本文主要是介绍Redis字符串操作及SDS字符串实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本专栏新增整合黄健宏老师的《Redis设计与实现》,以便更加有效地了解Redis 的内部构造及运作机制,帮助学者更高效得使用Redis。博文中会以虚线分区,上半区为Redis的简单使用,下半区为Redis内部实现,如果是简单地使用Redis快速完成工作或者只是想简单的了解Redis,只看上半区即可,有兴趣或等空闲的时候学习下下半区,结合源码会对Redis的理解更上一层楼。
redis-cli -n 登录不同的库
清楚当前库中的数据
FLUSHDB清楚所有库中的数据
FLUSHALL字符串
可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字(整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能超过512MB
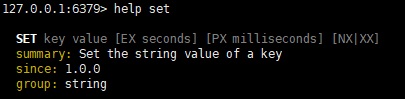
SET key value
- 如果一个键已经存在,再次set会覆盖它的值
- “XX”表示键不存在不能设置
- “NX”表示键不存在才能设置 [ SETNX key value 的同义]



SET key value [EX seconds] [PX millisenconds] 设置键的有效时间(还可以用EXPIRE key seconds)
MSET key value [key value......]同时设置多个值

MSETNX key value [key value......] 至少有一个存在才能设置成功 否则不执行任何设置[具有原子性]
GETSET key new-value 将字符串的值设置为 new-value ,并返回字符串设置新值之前存储的值

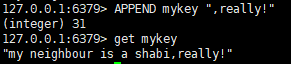
APPEND key value 将value插入到字符串的末尾
STRLEN key 获取key对应value的长度

KEYS * 查询已有的键
SETRANGE key [索引位置] value: 从[索引位置]开始设置
从左向右从0开始,从右向左从-1开始。
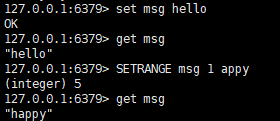
GETRANGE key [起始位
置][结束位置](GETRANGE key 0 -1:表示获取所有)

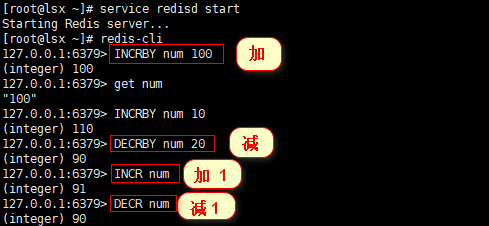
INCRBY DECRBY 数值的加减
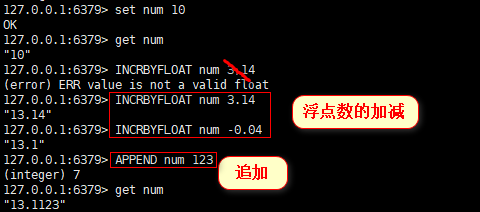
INCRBYFLOAT key value 浮点数的加减
过期时间设置
设置过多少秒或毫秒后过期
1、EXPIRE key seconds:秒
2、PEXPIRE key milliseconds:毫秒设置在指定Unix时间戳过去
1、EXPIREAT key timestamp
2、PEXPIREAT key milliseconds-timestamp删除过期
PERSIST key查看剩余生存时间
TTL key
1、key存在,但没有设置TTL,返回-1
2、可以存在,但还在生存期内,返回剩余生存时间
3、key曾经存在,但已经消亡,返回-2(2.8版本之前返回-1)键是否存在
EXISTS key键重命名
RENAME key newkeyName
ERNAMENX key newkeyName键删除
DEL key [key.......]首先需明确理解Redis是使用对象来表示数据库中的键和值,当我们在Redis数据库中新建一个键值对时,我们至少会创建两个对象,一个对象用作键值对的键(键对象),另一个对象用作键值对的值(值对象)
typedef struct redisObject{//类型unsigned type;//编码unsigned encoding;//指定底层实现数据结构的指针void *ptr;//...
