本文主要是介绍GNG论文+实验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GNG论文思路:
- GNG-A
- OGNG
- GNG-T
- GNG-Ada中的loss
- GNG降维可视化
- GWR
文章目录
- 前言
- 原始GNG
- 一、GNG-A
- 1.移除不相关神经元的机制
- 二、OGNG
- 1.插入外部神经元
- 2.基于“密度”来删除神经元
- 三、GNG-T
- 实验:动态阈值
- 四、GNG-Ada中的loss
- 五、bagging+集成学习+投票
- 1.权重的分配
- 2.动态重构的过程
- 3.集成决策输出
- 六、GNG降维可视化
- 七、GWR
前言
更新:2024/01/11
上世纪 90 年代,人工神经网络研究人员得出了一个结论:有必要为那些缺少网络层固定拓扑特征的运算机制,开发一个新的类。也就是说,人工神经在特征空间内的数量和布置并不会事先指定,而是在学习此类模型的过程中、根据输入数据的特性来计算,独立调节也与其适应。我们注意到,CNN/RNN这种在训练开始前就预先设置好了网络的神经元拓朴结构而训练的过程只是在调整这些神经元的参数,对于无监督学习的场景来说,大多数情况下,我们是无法预先知道输入数据空间的拓朴分布的。
理解上就是GNG是一种动态增长型神经网络,举个例子,对于神经网络中有的任务需要选择小的网络结构,有的需要使用大的网络结构,GNG相当于是按需增长型以完成对输入的拓扑结构学习。
实际场景中,就是因为出现了大量输入参数的压缩和向量量化受阻的实际问题,比如语音与图像识别、抽象范式的分类与识别等。当输入不一致的,如果要进入深度神经网络DNN/CNN训练,是必须要进行裁剪压缩等处理,这可能会丢失一部分的输入数据的拓朴结构。
这里可以理解为PCA降维过程中,保留主要信息,但是破坏了原有特征间的联系,无法保持拓扑结构的问题。
自组织映射与赫布型学习已为人所知(尤其是生成网络拓扑即在神经元之间创建一系列连接,构成一个"框架"层的算法),而且 “软” 竞争学习的方法亦已算出(在此类流程中,权重不仅适应"赢家"神经元,还适用其"近邻"神经元,本次竞争失败的神经元也要调整一下自己的参数,争取下次成功),合理的步骤是将上述方法结合起来,而这已由德国科学家 Bernd Fritzke 于 1995 年完成,从而创建了如今的流行算法 “生长型神经气”(GNG)
GNG原文地址:
链接: https://proceedings.neurips.cc/paper/1994/hash/d56b9fc4b0f1be8871f5e1c40c0067e7-Abstract.html
此方法被证实非常成功,所以出现了一系列由其衍生的修改版本;其中之一就是监督式学习的改编适应版本 (Supervised-GNG)。勿庸置疑,GNG 要优于 “K-means” 聚类。
原始GNG

- 创建两个节点,并初始化它们之间的连接边,将它们添加到图中。
- 对于每个输入数据,找到离输入节点最近的两个节点。
- 更新最近邻节点的位置和错误,以及连接最近邻节点和最近邻节点的邻居节点的边的年龄。
- 如果最近邻的节点和次近邻的节点之间没有边连接,那么则在两个节点之间加一条边,然后将age置0,如果有连接也置零。
- 如果当前的步数是lamda的倍数,且节点数没有达到最大值,则新建一个节点,将其加入到图中。
- 对于所有节点的错误率进行衰减。
- 如果需要,删除孤立节点和重要性参数较小的点。
