本文主要是介绍Java_多线程初阶_多线概念_Thread_线程安全_wait notify_线程案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、创建线程
- 1.继承Thread类,重写run
- 2.实现Runnable,重写run
- 3.继承Thread,重写run,使用匿名内部类
- 4.实现Runnable,重写run,使用匿名内部类
- 5.使用lambda表达式 (推荐)
- 6.观察多线程运行情况
- 二、Thread的一些重要属性和方法
- 1.构造方法 和 name作用
- 2.Thread的几个常见属性
- 1、ID
- 2、名称
- 3、状态
- 4、优先级
- 5、是否后台线程
- 6、是否存活
- 7、是否被中断
- 3. 启动线程start
- 4.终止线程
- 1、方法一
- 2.方法二
- 5.等待线程
- 6.获取线程引用
- 7.休眠线程
- 三、线程的状态
- 0.观察线程的所有状态
- 1.NEW
- 2.TERMINATED
- 3.RUNNABLE
- 4.TIMED_WAITING
- 四、线程安全(重点)
- 1.线程不安全的例子
- 2.原因
- 3.解决
- 4.synchronized
- 1、直接修饰普通方法
- 2、修饰静态方法
- 3、修饰代码块
- 4、synchronized重要性质:可重入
- 5、死锁
- 6、如何解决/避免死锁呢?
- 5.volatile
- 1、内存可见性
- 6.wait和notify
- 五、多线程案例
- 1.单例模式
- 1、饿汉模式
- 2、懒汉模式-单线程版
- 3、懒汉模式-多线程版
- 2.阻塞队列
- 1、阻塞队列是什么
- 2、生产者消费者模型
- 3、标准库中的阻塞队列
- 4、模拟实现阻塞队列
- 3.定时器(日常开发常见组件)
- 1、标准库中的定时器
- 2、实现简单的定时器
- 4.线程池
- 1、标准库中的线程池
- 2、Executors创建线程池发几种方式
- 3、模拟简单的线程池
一、创建线程
1.继承Thread类,重写run
继承 Thread 来创建一个线程类
class MyThread extends Thread{@Overridepublic void run() {//每个线程是一个独立的执行流//每个线程都可以执行一系列的逻辑(代码)//一个线程跑起来,从哪个代码开始执行???就是从他的入口方法//这个方法就是线程入口的方法System.out.println("这里是线程运行的代码");}
}
创建MyThread类的实例,并启动线程
public class Demo1 {public static void main(String[] args) {Thread t = new MyThread();//start 和 run 都是 Thread 的成员//run 只是描述了线程的入口(线程要做什么任务)//start 则是真正调用了系统API,在系统中创建出线程,让线程再调用runt.start();}
}
注意:如果把t.start改成t.run,此时,代码中不会创建出新的线程。只有一个主线程,这个主线程里只能依次执行循环,执行完一个循环再执行另一个。
2.实现Runnable,重写run
package thread;import static java.lang.Thread.sleep;class MyRunnable implements Runnable{@Overridepublic void run() {while(true){System.out.println("hello thread!");try {sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
public class demo2 {public static void main(String[] args) throws InterruptedException {Runnable runnable = new MyRunnable();Thread t = new Thread(runnable);t.start();while(true){System.out.println("hello main");sleep(1000);}}
}Runnable表示是一个“可以运行的任务”,这个任务是交给线程负责执行,还是交给其他的实体来执行…Runnable本身并不关心。
使用Runnable的写法和直接继承Thread之间的区别,主要就是三个字,解耦合。
创建一个线程,需要进行两个关键操作:
- 明确线程要执行的任务
- 调用系统API创建线程
3.继承Thread,重写run,使用匿名内部类
public static void main(String[] args) {Thread t = new Thread(){}};}
先创建出新的类,这个类的名字是啥不知道。只知道这个类,是Thread的子类,同时又把这个类的实例给创建出来了。(不知道这个类名,不影响,因为这个类本身就是只使用一次)毕竟这里的子类,可以重新父类的方法。
package thread;import static java.lang.Thread.sleep;public class Demo3 {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(){@Overridepublic void run() {while (true){System.out.println("hello thread");try {sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}};t.start();while(true){System.out.println("hello main");sleep(1000);}}}4.实现Runnable,重写run,使用匿名内部类
package thread;public class Demo4 {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(new Runnable() {@Overridepublic void run() {while (true){System.out.println("hello Thread");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}});t.start();while(true){System.out.println("hello main");Thread.sleep(1000);}}
}
5.使用lambda表达式 (推荐)
package thread;public class Demo5 {public static void main(String[] args) throws InterruptedException {Thread t =new Thread(()->{while(true){System.out.println("hello Thread");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});t.start();while(true){System.out.println("hello main");Thread.sleep(1000);}}
}
6.观察多线程运行情况
多线程程序运行的时候,可以使用IDEA或者jconsole来观察到该进程里的多线情况。
package thread;
//创建一个类,继承来
class MyThread extends Thread{@Overridepublic void run() {//每个线程是一个独立的执行流//每个线程都可以执行一系列的逻辑(代码)//一个线程跑起来,从哪个代码开始执行???就是从他的入口方法//这个方法就是线程入口的方法while (true){System.out.println("这里是线程运行的代码");}}
}
public class Demo1 {public static void main(String[] args) {Thread t = new MyThread();//start 和 run 都是 Thread 的成员//run 只是描述了线程的入口(线程要做什么任务)//start 则是真正调用了系统API,在系统中创建出线程,让线程再调用runt.start();while(true){System.out.println("hello main");}}
}
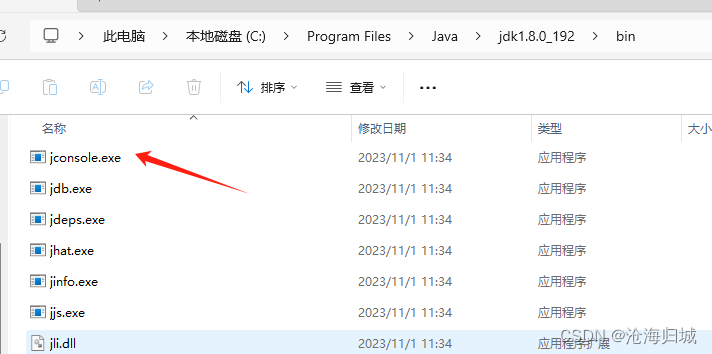
用jconsole来观察,这是JDK中带的工具。
如何找到jconsole,所在的文件夹?

