本文主要是介绍WorldGPT、Pix2Pix-OnTheFly、StyleDyRF、ManiGaussian、Face SR,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文首发于公众号:机器感知
WorldGPT、Pix2Pix-OnTheFly、StyleDyRF、ManiGaussian、Face SR
HandGCAT: Occlusion-Robust 3D Hand Mesh Reconstruction from Monocular Images
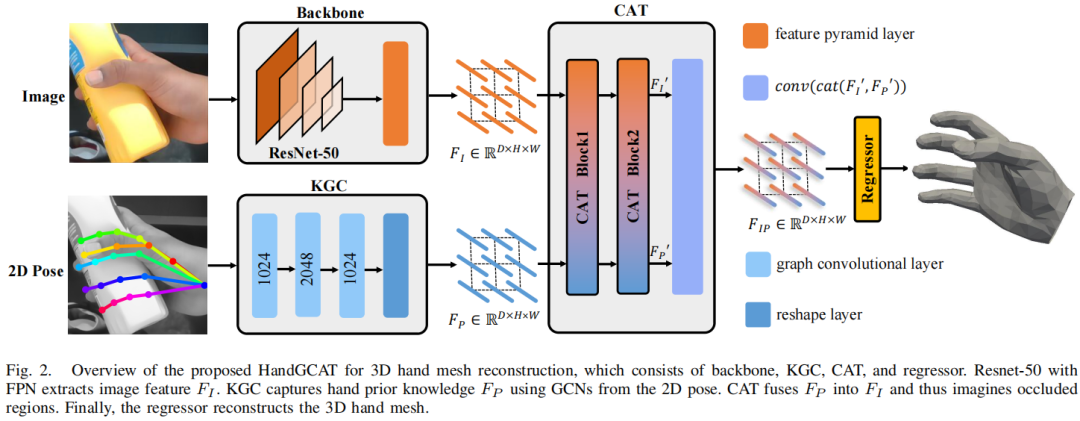
We propose a robust and accurate method for reconstructing 3D hand mesh from monocular images. This is a very challenging problem, as hands are often severely occluded by objects. Previous works often have disregarded 2D hand pose information, which contains hand prior knowledge that is strongly correlated with occluded regions. Thus, in this work, we propose a novel 3D hand mesh reconstruction network HandGCAT, that can fully exploit hand prior as compensation information to enhance occluded region features. Specifically, we designed the Knowledge-Guided Graph Convolution (KGC) module and the Cross-Attention Transformer (CAT) module. KGC extracts hand prior information from 2D hand pose by graph convolution. CAT fuses hand prior into occluded regions by considering their high correlation.
Text-to-Audio Generation Synchronized with Videos
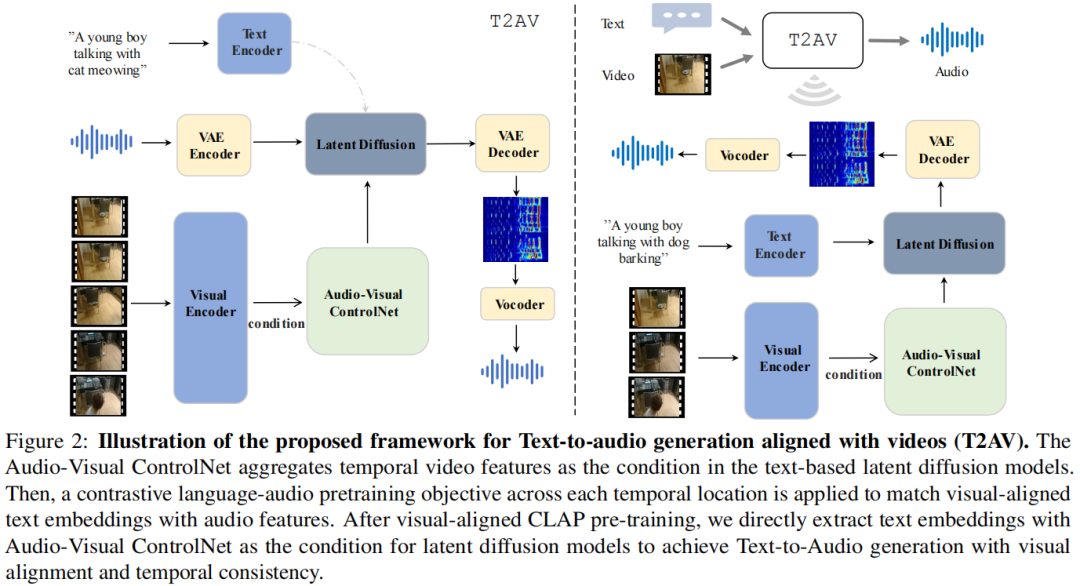
In recent times, the focus on text-to-audio (TTA) generation has intensified, as researchers strive to synthesize audio from textual descriptions. However, most existing methods, though leveraging latent diffusion models to learn the correlation between audio and text embeddings, fall short when it comes to maintaining a seamless synchronization between the produced audio and its video. This often results in discernible audio-visual mismatches. To bridge this gap, we introduce a groundbreaking benchmark for Text-to-Audio generation that aligns with Videos, named T2AV-Bench. This benchmark distinguishes itself with three novel metrics dedicated to evaluating visual alignment and temporal consistency.
WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
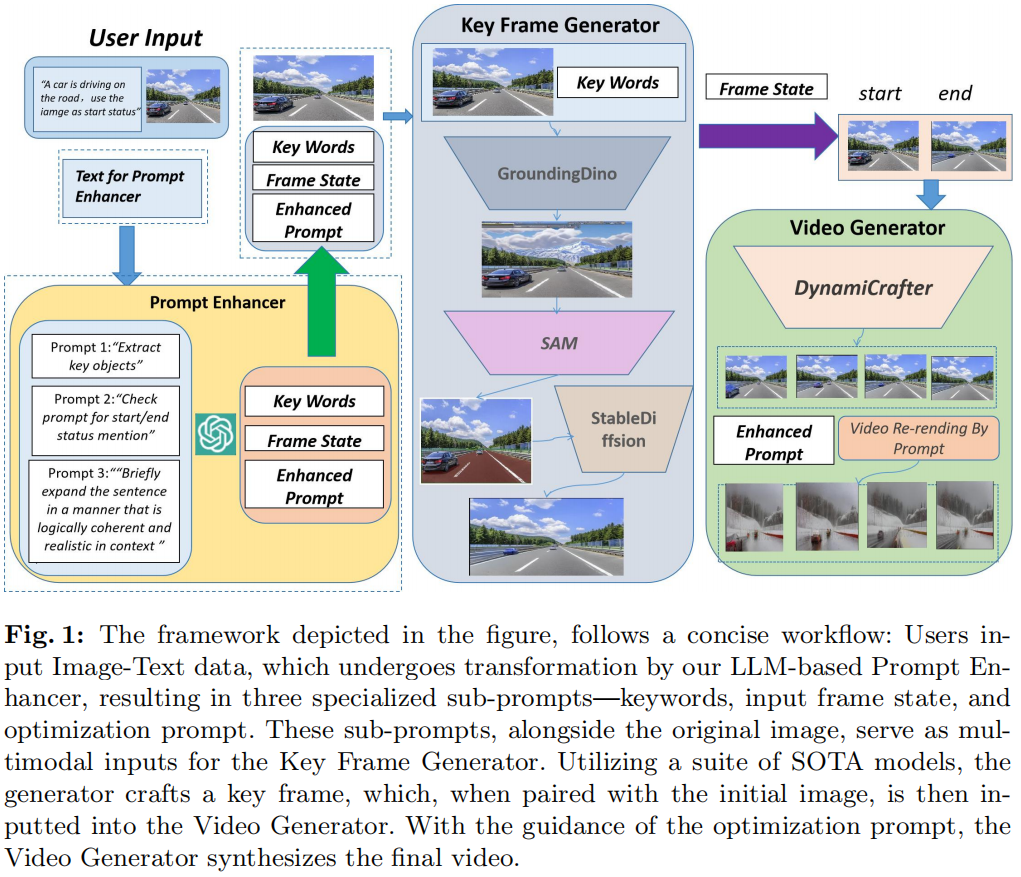
Several text-to-video diffusion models have demonstrated commendable capabilities in synthesizing high-quality video content. However, it remains a formidable challenge pertaining to maintaining temporal consistency and ensuring action smoothness throughout the generated sequences. In this paper, we present an innovative video generation AI agent that harnesses the power of Sora-inspired multimodal learning to build skilled world models framework based on textual prompts and accompanying images. The framework includes two parts: prompt enhancer and full video translation.