}robj;字符串对象模型图:
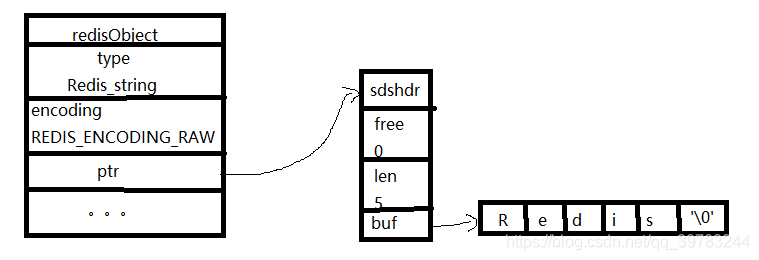
Redis只会使用C字符串作为字面量,在大多数情况下,redis使用SDS(Simple Dynamic String,简单动态字符串)作为字符串表示,Redis中简单动态字符串SDS数据结构与API相关文件是:sds.h, sds.c。SDS主要API如下,如需查看源代码,可自行百度“redis sds源码”,查看相关文档。本文截取自hoohack,感谢博主分享,源码在博文结尾。
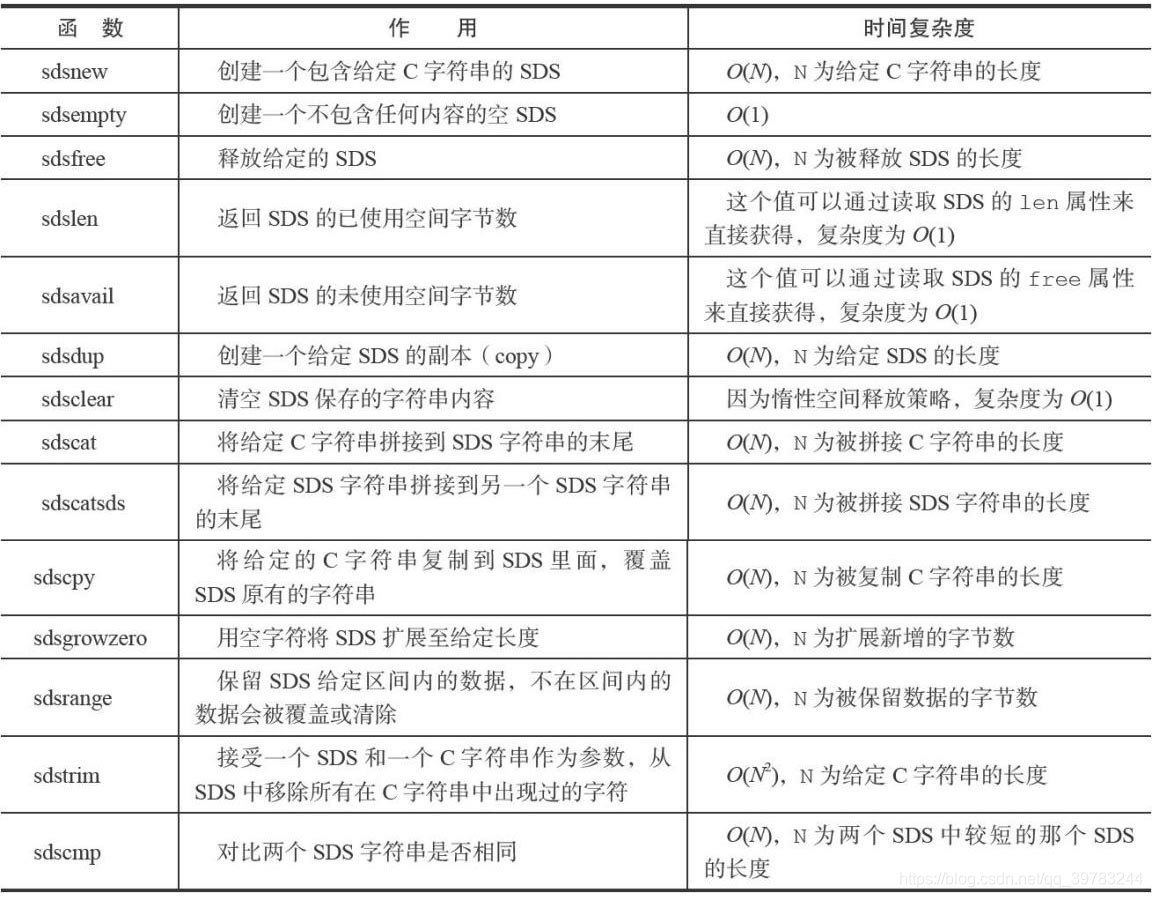
比起C字符串,SDS具有以下优点:
- 常数复杂度获取字符串长度(C字符串获取长度必须遍历整个字符串,对遇到的每个字符进行计数,直到遇到代表字符串结尾的空字符为止;而SDS只需访问SDS的len属性值)
- 杜绝缓冲区溢出(进行拼接操作时,SDS先检查给定的空间是否足够,不够的话,先扩展空间再执行拼接操作[扩展的同时会指定相同长度的free,达到“优点3”];而C字符串在空间不足时会导致缓冲区溢出,影响内存中与其紧邻的C字符串)
- 减少修改字符串长度时所需的内存分配次数(SDS通过非使用空间free实现可空间预分配和惰性空间释放两种策略)
- 二进制安全(SDS API会以二进制方式处理SDS存放在buf数组里的数据,不会对数据做任何限制、过滤或者假设,数据写入的时候什么样,他被读取的时候就是什么样;C字符串则不能保存图片、音频、视频、压缩文件这样的二级制数据,字符串里不能包含空字符,否则会被认为是字符串结尾)
- 兼容部分C字符串函数
SDS定义:1、‘len’用于记录buf数组总已使用的字节的数量,等于SDS中已保存的字符串的长度2、‘free’记录buf数组中未使用的字节的数量3、‘buf[]’字节数组,用于保存字符串。
SDS示例:

sds结构体的定义
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7// sds结构体,使用不同的结构体来保存不同长度大小的字符串
typedef char *sds;struct __attribute__ ((__packed__)) sdshdr5 {unsigned char flags; /* flags共8位,低三位保存类型标志,高5位保存字符串长度,小于32(2^5-1) */char buf[]; // 保存具体的字符串
};
struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* 字符串长度,buf已用的长度 */uint8_t alloc; /* 为buf分配的总长度,alloc-len就是sds结构体剩余的空间 */unsigned char flags; /* 低三位保存类型标志 */char buf[];
};struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len; /* used */uint16_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len; /* used */uint32_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};struct __attribute__ ((__packed__)) sdshdr64 {uint64_t len; /* used */uint64_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};sds结构体从4.0开始就使用了5种header定义,节省内存的使用,但是不会用到sdshdr5,我认为是因为sdshdr5能保存的大小较少,2^5=32,因此就不使用它。
其他的结构体保存了len、alloc、flags以及buf四个属性。各自的含义见代码的注释。
sds结构体的获取
上面可以看到有5种结构体的定义,在使用的时候是通过一个宏来获取的:
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))"##"被称为连接符,它是一种预处理运算符, 用来把两个语言符号(Token)组合成单个语言符号。比如SDS_HDR(8, s),根据宏定义展开是:
((struct sdshdr8 *)((s)-(sizeof(struct sdshdr8))))而具体使用哪一个结构体,sds底层是通过flags属性与SDS_TYPE_MASK做与运算得出具体的类型(具体的实现可见下面的sdslen函数),然后再根据类型去获取具体的结构体。
