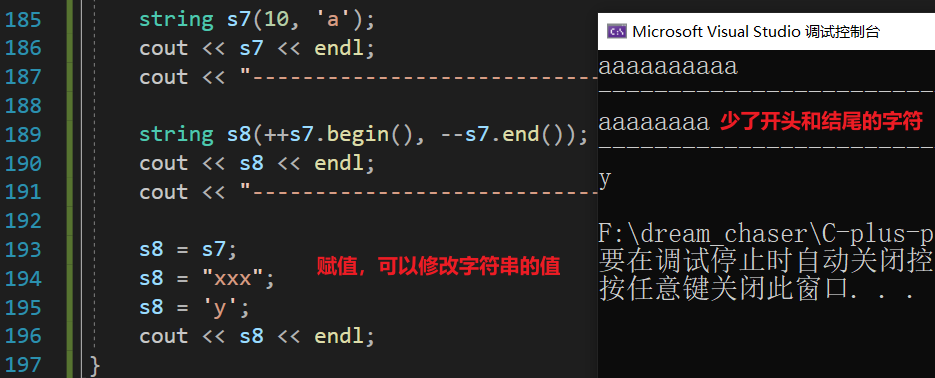
{string s1("apple pie,taste good");string s1("hello world");string s2(s1);cout << s2 << endl;cout << "-------------------------------------" << endl;string s3(s1, 6, 5);cout << s3 << endl;cout << "-------------------------------------" << endl;string s4(s1, 6, 3);cout << s4 << endl;cout << "-------------------------------------" << endl;//string s1("apple pie,taste good");string s5(s1, 6 );cout << s5 << endl;cout << "-------------------------------------" << endl;string s6(s1, 6, s1.size() - 6);// s1.size() - 6:子串的长度,从第七个位置的字符开始cout << s6 << endl;cout << "-------------------------------------" << endl;string s7(10, 'a');cout << s7 << endl;cout << "-------------------------------------" << endl;string s8(++s7.begin(), --s7.end());cout << s8 << endl;cout << "-------------------------------------" << endl;s8 = s7;s8 = "xxx";s8 = 'y';cout << s8 << endl;
}C.string类对象的容量操作

string容量相关方法使用代码演示
注意
1. size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。
2.clear()只是将string中有效字符清空,不改变底层空间大小。
3.resize(size_t n)与 resize(sizet n,char c)都是将字符串中有效字符个数改变到n个,
不同的是当字符个数增多时:
resize(n)用0来填充多出的元素空间,
resize(size tn,char c)用字符c来填充多出的元素空间。