Pix2Pix-OnTheFly: Leveraging LLMs for Instruction-Guided Image Editing
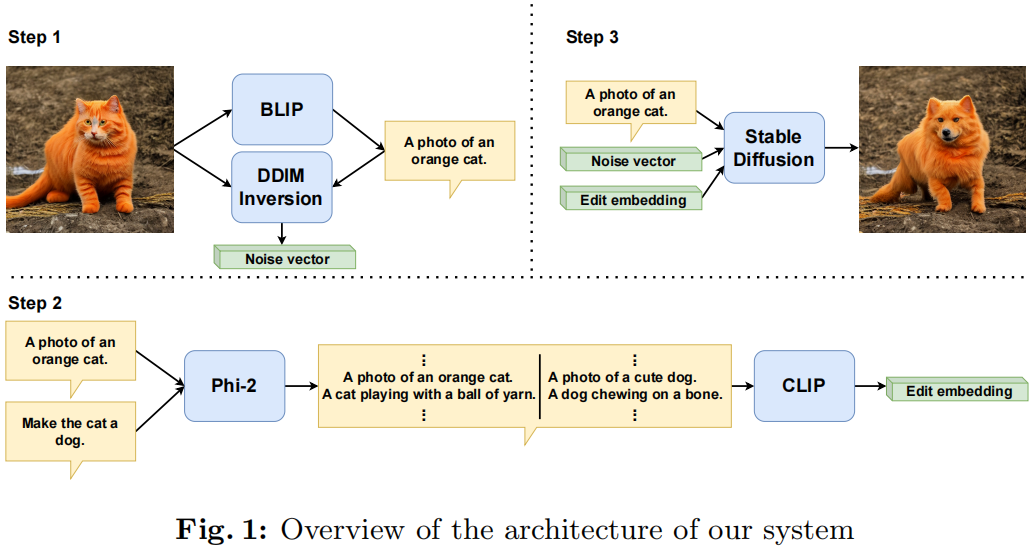
The combination of language processing and image processing keeps attracting increased interest given recent impressive advances that leverage the combined strengths of both domains of research. Among these advances, the task of editing an image on the basis solely of a natural language instruction stands out as a most challenging endeavour. While recent approaches for this task resort, in one way or other, to some form of preliminary preparation, training or fine-tuning, this paper explores a novel approach: We propose a preparation-free method that permits instruction-guided image editing on the fly. This approach is organized along three steps properly orchestrated that resort to image captioning and DDIM inversion, followed by obtaining the edit direction embedding, followed by image editing proper.
CHAI: Clustered Head Attention for Efficient LLM Inference
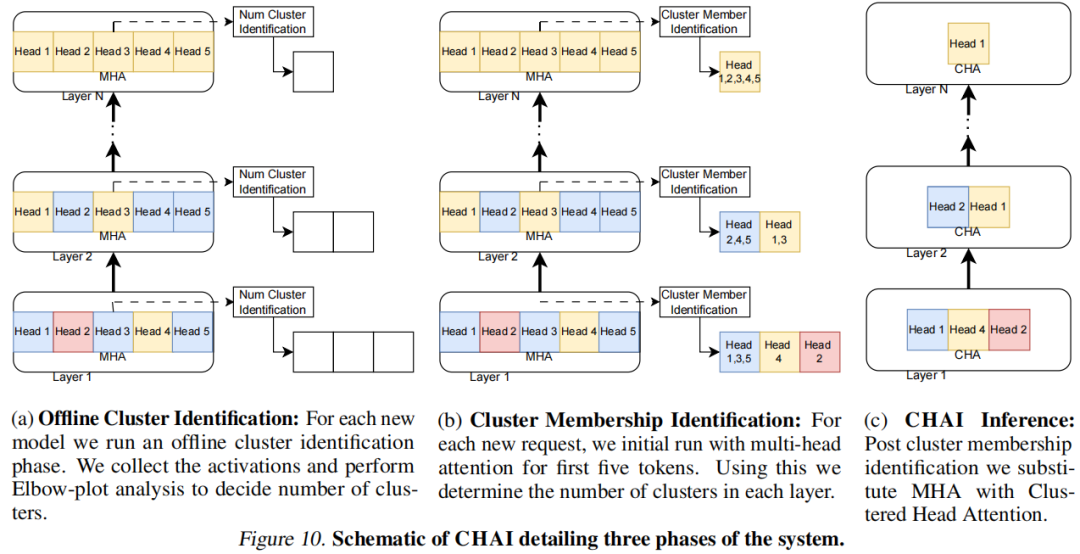
Large Language Models (LLMs) with hundreds of billions of parameters have transformed the field of machine learning. However, serving these models at inference time is both compute and memory intensive, where a single request can require multiple GPUs and tens of Gigabytes of memory. Multi-Head Attention is one of the key components of LLMs, which can account for over 50% of LLMs memory and compute requirement. We observe that there is a high amount of redundancy across heads on which tokens they pay attention to. Based on this insight, we propose Clustered Head Attention (CHAI). CHAI combines heads with a high amount of correlation for self-attention at runtime, thus reducing both memory and compute.
