本文主要是介绍部署单点elasticsearch7.17.6;,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Elasticsearch单点部署
1、设置主机名以及创建elasticsearch的目录
[root@localhost ~]# cat >> /etc/hosts << EOF
192.168.1.1 elk01
EOF
[root@localhost ~]# hostnamectl set-hostname elk01
[root@localhost ~]# bash创建存放elasticsearch数据和日志的目录
[root@elk01 ~]# mkdir -pv /hqtbj/hqtwww/data/{elasticsearch,logs}
mkdir: created directory ‘/hqtbj’
mkdir: created directory ‘/hqtbj/hqtwww’
mkdir: created directory ‘/hqtbj/hqtwww/data’
mkdir: created directory ‘/hqtbj/hqtwww/data/elasticsearch’
mkdir: created directory ‘/hqtbj/hqtwww/data/logs’
2、下载elasticsearch-7.17.6并解压到指定目录
[root@elk01 ~]# wget -cP /hqtbj/hqtwww/ https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.6-linux-x86_64.tar.gz
[root@elk01 ~]# cd /hqtbj/hqtwww/
[root@elk01 hqtwww]# tar -zxf elasticsearch-7.17.6-linux-x86_64.tar.gz
[root@elk01 hqtwww]# mv elasticsearch-7.17.6 elasticsearch_workspace
3、部署Oracle JDK环境
这里我们不使用elasticsearch自带的OpenJDK,我们手动部署Oracle JDK
软件包下载地址(需要使用oracle账号登录下载):
https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html
先将elasticsearch自带的jdk备份(~/elasticsearch/jdk)
[root@elk01 ~]# mv /hqtbj/hqtwww/elasticsearch_workspace/jdk /hqtbj/hqtwww/elasticsearch_workspace/jdk.default解压oracle jdk到elasticsearch目录下并命名为jdk
[root@elk01 ~]# tar -zxf jdk-8u211-linux-x64.tar.gz
[root@elk01 ~]# mv jdk1.8.0_211 /hqtbj/hqtwww/elasticsearch_workspace/jdk---`这里解释下为什么要把oracle jdk放到elasticsearch目录下:因为后面会去
用systemd来管理elasticsearch,但是用systemd不会去用全局的系统变量,
就会依着elasticsearch去使用自带的OpenJDK,所以这一步相当于是直接把elasticsearch自带的环境变量替换成了Oracle JDK`---配置jdk环境变量
[root@elk01 ~]# cat >> /etc/profile.d/elasticsearch.sh << EOF
JAVA_HOME=/hqtbj/hqtwww/elasticsearch_workspace/jdk
PATH=/hqtbj/hqtwww/elasticsearch_workspace/jdk/bin:/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
export JAVA_HOME PATH
EOF
[root@elk01 ~]# source /etc/profile.d/elasticsearch.sh
[root@elk01 ~]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
4、修改elasticsearch的配置文件
elasticsearch的主配置文件是~/config/elasticsearch.yml
备份初始配置文件
[root@elk01 ~]# cp /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml.default
[root@elk01 ~]# vim /hqtbj/hqtwww/elasticsearch_workspace/config/elasticsearch.yml
cluster.name: HQT-ELK-PROD #集群名称
node.name: elk01 #节点名称