注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
4.reserve(size_tres_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
size、length、capacity、clear 、max_size,:
建议使用size:size比length更具有通用性,length只能计算线性的数据结构。
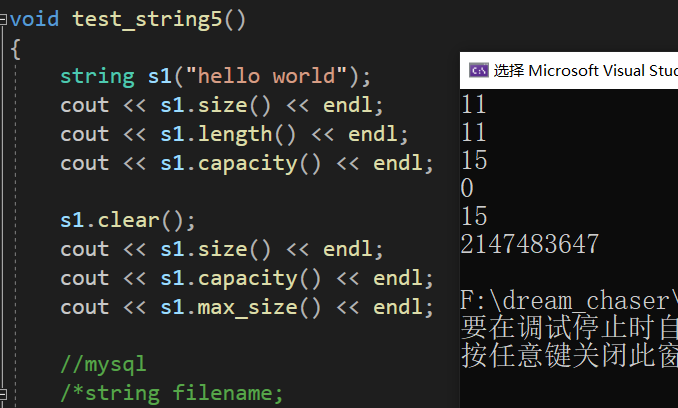
void test_string5()
{string s1("hello world");cout << s1.size() << endl;//返回字符串有效字符长度cout << s1.length() << endl;//返回字符串有效字符长度cout << s1.capacity() << endl;//返回空间总大小s1.clear();//清空有效字符,注意:不释放空间cout << s1.size() << endl;//返回字符串有效字符长度cout << s1.capacity() << endl;//返回字符串有效字符长度cout << s1.max_size() << endl;//返回容器所能容纳的最大元素数量(这个值一般是固定的)
}
❓来写一道题:387. 字符串中的第一个唯一字符
class Solution {
public:// 定义一个成员函数firstUniqChar,它接收一个字符串s作为参数,并返回一个整数// 这个整数代表字符串s中第一个唯一(只出现一次)字符的索引,如果不存在这样的字符,则返回-1int firstUniqChar(string s) {// 创建一个大小为26的整型数组countA,用于存储'a'到'z'每个字母出现的次数int countA[26] = {0};// 首先遍历字符串s中的每个字符for(auto ch: s){// 把当前字符ch转换为其在小写字母表中的相对位置(例如,'a'的位置是0,'b'的位置是1,依此类推)// 通过 ch - 'a' 计算得出int index = ch - 'a';// 把该位置的计数值加1,表示这个字母出现了一次countA[index]++;}// 再次遍历字符串s中的每个字符for(int i = 0; i < s.size(); ++i){// 获取当前字符s[i]在小写字母表中的相对位置int index = s[i] - 'a';// 检查此字符在countA数组中的计数值是否为1// 如果是1,说明这个字符在字符串s中只出现了1次,是唯一的if(countA[index] == 1){// 返回当前字符s[i]在字符串s中的索引return i;}}// 如果遍历完整个字符串都没有找到只出现一次的字符,则返回-1表示不存在这样的字符return -1;}