Mechanics of Next Token Prediction with Self-Attention

Transformer-based language models are trained on large datasets to predict the next token given an input sequence. Despite this simple training objective, they have led to revolutionary advances in natural language processing. Underlying this success is the self-attention mechanism. In this work, we ask: $\textit{What}$ $\textit{does}$ $\textit{a}$ $\textit{single}$ $\textit{self-attention}$ $\textit{layer}$ $\textit{learn}$ $\textit{from}$ $\textit{next-token}$ $\textit{prediction?}$ We show that training self-attention with gradient descent learns an automaton which generates the next token in two distinct steps: $\textbf{(1)}$ $\textbf{Hard}$ $\textbf{retrieval:}$ Given input sequence, self-attention precisely selects the $\textit{high-priority}$ $\textit{input}$ $\textit{tokens}$ associated with the last input token. $\textbf{(2)}$ $\textbf{Soft}$ $\textbf{composition:}$ It then creates a convex combination of the high-priority tokens from which the next token can be sampled. Under suitable conditions, we rigorously characterize these mechanics through a directed graph over tokens extracted from the training data. We prove that gradient descent implicitly discovers the strongly-connected components (SCC) of this graph and self-attention learns to retrieve the tokens that belong to the highest-priority SCC available in the context window.
Make Me Happier: Evoking Emotions Through Image Diffusion Models

Despite the rapid progress in image generation, emotional image editing remains under-explored. The semantics, context, and structure of an image can evoke emotional responses, making emotional image editing techniques valuable for various real-world applications, including treatment of psychological disorders, commercialization of products, and artistic design. For the first time, we present a novel challenge of emotion-evoked image generation, aiming to synthesize images that evoke target emotions while retaining the semantics and structures of the original scenes. To address this challenge, we propose a diffusion model capable of effectively understanding and editing source images to convey desired emotions and sentiments. Moreover, due to the lack of emotion editing datasets, we provide a unique dataset consisting of 340,000 pairs of images and their emotion annotations.
StyleDyRF: Zero-shot 4D Style Transfer for Dynamic Neural Radiance Fields
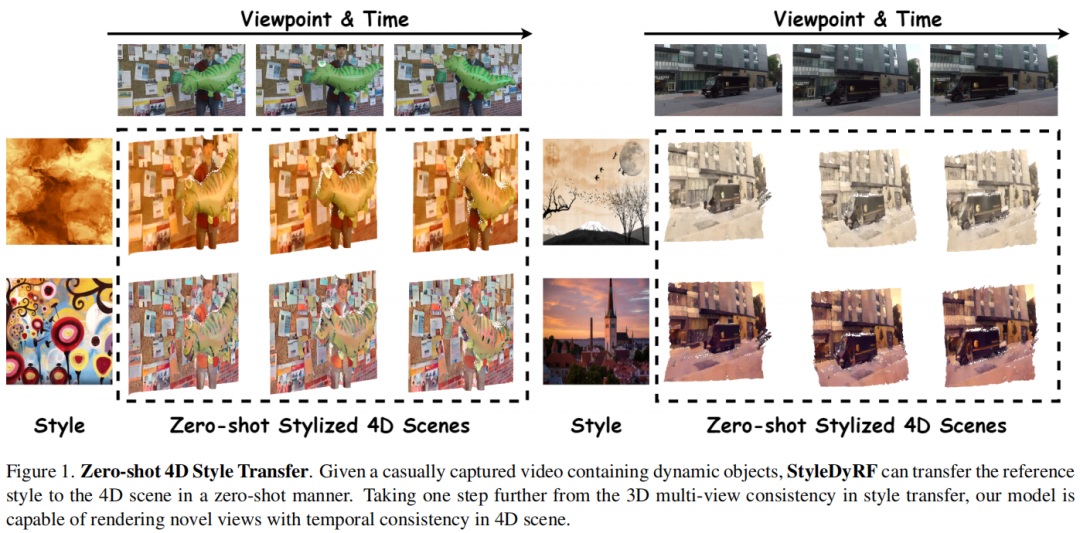
4D style transfer aims at transferring arbitrary visual style to the synthesized novel views of a dynamic 4D scene with varying viewpoints and times. Existing efforts on 3D style transfer can effectively combine the visual features of style images and neural radiance fields (NeRF) but fail to handle the 4D dynamic scenes limited by the static scene assumption. Consequently, we aim to handle the novel challenging problem of 4D style transfer for the first time, which further requires the consistency of stylized results on dynamic objects. In this paper, we introduce StyleDyRF, a method that represents the 4D feature space by deforming a canonical feature volume and learns a linear style transformation matrix on the feature volume in a data-driven fashion. To obtain the canonical feature volume, the rays at each time step are deformed with the geometric prior of a pre-trained dynamic NeRF to render the feature map under the supervision of pre-trained visual encoders.
