本文主要是介绍(三)PySpark3:SparkSQL40题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、前言
二、实践
三、总结
PySpark系列文章:
(一)PySpark3:安装教程及RDD编程
(二)PySpark3:SparkSQL编程
(三)PySpark3:SparkSQL40题
一、前言
本文主要根据我写的另一篇文章:SQL笔试经典40题,使用PySpark SQL代码实现。
import numpy as np
import findspark
import pyspark
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.window import Window
import pandas as pd
from pyspark.sql.types import *
findspark.init()spark = SparkSession.builder \.appName("test") \.config("master","local[4]") \.enableHiveSupport() \.getOrCreate()
sc = spark.sparkContextStudentData = [('01' , '赵雷' , '1990-01-01' , '男'),
('02' , '钱电' , '1990-12-21' , '男'),
('03' , '孙风' , '1990-05-20' , '男'),
('04' , '李云' , '1990-08-06' , '男'),
('05' , '周梅' , '1991-12-01' , '女'),
('06' , '吴兰' , '1992-03-01' , '女'),
('07' , '郑竹' , '1989-07-01' , '女'),
('08' , '王菊' , '1990-01-20' , '女')]CourseData = [('01' , '语文' , '02'),
('02' , '数学' , '01'),
('03' , '英语' , '03'),
('04' , '物理' , '01')]TeacherData = [('01' , '张三'),
('02' , '李四'),
('03' , '王五')]SCData = [('01' , '01' , 80),
('01' , '02' , 90),
('01' , '03' , 99),
('02' , '01' , 70),
('02' , '02' , 60),
('02' , '03' , 80),
('03' , '01' , 80),
('03' , '02' , 80),
('03' , '03' , 80),
('04' , '01' , 50),
('04' , '02' , 30),
('04' , '03' , 20),
('05' , '01' , 76),
('05' , '02' , 87),
('06' , '01' , 31),
('06' , '03' , 34),
('07' , '02' , 89),
('07' , '03' , 98),
('04' , '04' , 90)]df_student = spark.createDataFrame(StudentData,["sid","sname","sage","ssex"])
df_course = spark.createDataFrame(CourseData,["cid","cname","tid"])
df_teacher = spark.createDataFrame(TeacherData,["tid","tname"])
df_sc = spark.createDataFrame(SCData,["sid","cid","score"])二、实践
1、查询“01”课程比“02”课程成绩高的所有学生的学号
如果使用注册临时表视图的方式,那么直接通过spark.sql接受SQL语句进行查询就行了。
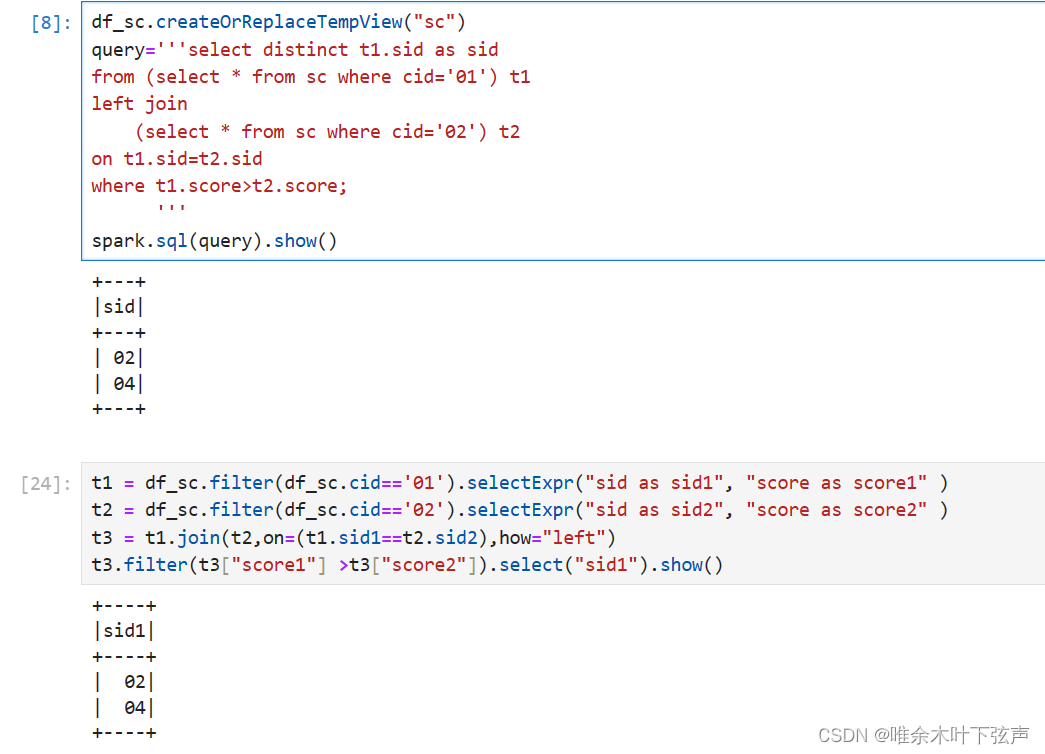
df_sc.createOrReplaceTempView("sc")
query='''select distinct t1.sid as sid
from (select * from sc where cid='01') t1
left join (select * from sc where cid='02') t2
on t1.sid=t2.sid
where t1.score>t2.score;'''
spark.sql(query).show()通过DataFrame API:
t1 = df_sc.filter(df_sc.cid=='01').selectExpr("sid as sid1", "score as score1" )
t2 = df_sc.filter(df_sc.cid=='02').selectExpr("sid as sid2", "score as score2" )
t3 = t1.join(t2,on=(t1.sid1==t2.sid2),how="left")
t3.filter(t3["score1"] >t3["score2"]).select("sid1").show()输出结果:
为加强对DataFrame API的掌握,以下题目皆使用DataFrame API进行编程,不再使用spark.sql(SQL语句)的方式。
2、查询平均成绩大于60分的同学的学号和平均成绩;
result = df_sc.groupBy("sid")\.agg(F.mean("score").alias("mean_score"))\.filter(F.col('mean_score')>60)
result.show()输出结果:
+---+-----------------+
|sid| mean_score|
+---+-----------------+
| 01|89.66666666666667|
| 02| 70.0|
| 03| 80.0|
| 05| 81.5|
| 07| 93.5|
+---+-----------------+3、查询所有同学的学号、姓名、选课数、总成绩。