};
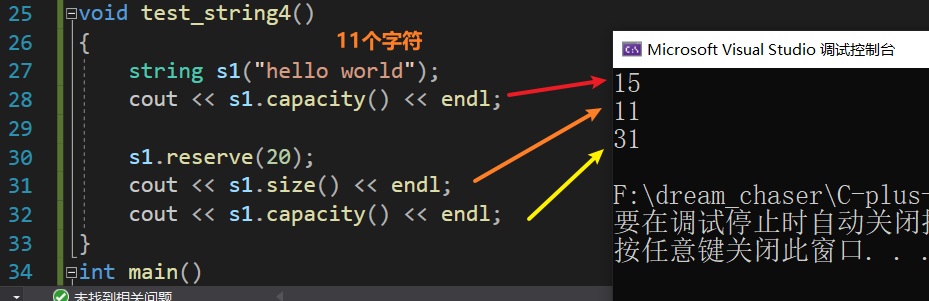
reserve

1.如果 n 大于当前字符串容量(capacity),则该函数会导致容器将其容量增加到 n 个字符(或更大)。 --> 也就是扩到n或者>n
2.在所有其他情况下,它被视为一个非约束性的缩减字符串容量请求:容器实现可以自由优化,保持字符串的容量大于n。
3.此函数对字符串长度没有影响,也无法更改其内容。
(当n小于对象当前的capacity时,什么也不做)
n大于当前字符串容量的测试:
n小于当前字符串的测试:

windows和Linux的增容规则的测试:
1.windows下的增容规则:
reserve开空间的对比,未使用reserve:
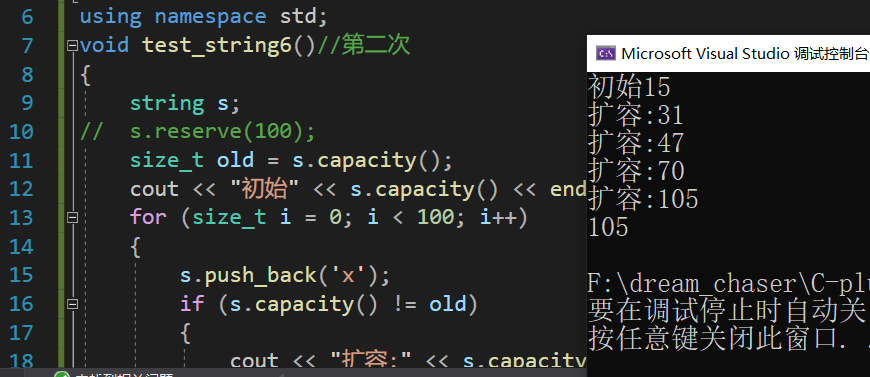
可以看到windows下的增容规则大约是1.5倍的增容
reserve开空间的对比,使用reserve:

💥reserve的意义:
reserve价值,确定大概知道要多少空间,提前开好,减少扩容,提高效率
2.Linux下的增容规则:
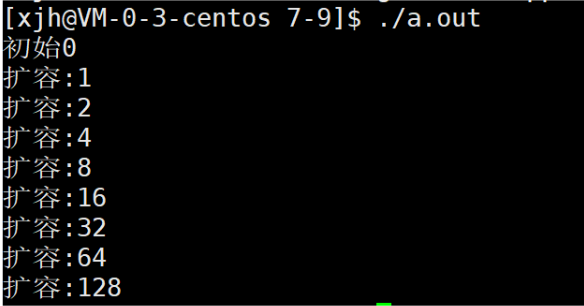
可以看到Linux下的增容规则是2倍增容
测试代码:
#include<iostream>
#include<string>
using namespace std;
void test_string6()//第二次
{string s;//s.reserve(100);size_t old = s.capacity();for (size_t i = 0; i < 100; i++){s.push_back('x');if (s.capacity() != old){cout << "扩容:" << s.capacity() << endl;old = s.capacity();}}//s.reserve(10);cout << s.capacity() << endl;
}resize

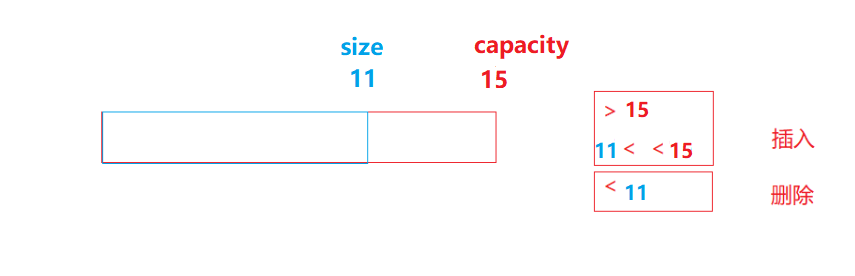
1.如果n小于当前字符串的长度,则将当前值缩短为前n个字符,删除第n个字符之后的字符。
2.如果n大于当前字符串长度,则扩展当前内容,在字符串末尾插入任意数量的字符,使长度达到n。如果指定了c,则新元素初始化为c的副本,否则为值初始化的字符(空字符) ---> '\0'。
图解:
n大于当前字符串长度测试:
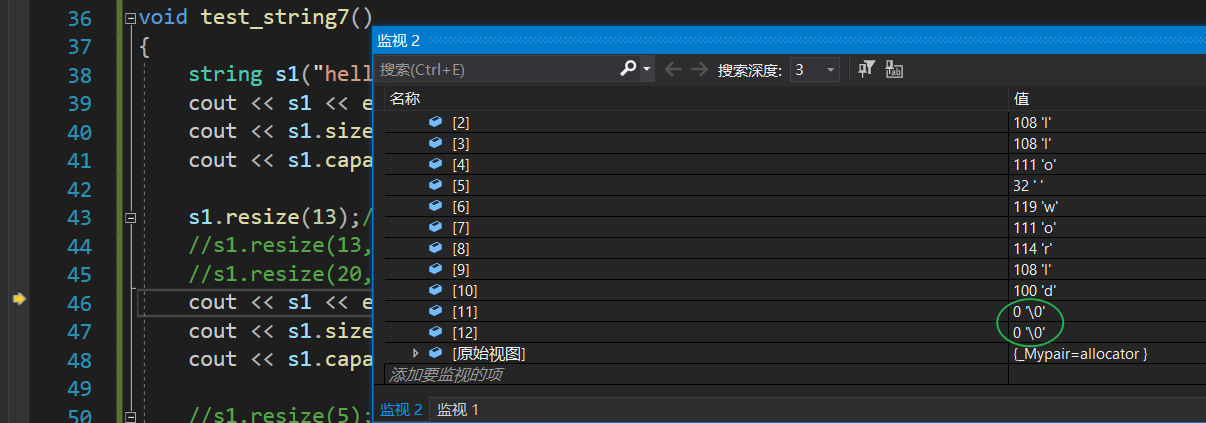