- 重复上述步骤,直到所有数据都被训练完毕。
一、GNG-A
链接: An adaptive algorithm for anomaly and novelty detection in evolving data streams
1.移除不相关神经元的机制
-
定义局部变量 C n C_n Cn: 对于每个神经元 n n n,引入了一个局部变量 C n C_n Cn,用于估算移除该神经元的代价。 C n C_n Cn 的值表示了如果移除神经元 n n n,那么与 n n n 关联的数据点会被重新分配给其附近的神经元,从而导致附近神经元的总误差增加。因此, C n C_n Cn 的计算基于与神经元 n n n 关联的数据点到其第二近的神经元的距离。
-
计算 C n C_n Cn: 公式中的 C n C_n Cn 表示为:
C n = ∑ i = 0 t 1 ( n = n x i ) × ∣ x i − n x i ∗ ∣ C_n = \sum_{i=0}^t \mathbb{1}(n=n_{x_i}) \times |x_i - n_{x_i}^{*}| Cn=i=0∑t1(n=nxi)×∣xi−nxi∗∣
这里, t t t 是当前时间步, 1 ( C o n d ) \mathbb{1}(Cond) 1(Cond) 是一个条件为真时为 1,否则为 0 的指示函数。这个公式的含义是,对于每个步数,当一个数据点与神经元 n n n 关联时, C n C_n Cn 会增加该数据点到其第二近的神经元的距离。 -
在线计算 C n C_n Cn: 针对每个新接收的数据点 x x x,找到与其最近的神经元 n x ∗ n_x^* nx∗(即获胜神经元),然后将该神经元的 C n x ∗ C_{n_x^*} Cnx∗ 值增加 ∣ x − n x ∗ ∣ |x - n_x^*| ∣x−nx∗∣,表示了该数据点到其第二近的神经元的距离。
-
指数衰减 C n C_n Cn: 在每个迭代中,对所有现有的神经元, C n C_n Cn 会以指数方式减小:
∀ n ∈ G , C n ← 0.9 × C n \forall n \in G, \quad C_n \leftarrow 0.9 \times C_n ∀n∈G,Cn←0.9×Cn
C n C_n Cn 随时间以指数速度衰减、 -
决定移除神经元: 根据 C n C_n Cn 的值,可以判断神经元的相关性。当 C n C_n Cn 足够小时,可以触发遗忘机制,移除该神经元。但是,由于 C n C_n Cn 的值会快速接近 0,很难直接设置一个阈值。因此,提出了一个更方便的策略,即当 − log C n ^ -\log C_{\hat{n}} −logCn^ 足够高时触发移除操作,其中 n ^ \hat{n} n^ 是具有最小 C n C_n Cn 值的神经元, τ \tau τ 是一个上限生存阈值。较小的 τ \tau τ 会导致更快的遗忘,较大的 τ \tau τ 会保留更长时间的记忆,具体阈值的选择取决于数据分布和其变化速度。
-
自适应阈值 τ \tau τ: 为了确定 τ \tau τ 的合适值,用自适应的方法
- 如果应该被移除 − log C n ^ > τ -\log C_{\hat{n}}>\tau −logCn^>τ,则将 τ \tau τ 以 τ ← τ + ϵ × [ ( − log C r x ˙ ∗ ) − τ ] , \tau \leftarrow \tau+\epsilon \times\left[\left(-\log C_{r_{\dot{x}}^*}\right)-\tau\right], τ←τ+ϵ×[(−logCrx˙∗)−τ],增加阈值;