t1 = df_sc.groupBy("sid").agg(F.sum("score").alias("total_score"),F.count("cid").alias("course_cnt"))
result =t1.join(df_student.select('sid','sname'),on='sid',how='inner')
result.show()输出结果:
+---+-----------+----------+-----+
|sid|total_score|course_cnt|sname|
+---+-----------+----------+-----+
| 01| 269| 3| 赵雷|
| 02| 210| 3| 钱电|
| 03| 240| 3| 孙风|
| 04| 190| 4| 李云|
| 05| 163| 2| 周梅|
| 06| 65| 2| 吴兰|
| 07| 187| 2| 郑竹|
+---+-----------+----------+-----+4、查询姓“李”的老师的个数
#type1
df_teacher.filter(F.col('tname').startswith('李')).count()#type2
df_teacher.where("tname like'李%'").count()输出结果:
15、查询没学过“张三”老师课的同学的学号、姓名;
t1 = df_course.join(df_teacher.where("tname='张三'"),on='tid',how='inner').select('cid')
t2 = df_sc.join(t1,on='cid',how='inner').select('sid')
t3 = df_student.select('sid').exceptAll(t2)
result = t3.join(df_student.select('sid','sname'),on='sid',how='inner').distinct()
result.show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 06| 吴兰|
| 08| 王菊|
+---+-----+6、查询学过“01”并且也学过编号“02”课程的同学的学号、姓名;
t1 = df_sc.filter(df_sc.cid == '01').select(F.col('sid').alias('sid01'))
t2 = df_sc.filter(df_sc.cid == '02').select(F.col('sid').alias('sid02'))
t3 = t1.join(t2, t1.sid01==t2.sid02, 'inner').select('sid01')
result = df_student.join(t3, df_student.sid == t3.sid01, 'inner').select('sid01', 'sname')
result.show()输出结果:
+-----+-----+
|sid01|sname|
+-----+-----+
| 01| 赵雷|
| 02| 钱电|
| 03| 孙风|
| 04| 李云|
| 05| 周梅|
+-----+-----+7、查询学过“张三”老师所教的课的同学的学号、姓名
t1 = df_course.join(df_teacher.where("tname='张三'"),on='tid',how='inner').select('cid')
t2 = df_sc.join(t1,on='cid',how='inner').select('sid')
result = t2.join(df_student.select('sid','sname'),on='sid',how='inner').distinct()
result.show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 01| 赵雷|
| 02| 钱电|
| 03| 孙风|
| 04| 李云|
| 05| 周梅|
| 07| 郑竹|
+---+-----+8、查询课程编号“01”的成绩比课程编号“02”课程低的所有同学的学号、姓名
t1 = df_sc.filter(df_sc.cid == '01').selectExpr("sid as sid01","score as score01")
t2 = df_sc.filter(df_sc.cid == '02').selectExpr("sid as sid02","score as score02")
t3 = t1.join(t2, t1.sid01==t2.sid02, 'inner').filter(F.col("score01")<F.col("score02")).select('sid01')
result = t3.join(df_student.select('sid','sname'),t3.sid01==df_student.sid,how='inner').distinct()
result.select('sid','sname').show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 01| 赵雷|
| 05| 周梅|
+---+-----+9、查询所有课程成绩小于60分的同学的学号、姓名。
t1 = df_sc.filter(df_sc.score>=60).select('sid')
t2 = df_student.select('sid').exceptAll(t1)
t2_sid_set = set(t2.rdd.map(lambda row: row.sid).collect())
df_student.filter(df_student.sid.isin(t2_sid_set)).select('sid', 'sname').show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 06| 吴兰|
| 08| 王菊|
+---+-----+10、查询没有学全所有课的同学的学号、姓名。
counts = df_course.select("cid").distinct().count()
df_course_cnt = df_sc.groupBy("sid").agg(F.count("cid").alias("course_cnt"))