size < resize < capacity 不使用字符参数:
size < resize < capacity 使用字符参数:
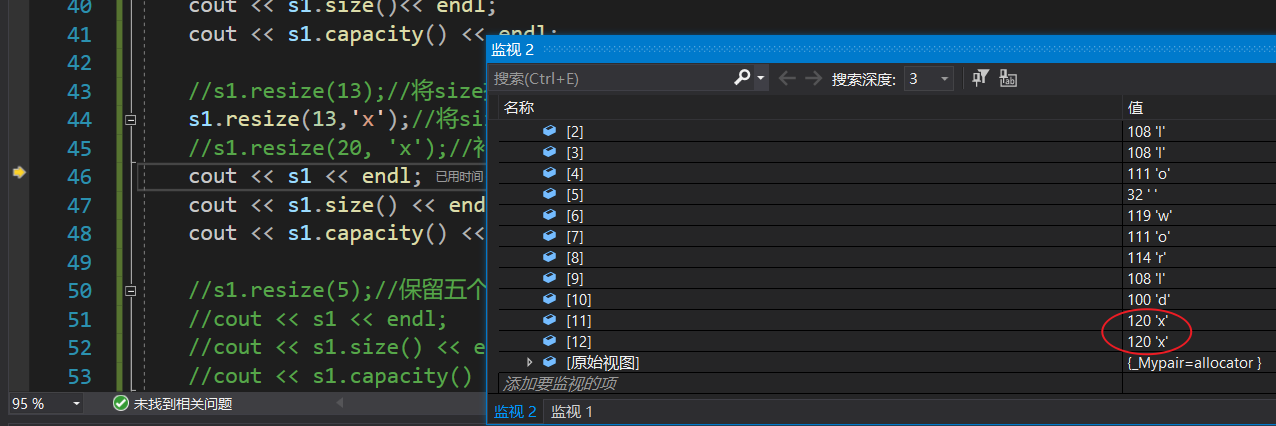
resize > capacity 使用字符参数:
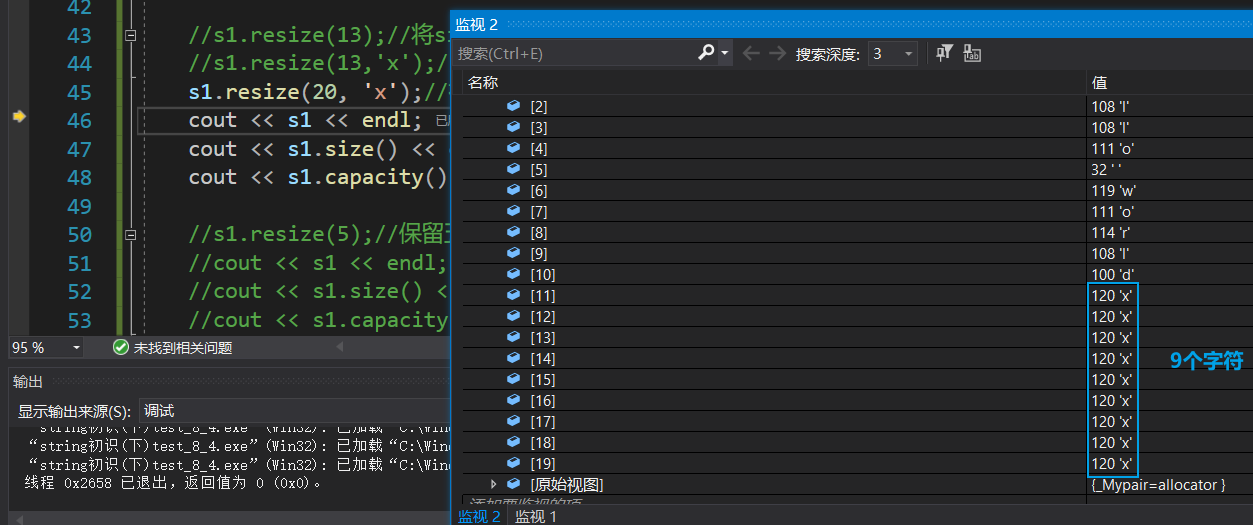
n小于当前字符串长度测试:
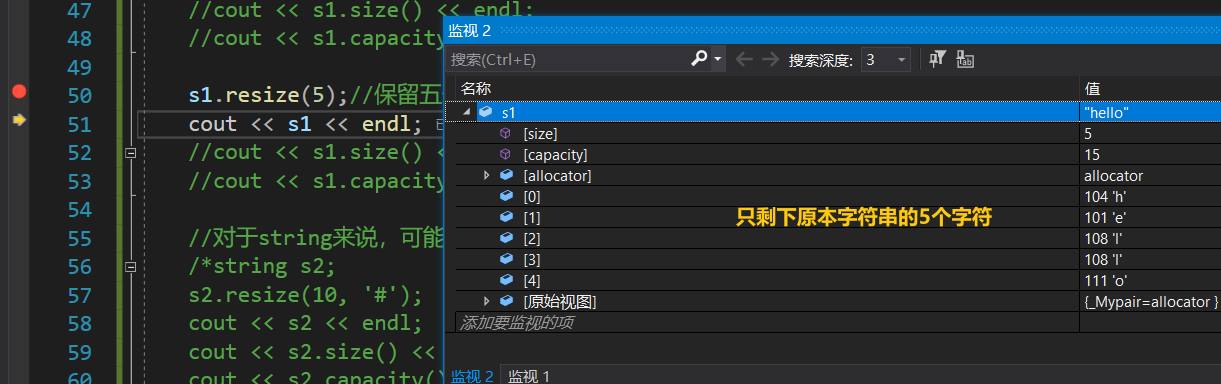
对于空字符串,若给出n的值,则会初始化到第n个字符(下标要 -1 )
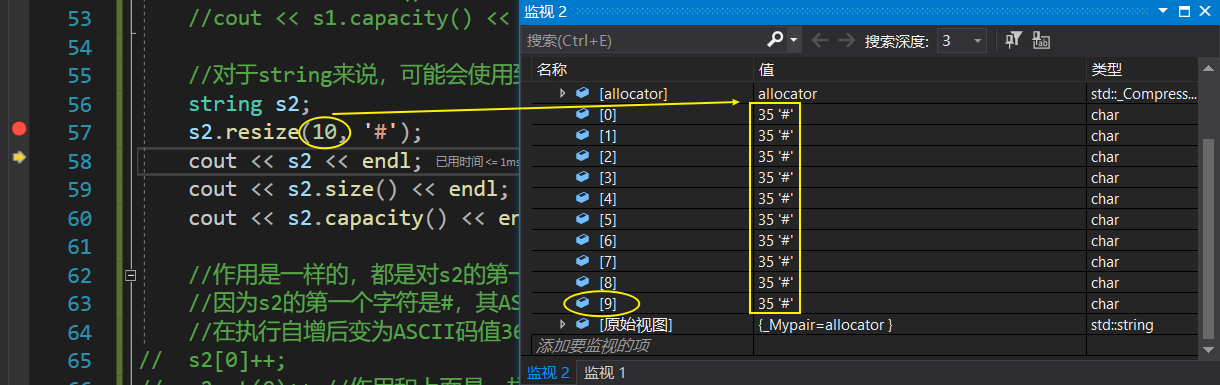
测试代码:
void test_string7()
{string s1("hello world");cout << s1 << endl;cout << s1.size()<< endl;cout << s1.capacity() << endl;//s1.resize(13);//将size扩到13,原本size是11,剩下的两个字符补'\0',加上末尾的'\0'(调试看不见),3个'\0's1.resize(13,'x');//将size扩到13,不够的话补两个'x's1.resize(20, 'x');//补9个x,因为原本size是11+9个'x'是20字符cout << s1 << endl;cout << s1.size() << endl;cout << s1.capacity() << endl;s1.resize(5);//保留五个字符cout << s1 << endl;cout << s1.size() << endl;cout << s1.capacity() << endl;//对于string来说,可能会使用到resize的场景string s2;s2.resize(10, '#');cout << s2 << endl;cout << s2.size() << endl;cout << s2.capacity() << endl;
}at 下标自增
两种:①数组 ②at:


代码:
void test_string7()
{string s2;s2.resize(10, '#');cout << s2 << endl;cout << s2.size() << endl;cout << s2.capacity() << endl;//作用是一样的,都是对s2的第一个字符(下标为0的位置)执行自增操作。//因为s2的第一个字符是#,其ASCII码值为35,//在执行自增后变为ASCII码值36对应的字符,即$。s2[0]++;s2.at(0)++;//作用和上面是一样的cout << s2 << endl;
