本文主要是介绍博客园整改之思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在博客园写博客写了三年半的时间了,当初为什么会选择在博客园写,我也记不清是什么原因了,或许这大概是缘分吧。
今年3月份后半段的时候,博客园突然访问不了了,如今通过搜索资料,仍然发现有部分文章访问不了,如下图所示:
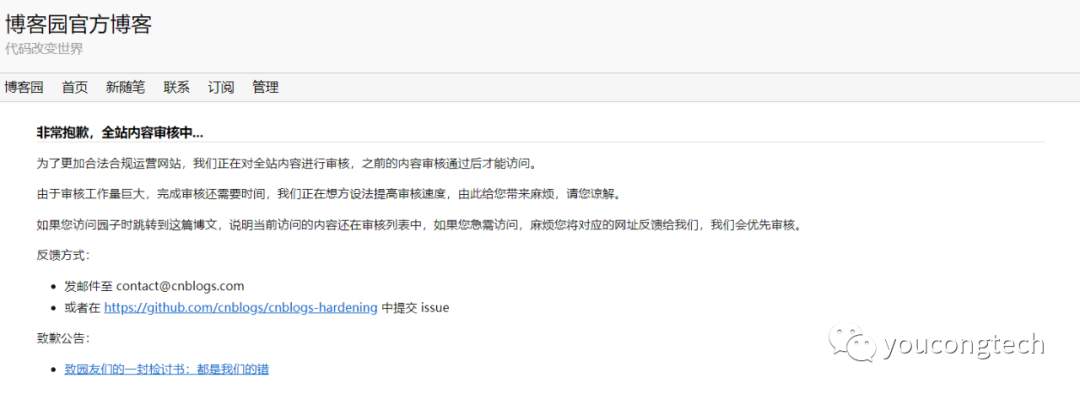
博客园给园友致歉,内容如下图所示:
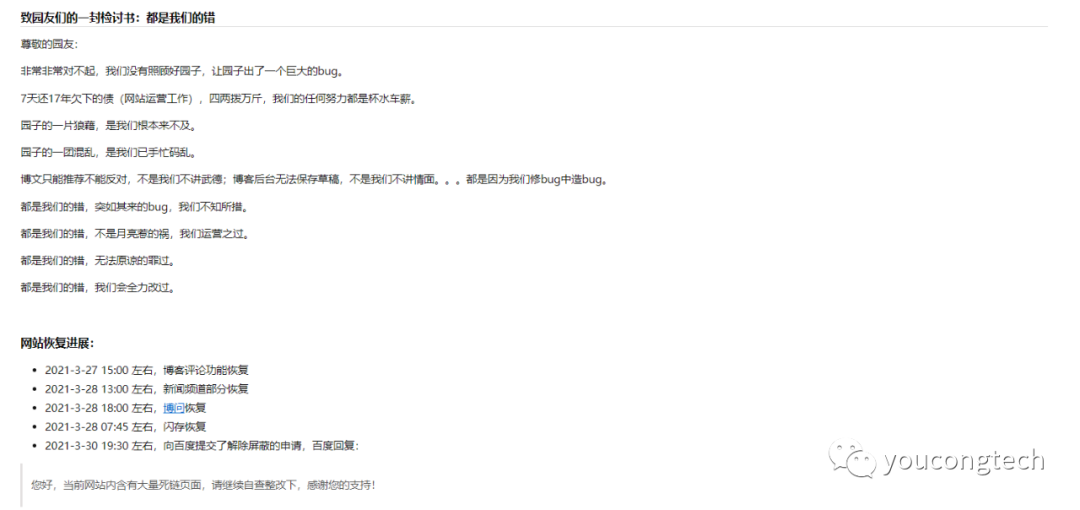
从这张图中引发我的一些思考,最核心的一句就是:
7天还17年欠下的债(网站运营工作),四两拨万斤,我们的任何努力都是杯水车薪。
一、技术债务的思考
技术债务又称代码债务。定义如下:
交付第一次代码就像陷入债务。债务是可以加快开发速度,只有通过重写代码,及时偿还债务。如果不偿还债务,就会发生危险。把时间花在写一些不正确的代码上的每一分钟都算作该债务的利息。整个软件项目可能在未合并代码的部署,面向对象设计或其他方面的债务问题而陷入停顿-著名的计算机程序员沃德·坎宁安
在创业公司的时候,从智能酒店+智能门锁、快速开发平台、编程教育平台到电商平台二次开发等,写了大量的代码(至少十万行代码量,不含空格),代码虽然写的多,但技术债务也不少,这导致的一个结果就是bug越写越多,最后不得不以周末的时间来改bug。
1.为什么bug越写越多?以我的经验总结如下:
写之前想的太少,没有想清楚就直接开敲,一切凭感觉(凭感觉写代码,在没养成良好的编码习惯和研发制度的约束下,凭感觉写代码很不可靠);
工期紧,任务多,注重功能实现,忽略实现细节(对输入进行参数校验、复杂的业务逻辑处理考虑过于简单、不合理的数据库/IO操作、无异常机制或大量不必要的try/catch等)。
2.那么如何减少bug率?
团队编码规范一定要落实(可以参考阿里巴巴的Java开发规范);
每写完一个功能,一定要自测(如果你平时bug率很高一定要这样做,当你的bug率大幅度降低时不一定都要自测(可能代表你逐渐养成好的编码习惯),不过我的习惯是不管代码bug率多么低,一定要自测);
代码Code Review(不管是Review自己的或者还是其他人的,多少都会有些收获的);
一定要有责任心(记得当初在创业公司的时候,整个后台的前后端都是由我和另外一个同事负责,我们俩写了一堆bug,整个后台管理系统可用性非常差,根本原因就是我们责任心缺失,写的很随意)。
3.技术债务如何从源头控制?