- 启动之前,确保你idea中的程序已经跑起来了。
- 有些需要使用管理员方式运行。
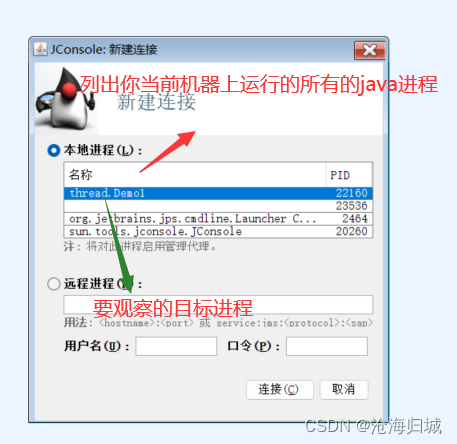
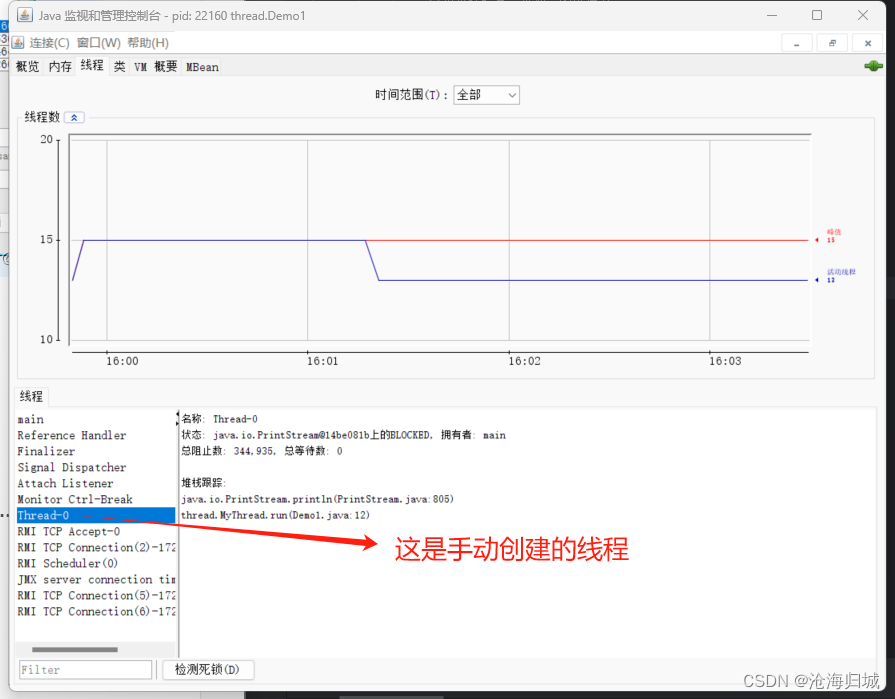
在jconsole,可以看到一个Java进程即便是最简单的,里面也包含了很多线程,除了手动创建的,其他线程线程都是JVM自动创建的。一个Java进程启动之后,JVM会在后面,默默的帮咱们做很多的事情。(比如,垃圾回收,资源统计,远程方法调用…)。
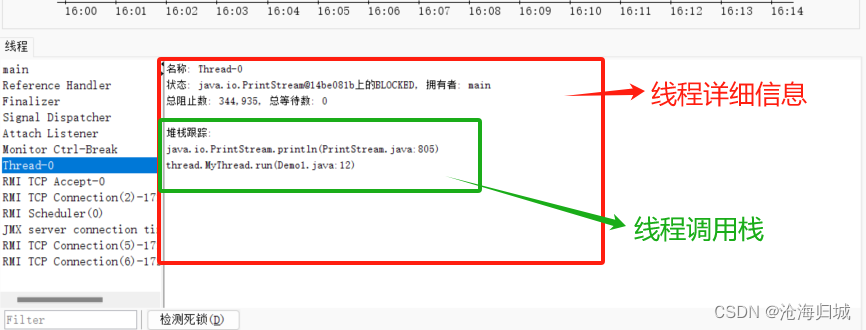
未来写一些多线线程程序的时候,就可以借助这个功能,能看到该线程实时的运行情况,比如:你写的程序卡死了。
当前这两线程,while循环转的太快了,如何让他慢点?
在循环体里,加上sleep。sleep是Thread的静态方法(static)。
sleep方法可能会抛出一个这样的异常,这个异常是受查异常,必须要显示处理。
修改后的代码:
package thread;
//创建一个类,继承来
class MyThread extends Thread{@Overridepublic void run() {//每个线程是一个独立的执行流//每个线程都可以执行一系列的逻辑(代码)//一个线程跑起来,从哪个代码开始执行???就是从他的入口方法//这个方法就是线程入口的方法while (true){System.out.println("这里是线程运行的代码");try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}}
}
public class Demo1 {public static void main(String[] args) throws InterruptedException {Thread t = new MyThread();//start 和 run 都是 Thread 的成员//run 只是描述了线程的入口(线程要做什么任务)//start 则是真正调用了系统API,在系统中创建出线程,让线程再调用runt.start();while(true){System.out.println("hello main");Thread.sleep(1000);}}
}
二、Thread的一些重要属性和方法
1.构造方法 和 name作用
| 方法 | 说明 |
|---|---|
| Thread() | 创建线程对象 |
| Thread(Runnable target) | 使用 Runnable 对象创建线程对象 |
| Thread(String name) | 创建线程对象,并命名 |
| Thread(Runnable target, String name) | 使用 Runnable 对象创建线程对象,并命名 |
| 【了解】Thread(ThreadGroup group,Runnable target) | 线程可以被用来分组管理,分好的组即为线程组,这个目前我们了解即可 |
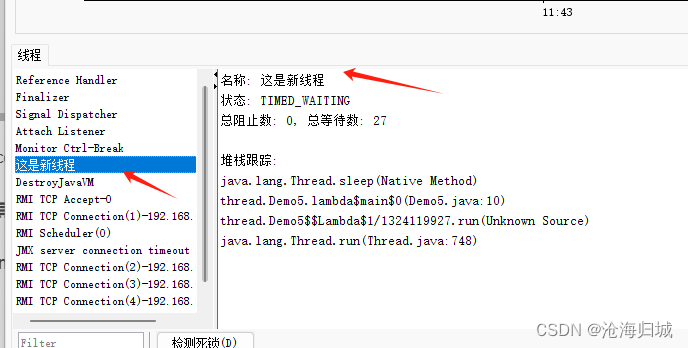
创建线程的时候,可以去指定name,name不影响线程的执行,只是给线程起个名字后续再调试的时候,比较方便区分。
package thread;public class Demo5 {public static void main(String[] args) throws InterruptedException {Thread t =new Thread(()->{while(true){System.out.println("hello Thread");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}},"这是新线程");t.start();}
}用jconsole来查看线程:
2.Thread的几个常见属性
1、ID
getId()
线程的身份标识,标识一个进程中唯一的一个线程。(这个id是Java给你这个线程分配的,不是系统api提供的线程id,更不是pcb中的id)
2、名称
getName()
3、状态
getState()
4、优先级
getPriority()
虽然提供了api可以设置/获取优先级,但是没啥用,应该程序的角度,很难察觉出,优先级带来的差异。
优先级影响到的是系统微观上进行的调度。
5、是否后台线程
isDaemon()
默认情况下一个线程是前台线程。
守护线程(后台线程)相比之下,后台线程不结束,不 影响整个进程的结束。
前台线程,一个java进程中,如果前台线程没有执行结束,此时整个进程,是一定不会结束的。
6、是否存活
isAlive()
7、是否被中断
isInterrupted()
Thread对象的生命周期,要比系统内核中的线程更长一些
Thread对象还在,内核中的线程已经销毁了这样的情况
3. 启动线程start
start方法内部,是会调用到系统api,来在系统内核中创建出线程。
run方法,就直说单纯的描述了该线程执行啥内容。(会在start创建好线程之后自动被调用的)。
start 和 run 的区别:
本质上的差别在于是否在系统内部创建出新的线程
4.终止线程
让一个线程停止运行(销毁),在Java中,要销毁/终止线程,做法是比较唯一的,就是想办法让run方法尽快执行结束。
1、方法一
可以在代码中手动创建出标志位,来作为run的执行结束的条件。
package thread;public class Deamo1 {private static boolean isQuit = false;public static void main(String[] args) throws InterruptedException {Thread t =new Thread(()->{while(!isQuit){System.out.println("线程工作");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("线程工作完毕");});t.start();Thread.sleep(5000);isQuit =true;System.out.println("设置 isQuit 为 true");}
}
此方案的缺点:
- 需要手动创建变量
- 当线程内部在sleep的时候,主线程修改变量,新线程内部不能及时响应。
2.方法二
调用interrupt()方法来通知
| 方法 | 说明 |
|---|---|
| public void interrupt() | 中断对象关联的线程,如果线程正在阻塞,则以异常方式通知,否则设置标志位 |
| public static boolean interrupted() | 判断当前线程的中断标志位是否设置,调用后清除标志位 |
| public boolean isInterrupted() | 判断对象关联的线程的标志位是否设置,调用后不清除标志位 |
| public static native Thread currentThread(); | 哪个线程调用这个方法,就会返回哪个线程的对象(获取到当前线程的实例)。 |
isInterrupted():
Thread 内部有一个标志位,这个标志位就可以用来判定线程是否结束。
inerrupt():
调用这个方法就是把Thread对象内部的标志位设置为true了。即使线程内部的逻辑出现阻塞(sleep)也是可以使用这个方法唤醒的。
package thread; public class Demo2 {public static void main(String[] args) throws InterruptedException {//Thread 类内部,有一个现成的标志位,可以用来判定之前的循环是否要结束Thread t = new Thread(()->{while(!Thread.currentThread().isInterrupted()){System.out.println("线程工作中!");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});t.start();Thread.sleep(5000);System.out.println("让t线程终止");t.interrupt();}
}
但是没有中断!!!