}
int main()
{test_string7();
}D.string类对象的修改操作
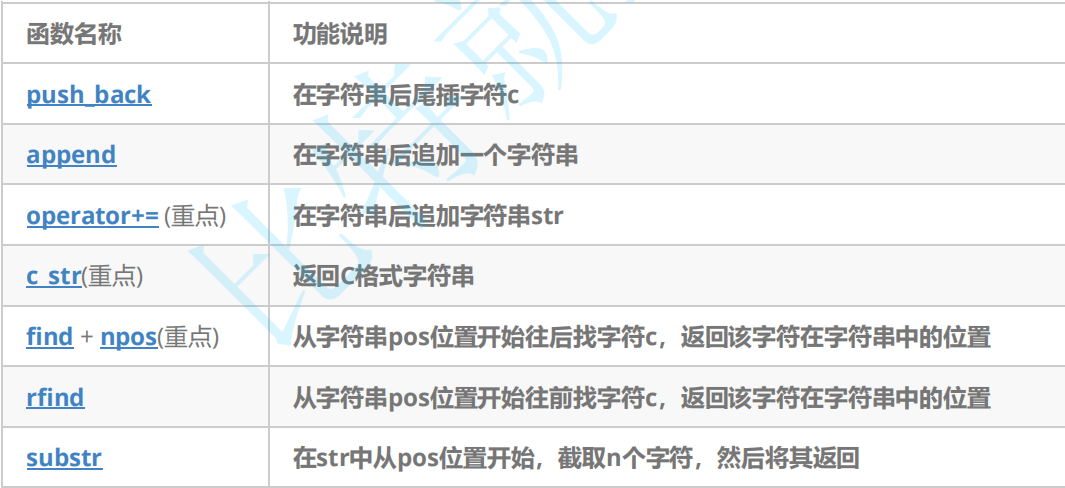
string中插入和查找等使用代码演示
注意:
1. 在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式
差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
2. 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
push_back、append、+=、+:
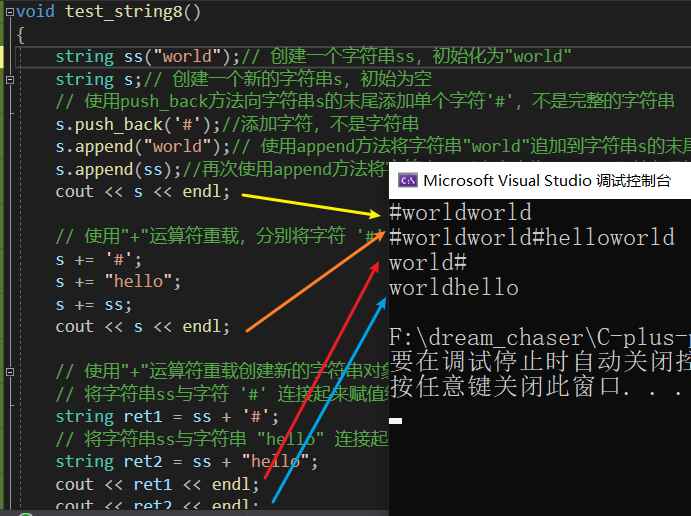
代码:
void test_string8()
{string ss("world");// 创建一个字符串ss,初始化为"world"string s;// 创建一个新的字符串s,初始为空// 使用push_back方法向字符串s的末尾添加单个字符'#',不是完整的字符串s.push_back('#');//添加字符,不是字符串s.append("world");// 使用append方法将字符串"world"追加到字符串s的末尾s.append(ss);//再次使用append方法将字符串ss(内容也为"world")追加到字符串s的末尾cout << s << endl;// 使用"+"运算符重载,分别将字符 '#' 和字符串 "hello" 追加到字符串s的末尾s += '#';s += "hello";s += ss;cout << s << endl;// 使用"+"运算符重载创建新的字符串对象ret1和ret2// 将字符串ss与字符 '#' 连接起来赋值给ret1string ret1 = ss + '#';// 将字符串ss与字符串 "hello" 连接起来赋值给ret2string ret2 = ss + "hello";cout << ret1 << endl;cout << ret2 << endl;
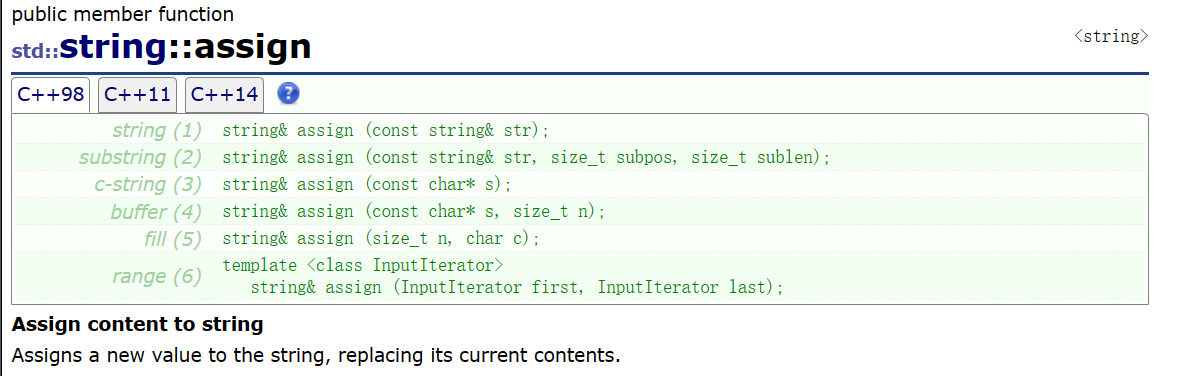
}assgin
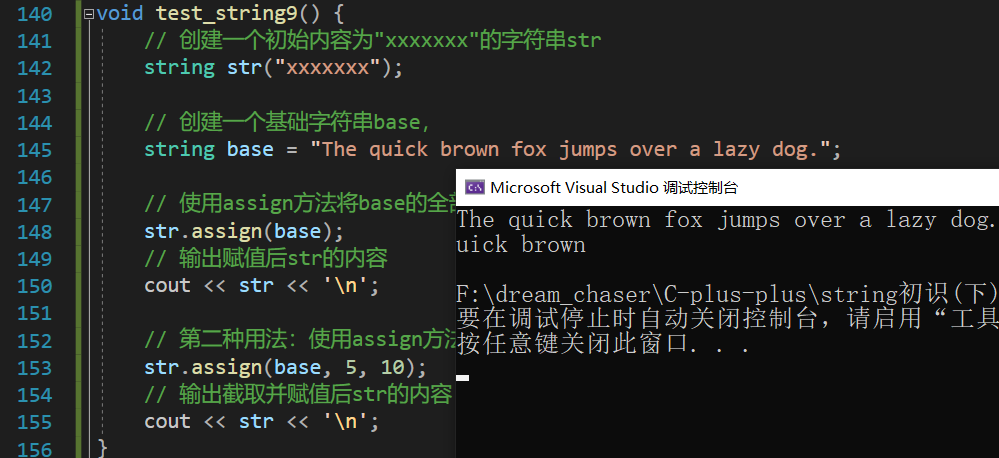