ManiGaussian: Dynamic Gaussian Splatting for Multi-task Robotic Manipulation
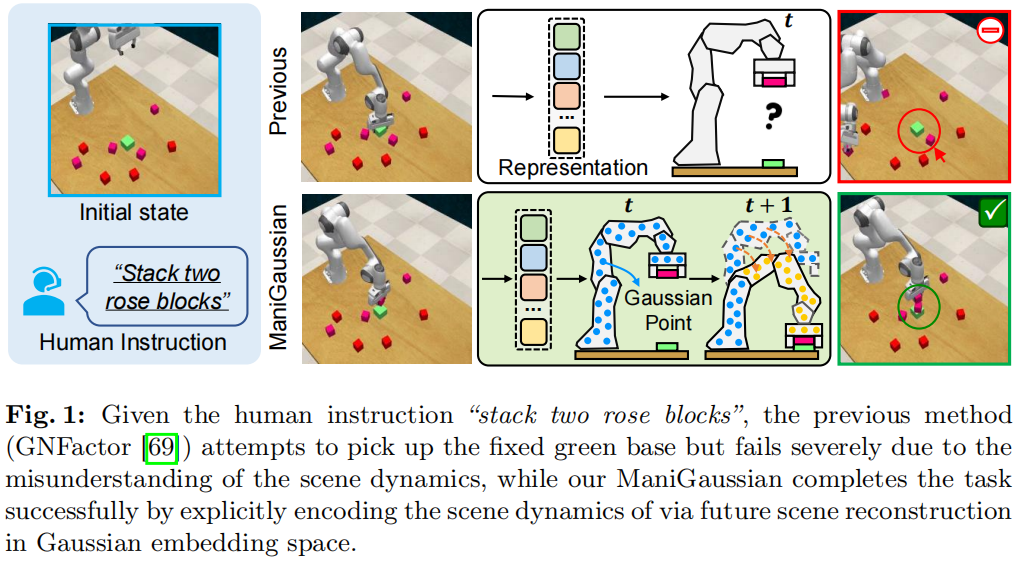
Performing language-conditioned robotic manipulation tasks in unstructured environments is highly demanded for general intelligent robots. Conventional robotic manipulation methods usually learn semantic representation of the observation for action prediction, which ignores the scene-level spatiotemporal dynamics for human goal completion. In this paper, we propose a dynamic Gaussian Splatting method named ManiGaussian for multi-task robotic manipulation, which mines scene dynamics via future scene reconstruction. Specifically, we first formulate the dynamic Gaussian Splatting framework that infers the semantics propagation in the Gaussian embedding space, where the semantic representation is leveraged to predict the optimal robot action. Then, we build a Gaussian world model to parameterize the distribution in our dynamic Gaussian Splatting framework, which provides informative supervision in the interactive environment via future scene reconstruction. We evaluate our ManiGaussian on 10 RLBench tasks with 166 variations, and the results demonstrate our framework can outperform the state-of-the-art methods by 13.1\% in average success rate.
Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models

Most diffusion models assume that the reverse process adheres to a Gaussian distribution. However, this approximation has not been rigorously validated, especially at singularities, where t=0 and t=1. Improperly dealing with such singularities leads to an average brightness issue in applications, and limits the generation of images with extreme brightness or darkness. We primarily focus on tackling singularities from both theoretical and practical perspectives. Initially, we establish the error bounds for the reverse process approximation, and showcase its Gaussian characteristics at singularity time steps. Based on this theoretical insight, we confirm the singularity at t=1 is conditionally removable while it at t=0 is an inherent property. Upon these significant conclusions, we propose a novel plug-and-play method SingDiffusion to address the initial singular time step sampling, which not only effectively resolves the average brightness issue for a wide range of diffusion models without extra training efforts, but also enhances their generation capability in achieving notable lower FID scores.
Language-Driven Visual Consensus for Zero-Shot Semantic Segmentation
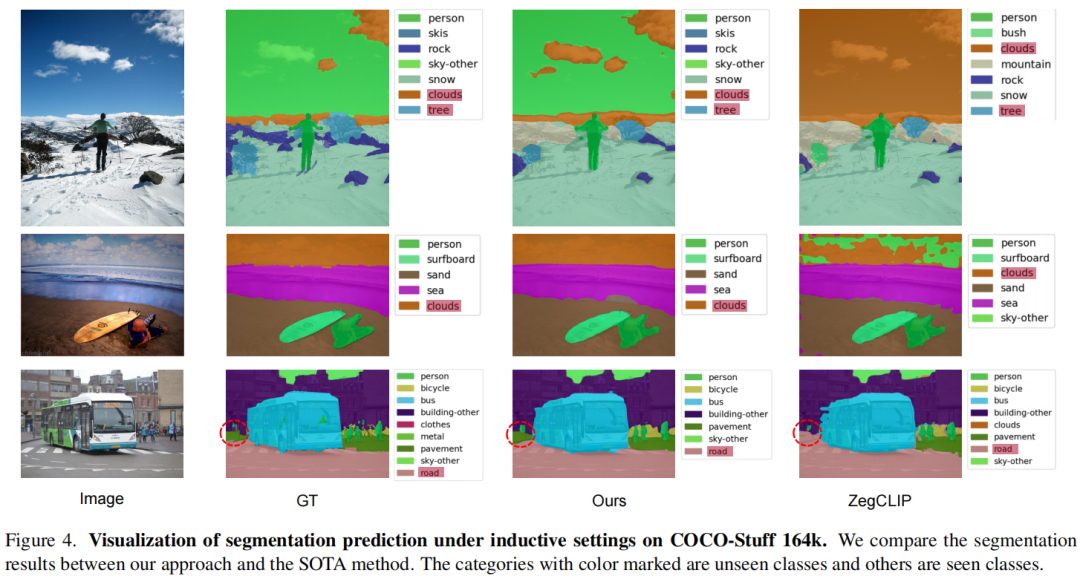
The pre-trained vision-language model, exemplified by CLIP, advances zero-shot semantic segmentation by aligning visual features with class embeddings through a transformer decoder to generate semantic masks. Despite its effectiveness, prevailing methods within this paradigm encounter challenges, including overfitting on seen classes and small fragmentation in masks. To mitigate these issues, we propose a Language-Driven Visual Consensus (LDVC) approach, fostering improved alignment of semantic and visual information.Specifically, we leverage class embeddings as anchors due to their discrete and abstract nature, steering vision features toward class embeddings. Moreover, to circumvent noisy alignments from the vision part due to its redundant nature, we introduce route attention into self-attention for finding visual consensus, thereby enhancing semantic consistency within the same object. Equipped with a vision-language prompting strategy, our approach significantly boosts the generalization capacity of segmentation models for unseen classes. Experimental results underscore the effectiveness of our approach, showcasing mIoU gains of 4.5 on the PASCAL VOC 2012 and 3.6 on the COCO-Stuff 164k for unseen classes compared with the state-of-the-art methods.
PFStorer: Personalized Face Restoration and Super-Resolution

Recent developments in face restoration have achieved remarkable results in producing high-quality and lifelike outputs. The stunning results however often fail to be faithful with respect to the identity of the person as the models lack necessary context. In this paper, we explore the potential of personalized face restoration with diffusion models. In our approach a restoration model is personalized using a few images of the identity, leading to tailored restoration with respect to the identity while retaining fine-grained details. By using independent trainable blocks for personalization, the rich prior of a base restoration model can be exploited to its fullest. To avoid the model relying on parts of identity left in the conditioning low-quality images, a generative regularizer is employed. With a learnable parameter, the model learns to balance between the details generated based on the input image and the degree of personalization. Moreover, we improve the training pipeline of face restoration models to enable an alignment-free approach. We showcase the robust capabilities of our approach in several real-world scenarios with multiple identities, demonstrating our method's ability to generate fine-grained details with faithful restoration. In the user study we evaluate the perceptual quality and faithfulness of the genereated details, with our method being voted best 61% of the time compared to the second best with 25% of the votes.