- 如果不应该被移除 − log C n ^ > τ -\log C_{\hat{n}}>\tau −logCn^>τ,则将 τ \tau τ 以 τ ← τ − ϵ × [ ( − log C r x ˙ ∗ ) − τ ] , \tau \leftarrow \tau-\epsilon \times\left[\left(-\log C_{r_{\dot{x}}^*}\right)-\tau\right], τ←τ−ϵ×[(−logCrx˙∗)−τ],减小阈值;
ϵ \epsilon ϵ是一个0到1的很小的学习率,这个学习率也是随着步数逐渐减少达到收敛的:
ϵ = 1 1 + N τ \epsilon=\frac{1}{1+N_\tau} ϵ=1+Nτ1
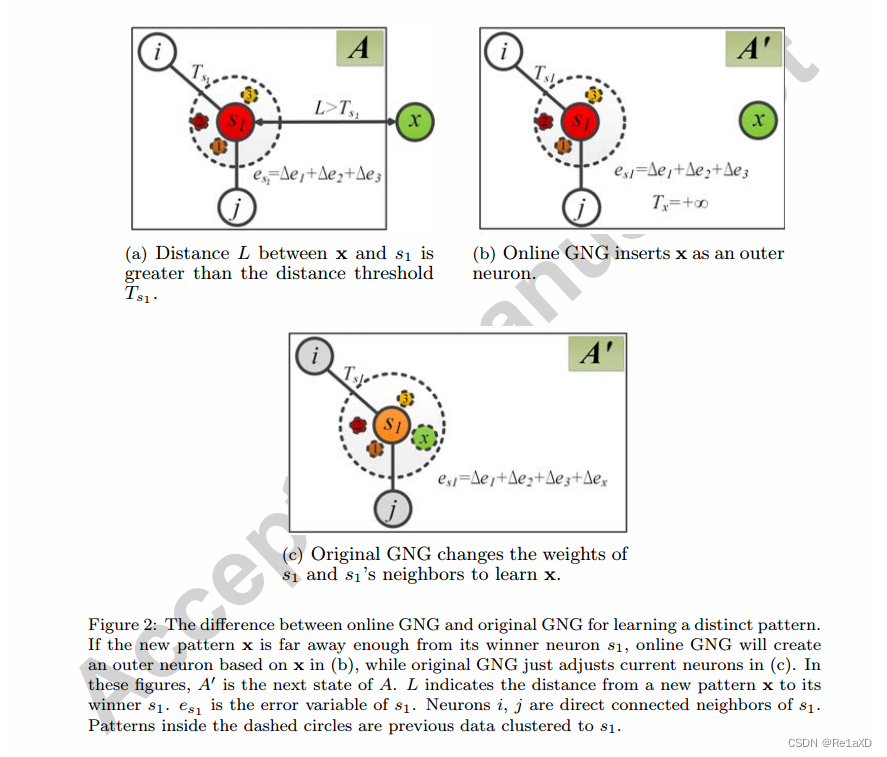
二、OGNG
链接: Online growing neural gas for anomaly detection in changing surveillance scenes
1.插入外部神经元
- 在原始的GNG插入的基础上,增加外部插入的阈值,阈值计算为当前节点离所有邻居最远的距离
2.基于“密度”来删除神经元
- 先计算获胜节点离所有邻居的平均距离
- 然后计算分数(越稀疏分数越低) score i = e − dist i ‾ \text { score }_i=e^{-\overline{\text { dist }_i}} score i=e− dist i
- 计算总得分(每次都不停的累加),除以次数为平均得分 a s i = ∑ k = 1 K ∑ j = 1 λ score i ( k , j ) a s_i=\sum_{k=1}^K \sum_{j=1}^\lambda \text { score }_i(k, j) asi=k=1∑Kj=1∑λ score i(k,j)
- 最后删除分低的,基于阈值
- 阈值计算方法为,计算所有节点的分数,然后除以节点数量得到平均值当作阈值
三、GNG-T
链接: Following non-stationary distributions by controlling the vector quantization accuracy of a growing neural gas network
E ˉ i = ∫ V i d ( ξ , w i ) p ( ξ / ξ ∈ V i ) d ξ = ( ∫ V i d ( ξ , w i ) p ( ξ ) d ξ ) / ( ∫ V i p ( ξ ) d ξ ) . \begin{aligned} \bar{E}i & =\int{V_i} d\left(\xi, w_i\right) p\left(\xi / \xi \in V_i\right) \mathrm{d} \xi \ & =\left(\int_{V_i} d\left(\xi, w_i\right) p(\xi) \mathrm{d} \xi\right) /\left(\int_{V_i} p(\xi) \mathrm{d} \xi\right) . \end{aligned} Eˉi=∫Vid(ξ,wi)p(ξ/ξ∈Vi)dξ =(∫Vid(ξ,wi)p(ξ)dξ)/(∫Vip(ξ)dξ).