void test_string9() {// 创建一个初始内容为"xxxxxxx"的字符串strstring str("xxxxxxx");// 创建一个基础字符串base,string base = "The quick brown fox jumps over a lazy dog.";// 使用assign方法将base的全部内容赋给str,替换str原来的内容str.assign(base);// 输出赋值后str的内容cout << str << '\n';// 第二种用法:使用assign方法从base的第5个字符开始截取10个字符,并将这10个字符赋给strstr.assign(base, 5, 10);// 输出截取并赋值后str的内容cout << str << '\n';
}insert
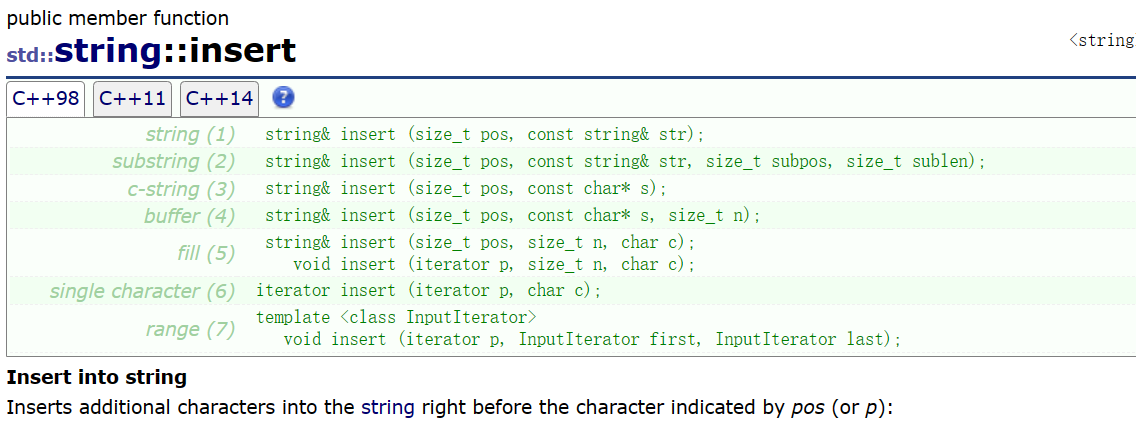

void test_string10()
{
//接口设计复杂繁多,需要时查一下文档即可//下面两种写法都是头插 string str("hello world");str.insert(0,3,'x');//表示在字符串的起始位置插入cout << str << endl;str.insert(str.begin(), '#');cout << str << endl;}erase

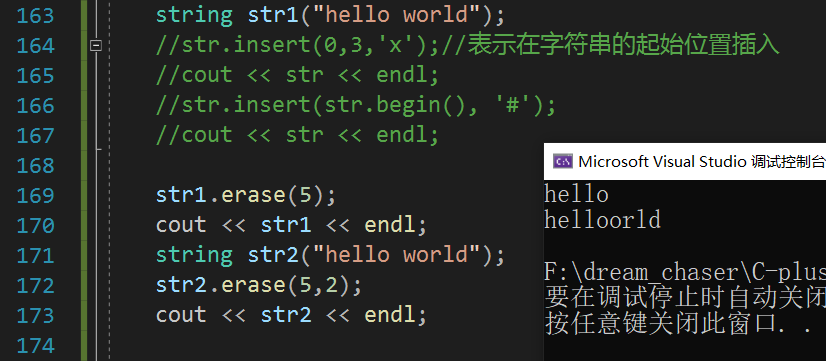
void test_string10()
{string str1("hello world");str1.erase(5);//删至5个字符:hello后面的全删掉cout << str1 << endl;string str2("hello world");str2.erase(5,2);//从第6个位置开始删掉,并删掉下标为6,7的字符cout << str2 << endl;replace
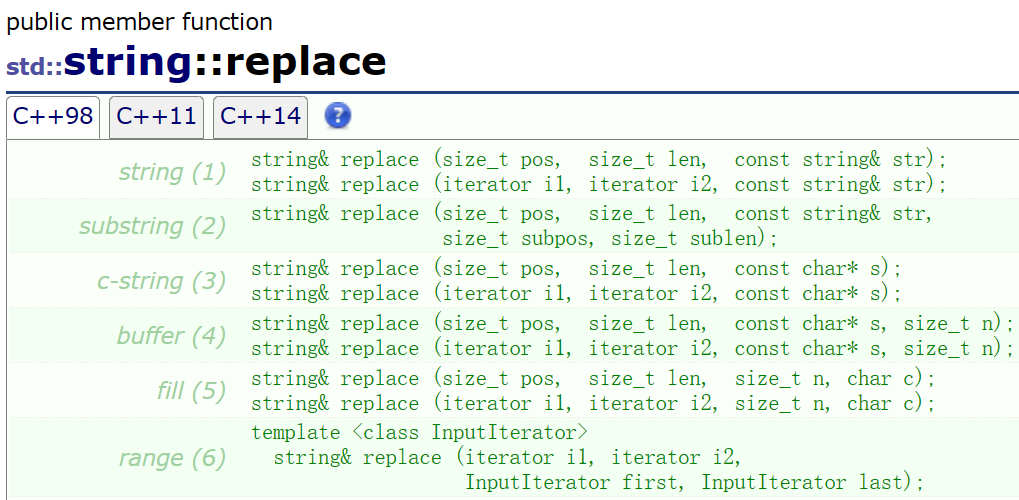
对于replace来说,第一个参数传入pos的位置,第二个参数就是你想要替换的字符个数,第三个参数是你想替换的内容
从以下的示例可以看出:如果第二个参数给多给少都会影响最终打印:多了就会替换掉原来的字符串,少了就会挪动数据

代码:
void test_string10()
{string s1("hello world");s1.replace(5,1,"%%20");cout << s1 << endl;string s2("hello world");s2.replace(5, 3,"%%20");cout << s2 << endl;string s3("hello world");s3.replace(5, 4,"%%20");cout << s3 << endl;
}🚩总结:
insert/erase/replace能不用就尽量不用,因为他们都涉及挪动数据,效率不高
接口设计复杂繁多,需要时查一下文档即可
swap
swap 成员函数通常比直接拷贝数据更高效,因为它可能仅交换内部指针和一些元数据,而无需复制整个字符串内容。