result = df_course_cnt.filter(F.col("course_cnt")<counts).join(df_student,on='sid',how='inner').select("sid","sname")
result.show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 01| 赵雷|
| 02| 钱电|
| 03| 孙风|
| 05| 周梅|
| 06| 吴兰|
| 07| 郑竹|
+---+-----+11、查询至少有一门课与学号为“01”的同学所学相同的同学的学号和姓名。
courses_of_01 = df_sc.filter(F.col("sid") == "01").select("cid").rdd.map(lambda x:x.cid).collect()
t1 = df_sc.filter((df_sc.cid.isin(courses_of_01))&(df_sc.sid!='01')).select('sid').distinct()
result = t1.join(df_student,on='sid',how='inner').select("sid","sname")
result.show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 02| 钱电|
| 03| 孙风|
| 04| 李云|
| 05| 周梅|
| 06| 吴兰|
| 07| 郑竹|
+---+-----+12、查询和"01"号的同学学习的课程完全相同的其他同学的学号和姓名。
courses_of_01 = df_sc.filter(F.col("sid") == "01").select("cid").rdd.map(lambda x:x.cid).collect()
t1 = df_sc.filter((df_sc.cid.isin(courses_of_01))&(df_sc.sid!='01')).select('sid', 'cid')
t2 = t1.groupby('sid').agg(F.count("cid").alias("course_cnt")).filter(F.col("course_cnt")==len(courses_of_01))
t3 = df_sc.groupby('sid').agg(F.count("cid").alias("course_cnt")).filter(F.col("course_cnt")==len(courses_of_01))
result = t2.select("sid").intersect(t3.select("sid")).join(df_student,on='sid',how='inner').select("sid","sname")
result.show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 02| 钱电|
| 03| 孙风|
+---+-----+13、把“SC”表中“张三”老师教的课的成绩都更改为此课程的平均成绩。
tid_of_zhangsan = df_teacher.filter(F.col("tname")=='张三').select("tid").first().asDict().get("tid")
t1 = df_course.filter(F.col("tid")==tid_of_zhangsan)
t2 = t1.join(df_sc,on='cid',how='inner').groupby('cid').agg(F.mean('score').alias("score_avg"))
result = df_sc.join(t2,on='cid',how='left').selectExpr("cid","sid","nvl(score_avg,score) as score")
result.show()输出结果:
+---+---+-----------------+
|cid|sid| score|
+---+---+-----------------+
| 01| 01| 80.0|
| 02| 01|72.66666666666667|
| 03| 01| 99.0|
| 01| 02| 70.0|
| 02| 02|72.66666666666667|
| 01| 03| 80.0|
| 03| 02| 80.0|
| 02| 03|72.66666666666667|
| 03| 03| 80.0|
| 01| 04| 50.0|
| 02| 04|72.66666666666667|
| 01| 05| 76.0|
| 03| 04| 20.0|
| 02| 05|72.66666666666667|
| 01| 06| 31.0|
| 03| 06| 34.0|
| 02| 07|72.66666666666667|
| 03| 07| 98.0|
| 04| 04| 90.0|
+---+---+-----------------+14、查询没学过"张三"老师讲授的任一门课程的学生姓名
t1 = df_course.join(df_teacher.where("tname='张三'"),on='tid',how='inner').select('cid')
t2 = df_sc.join(t1,on='cid',how='inner').select('sid')
result = df_student.select('sid').exceptAll(t2).join(df_student,on='sid',how='inner').select("sid","sname")
result.show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 06| 吴兰|
| 08| 王菊|
+---+-----+15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩。
t1 = df_sc.filter(F.col("score") < 60).groupby("sid")\.agg(F.count("cid").alias("counts"),F.mean("score").alias("score_avg"))