sds特性的实现
在Redis设计与实现一书中讲到,相比C字符串而言,sds的特性如下:
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 减少内存重新分配次数
- 二进制安全
那么,它是怎么做到的呢?看代码。
常数复杂度获取字符串长度
因为sds将长度属性保存在结构体中,所以只需要读取这个属性就能获取到sds的长度,具体调用的函数时sdslen,实现如下:
static inline size_t sdslen(const sds s) {unsigned char flags = s[-1];switch(flags&SDS_TYPE_MASK) {case SDS_TYPE_5:return SDS_TYPE_5_LEN(flags);case SDS_TYPE_8:return SDS_HDR(8,s)->len;case SDS_TYPE_16:return SDS_HDR(16,s)->len;case SDS_TYPE_32:return SDS_HDR(32,s)->len;case SDS_TYPE_64:return SDS_HDR(64,s)->len;}return 0;
}可以看到,函数是根据类型调用SDS_HDR宏来获取具体的sds结构,然后直接返回结构体的len属性。
杜绝缓冲区溢出
对于C字符串的操作函数来说,如果在修改字符串的时候忘了为字符串分配足够的空间,就有可能出现缓冲区溢出的情况。而sds中的API就不会出现这种情况,因为它在修改sds之前,都会判断它是否有足够的空间完成接下来的操作。
拿书中举例的sdscat函数来看,如果strcat想在原来的"Redis"字符串的基础上进行字符串拼接的操作,但是没有检查空间是否满足,就有可能会修改了"Redis"字符串之后使用到的内存,可能是其他结构使用了,也有可能是一段没有被使用的空间,因此有可能会出现缓冲区溢出。但是sdscat就不会,如下面代码所示:
sds sdscatlen(sds s, const void *t, size_t len) {size_t curlen = sdslen(s);s = sdsMakeRoomFor(s,len);if (s == NULL) return NULL;memcpy(s+curlen, t, len);sdssetlen(s, curlen+len);s[curlen+len] = '\0';return s;
}sds sdscat(sds s, const char *t) {return sdscatlen(s, t, strlen(t));
}从代码中可以看到,在执行memcpy将字符串写入sds之前会调用sdsMakeRoomFor函数去检查sds字符串s是否有足够的空间,如果没有足够空间,就为其分配足够的空间,从而杜绝了缓冲区溢出。sdsMakeRoomFor函数的实现如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {void *sh, *newsh;size_t avail = sdsavail(s);size_t len, newlen;char type, oldtype = s[-1] & SDS_TYPE_MASK;int hdrlen;/* 只有有足够空间就马上返回,否则就继续执行分配空间的操作 */if (avail >= addlen) return s;len = sdslen(s);sh = (char*)s-sdsHdrSize(oldtype);newlen = (len+addlen);// SDS_MAX_PREALLOC == 1MB,如果修改后的长度小于1M,则分配的空间是原来的2倍,否则增加1MB的空间if (newlen < SDS_MAX_PREALLOC)newlen *= 2;elsenewlen += SDS_MAX_PREALLOC;type = sdsReqType(newlen);if (type == SDS_TYPE_5) type = SDS_TYPE_8;hdrlen = sdsHdrSize(type);if (oldtype==type) {newsh = s_realloc(sh, hdrlen+newlen+1);if (newsh == NULL) return NULL;s = (char*)newsh+hdrlen;} else {/* 新增空间后超过当前类型的长度,使用malloc,并把原字符串拷贝过去 */newsh = s_malloc(hdrlen+newlen+1);if (newsh == NULL) return NULL;memcpy((char*)newsh+hdrlen, s, len+1);s_free(sh);s = (char*)newsh+hdrlen;s[-1] = type; // 给类型标志位赋值sdssetlen(s, len);}sdssetalloc(s, newlen);return s;