-
原理:总误差 E E E等于各部分误差项 E i E_i Ei的总和,当 E i E_i Ei的值趋于一个相同的值相等 T T T时,总误差就达到最小。GNG-T的目标是通过控制这个 T T T值,调整网络收敛到目标值。
-
误差累积:当 w i w_i wi作为获胜节点,输入样本为 ξ \xi ξ时,它将样本 ξ \xi ξ与自己的距离 d ( w i , ξ ) d(w_i, \xi) d(wi,ξ)累积到一个累加器 e i = ∑ 1 ≤ j ≤ n i d ( ξ j i , w i ) e_i=\sum_{1 \leq j \leq n_i} d(\xi_j^i, w_i) ei=∑1≤j≤nid(ξji,wi)中。这个累加误差 e i e_i ei估计了 E i E_i Ei,即 E ˉ i \bar{E}_i Eˉi的值。
-
估算 E i E_i Ei:在一个包含N个样本的时期内,可以使用累加误差 e i e_i ei来估算 E i E_i Ei。这可以表示为 E i ≈ e i N E_i \approx \frac{e_i}{N} Ei≈Nei。这个过程可以在每个原型上独立进行,但需要知道时期大小 N N N。
-
目标值 T T T:GNG-T的核心思想是,当所有的 E i E_i Ei在平衡状态下都达到相同的值 T ′ T' T′时,将 T ′ T' T′与期望目标 T T T进行比较。如果 T T T小于 T ′ T' T′,则需要更多的神经元以提高量化的准确性。相反,如果 T T T大于 T ′ T' T′,则当前的量化太精确,需要移除一些神经元。
-
1 / N 1/N 1/N因子的去除:在原文中, 1 / N 1/N 1/N因子用于对计算进行规范化,使其与实际时期大小 N N N无关。然而,为了处理非稳态分布,建议删除这个因子,以便更好地反映分布概率的变化。
-
实现:GNG-T算法的实现是通过处理连续的时期来完成的。每个时期都开始于具有v个节点的图,这个图是前一次计算的结果。算法的主要步骤包括初始化、累积误差、更新权重、调整网络大小以使 e i e_i ei接近 T T T等。
GNG-T算法是一种用于自适应数据量化和聚类的算法,通过控制每个神经元的累积误差来实现对网络结构的自动调整,以适应不同的分布情况。这个算法的设计思想和步骤使得它适用于处理非稳态分布,并且提供了一个易于解释的目标值 T T T来控制量化的准确性。
实验:动态阈值
s c o r e i = v o t i n g _ n o d e _ s c o r e i m a x _ v o t i n g _ n o d e _ s c o r e × e − d i score_i = \frac{voting\_node\_score_i}{max\_voting\_node\_score} \times e^{-d_i} scorei=max_voting_node_scorevoting_node_scorei×e−di
变量含义:
- s c o r e i score_i scorei:第 i i i 个投票节点的最终得分
- v o t i n g _ n o d e _ s c o r e i voting\_node\_score_i voting_node_scorei:第 i i i 个投票节点的分数
- m a x _ v o t i n g _ n o d e _ s c o r e max\_voting\_node\_score max_voting_node_score:参与投票节点中最高的分数
- d i d_i di:第 i i i 个投票节点到当前数据点的欧氏距离
四、GNG-Ada中的loss
loss1计算公式:
l o s s 1 = 1 N ∑ i = 1 N e − w i n D i s t i loss1 = \frac{1}{N}\sum_{i=1}^{N} e^{-\sqrt{winDist_i}} loss1=N1i=1∑Ne−winDisti
其中, N N N表示验证数据的数量, w i n D i s t i winDist_i winDisti表示第 i i i个验证数据的最近邻神经元的距离。
loss2计算公式:
l o s s 2 = 1 N ∑ i = 1 N w i n D i s t i loss2 = \frac{1}{N}\sum_{i=1}^{N} \sqrt{winDist_i} loss2=N1i=1∑NwinDisti