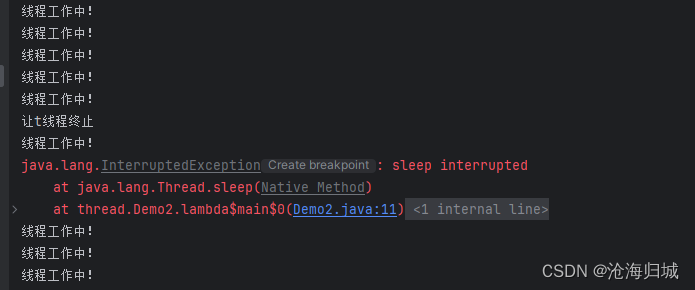
原因:
inrtrrupt在唤醒之后,此时sleep方法抛出异常,同时会自动清除刚才设置的标记位,这样就使“设置标志位”这样的效果就好像没有生效一样
package thread;public class Demo2 {public static void main(String[] args) throws InterruptedException {//Thread 类内部,有一个现成的标志位,可以用来判定之前的循环是否要结束Thread t = new Thread(()->{while(!Thread.currentThread().isInterrupted()){System.out.println("线程工作中!");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();break;}}});t.start();Thread.sleep(5000);System.out.println("让t线程终止");t.interrupt();}
}
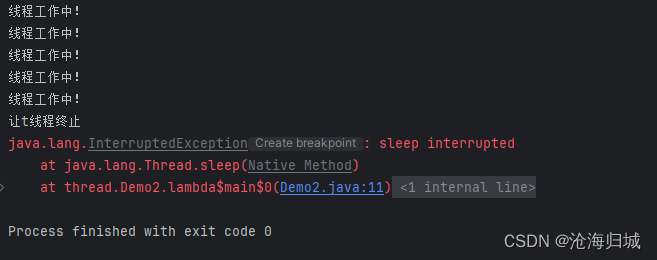
5.等待线程
有时,我们需要等待一个线程完成它的工作后,才能进行自己的下一步工作。
package thread;public class Demo3 {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(()->{for(int i = 0;i<5;i++){System.out.println(" t 线程工作中");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();break;}}});t.start();//让住线程等待t线程结束//一旦调用join,主线程就会触发阻塞,此时t线程就可以趁机完成后续的工作。//一直阻塞到t执行完毕了,join才会解除阻塞,才能继续执行System.out.println("join 等待开始");t.join();System.out.println("join 等待结束");}
}t.join工作过程:
- 如果t线程正在运行中,此时调用join的线程就会阻塞,一直阻塞到t线程执行结束为止。
- 如果t线程已经结束了,此时调用join线程,就直接返回了,不会涉及到阻塞
| 方法 | 说明 |
|---|---|
| public void join() | 等待线程结束 |
| public void join(long millis) | 等待线程结束,最多等 millis 毫秒 |
| public void join(long millis, int nanos) | 同理,但可以更高精度 |
6.获取线程引用
| 方法 | 说明 |
|---|---|
| public static Thread currentThread(); | 返回当前线程对象的引用 |
package thread;public class Demo4 {public static void main(String[] args) {Thread t = Thread.currentThread();System.out.println(t.getName());}
}
7.休眠线程
也是我们比较熟悉一组方法,有一点要记得,因为线程的调度是不可控的,所以,这个方法只能保证实际休眠时间是大于等于参数设置的休眠时间的。
| 方法 | 说明 |
|---|---|
| public static void sleep(long millis) throws InterruptedException | 休眠当前线程 millis毫秒 |
| public static void sleep(long millis, int nanos) throwsInterruptedException | 可以更高精度的休眠 |
三、线程的状态
0.观察线程的所有状态
线程的状态是一个枚举类型 Thread.State
package thread;public class Demo4 {public static void main(String[] args) {for(Thread.State state:Thread.State.values()){System.out.println(state);}}
}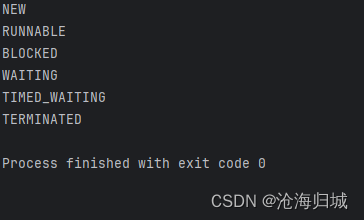
- NEW:Thread对象已经有了.start方法还没调用
- RUNNABLE:就绪状态(线程已经在cpu上执行了/线程正在排队等待上cpu执行)
- BLOCKED:阻塞,由于锁竞争导致的阻塞
- WAITING:阻塞,由于wait这种不固定时间方式产生的阻塞
- TIMED_WAITING:阻塞,由于sleep这个固定时间的方式产生的阻塞
- TERMINATED:Thread对象还在,内核中的线程已经没了
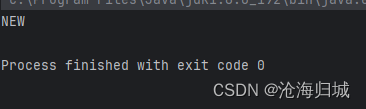
1.NEW
Thread对象已经有了.start方法还没调用
package thread;public class Demo5 {public static void main(String[] args) {Thread t = new Thread(()->{while (true){}});//在调用start之前获取状态,此时就NEW状态System.out.println(t.getState());}
}
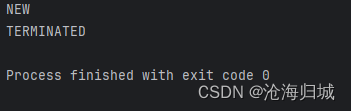
2.TERMINATED
Thread对象还在,内核中的线程已经没了
package thread;public class Demo5 {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(()->{
// while (true)
// {
//
// }});//在调用start之前获取状态,此时就NEW状态System.out.println(t.getState());t.start();t.join();//在线程执行结束之后,获取线程的状态,此时是TERMINATEDSystem.out.println(t.getState());}
}
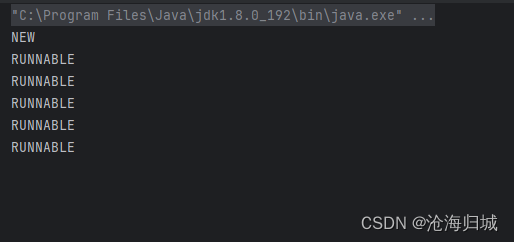
3.RUNNABLE
就绪状态(线程已经在cpu上执行了/线程正在排队等待上cpu执行)
package thread;public class Demo5 {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(()->{while (true){}});//在调用start之前获取状态,此时就NEW状态System.out.println(t.getState());t.start();for(int i =0;i<5;i++){System.out.println(t.getState());Thread.sleep(1000);}t.join();//在线程执行结束之后,获取线程的状态,此时是TERMINATEDSystem.out.println(t.getState());}
}
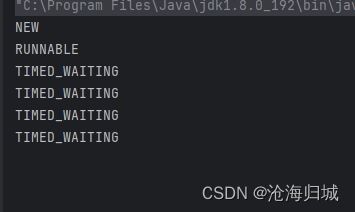
4.TIMED_WAITING
阻塞,由于sleep这个固定时间的方式产生的阻塞