path.data: /hqtbj/hqtwww/data/elasticsearch #存放数据的目录
path.logs: /hqtbj/hqtwww/data/logs #存放日志的目录
network.host: 192.168.1.1 #ES服务监听的IP地址(默认只能本地127.0.0.1访问;)如果主机有多个网卡的的话可以在这里设置监听的IP地址,0.0.0.0代表监听本机上的所有IP地址;
discovery.seed_hosts: ["elk01"] #服务发现的主机列表,用于发现集群内其它的节点;
cluster.initial_master_nodes: ["elk01"] #首次启动全新的Elasticsearch集群时,会出现一个集群引导步骤,该步骤确定了在第一次选举中便对其票数进行计数的有资格成为集群中主节点的节点的集合(投票的目的是选出集群的主节点)。在开发模式中,集群引导步骤由节点们自动引导,但在生产环境中这种自动引导的方式不安全,cluster.initial_master_nodes参数提供一个列表,列表中是全新集群启动时,有资格成为集群主节点的节点(这些节点要被投票决定谁成为集群主节点),它在集群重启或添加新节点到集群时时不起作用的;
参数说明:
–cluster.name:集群名称,同一集群内的节点集群名称需要统一;
–node.name:当前节点名称;
–path.data:存放elasticsearch数据的目录;
–path.logs:存放elasticsearch日志的目录;
–network.host:ES服务监听的IP地址(默认只能本地127.0.0.1访问;)如果主机有多个网卡的的话可以在这里设置监听的IP地址,0.0.0.0代表监听本机上的所有IP地址;
–discovery.seed_hosts:服务发现的主机列表,用于发现集群内其它的节点;
–cluster.initial_master_nodes:#如首次启动全新的Elasticsearch集群时,会出现一个集群引导步骤,该步骤确定了在第一次选举中便对其票数进行计数的有资格成为集群中主节点的节点的集合(投票的目的是选出集群的主节点)。在开发模式中,集群引导步骤由节点们自动引导,但在生产环境中这种自动引导的方式不安全,cluster.initial_master_nodes参数提供一个列表,列表中是全新集群启动时,有资格成为集群主节点的节点(这些节点要被投票决定谁成为集群主节点),它在集群重启或添加新节点到集群时是不起作用的;
5、创建ES用户(用于运行ES服务)并设置内核参数
创建es用户并授权
[root@elk01 ~]# useradd es
[root@elk01 ~]# chown -R es:es /hqtbj/hqtwww/elasticsearch_workspace/
[root@elk01 ~]# chown -R es:es /hqtbj/hqtwww/data/修改打开文件的数量
[root@elk01 ~]# cat > /etc/security/limits.d/elk.conf <<'EOF'
* soft nofile 65535
* hard nofile 131070
EOF修改内核参数的内存映射信息
[root@elk01 ~]# cat > /etc/sysctl.d/elk.conf <<'EOF'
vm.max_map_count = 262144
EOF
[root@elk01 ~]# sysctl -p /etc/sysctl.d/elk.conf
vm.max_map_count = 262144
6、编写ES启动脚本 并启动
[root@elk01 ~]# cat > /usr/lib/systemd/system/elasticsearch.service << EOF
[Unit]
Description=elasticsearch-v7.17.6
After=network.target[Service]
Restart=on-failure
ExecStart=/hqtbj/hqtwww/elasticsearch_workspace/bin/elasticsearch
User=es
Group=es
LimitNOFILE=65535[Install]
WantedBy=multi-user.target
EOF
[root@elk01 ~]# systemctl daemon-reload
[root@elk01 ~]# systemctl start elasticsearch
[root@elk01 ~]# systemctl enable elasticsearch
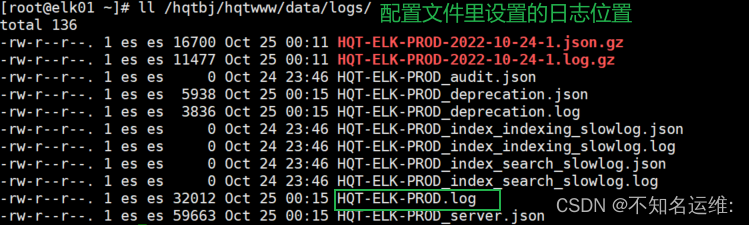
大家在启动的过程中也可以tail看下elasticsearch系统日志,输出的都是一些启动的详细信息;
日志的格式是我们配置文件中设置的 <cluster.name>(集群名称)+XXXX
7、修改ES的堆(heap)内存大小
elasticsearch的jvm配置文件是~/config/jvm.options
先查看此时的堆内存大小
[root@elk01 ~]# jmap -heap `jps | grep Elasticsearch | awk '{print $1}'`
...