s3遍历s2,s3遇到空格替换成20%,其他位置不变,之后交换s2和s3的地址:
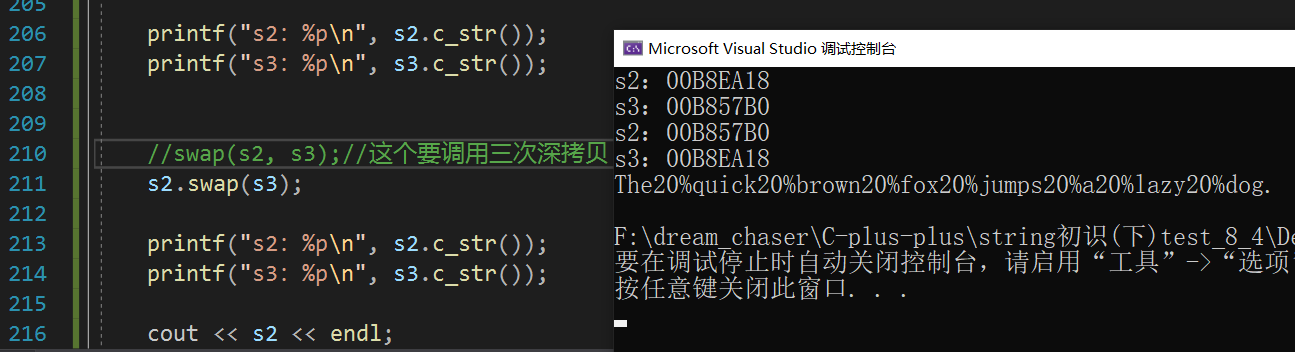
void test_string10()
{//空格替换成20%string s2("The quick brown fox jumps a lazy dog.");string s3;for (auto ch : s2){if (ch != ' '){s3 += ch;}else{s3 += "20%";}}//这两个是深拷贝:s2 = s3;s2.assign(s3);printf("s2:%p\n", s2.c_str());printf("s3:%p\n", s3.c_str());//swap(s2, s3);//这个要调用三次深拷贝s2.swap(s3);//其实本质是调用了swap(s2,s3)printf("s2:%p\n", s2.c_str());printf("s3:%p\n", s3.c_str());cout << s2 << endl;
}以上例子也用到了c_str。
c_str
find、rfind、substr
find


这里我们需要注意find的返回值:第一次匹配的第一个字符的位置。如果没有找到匹配,函数返回string::npos。
rfind


这里我们需要注意rfind的返回值:最后匹配的第一个字符的位置。如果没有找到匹配,函数返回string::npos。
substr

这个函数是取出子串,有两个参数:pos,len,pos指的是你想要从哪里开始,len是取得长度,并且它两都有缺省值
我们想要取出文件名的后缀就需要用到rfind和substr这两个函数:
因为最后面的.才是后缀,所以我们需要找最后一个.字符,所以需要用到rfind这个函数
代码测试:
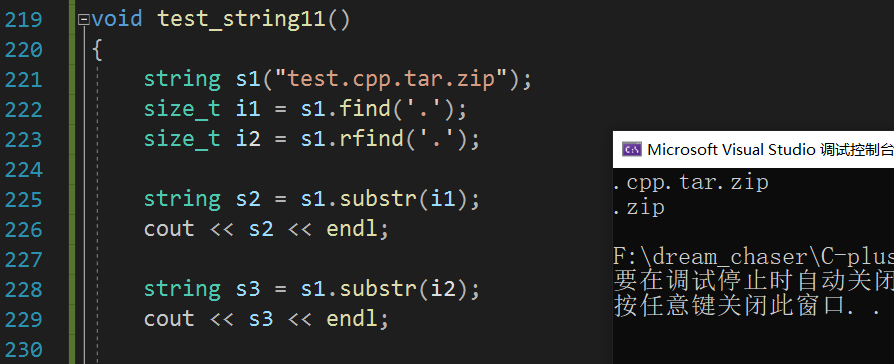
void test_string11()
{string s1("test.cpp.tar.zip");size_t i1 = s1.find('.');size_t i2 = s1.rfind('.');string s2 = s1.substr(i1);cout << s2 << endl;string s3 = s1.substr(i2);cout << s3 << endl;
}
取出url协议、域名、uri:
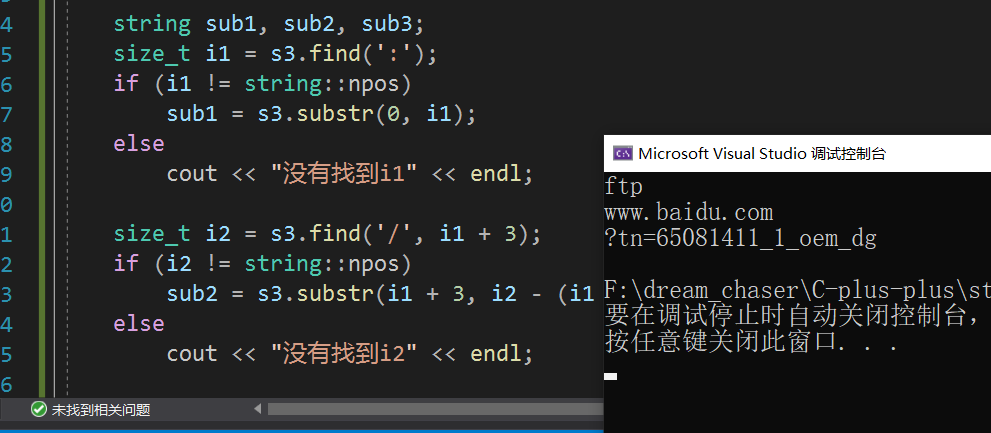
void test_string11()