package thread;public class Demo5 {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(()->{while (true){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});//在调用start之前获取状态,此时就NEW状态System.out.println(t.getState());t.start();for(int i =0;i<5;i++){System.out.println(t.getState());Thread.sleep(1000);}t.join();//在线程执行结束之后,获取线程的状态,此时是TERMINATEDSystem.out.println(t.getState());}
}
四、线程安全(重点)
1.线程不安全的例子
package thread;public class Demo6 {private static int count = 0;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(()->{for(int i = 0;i<50000;i++){count++;}});Thread t2 = new Thread(()->{for(int i = 0;i<50000;i++){count++;}});t1.start();t2.start();t1.join();t2.join();//预期结果10wSystem.out.println("count:"+count);}
}
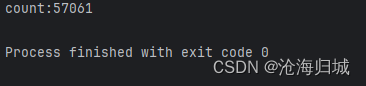
两个线程,并发进行上面的循环,此时逻辑就可能出现问题。
2.原因
如果像下面修改:
t1.start();t1.join();t2.start();t2.join();
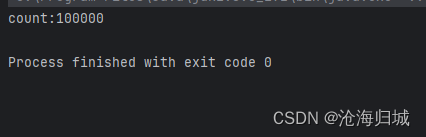
这段代码虽然写在两个线程,但是没有同时执行,此时没事。
count++这个操作,本质上,是分三步操作进行的,站在cpu的角度上,count++是由cpu通过三个指令来实现的。
- load 把数据从内存,读到cpu寄存器中
- add 把寄存器中的数据进行 +1
- sava 把寄存器中的数据,保存到内存中
如果是多个线程执行上述代码,由于线程之间的调度顺序是“随机”的,就会导致在有些调度顺序下,上述的逻辑就会出现问题。比如:
t1在count为10的时候把数据load到cpu里,此时t2完成俩次完整的count++后count为12,重新调度到t1时,t1会把之前的10进行+1,在保存到内存里count变成11了。这就是为什么两线程并发为count++5w此不能达到10w.
产生线程安全问题的原因:
- 操作系统中,线程的调度顺序是随机的(抢占式执行)。
- 两个线程,针对同一个变量进行修改
1、一个线程针对一个变量修改
2、两个线程对不同变量修改
3、两个线程对一个变量读取 - 修改操作,不是原子的
此处给定的count++就属于是非原子的操作(先读,在修改)
类似的,如果一段逻辑中,就需要根据一定条件来决定是否修改,也存在类似的问题 - 内存可见性问题
当前代码还不涉及 - 指令重排序问题
当前代码还不涉及
3.解决
想办法让count++这里的三步走,成为“原子”的,加锁!
如何给java中的代码加锁?
其中最常用的办法,就是使用synchronized关键字!
synchronized在使用的时候,要搭配一个代码块{ }进入{就会加锁}出来就会解锁。
在已经加锁的状态中,另一个线程尝试同样加这个锁,就会产生“锁冲突/锁竞争”,后一个线程就会阻塞等待。一直等到前一个线程解锁为止。
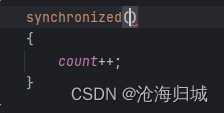
()中需要表示一个用来加锁的对象,这个对象是啥不重要,重要的是通过这个对象来区分两线程是否在竞争同一个锁。如果两线程是针对一个对象加锁,就会有锁竞争,如果不是针对同一个对象加锁,就不会有锁竞争,仍然是并发执行!
package thread;public class Demo6 {private static int count = 0;public static void main(String[] args) throws InterruptedException {Object locker =new Object();Thread t1 = new Thread(()->{for(int i = 0;i<50000;i++){synchronized(locker){count++;}}});Thread t2 = new Thread(()->{for(int i = 0;i<50000;i++){synchronized(locker){count++;}}});t1.start();t2.start();t1.join();t2.join();//预期结果10wSystem.out.println("count:"+count);}
}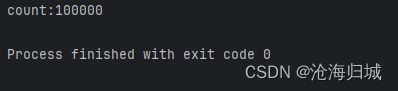
在t1load前就会加锁,如果在没有完整count++不会被解锁,如果在中间切走,t2由于锁的竞争,导致lock操作出现了阻塞,阻塞到t1线程unlock之后t2的lock才算执行完。
阻塞就避免了t2的load,add,save和第一个线程操作出现穿插,形成这种“串行“执行的效果。此时线程安全问题就迎刃而解了.
4.synchronized
synchronized 本质上要修改指定对象的 “对象头”. 从使用角度来看, synchronized 也势必要搭配一个具体的对象来使用。
Java的一个对象,对应的内存空间中,除了你自己定义的一些属性之外,还有一些自带的属性:对象头,在对象头里,其中就有属性表示当前对象是否已经加锁
1、直接修饰普通方法
锁的 Conter 对象
class Counter{public int count;synchronized public void increase(){count++;}
}
此时就是使用this作为锁的对象了。相当于下面代码:
public void increase2(){synchronized(this){count++;}}2、修饰静态方法
锁的 Counter 类的对象
synchronized public static void increase3(){}
如果修饰静态方法,相当于是针对类的对象加锁。相当于下面代码:
public static void increase4(){synchronized (Counter.class){}}
3、修饰代码块
明确指定锁哪个对象
Object locker =new Object();Thread t1 = new Thread(()->{synchronized (locker){}});
4、synchronized重要性质:可重入
所谓的可重入锁,指的是,一个线程,连续针对一把锁,加锁两次,不会出现死锁。满足这个要求,就是“可重入”,不满足就是"不可重入"
代码如下:
线程 t
锁对象 locker
synchronized (locker){synchronized (locker){.......}}
第一次加锁,假设能够加锁成功,此时locker就属于是“被锁定”状态。
进行第二次加锁,很明显locker已经锁定状态了,第二次加锁操作,原则上来说,是应该要“阻塞等待”的。应该要等待到,锁被释放了之后,才能加成功。但是实际情况,一旦第二次加锁的时候阻塞了,就会出现死锁的情况(线程卡死),第二次要想加锁成功,就需要第一次加锁释放锁,第一次加锁要想释放锁,就需要执行完第二次加锁这段代码,导致一个想加锁,一个无法释放锁。
如果是可重入锁,就不会卡死。
synchronized是可重入锁,在第二次加锁的代码块结束后是否要是否要释放锁?
如果有N层,释放的时机如何判定?