result = t1.filter(F.col("counts") >1)\.join(df_student,on='sid',how='inner')\.select("sid","sname","score_avg")
result.show()输出结果:
+---+-----+------------------+
|sid|sname| score_avg|
+---+-----+------------------+
| 04| 李云|33.333333333333336|
| 06| 吴兰| 32.5|
+---+-----+------------------+16、检索"01"课程分数小于60,按分数降序排列的学生信息。
t1 = df_sc.where("score<60 and cid='01'")\.join(df_student,on='sid',how='inner')\.select("sid","sname","score")
result = t1.orderBy(F.col("score").desc())
result.show()输出结果:
+---+-----+-----+
|sid|sname|score|
+---+-----+-----+
| 04| 李云| 50|
| 06| 吴兰| 31|
+---+-----+-----+17、按平均成绩从高到低显示所有学生的平均成绩
t1 = df_sc.groupby("sid").agg(F.mean("score").alias("score_avg"))
result = t1.select("sid","score_avg").orderBy(F.col("score_avg").desc())
result.show()输出结果:
+---+-----------------+
|sid| score_avg|
+---+-----------------+
| 07| 93.5|
| 01|89.66666666666667|
| 05| 81.5|
| 03| 80.0|
| 02| 70.0|
| 04| 47.5|
| 06| 32.5|
+---+-----------------+18、查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率。
t1 = df_sc.groupby("cid").agg(F.max("score").alias("score_max"),F.min("score").alias("score_min"),F.mean("score").alias("score_avg"),(F.sum(F.when(F.col("score") >= 60, 1).otherwise(0))/F.count("*")).alias("pass_ratio"))
result = t1.join(df_course,on='cid',how='left').select("cid","cname","score_max","score_min","score_avg","pass_ratio")
result.show()输出结果:
+---+-----+---------+---------+-----------------+------------------+
|cid|cname|score_max|score_min| score_avg| pass_ratio|
+---+-----+---------+---------+-----------------+------------------+
| 01| 语文| 80| 31| 64.5|0.6666666666666666|
| 02| 数学| 90| 30|72.66666666666667|0.8333333333333334|
| 03| 英语| 99| 20| 68.5|0.6666666666666666|
| 04| 物理| 90| 90| 90.0| 1.0|
+---+-----+---------+---------+-----------------+------------------+19、按各科课程ID和成绩从高到低顺序排列。
result = df_sc.orderBy(F.asc("cid"), F.desc("score"))
result.show()输出结果:
+---+-----+
|cid|score|
+---+-----+
| 01| 80|
| 01| 80|
| 01| 76|
| 01| 70|
| 01| 50|
| 01| 31|
| 02| 90|
| 02| 89|
| 02| 87|
| 02| 80|
| 02| 60|
| 02| 30|
| 03| 99|
| 03| 98|
| 03| 80|
| 03| 80|
| 03| 34|
| 03| 20|
| 04| 90|
+---+-----+
20、查询学生的总成绩并进行排名
t1 = df_sc.groupby("sid").agg(F.sum("score").alias("score_sum"))
w = Window.orderBy(F.col("score_sum").desc())
result = t1.withColumn("rank", F.row_number().over(w))
result.show()输出结果:
+---+---------+----+
|sid|score_sum|rank|
+---+---------+----+
| 01| 269| 1|
| 03| 240| 2|
| 02| 210| 3|
| 04| 190| 4|
| 07| 187| 5|
| 05| 163| 6|
| 06| 65| 7|
+---+---------+----+21、查询不同老师所教不同课程平均分从高到低显示
t1 = df_sc.join(df_course,on='cid',how='left')\.join(df_teacher,on='tid',how='left')\.select("tname","cname","score")
t2 = t1.groupby(["tname","cname"]).agg(F.mean("score").alias("score_mean"))