其中, N N N表示验证数据的数量, w i n D i s t i winDist_i winDisti表示第 i i i个验证数据的最近邻神经元的距离。
d i f f L o s s = l o s s 1 − l o s s 2 diffLoss = loss1 - loss2 diffLoss=loss1−loss2
- loss1中,测试集中数据应到最近邻神经元的欧式距离小,模型越好,欧式距离越小,负指数距离越大,平均负指数距离也越大,所以loss1越大越好;
- loss2中,同理,测试集中数据应到最近邻神经元的欧氏距离越小,模型越好,欧式距离越小,平均欧式距离也越小,所以loss2越小越好;
- 由于 d i f f L o s s = l o s s 1 − l o s s 2 diffLoss = loss1 - loss2 diffLoss=loss1−loss2,所以 d i f f l o s s diffloss diffloss越大越好
五、bagging+集成学习+投票
1.权重的分配
当输入增量样本集 D i D_i Di 时, 我们使用 λ m \lambda_m λm 来更新每个 RVM 的权重:
P m = ∑ i = 1 T I ( f m ( x i ∗ ) = t i ∗ ) / T λ m = P m / ∑ m = 1 M P m \begin{aligned} & P_m=\sum_{i=1}^T I\left(f_m\left(x_i^*\right)=t_i^*\right) / T \\ & \lambda_m=P_m / \sum_{m=1}^M P_m \end{aligned} Pm=i=1∑TI(fm(xi∗)=ti∗)/Tλm=Pm/m=1∑MPm
- P m P_m Pm 表示第 m m m 个 RVM 的准确率,也就是在样本集 D i D_i Di 上的正确率
- I ( ⋅ ) I(\cdot) I(⋅) 是指示函数,当 f m ( x i ∗ ) = t i ∗ f_m(x_i^*)=t_i^* fm(xi∗)=ti∗ 时取值为 1 1 1,否则取值为 0 0 0,只是函数的意思是预测准了就是1,不准就是0
- T T T 表示样本集 D i D_i Di 的大小
- λ m \lambda_m λm 表示第 m m m 个 RVM 的权重,它是第 m m m 个 RVM 准确率 P m P_m Pm 与所有 RVM 准确率之和的比值
思路:先每个基学习器算一遍 P m P_m Pm,然后每个基学习器再算一遍 λ m \lambda_m λm,通过投票法(或者说综合所有学习器性能来判断)来确定每个 RVM 的权重,使得准确率高的 RVM 在集成模型中占据更大的权重,从而提高集成模型的准确率。
2.动态重构的过程
为了对新的输入样本集 D i D_i Di 获得更好的分类性能, 结合 RVM 的概率输出特性, 我们提出了评价基分类器好坏的一个性能指标总体错分概率权重值 u m u_m um 。定义为:
u m = ∑ i = 1 T ( 1 − p m ( f m ( x i ∗ ) = t i ∗ ∣ x i ∗ ) ) λ m r = arg max m ( u m ) \begin{aligned} & u_m=\sum_{i=1}^T\left(1-p_m\left(f_m\left(x_i^*\right)=t_i^* \mid x_i^*\right)\right) \lambda_m \\ & r=\underset{m}{\arg \max }\left(u_m\right) \end{aligned} um=i=1∑T(1−pm(fm(xi∗)=ti∗∣xi∗))λmr=margmax(um)
这个公式是用来评价集成模型中每个基分类器的分类性能的。其中, u m u_m um 是错分概率权重和,表示每个基分类器 RVM 对于新的增量集的分类错误概率的加权和。
- p m ( f m ( x i ∗ ) = t i ∗ ∣ x i ∗ ) p_m(f_m(x_i^*)=t_i^*|x_i^*) pm(fm(xi∗)=ti∗∣xi∗) 表示基分类器 RVM 对于样本 x i ∗ x_i^* xi∗ 的分类正确的概率, t i ∗ t_i^* ti∗ 是样本 x i ∗ x_i^* xi∗ 的真实标签,原来公式中用1减去 p m p_m pm,说明公式中需要的是分类错误的概率(这个公式可能有错误,1-应该放在前面?)