无论此处有多少层,都是要在最外层才能释放锁,采取了引用计数,锁对象中,不光要记录谁拿到了锁还要记录,锁被加了几次,每加锁一次,计数器就+1,每解锁一次,计数器就-1。出现最后一个大括号,恰好就是减到0了,才真正释放锁。
5、死锁
- 一个线程,针对一把锁,连续加锁两次,如果是不可重入锁,就死锁.(synchronized不会出现,C++的std::mutex就是不可重入锁,就会出现死锁)
- 两个线程,两把锁。(此时无论是不是可重入锁,都会死锁)
线程:t1 t2
锁:A B
1、t1获取A,t2获取B
2、t1尝试获取B,t2尝试获取A
3、 N个线程,M把锁。(相当于2的扩充)
6、如何解决/避免死锁呢?
死锁的成因,涉及到四个必要条件:
- 互斥使用.(锁的基本特性).当一个线程有一把锁之后,另一个线程也想获取到锁,就要阻塞等待。
- 不可抢占。(锁的基本特性)。当锁已经被线程1拿之后,线程2只能等待线程1主动释放,不能强行抢过来
- 请求保持(代码结构)。一个线程尝试获取多把锁。(先拿到锁1,再尝试获取锁2,获取的时候锁1不会释放)
- 循环等待/环路等待,等待的依赖关系,形成环了
要想出现死锁,也不是个容易事情。得把上面4条都占了,1和2都是锁本身的特性,只要代码中,把3和4占了就容易出现死锁!
解决死锁,核心就是破坏上述必要条件,只要破坏一个,死锁就形成不了。
1和2破坏不了(synchronzied自带特性,你无法干预)
对于3来说,调整代码结构,避免编写“锁嵌套”逻辑
对于4来说,可以预定加锁的顺序,就可以避免循环等待,针对锁,进行编号,比如约定,加多把锁的时候就,先加编号小的锁,后加编号大的锁。
5.volatile
1、内存可见性
计算机运行的程序/代码,经常要访问数据。这些依赖的数据,往往会存储在内存中。(定义一个变量,变量就是在内存中)
cpu使用变量的时候,就会把这个内存中的数据,先读出来,放到cpu的寄存器中在参与运算(load)
cpu读内存相比于读硬盘,快几千倍,上万倍,读寄存器,相比于读内存,又快了几千倍,上万倍。
cpu读内存的这个操作,其实非常慢!!!(快慢是相对的)
cpu进行大部分操作,都很快,一旦操作到读/写内存,此时速度一下就降下来了。
为了解决上述问题,提供效率,此时编译器,就可能对代码做出优化,把一些本来要读内存的操作,优化成读取寄存器,减少读内存的次数,也就可以提高程序的效率了。
package thread;import java.util.Scanner;public class Demo2 {private static int isQuit = 0;public static void main(String[] args) {Thread t1 = new Thread(()->{while(isQuit==0){}});t1.start();Thread t2 = new Thread(()->{System.out.println("请输入 isQuit");Scanner scanner = new Scanner(System.in);isQuit = scanner.nextInt();});t2.start();}
}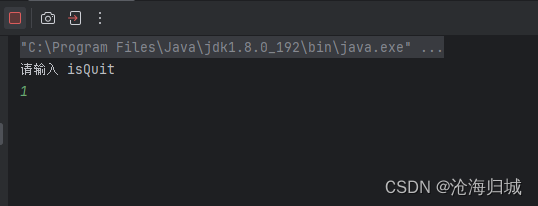
此时代码预期效果:
用户输入非0值之后,t1线程要退出。
但是,当我真正输入1的时候,此时t1线程并没有结束!!!
很明显,实际效果和预期效果不一样,由于多线程引起的,也是线程安全问题!
此处的问题,就是内存可见性引起的。
t1线程做了什么?
1、load读取内存中isQuit的值到寄存器中。
2、通过cmp指令比较寄存器的值是否是0,决定是否要继续循环。
由于这个循环,循环速度飞快,短时间内,就会进行大量的循环,也就是进行大量的load和cmp操作。
此时,编译器/JVM就发现了,虽然进行了这么多次load,但是load出来的结果都是一样的,并且load操作又非常 时间,一次load花的时间相当于上万次cmp了。
所以编译器就做了一个大胆的决定,只是第一次循环的时候,才读取内存,后续都不再读内存了,而且是直接从寄存器中,取出isQuit的值了。
编译器优化:
编译器的初心是好的,希望能够提高程序的效率,但是提高效率的前提是保证逻辑不变。此时由于修改isQuit代码是另一个线程的操作,编译器没有正确的判定,所以编译器以为没人修改isQuit,就做出了上述优化,也就进一步引出bug了,后续t2修改isQuit之后,t1感知不到isQuit变量的变化,volatile就是解决方案,在多线程环境下,编译器对于是否进行这样的优化,判定不一定准,就需要程序员通过volatile关键字,告诉编译器,你不要优化!!!
6.wait和notify
多线程中一个比较重要的机制,协调多个线程的执行顺序的,本身多个线程的执行顺序,是随机的(系统随机调度,抢占式执行的),很多时候是希望能够通过一定的手段,协调的执行顺序的。
join是影响到线程结束的先后顺序,相比之下,此处是希望线程不结束,也能够有先后顺序的控制。
wait等待,让指定线程进入阻塞状态。
notify通知,唤醒对应的阻塞状态的线程。
wait和notify都是Object的方法。随便定义一个对象,都可以使用wait和notify
package thread;public class Demo2 {public static void main(String[] args) throws InterruptedException {Object object = new Object();object.wait();}
}
执行后发现:

抛了个异常,非法的 监视器(synchronized也叫监视器锁) 状态 异常
wait在执行的时候要做三件事。
1、释放当前的锁
2、让线程进入阻塞
3、当线程被唤醒的时候,重新获取到锁
释放锁的前提是,先加锁。
package thread;public class Demo2 {public static void main(String[] args) throws InterruptedException {Object object = new Object();synchronized (object){System.out.println("wait 之前");object.wait();System.out.println("wait 之后");}}
}
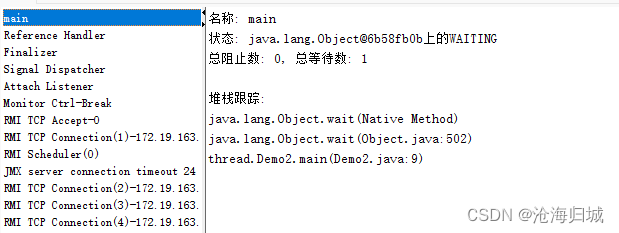
wait会持续的阻塞等待下去,直到其他线程调用notify唤醒。
一个线程wait一个线程唤醒:
package thread;public class Demo3 {public static void main(String[] args) throws InterruptedException {Object object = new Object();Thread t1 = new Thread(()->{synchronized (object){System.out.println("wait 之前");try {object.wait();} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("wait 之后");}});Thread t2 = new Thread(()->{try {Thread.sleep(3000);} catch (InterruptedException e) {throw new RuntimeException(e);}synchronized (object){System.out.println("进行通知");object.notify();}});t1.start();t2.start();}
}

“线程饿死”:
多个线程等待锁,都是阻塞状态,没在cpu上执行,当1号线程释放锁后,其他线程想要进入cpu,还需要调度的过程,而1号线程已经在cpu上执行,没有这个调度过程,更容易拿到锁,这就是线程饿死。
针对上述情况,同样也可以使用wait 和 notify 来解决。让在cpu上的1号线程进行wait,1号线程就不会参与后续的锁竞争了,也就把锁释放出来让别人获取。
notify:一次唤醒一个。
notifyAll:一次唤醒全部线程,唤醒的时候,wait要涉及到一个重新获取的过程,也是需要串行执行的。
调用wait不一定就只有一个线程调用,N个线程都可以调用wait,此时,当有多个线程调用的时候,这些线程都会进入阻塞状态。
wait除了默认的无参数版本之外,还有一个带参数的版本。带参数的版本就是指定超时时间,避免wait无休止的等待下去。
五、多线程案例
1.单例模式
单例=>单个实例(对象)。
有些场景中,希望有的类,只能有一个对象,不能有多个!!!在这样的场景下,就可以使用单例模式了。
1、饿汉模式
类加载的同时, 创建实例
class Singleton{//static成员,在Singleton类被加载的时候,就会执行到这里的创作实例的操作private static Singleton instance = new Singleton();//把构造方法设置为私有,此时类外面的其他代码,就无法new出这个类的对象private Singleton(){}//通过这个方法来获取到刚才的实例//后续如果想使用这个类的实例,都通过getInstance方法来获取public static Singleton getInstance(){return instance;}}
2、懒汉模式-单线程版
类加载的时候不创建实例. 第一次使用的时候才创建实例。
class SingletonLazy{private static SingletonLazy instance=null;public static SingletonLazy getInstance (){if(instance==null){instance =new SingletonLazy();}return instance;}private SingletonLazy(){}}
如果多个线程,同时修改同一个变量,此时就可能出现线程安全问题。
如果多个线程,同时读取一个变量,不会出现线程安全问题。
懒汉模式,即会读取,又会修改。
而饿汉模式,只会读取。
线程安全问题:
线程:t1 t2
t1在调getInstance时,还没有更改instance的时候,就被切走,t2发现instance依旧为空,就开始new。当再度切回t1,再度更改instance.此时就不再是单例,而是有多个实例。
3、懒汉模式-多线程版
思考:懒汉模式,线程安全问题发生时候?