result = t2.orderBy(F.col("score_mean").desc())
result.show()输出结果:
+-----+-----+-----------------+
|tname|cname| score_mean|
+-----+-----+-----------------+
| 张三| 物理| 90.0|
| 张三| 数学|72.66666666666667|
| 王五| 英语| 68.5|
| 李四| 语文| 64.5|
+-----+-----+-----------------+22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
w = Window.partitionBy("cid").orderBy(F.col("score").desc())
t1 = df_sc.withColumn("rank", F.dense_rank().over(w))
result = t1.where("rank=2 or rank=3").join(df_student,on='sid',how='left').select("sid","sname","cid","score","rank")
result.show()输出结果:
+---+-----+---+-----+----+
|sid|sname|cid|score|rank|
+---+-----+---+-----+----+
| 02| 钱电| 01| 70| 3|
| 02| 钱电| 03| 80| 3|
| 03| 孙风| 03| 80| 3|
| 05| 周梅| 01| 76| 2|
| 05| 周梅| 02| 87| 3|
| 07| 郑竹| 02| 89| 2|
| 07| 郑竹| 03| 98| 2|
+---+-----+---+-----+----+23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比。
t1 = df_sc.join(df_course, on='cid',how='inner')
t2 = t1.groupby(["cid","cname"])\.agg(F.sum(F.when(F.col('score') >= 85, 1).otherwise(0)).alias('between85to100'),F.sum(F.when((F.col('score') >= 70) & (F.col('score') < 85), 1).otherwise(0)).alias('between70to85'),F.sum(F.when((F.col('score') >= 60) & (F.col('score') < 70), 1).otherwise(0)).alias('between60to70'),F.sum(F.when(F.col('score') < 60, 1).otherwise(0)).alias('between0to60'),F.count('*').alias('total_students'))
result = t2.withColumn('between85to100_ratio',F.col("between85to100")/F.col("total_students"))\.withColumn('between70to85_ratio',F.col("between70to85")/F.col("total_students"))\.withColumn('between60to70_ratio',F.col("between60to70")/F.col("total_students"))\.withColumn('between0to60_ratio',F.col("between0to60")/F.col("total_students"))
result.show()输出结果:
+---+-----+--------------+-------------+-------------+------------+--------------+--------------------+-------------------+-------------------+-------------------+
|cid|cname|between85to100|between70to85|between60to70|between0to60|total_students|between85to100_ratio|between70to85_ratio|between60to70_ratio| between0to60_ratio|
+---+-----+--------------+-------------+-------------+------------+--------------+--------------------+-------------------+-------------------+-------------------+
| 01| 语文| 0| 4| 0| 2| 6| 0.0| 0.6666666666666666| 0.0| 0.3333333333333333|
| 02| 数学| 3| 1| 1| 1| 6| 0.5|0.16666666666666666|0.16666666666666666|0.16666666666666666|
| 03| 英语| 2| 2| 0| 2| 6| 0.3333333333333333| 0.3333333333333333| 0.0| 0.3333333333333333|
| 04| 物理| 1| 0| 0| 0| 1| 1.0| 0.0| 0.0| 0.0|
+---+-----+--------------+-------------+-------------+------------+--------------+--------------------+-------------------+-------------------+-------------------+24、查询学生平均成绩及其名次
t1 = df_sc.groupby("sid").agg(F.mean('score').alias('score_avg'))
w = Window.partitionBy().orderBy(F.col("score_avg").desc())