此次博客园被审查,很大原因是因为对于内容审核不严,内容审核太松的话,某些非法分子就会借此进行非法宣传和传播,最后遭殃的一定是平台,微信公众号在这块就做的很不错(可以借鉴)。之前在纵横网写小说的时候,发现纵横网的内容编辑器对内容审核还是比较严的,特别当内容出现违禁词的时候,强制性不准发布。
回归正题,技术债务如何从源头控制住?或者是已经发生要如何控制?
制度(光靠人的主观能动性是不行的,还要从制度上约束,合理的制度能充分调动人的主观能动性和积极性);
定期团队内部培训(代码规范、业务讲解、问题复盘、技术分享);
工程师要有主人翁的意识(开发前熟悉业务和理解需求、开发时画流程图(针对业务逻辑复杂的)和写代码遵守公司代码规范、开发后自测);
定期处理技术债务(功能实现了,但可读性和可扩展性非常不好需要重构,定期抽时间处理不一定要一口吃一个大胖子);
推行代码Review(利于发现系统的技术债务,同时也是为了提高团队的编码质量,好的推广落实,不好的引以为鉴)。
二、面向搜索编程受阻
平时开发基于以往的经历(踩过的坑),基本上能解决开发过程中的不少问题,但面对有些问题还需要搜索,没有搜索很难进行的下去。
这次说的面向搜索编程搜索受阻,不是指不会用搜索引擎,而是指我想要搜的关键信息,其中有一篇文章在博客园平台,但因为博客园平台整改,看不到我想要的信息。于是我便只能转向CSDN、思否、简书、StackoverFlow或其他个人博客,从中得到我想要的信息。
不禁想起导师曾写过的一篇wiki关于技术管理的,其中提到一点
“一定要自己把问题搞清楚,不要寄希望于别人来帮你搞清楚事情,可以借助别人的帮助,但不能过度依赖”
对于面向搜索编程时,有些时候我会犯这样的错误,只是看到报错部分的信息,没有注意到是那一行出现这样的错误,就直接搜索了(有些时候这样的搜索很低效,因为你没有弄清楚真正的错误是什么),这种情况就是过于依赖搜索引擎,不过好在这种现象自去年下半年和至今基本犯的比较少,这或许是一个好的兆头。
1.面向搜索编程让我看到自身的一些不足?
基本功有待加强(体现在Java中对String、List、Set、Map、I/O和多线程的合理应用,应用不等于合理应用,当然了不仅仅是Java);
没有总结出自己的代码库(最直接的体现没有将以往的工具类总结出来,直接网上复制(不少代码是有问题的)或者将之前公司的代码迁移过来,总结自己的代码库不仅仅是为了方便以后复用,也是为了更好的深入理解)。
2.如何避免面向搜索编程形成的机械思维?
面向搜索编程有利也有弊端,
利是能在一定程度上提高学习或工作效率;
弊是如果过于依赖大脑会变得不思考,长此以往,不利于长远发展。
这里提到的如何避免面向搜索编程形成的机械思维或者是依赖性思维不等同于不使用搜索引擎。
刚好之前有一个活生生案例,是我写的一个复盘,文章如下:
ssh问题之复盘
这篇文章提到的问题,问题的根源在于我没有弄清楚真正的问题是什么,仅仅是依据是没有权限导致重复输入密码,结果是没有找准问题的关键,搜索了一堆,参考了网上各种解决办法都没有解决这样的问题(花费大量不必要的时间,仍然没有解决)。最后冷静下来,复现这个问题,一步步来,才找准了问题的根本原因。
面向搜索编程的机械思维也可叫惯性思维,这种惯性思维会让我们产生一个错觉(前面提到过),当遇到一个问题时,我们看到错误信息,只看一部分不看很整体,发现解决不了就直接复制一些关键字搜索,其实这些问题原本是不需要搜索的,错误信息看全了,定位到关键代码(必要时可以借助Debug)实际是可以解决的。
作为程序员平常工作中用到搜索引擎,主要为如下几个方面?
个人学习(网上教程、博文、在线视频、技术官网等);
工作中高效解决问题(站在巨人的肩上,前人踩过的坑,我们不必从头来过)。
过去近几年的时间,我过于依赖搜索给我带来的一些快感,这些快感让我养成了问题的浅度思考习惯(所谓问题的浅度思考习惯指仅仅满足于问题的解决,而不去深究问题背后的原因以及如何避免类似的问题再现等)。
说了这么多,那么我们如何避免面向搜索编程形成的机械思维?
答案很简单,那就是多给自己提问(凡是多问个为什么),随着不断提问和回答所提的问题,问题的本质也就找到了,本质定位到了,对应的解决方案自然会有,这一个过程中,深度思考能力也在不断提升。
当然了突破人的惯性很难,习惯一旦养成,不是一两天就能改的掉的,所以我选择用复盘来提高自己深度思考的能力和看问题的视角。
三、总结
舒婷有一首诗叫做《这也是一切》,其中有一句我印象深刻,即”一切的现在都孕育着未来,未来的一切都生长于它的昨天“,从18年到至今,我比较关键的三年经历(从2018年初到至今),深刻地验证着这句话。这关键的三年有太多的经验教训,我都没有好好复盘总结过,导致至今还时不时犯这些错误,不过好在近来定期复盘一些事情,能规避不少曾经的错误。



扫码二维码关注我
这篇关于博客园整改之思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