在第一次new对象时候发生的,在后续获取,则是读取不存在线程安全问题。
为什么不在每次获取加锁?
加锁和解锁是一件开销比较高的事情。
在判断是否实例时,会用到if,但在多线程的时候,会有内存不可见性问题,就需要对类的引用加上volatile
class SingletonLazy2{volatile private static SingletonLazy2 instance=null;public static SingletonLazy2 getInstance (){if(instance==null){synchronized(SingletonLazy2.class){if(instance==null){instance =new SingletonLazy2();}}}return instance;}private SingletonLazy2(){}}
指令重排序:也是编译器优化,编译器为了执行效率,可能会调整原有代码的执行顺序,调整的前提是保证逻辑不变。
对于指令重排序,可能对上述代码产影响。
new操作,是可能会触发指令重排序的:
- 申请内存空间
- 在内存空间上构造对象
- 把内存的地址,赋值给instance引用
可以按照123来执行,也可以按照132来执行,如果是132来执行,t1了13还没有执行到2,也就是还没有初始化,线程被 切到t2,判断发现instance有地址了,但是内容是没有被初始化的,就会有访问没有被初始化的非法对象。
针对上述问题,解决方案,仍然是volatile,让volatile修饰Instance,此时就可以保证Instance在修改的过程中就不会出现指令重排序的现象了。
2.阻塞队列
1、阻塞队列是什么
多线程代码中比较常用到的一种数据结构,特殊的队列。
- 线程安全
- 带有阻塞特性
a. 如果队列为空,继续出队列,就会发生阻塞,阻塞到其他线程往队列添加元素为止。
b.如果队列为满,继续入队列,也会发生阻塞,阻塞到其他线程从队列取走元素为止。
阻塞队列,最大的意义,就是可以用来实现,“生产者消费者模型”
2、生产者消费者模型
意义:
1.解耦合
两个模块,联系越紧密,耦合就越高。尤其是对于分布式系统来说,是更加有意义的。
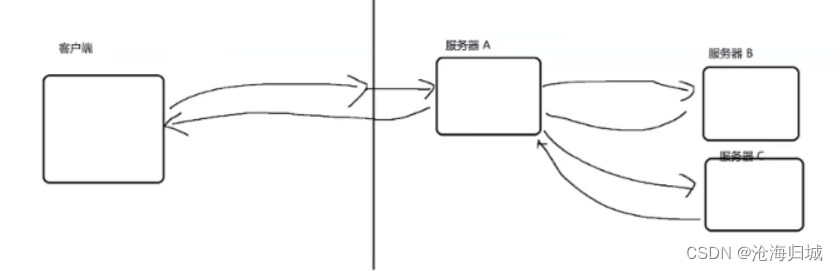
如果A和B直接交互(A把请求发给B,B把响应返回给A)
彼此之间的耦合就是比较高的。
1.如果B出现问题,很可能就把A也影响到了
2.如果未来再添加一个C,就需要对A这边的代码,做出一定的改动。
相比之下,使用生产者消费者模型,就可以有效的解决刚才的耦合问题。
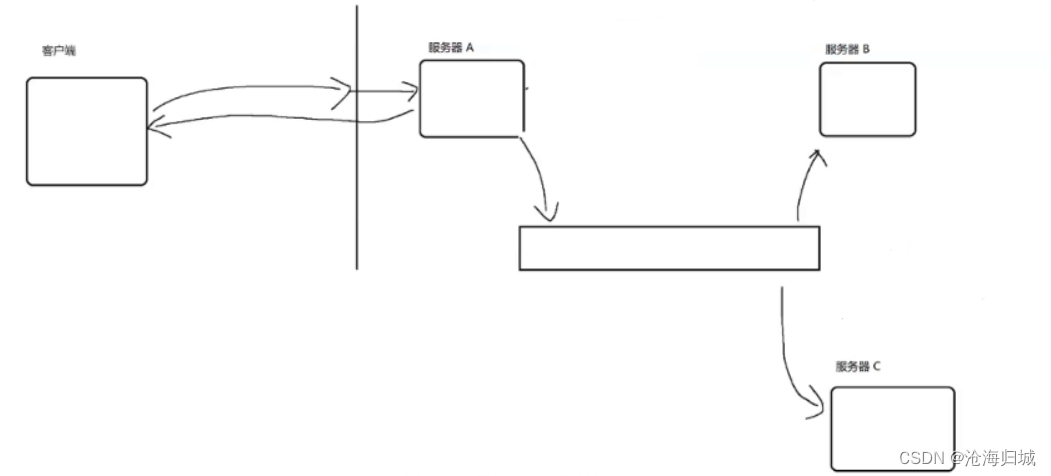
此时,耦合就会被降低,如果B这边出现问题,就不会对A产生直接的影响。(A只是和队列交互,不知道B的存在)
后续如果新增一个C,此时A不必进行任何修改,只需要让C从队列中获取数据即可。
因为不同服务器,上面跑的业务不同,虽然访问量一样,单个访问,消耗的硬件资源不一样,可能A承担这些并发量,没事B承担这些并发量就会挂!