result = t1.withColumn("rank", F.row_number().over(w))
result.show()输出结果:
+---+-----------------+----+
|sid| score_avg|rank|
+---+-----------------+----+
| 07| 93.5| 1|
| 01|89.66666666666667| 2|
| 05| 81.5| 3|
| 03| 80.0| 4|
| 02| 70.0| 5|
| 04| 47.5| 6|
| 06| 32.5| 7|
+---+-----------------+----+25、查询各科成绩前三名的记录。
w = Window.partitionBy("cid").orderBy(F.col("score").desc())
result = df_sc.withColumn("rank", F.row_number().over(w)).filter(F.col("rank")<=3)
result.show()输出结果:
+---+---+-----+----+
|sid|cid|score|rank|
+---+---+-----+----+
| 01| 01| 80| 1|
| 03| 01| 80| 2|
| 05| 01| 76| 3|
| 01| 02| 90| 1|
| 07| 02| 89| 2|
| 05| 02| 87| 3|
| 01| 03| 99| 1|
| 07| 03| 98| 2|
| 02| 03| 80| 3|
| 04| 04| 90| 1|
+---+---+-----+----+26、查询每门课程被选修的学生数
result = df_sc.groupby("cid").agg(F.count("*").alias("students_cnt"))
result.show()输出结果:
+---+------------+
|cid|students_cnt|
+---+------------+
| 01| 6|
| 02| 6|
| 03| 6|
| 04| 1|
+---+------------+27、查询出只选修了两门课程的全部学生的学号和姓名。
t1 = df_sc.groupby("sid").agg(F.count("*").alias("course_cnt"))
t2 = t1.filter(F.col("course_cnt")==2)
result = t2.join(df_student,on='sid').select("sid","sname")
result.show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 05| 周梅|
| 06| 吴兰|
| 07| 郑竹|
+---+-----+28、查询男生、女生人数。
result = df_student.groupby("ssex").agg(F.count("*").alias("counts"))
result.show()输出结果:
+----+------+
|ssex|counts|
+----+------+
| 男| 4|
| 女| 4|
+----+------+29、查询名字中含有"风"字的学生信息
result = df_student.where("sname like '%风%'")
#或
result = df_student.filter(F.col("sname").contains("风"))
result.show()
输出结果:
+---+-----+----------+----+
|sid|sname| sage|ssex|
+---+-----+----------+----+
| 03| 孙风|1990-05-20| 男|
+---+-----+----------+----+30、查询同一课程分数相同的情况,并统计人数
t1 = df_sc.groupby(["cid","score"]).agg(F.count("*").alias("counts"))
result = t1.where("counts>1")
result.show()输出结果:
+---+-----+------+
|cid|score|counts|
+---+-----+------+
| 01| 80| 2|
| 03| 80| 2|
+---+-----+------+31、查询1990年出生的学生名单。
result = df_student.where("substr(sage,1,4)='1990'")
#或
result = df_student.withColumn("birth_year", F.substring(F.col("sage"), 1, 4)).filter(F.col("birth_year")=='1990')
result.show()32、查询每门课程的平均成绩,结果按平均成绩升序排列。
t1 = df_sc.groupby("cid").agg(F.mean("score").alias("score_avg"))
result = t1.orderBy(F.col("score_avg").asc())
result.show()输出结果:
+---+-----------------+
|cid| score_avg|
+---+-----------------+
| 01| 64.5|
| 03| 68.5|
| 02|72.66666666666667|
| 04| 90.0|
+---+-----------------+33、查询每门不及格的成绩,并按课程号从小到大、分数从高到低的顺序排列。
result = df_sc.where("score<60").orderBy(F.col("cid").asc(),F.col("score").desc())
result.show()输出结果:
+---+---+-----+
|sid|cid|score|
+---+---+-----+
| 04| 01| 50|
| 06| 01| 31|
| 04| 02| 30|
| 06| 03| 34|
| 04| 03| 20|
+---+---+-----+34、查询课程编号为"01"且课程成绩在60分以上的学生的学号和姓名。