Towards Dense and Accurate Radar Perception Via Efficient Cross-Modal Diffusion Model
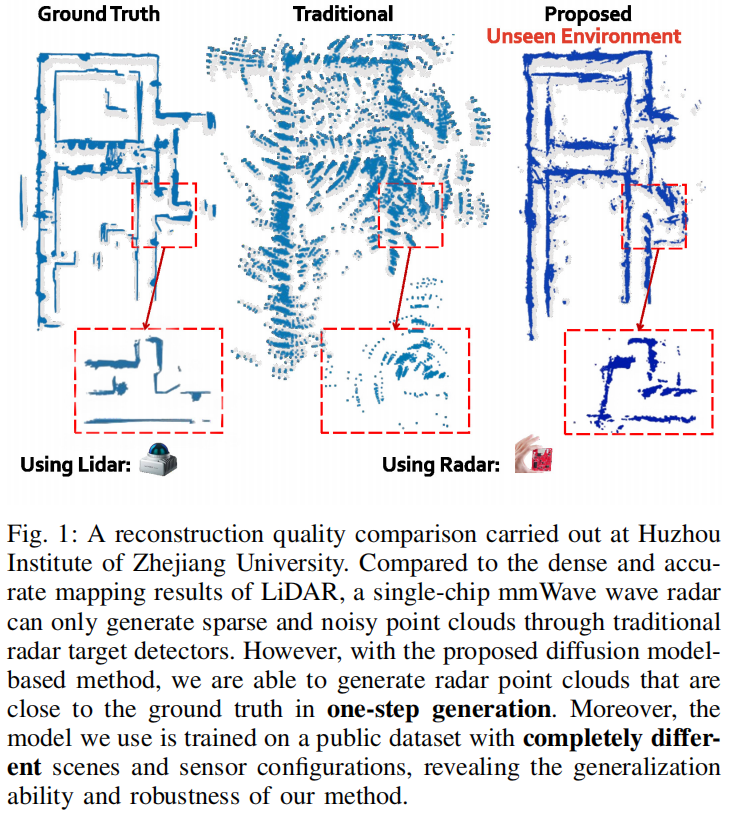
Millimeter wave (mmWave) radars have attracted significant attention from both academia and industry due to their capability to operate in extreme weather conditions. However, they face challenges in terms of sparsity and noise interference, which hinder their application in the field of micro aerial vehicle (MAV) autonomous navigation. To this end, this paper proposes a novel approach to dense and accurate mmWave radar point cloud construction via cross-modal learning. Specifically, we introduce diffusion models, which possess state-of-the-art performance in generative modeling, to predict LiDAR-like point clouds from paired raw radar data. We also incorporate the most recent diffusion model inference accelerating techniques to ensure that the proposed method can be implemented on MAVs with limited computing resources.
Gaussian Splatting in Style
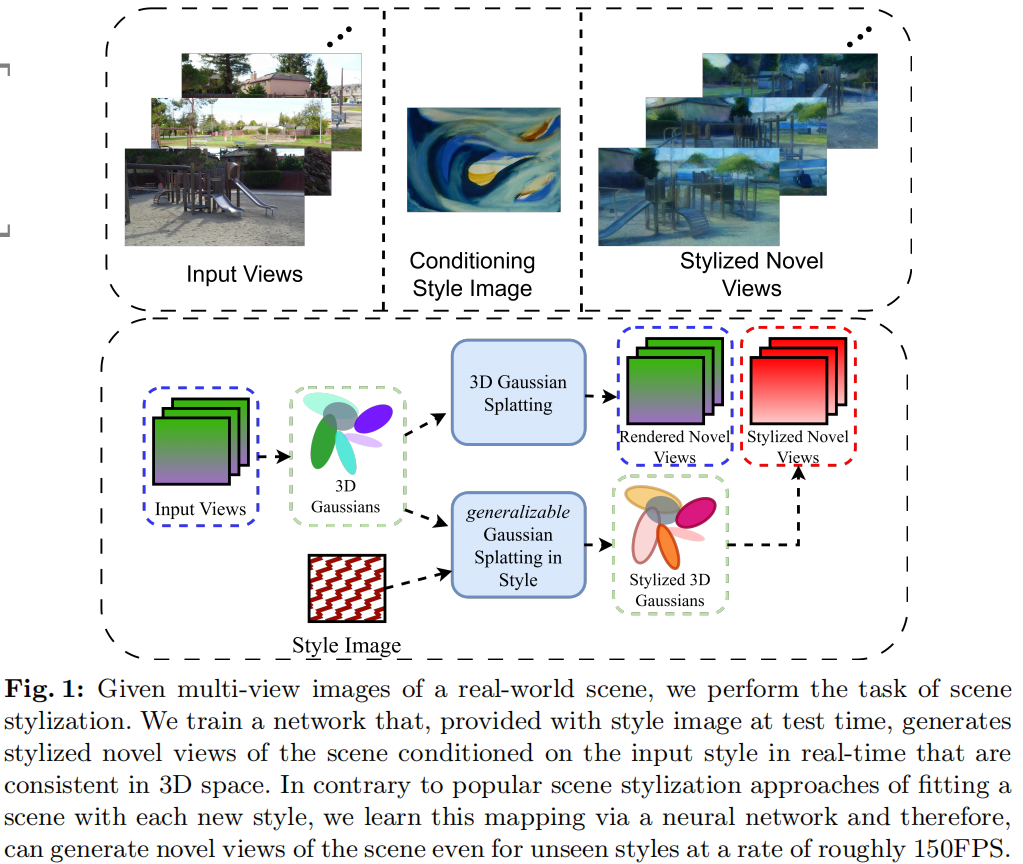
Scene stylization extends the work of neural style transfer to three spatial dimensions. A vital challenge in this problem is to maintain the uniformity of the stylized appearance across a multi-view setting. A vast majority of the previous works achieve this by optimizing the scene with a specific style image. In contrast, we propose a novel architecture trained on a collection of style images, that at test time produces high quality stylized novel views. Our work builds up on the framework of 3D Gaussian splatting. For a given scene, we take the pretrained Gaussians and process them using a multi resolution hash grid and a tiny MLP to obtain the conditional stylised views. The explicit nature of 3D Gaussians give us inherent advantages over NeRF-based methods including geometric consistency, along with having a fast training and rendering regime.
OneVOS: Unifying Video Object Segmentation with All-in-One Transformer Framework

Contemporary Video Object Segmentation (VOS) approaches typically consist stages of feature extraction, matching, memory management, and multiple objects aggregation. Recent advanced models either employ a discrete modeling for these components in a sequential manner, or optimize a combined pipeline through substructure aggregation. However, these existing