}减少内存分配操作
sds字符串的很多操作都涉及到修改字符串内容,比如sdscat拼接字符串、sdscpy拷贝字符串等等。这时候就需要内存的分配与释放,如果每次操作都分配刚刚好的大小,那么对程序的性能必定有影响,因为内存分配涉及到系统调用以及一些复杂的算法。
sds使用了空间预分配以及惰性空间释放的策略来减少内存分配操作。
空间预分配
前面提到,每次涉及到字符串的修改时,都会调用sdsMakeRoomFor检查sds字符串,如果大小不够再进行大小的重新分配。sdsMakeRoomFor函数有下面这几行判断:
// SDS_MAX_PREALLOC == 1MB,如果修改后的长度小于1M,则分配的空间是原来的2倍,否则增加1MB的空间
if (newlen < SDS_MAX_PREALLOC)newlen *= 2;
elsenewlen += SDS_MAX_PREALLOC;函数判断字符串修改后的大小,如果修改后的长度小于1M,则分配给sds的空间是原来的2倍,否则增加1MB的空间。
惰性空间释放
如果操作后减少了字符串的大小,比如下面的sdstrim函数,只是在最后修改len属性,不会马上释放多余的空间,而是继续保留多余的空间,这样在下次需要增加sds字符串的大小时,就不需要再为其分配空间了。当然,如果之后检查到sds的大小实在太大,也会调用sdsRemoveFreeSpace函数释放多余的空间。
sds sdstrim(sds s, const char *cset) {char *start, *end, *sp, *ep;size_t len;sp = start = s;ep = end = s+sdslen(s)-1;/* 从头部和尾部逐个字符遍历往中间靠拢,如果字符在cest中,则继续前进 */while(sp <= end && strchr(cset, *sp)) sp++;while(ep > sp && strchr(cset, *ep)) ep--;len = (sp > ep) ? 0 : ((ep-sp)+1); // 全部被去除了,长度就是0if (s != sp) memmove(s, sp, len); // 拷贝内容s[len] = '\0';sdssetlen(s,len);return s;
}二进制安全
二进制安全指的是只关心二进制化的字符串,不关心具体格式。只会严格的按照二进制的数据存取,不会妄图以某种特殊格式解析数据。比如遇到'\0'字符不会停止解析。
对于C字符串来说,strlen是判断遇到'\0'之前的字符数量。如果需要保存二进制的数据,就不能通过传统的C字符串来保存,因为获取不到它真实的长度。而sds字符串是通过len属性保存字符串的大小,所以它是二进制安全的。
其他小函数实现
在阅读源码的过程中,也发现了两个个人比较感兴趣趣的函数:
- sdsll2str(将long long类型的整型数字转成字符串)
- sdstrim (去除头部和尾部的指定字符)
我这两个函数拉出来做了测试,在项目的redis-4.0/tests目录下。sdstrim函数的实现源码上面有列出,看看sdsll2str的实现:
int sdsll2str(char *s, long long value) {char *p, aux;unsigned long long v;size_t l;/* 通过取余数得到原字符串的逆转形式 */v = (value < 0) ? -value : value;p = s;do {*p++ = '0'+(v%10);v /= 10;} while(v);if (value < 0) *p++ = '-';/* Compute length and add null term. */l = p-s;*p = '\0';/* 反转字符串 */p--;while(s < p) {aux = *s;*s = *p;*p = aux;s++;p--;}return l;
}函数是通过不断取余数,得到原字符串的逆转形式,接着,通过从尾部开始将字符逐个放到字符串s中,看起来像是一个反转操作,从而实现了将整型转为字符串的操作。
直达黄老师Redis源码翻译Git地址
这篇关于Redis字符串操作及SDS字符串实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