t1 = df_sc.where("score>60 and cid='01'")
result = t1.join(df_student,on="sid").select("sid","sname")
result.show()输出结果:
+---+-----+
|sid|sname|
+---+-----+
| 01| 赵雷|
| 02| 钱电|
| 03| 孙风|
| 05| 周梅|
+---+-----+35、查询选修“张三”老师所授课程的学生中,成绩最高的学生姓名及其成绩
t1 = df_teacher.where("tname='张三'").join(df_course,on='tid').join(df_sc,on='cid')
max_score = t1.agg(F.max("score")).collect()[0][0]
result = df_sc.where("score={}".format(max_score)).join(df_student,on="sid").select("sname","score")
result.show()输出结果:
+-----+-----+
|sname|score|
+-----+-----+
| 赵雷| 90|
| 李云| 90|
+-----+-----+36、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列。
t1 = df_sc.groupby("cid").agg(F.count("*").alias("counts")).where("counts>5")
result = t1.orderBy(F.col("counts").desc(),F.col("cid").asc())
result.show()输出结果:
+---+------+
|cid|counts|
+---+------+
| 01| 6|
| 02| 6|
| 03| 6|
+---+------+
37、检索至少选修两门课程的学生学号。
result = df_sc.groupby("sid").agg(F.count("*").alias("counts")).where("counts>=2")
result.show()输出结果:
+---+------+
|sid|counts|
+---+------+
| 01| 3|
| 02| 3|
| 03| 3|
| 04| 4|
| 05| 2|
| 06| 2|
| 07| 2|
+---+------+38、查询各学生的年龄
t1 = df_student.withColumn("birthday", F.to_date(F.col("sage")))
t2 = t1.withColumn("age", F.datediff(F.current_date(), F.col("birthday"))/365)
result = t2.withColumn("age",F.round("age")).select("sid","sname","age")
result.show()输出结果:
+---+-----+----+
|sid|sname| age|
+---+-----+----+
| 01| 赵雷|34.0|
| 02| 钱电|33.0|
| 03| 孙风|34.0|
| 04| 李云|34.0|
| 05| 周梅|32.0|
| 06| 吴兰|32.0|
| 07| 郑竹|35.0|
| 08| 王菊|34.0|
+---+-----+----+39、查询本月过生日的学生。
result = df_student.where('''to_date(sage,'yyyy-mm-dd')>=trunc(current_date(),'mm')and to_date(sage,'yyyy-mm-dd')<trunc(add_months(current_date(),1),'mm')''')
result.show()#或
t1 = df_student.withColumn("birthday", F.to_date(F.col("sage")))
current_month = F.month(F.current_date()).alias("current_month")
birthday_month = F.month(F.col("birthday")).alias("birthday_month")
result = t1.withColumn("current_month", current_month) \.withColumn("birthday_month", birthday_month) \.where(F.col("birthday_month") == F.col("current_month")) \.select("sid","sname","ssex","birthday")
result.show()输出结果:
+---+-----+----+----------+
|sid|sname|ssex| birthday|
+---+-----+----+----------+
| 06| 吴兰| 女|1992-03-01|
+---+-----+----+----------+40、查询年龄最大的学生。
sage_min = df_student.agg(F.min(F.col("sage")).alias("sage_min")).collect()[0][0]
result = df_student.where("sage='{}'".format(sage_min))
result.show()输出结果:
+---+-----+----------+----+
|sid|sname| sage|ssex|
+---+-----+----------+----+
| 07| 郑竹|1989-07-01| 女|
+---+-----+----------+----+三、总结
以上40题主要是对数据的关联、筛选、查询,最常用的DataFrame API是select、filter、where等。由于Spark DataFrame是不可变的分布式数据集,只能通过生成新的DataFrame已达到对其修改的效果。
这篇关于(三)PySpark3:SparkSQL40题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