如果引入生产者消费者模型,A这边收到了较大的请求量,A会把对应的请求写入到队列中,B仍然可以按照之前的节奏,来处理请求。
比如,正确情况下,A和B,每秒处理1000次请求,极端情况下,A这边每秒处理3000次请求,如果让B也处理3000次,就要挂了,队列帮B承担了压力,B仍然可以按照1000次的节奏,处理请求。
与其直接把B搞挂了,不如让B慢点搞,虽然A这边得到响应的速度会慢,总好过完全没响应,就会有一定的请求在队列积压。
像上述的峰值情况,一般不会持续存在,只会短时间出现,过了峰值之后,A的请求就恢复正常,B就可以逐渐的把积压的数据都给处理掉了。
3、标准库中的阻塞队列
在Java标准库里,已经提供了现成的阻塞队列,让咱们直接使用。
标准库里,针对BlockingQueue提供了两种最重要的实现方式:
1.基于数组
2.基于链表
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
// 入队列
queue.put("abc");
// 出队列. 如果没有 put 直接 take, 就会阻塞.
String elem = queue.take();

Queue这里提供的各种方法,对于BlockingQueue来说也可以使用,但一般不建议使用这些方法。这些方法,都不具备“阻塞”特性。
put阻塞式的入队列
take阻塞式的出队列
4、模拟实现阻塞队列
class MyBlockingQueue{//此处这里的最大长度,也是可以指定构造方法,由构造方法的参数来制定private String [] data = new String[1000];//队列起始位置volatile private int head =0;//队列中的结束位置的下一个位置volatile private int tail =0;//队列中有效元素的个数volatile private int size = 0;//提供核心方法,入队列和出队列
synchronized public void put(String elem) throws InterruptedException {while(size==data.length){//队列满了//如果是普通队列,满了就直接return即可。this.wait();}//队列没满,真正的往里面添加元素data[tail] = elem;tail++;tail%=data.length;size++;this.notify();}synchronized public String take() throws InterruptedException {while(size==0){//队列空的//对于普通队列,直接返回就行了this.wait();}String ret = data[head++];head%=data.length;size--;this.notify();return ret;}}
测试代码:
public class Demo2 {public static void main(String[] args) throws InterruptedException {MyBlockingQueue queue1 = new MyBlockingQueue();//生产者Thread t1 =new Thread(()->{int num=1;while(true){try {queue1.put(num+"");System.out.println("生产元素: "+num++);
// Thread.sleep(500);} catch (InterruptedException e) {throw new RuntimeException(e);}}});//消费者Thread t2 =new Thread(()->{while (true){try {String result = queue1.take();System.out.println("消费元素: "+result);Thread.sleep(500);} catch (InterruptedException e) {throw new RuntimeException(e);}}});t1.start();t2.start();}
}

生产者快,消费者慢,生产一个消费一个。
测试代码:
public class Demo2 {public static void main(String[] args) throws InterruptedException {MyBlockingQueue queue1 = new MyBlockingQueue();//生产者Thread t1 =new Thread(()->{int num=1;while(true){try {queue1.put(num+"");System.out.println("生产元素: "+num++);
// Thread.sleep(500);} catch (InterruptedException e) {throw new RuntimeException(e);}}});//消费者Thread t2 =new Thread(()->{while (true){try {String result = queue1.take();System.out.println("消费元素: "+result);Thread.sleep(500);} catch (InterruptedException e) {throw new RuntimeException(e);}}});t1.start();t2.start();}
}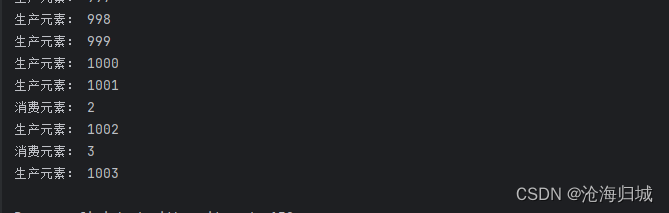
生产快,消费慢,一次性生产到队列上限,后生产一个消费一个。
3.定时器(日常开发常见组件)
1、标准库中的定时器
约定一个时间,时间到达之后,执行某个代码逻辑。
定时器非常常见,尤其是在进行网络通信的时候。
标准库中提供了一个 Timer 类. Timer 类的核心方法为 schedule .
schedule 包含两个参数. 第一个参数指定即将要执行的任务代码, 第二个参数指定多长时间之后执行 (单位为毫秒)
import java.util.Timer;
import java.util.TimerTask;public class Demo3 {public static void main(String[] args) {Timer timer = new Timer();//给定时器安排一个任务,预定在xxx时间去执行timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("执行定时器任务");}},2000);System.out.println("程序启动");}
}
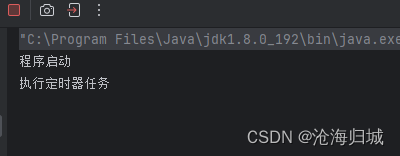
主线程执行schedule方法的时候,就把这个任务放到timer对象了,于此同时timer里头也包含一个线程,这个线程叫做“扫描线程”,一旦时机到,扫描线程就会执行刚才安排的任务了。
仔细观察,可以发现,整个进程没有结束!!就是因为Timer内部线程,阻止了进程结束。Timer里,是可以安排多个任务的。
2、实现简单的定时器
1.Timer中需要有一个线程,扫描任务是否到时间,可以执行了。
2.需要有一个数据结构,把任务都保存起来
3.还需要建一个类,通过类的对象来描述一个任务。(至少包含任务内容和时间)
class MyTimerTask implements Comparable<MyTimerTask>{//要有一个执行的任务private Runnable runnable;//还要有一个执行任务时间private long time;public MyTimerTask(Runnable runnable,long delay){this.runnable = runnable;this.time = System.currentTimeMillis()+delay;}@Overridepublic int compareTo(MyTimerTask o) {return (int) (this.time-o.time);}public long getTime(){return time;}public Runnable getRunnable(){return runnable;}}class MyTimer{//使用一个数据结构,保存所有要安排的任务private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();private Object locker = new Object();public void schedule(Runnable runnable,long delay){synchronized (locker){queue.offer(new MyTimerTask(runnable,delay));locker.notify();}}//搞一个扫描线程public MyTimer(){//创建一个扫描线程Thread t = new Thread(()->{//扫描线程,需要不停的扫描队首元素,看是否到达时间。while (true){synchronized (locker){try {while (queue.isEmpty()){//使用wait进行等待locker.wait();}} catch (InterruptedException e) {e.printStackTrace();}MyTimerTask task = queue.peek();long curTiem = System.currentTimeMillis();if(curTiem>=task.getTime()){task.getRunnable().run();queue.poll();}else{//当前时间还没到任务时间try {locker.wait(task.getTime()-curTiem);} catch (InterruptedException e) {e.printStackTrace();}}}}});t.start();}
}
4.线程池
线程诞生的意义,是因为进程的创建/销毁,太重量了(比较慢),和进程比,线程是快了,但是如果进一步提高创建销毁的频率,线程的开销也不能忽略了!!
两种典型的办法,进一步提高效率:
- 协程(轻量级线程)相比于线程,把系统调度的过程,给省略了。(程序员手工调度)当下,一种比较流行的并发编程的手段。但是在Java圈子里,协程还不够流行。
- 线程池,这个方案,使线程也不至于很慢。
线程池:在使用第一个线程的时候,提前把2,3,4,5…线程创建好。后续如果想使用新线程,不必重写创建了,直接拿来就能用。(此时创建线程的开销就被降低了)
把线程创建好,放在池子里,后续用的时候直接从池子里取,为啥,从池子里取,的效率比新创建线程,效率更高???