- λ m \lambda_m λm 是基分类器 RVM 在集成模型中的权重(见 1.权重的分配)
- r r r 是总体错分概率权重值最大的 RVM 的索引
思路:在动态增量更新阶段,寻找和删除性能最差的 RVM基学习器,同时在增量集上训练一个新的RVM。
3.集成决策输出
由:
F ( x ∗ ) = arg max j ( ∑ m = 1 M λ m I ( f m ( x ∗ ) = j ) ) F\left(x^*\right)=\underset{j}{\arg \max }\left(\sum_{m=1}^M \lambda_m I\left(f_m\left(x^*\right)=j\right)\right) F(x∗)=jargmax(m=1∑MλmI(fm(x∗)=j))
变为:
F ( x ∗ ) = arg max j ( ∑ m = 1 M λ m p m ( f m ( x ∗ ) = j ∣ x ∗ ) ) F\left(x^*\right)=\underset{j}{\arg \max }\left(\sum_{m=1}^M \lambda_m p_m\left(f_m\left(x^*\right)=j \mid x^*\right)\right) F(x∗)=jargmax(m=1∑Mλmpm(fm(x∗)=j∣x∗))
思路:由用权重修正预测结果并求和取综合,变为权重加上正预测概率同时决定输出标签
问题:
- 这个应用过程应该是一段一段的,而不是连续的,猜测:预训练之后进行应用,第一次增量正常>预测,第二次增量来的时候已经知道了第一次增量的标签结果,结合标签结果进行模型更新
- 这个公式 p m ( f m ( x i ∗ ) = t i ∗ ∣ x i ∗ ) p_m(f_m(x_i^*)=t_i^*|x_i^*) pm(fm(xi∗)=ti∗∣xi∗),计算方法比较奇怪,正样本理论上来说是未知的,如果如同1中所说就没问题
- 集成决策输出的部分也有类似的问题
- RVM是相关向量机,用作分类训练的时候必须要有2个及2个以上的标签,我们的训练数据都是正常数据只有1个标签,RVM换成GNG也无法决定标签的种类总数 j j j
- 这个在输入时进行了降维,一般PCA将高维降维成2维度,但是新的数据流肯定是高维度,只有变为完整连续的数据集才能进行降维,侧面说明了数据是一段一段来的
- 鲸鱼算法是优化超参的,这部分主要是提升指标凑篇幅
六、GNG降维可视化
链接: Scaling the Growing Neural Gas for Visual Cluster Analysis
- t-SNE降维+避免重叠边缘 结果


- 添加边时的策略,当a点和b点还没建立连接时需要满足:
- a点和b点只有在它们有至少一个共同的邻居时才能连接。这样可以避免将远距离的节点连接起来,从而保留数据的局部结构。
- a点和b点都分别与其它节点没有2条以上的边,避免了高维数据在低维空间中出现重叠的情况。
- 如果存在两条边,则这两条边之间不能有连接。这样可以避免在低维空间中出现重叠的边缘。
- 如果只有一条边,则连接两个节点的另一个节点最多只能与边有一个共同邻居,避免在低维空间中出现过于复杂的结构。
- 次近邻获胜的节点必须属于一个小簇,这样可以保持数据的局部结构。
七、GWR
链接: A self-organising network that grows when required
初始化:
- 初始化节点集合 A = { n 1 , n 2 } A=\left\{n_1, n_2\right\} A={n1,n2},其中 n 1 , n 2 n_1, n_2 n1,n2 从输入分布 p ( ξ ) p(\xi) p(ξ) 中随机初始化。
- 初始化连接集合 C = ∅ C=\emptyset C=∅。
迭代过程(随数据流输入更新网络):
-
生成数据样本 ξ \boldsymbol{\xi} ξ 作为网络的输入。
-
对于网络中的每个节点 i i i,计算输入与节点权重向量的距离 ∣ ξ − w i ∣ |\boldsymbol{\xi}-\mathbf{w}_i| ∣ξ−wi∣。
-
选择最匹配的节点和次匹配的节点,即节点 s , t ∈ A s, t \in A s,t∈A,其中 w n \mathbf{w}_n wn是节点 n n n的权重向量。
s = arg min n ∈ A ∣ ξ − w n ∣ s=\arg \min _{n \in A}\left|\boldsymbol{\xi}-\mathbf{w}_n\right| s=argn∈Amin∣ξ−wn∣