explicit staged approaches prevent the VOS framework from being optimized as a unified whole, leading to the limited capacity and suboptimal performance in tackling complex videos. In this paper, we propose OneVOS, a novel framework that unifies the core components of VOS with All-in-One Transformer. Specifically, to unify all aforementioned modules into a vision transformer, we model all the features of frames, masks and memory for multiple objects as transformer tokens, and integrally accomplish feature extraction, matching and memory management of multiple objects through the flexible attention mechanism. Furthermore, a Unidirectional Hybrid Attention is proposed through a double decoupling of the original attention operation, to rectify semantic errors and ambiguities of stored tokens in OneVOS framework. Finally, to alleviate the storage burden and expedite inference, we propose the Dynamic Token Selector, which unveils the working mechanism of OneVOS and naturally leads to a more efficient version of OneVOS.
VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis

We propose VLOGGER, a method for audio-driven human video generation from a single input image of a person, which builds on the success of recent generative diffusion models. Our method consists of 1) a stochastic human-to-3d-motion diffusion model, and 2) a novel diffusion-based architecture that augments text-to-image models with both spatial and temporal controls. This supports the generation of high quality video of variable length, easily controllable through high-level representations of human faces and bodies. In contrast to previous work, our method does not require training for each person, does not rely on face detection and cropping, generates the complete image (not just the face or the lips), and considers a broad spectrum of scenarios (e.g. visible torso or diverse subject identities) that are critical to correctly synthesize humans who communicate. We also curate MENTOR, a new and diverse dataset with 3d pose and expression annotations, one order of magnitude larger than previous ones (800,000 identities) and with dynamic gestures, on which we train and ablate our main technical contributions.
这篇关于WorldGPT、Pix2Pix-OnTheFly、StyleDyRF、ManiGaussian、Face SR的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