MaxHeapSize = 536870912 (512.0MB)
备份并修改
[root@elk01 ~]# cp /hqtbj/hqtwww/elasticsearch_workspace/config/jvm.options /hqtbj/hqtwww/elasticsearch_workspace/config/jvm.options.default
[root@elk01 ~]# vim /hqtbj/hqtwww/elasticsearch_workspace/config/jvm.options
...
-Xms1g
-Xmx1g重启elasticsearch服务
[root@elk01 ~]# systemctl restart elasticsearch验证堆内存大小
[root@elk01 config]# jmap -heap `jps | grep Elasticsearch | awk '{print $1}'`
...
MaxHeapSize = 1073741824 (1024.0MB)
官方建议设置es内存,大小为物理内存的一半,剩下的一半留给luence,这是因为es的底层是luence(java语言研发的搜索引擎框架),luence本身就是单独占用内存的,而且占用的还不少
请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/advanced-configuration.html#jvm-options-syntax
8、验证
启动成功后访问elasticsearch接口输出以下就部署成功了
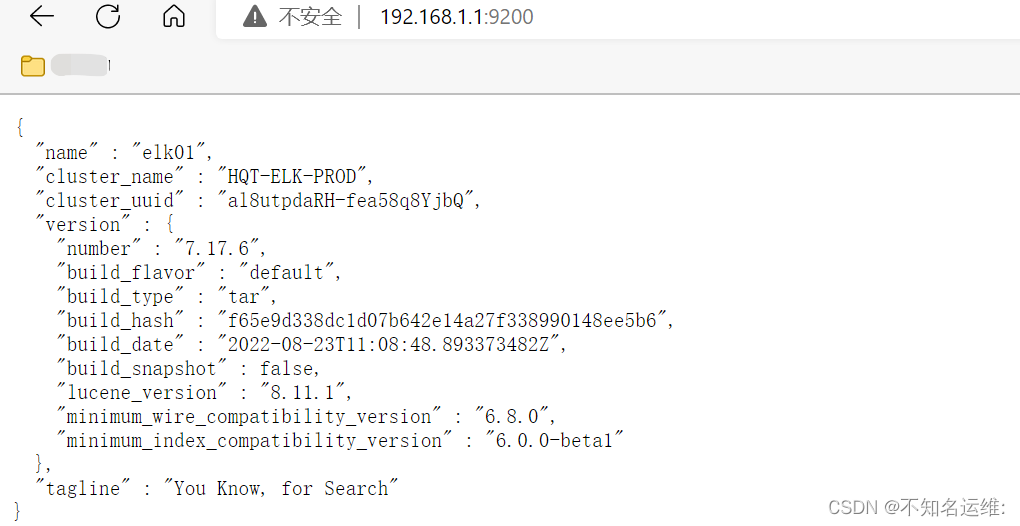
[root@elk01 ~]# curl 192.168.1.1:9200 #查看当前节点信息所在集群信息
{"name" : "elk01", 当前节点名称"cluster_name" : "HQT-ELK-PROD", 集群名称"cluster_uuid" : "al8utpdaRH-fea58q8YjbQ", 集群uuid,一个集群唯一的"version" : { //-下面都是版本信息"number" : "7.17.6","build_flavor" : "default","build_type" : "tar","build_hash" : "f65e9d338dc1d07b642e14a27f338990148ee5b6","build_date" : "2022-08-23T11:08:48.893373482Z","build_snapshot" : false,"lucene_version" : "8.11.1","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"
}
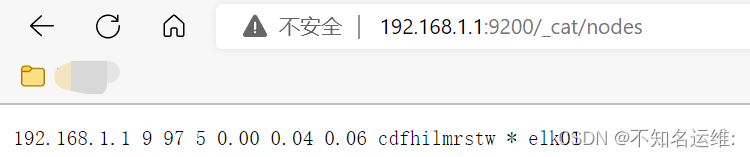
[root@elk01 ~]# curl 192.168.1.1:9200/_cat/nodes 查看集群中所有节点信息
192.168.1.1 30 96 1 0.05 0.59 0.98 cdfhilmrstw * elk01 #带*的是master节点;
同样在浏览器也是可以的
这篇关于部署单点elasticsearch7.17.6;的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