{//string s3("https://legacy.cplusplus.com/reference/string/string/rfind/");string s3("ftp://www.baidu.com/?tn=65081411_1_oem_dg");// 协议// 域名// 资源名string sub1, sub2, sub3;size_t i1 = s3.find(':');if (i1 != string::npos)sub1 = s3.substr(0, i1);elsecout << "没有找到i1" << endl;size_t i2 = s3.find('/', i1 + 3);if (i2 != string::npos)sub2 = s3.substr(i1 + 3, i2 - (i1 + 3));elsecout << "没有找到i2" << endl;sub3 = s3.substr(i2 + 1);cout << sub1 << endl;cout << sub2 << endl;cout << sub3 << endl;
}find_first_of 和 find_first_not_of
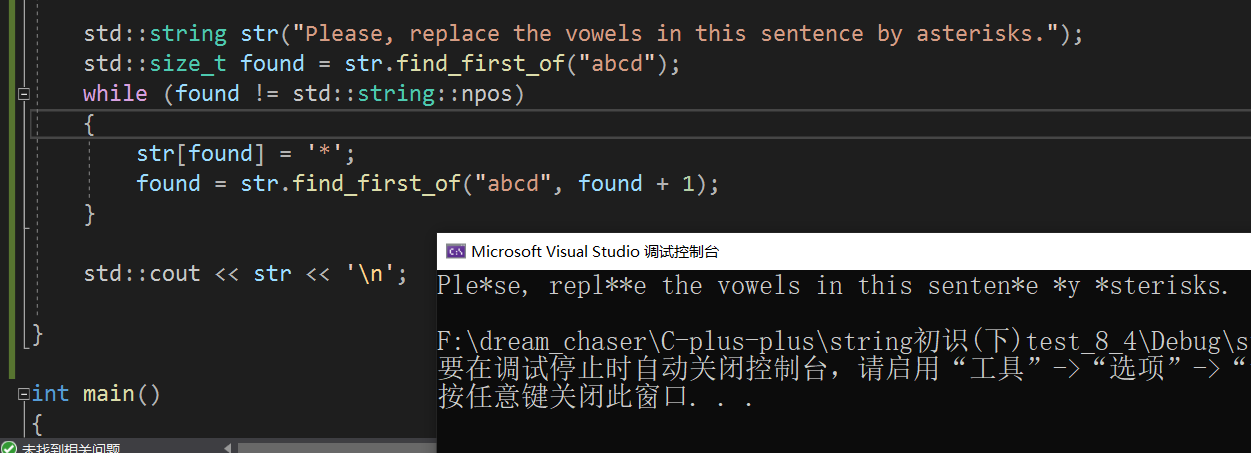
void test_string12()
{/*std::string str("Please, replace the vowels in this sentence by asterisks.");std::size_t found = str.find_first_not_of("abc");while (found != std::string::npos){str[found] = '*';found = str.find_first_not_of("abcdefg", found + 1);}std::cout << str << '\n';*/std::string str("Please, replace the vowels in this sentence by asterisks.");std::size_t found = str.find_first_of("abcd");while (found != std::string::npos){str[found] = '*';found = str.find_first_of("abcd", found + 1);}std::cout << str << '\n';}
string初识篇告一段落,接下来是string的模拟实现。
🔧本文修改次数:0
🧭更新时间:2024年3月19日
这篇关于【C++初阶】第七站:string类的初识(万字详解、细节拉满)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