从池子取,这个动作,是纯粹用户态的操作。
创建新的线程,这个动作,则是需要用户态+内核态相互配合,完成的操作。
如果一段程序,是在系统内核中执行,此时就称为“内核态”,如果不是,则称为“用户态”,操作系统是由内核+配套的应用程序构成的,系统最核心的部分,就是内核,创建线程操作,就需要调用系统api,进入内核中,按照内核态的方式完成一系列的动作。
1、标准库中的线程池
Java标准库中,也有线程池具体的实现。
ExecutorService service = Executors.newCachedThreadPool();
线程池对象不是咱们直接new的,而是通过一个专门的方法,返回了一个线程池对象。Executors.newCachedThreadPool()就是工厂模式(设计模式),通常创建对象,使用new,new关键字会触发类的构造方法,但是构造方法,存在一定的局限性。而工厂模式是给构造方法填坑的。
很多时候,构造一个对象,希望有多种构造方式,多种方式,就需要使用多个版本的构造方法来分别实现。但是构造方法要求的名字必须是类名,不同的构造方法,只能通过重载方方式来区分了,但如果两种构造方法,但参数类型/个数一样就无法构成重载。
使用工厂设计模式,就能解决这个问题,使用普通的方法,代替构造方法完成初始化工作。普通方法就可以使用方法名来区分了,也就不再收到了重载的规则制约了。
Executors就是工厂类,newCachedThreadPool()就是工厂方法
2、Executors创建线程池发几种方式
newFixedThreadPool: 创建固定线程数的线程池
newCachedThreadPool: 创建线程数目动态增长的线程池.
newSingleThreadExecutor: 创建只包含单个线程的线程池.
newScheduledThreadPool: 设定 延迟时间后执行命令,或者定期执行命令. 是进阶版的 Timer
上述这几个工厂方法生产的线程池,本质上都是对一个类进行的封装,ThreadPoolExecutor这个类,功能非常丰富,提供了很多参数,标准库上述的几个工厂方法,其实就是给这个类填写了不同的参数用来构造线程池了。
ThreadPoolExecutor核心方法就两个:
1、构造,构造方法中的参数很多(重点)
2、注册任务(添加任务)
ThreadPoolExecutor的构造方法
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
参数:
int corePoolSize :核心线程数
int maximumPoolSize :最大线程数
描述了线程池中,线程数目,这个线程池里线程的数目是可以变动的,变化范围是[corePoolsize,maximumPoolSize]
long keepAliveTime:没有新任务,大于核心线程数的线程,允许存活一定时间后,如何没有新任务就销毁。
TimeUnit unit:时间单位
BlockingQueue workQueue:阻塞队列,存放线程池中的任务的。可以根据需要灵活设置这里的队列是啥,需要优先级,就可以设置PriorityBlaockingQueue如果不需要优先级,并且任务数目是相对恒定的,可以使用ArrayBlockingQueue如果不需要优先级,并且任务数目变动较大LinkedBlockingQueue
ThreadFactory threadFactory :工厂模式的体现,此处使用ThreadFactory作为工厂类由这个负责创建线程,使用工厂类创建线程,主要是为了在创建过程中,对线程的属性做出一些设置。
RejectedExecutionHandler handler:线程池的拒绝策略,一个线程池,能容纳的任务数量是有上限,当持续往线程池里添加任务的时候,一旦已经达到上限了,继续再添加,会出现什么效果???以下四种就是决策略
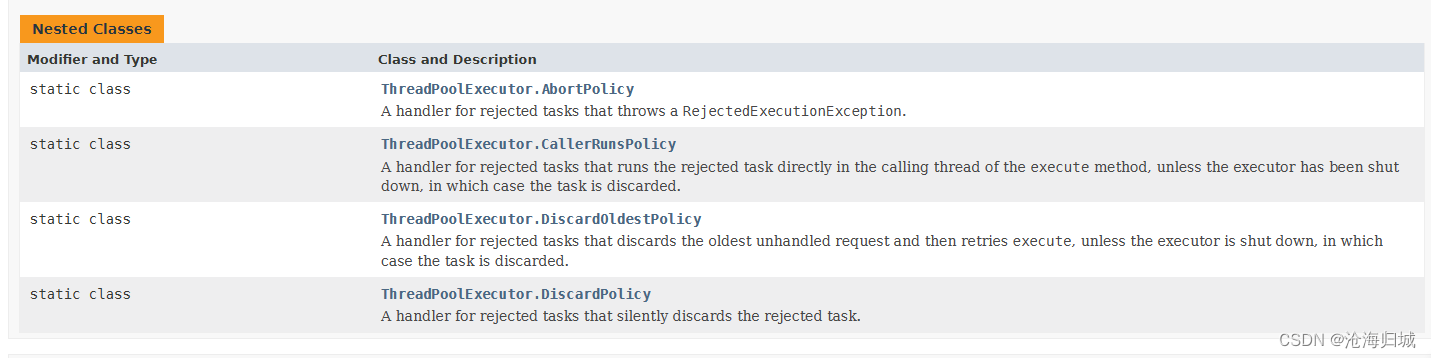
ThreadPoolExecutor.AbortPolicy:如果队列满了,直接抛出异常
ThreadPoolExecutor.CallerRunsPolicy:新添加的任务,由添加任务的线程负责执行
ThreadPoolExecutor.DiscardOldestPolicy :丢弃任务队列中最老的任务
ThreadPoolExecutor.DiscardPolicy:丢弃当前新加的任务
使用线程池,需要设置线程数目,数目设置多少合适??
因为在接触到实际的项目代码之前,是无法确定的!!!
一个线程,执行的代码主要有两类:
1、cpu密集型:代码里主要逻辑是在进行算术运算/逻辑判断
2、IO密集型:代码里主要进行的是IO操作
假设一个线程的所有代码都是cpu密集型代码,这个时候,线程池的数量不应该超过N(设置N就是极限了)
假设一个线程的所有代码都是IO密集型,这时候不吃CPU,此时设置的线程数,就可以是超过N.较大的值。一个核心可以通过调度的方式,来并发执行
代码不同,线程池的线程数目设置就不同,无法知道一个代码,具体多少内容是cpu密集,多少内容是IO密集。
正确做法:使用实验的方式,对程序进行性能测试,测试的过程中尝试修改不同的线程池的线程数目,看看哪种情况下,最符合你的要求。
3、模拟简单的线程池
package thread;import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.BlockingQueue;class MyThreadPool{//创建出n个线程,负责执行上述队列中的任务//任务队列private BlockingQueue<Runnable> queue =new ArrayBlockingQueue<>(1000);//通过这个方法,把任务添加到队列中public void submit(Runnable runnable) throws InterruptedException {queue.put(runnable);}public MyThreadPool(int n){for(int i = 0; i<n; i++){Thread t = new Thread(()->{//让这个线程,从任务队列中消费任务,并进行执行while(true){try {Runnable runnable =queue.take();runnable.run();} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}}
}测试代码:
public class Demo2 {public static void main(String[] args) throws InterruptedException {MyThreadPool myThreadPool =new MyThreadPool(4);for(int i = 0;i<1000;i++){int id = i;myThreadPool.submit(new Runnable() {@Overridepublic void run() {System.out.println("执行任务: "+id);}});}}
}
这篇关于Java_多线程初阶_多线概念_Thread_线程安全_wait notify_线程案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