t = arg min n ∈ A ∖ { s } ∣ ξ − w n ∣ t=\arg \min _{n \in A \setminus \{s\}}\left|\boldsymbol{\xi}-\mathbf{w}_n\right| t=argn∈A∖{s}min∣ξ−wn∣ -
如果 s s s 和 t t t 之间没有连接,则创建连接,否则,将连接的年龄设置为 0。
C = C ∪ { ( s , t ) } C=C \cup\{(s, t)\} C=C∪{(s,t)} -
计算最匹配单元的活跃度(即e指数计算阈值)
a = exp ( − ∣ ξ − w s ∣ ) a=\exp \left(-|\boldsymbol{\xi}-\mathbf{w}_s|\right) a=exp(−∣ξ−ws∣) -
如果 a < a< a<阈值 a T a_{\mathrm{T}} aT并且触发次数 h T h_{\mathrm{T}} hT < < <触发阈值 h T h_{\mathrm{T}} hT,则应在两个最匹配的节点 s s s和 t t t之间添加一个新节点 r r r:
- 添加新节点 r r r,创建新的权重向量,将权重设置为最匹配节点和输入向量的平均值: w r = ( w s + ξ ) / 2 \mathbf{w}_r=\left(\mathbf{w}_s+\xi\right) / 2 wr=(ws+ξ)/2。
- 在 r r r和 s s s之间以及 r r r和 t t t之间插入边: C = C ∪ ( r , s ) , ( r , t ) C=C \cup{(r, s),(r, t)} C=C∪(r,s),(r,t)。
- 删除 s s s和 t t t之间的连接。
- 如果未添加新节点,则调整获胜节点及其邻居的位置 i i i,即连接到它的节点:
Δ w s = ϵ b × h s × ( ξ − w s ) Δ w i = ϵ n × h i × ( ξ − w i ) , \begin{aligned} \Delta \mathbf{w}_s &= \epsilon_b \times h_s \times (\xi-\mathbf{w}_s) \\ \Delta \mathbf{w}_i &= \epsilon_n \times h_i \times (\xi-\mathbf{w}_i), \end{aligned} ΔwsΔwi=ϵb×hs×(ξ−ws)=ϵn×hi×(ξ−wi),
其中 0 < ϵ n < ϵ b < 1 0 < \epsilon_n < \epsilon_b < 1 0<ϵn<ϵb<1, h s h_s hs 是节点 s s s 触发次数。 - 更新以 s s s 为终点的边的年龄
age ( s , i ) = age ( s , i ) + 1 \operatorname{age}(s, i) = \operatorname{age}(s, i) + 1 age(s,i)=age(s,i)+1 - 根据以下公式减少获胜节点 s s s 的 触发次数以及其邻居节点 i i i 的 触发次数:
h s ( t ) = h 0 − S ( t ) α b ( 1 − e − ω 3 t / x b ) h i ( t ) = h 0 − S ( t ) α n ( 1 − e − α n τ n ) , \begin{aligned} h_s(t) &= h_0 - \frac{S(t)}{\alpha_b} \left(1-\mathrm{e}^{-\omega_3 t / x_b}\right) \\ h_i(t) &= h_0 - \frac{S(t)}{\alpha_n} \left(1-\mathrm{e}^{-\alpha_n \tau_n}\right), \end{aligned} hs(t)hi(t)=h0−αbS(t)(1−e−ω3t/xb)=h0−αnS(t)(1−e−αnτn),
其中 h i ( t ) h_i(t) hi(t) 是节点 i i i 的触发变量的大小, h 0 h_0 h0 是初始, S ( t ) S(t) S(t) 是强度,通常为1。 α n , α b \alpha_n, \alpha_b αn,αb 和 τ n , τ b \tau_n, \tau_b τn,τb 是控制曲线行为的常数。 - 检查是否有要删除的节点或边,即是否有不再具有邻居的节点或年龄大于最大允许年龄的边,如果是,则删除它们(达到最大年龄、孤立点)。
- 如果还有更多的输入可用,则返回到步骤(1)----数据流输入
这篇关于GNG论文+实验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
