本文主要是介绍人人都是艺术家!谈谈那些奇怪的字符,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前言
编码,是每个程序员绕不开的话题。对于前端工程师而言,字符更是会直观地展示在界面上。
提起文字,大部分人的脑中,都会定式为规整排列的字符。但是林子大了什么鸟都有,世界上可是存在着6800+种文字,难免会飞出来一些诡异的鸟…
而号称“万国码”的Unicode,在实现编码与展示的时候,也会不会遇到一些奇葩的事情呢?
事实上,可能你早已见识过了:
x̙͈̝͍͕̙̄͛̽̆͌́̕͟g̘̣̠̝̟̤̥̼̼̽͑͋̈̑̒͟͞q̛̤̦̝̘͎͋̔̋͌͒̆̋̚͡f̵̢̙͇̮̠̋̀͌̅̉̃̔͜͜͠͡r̢̜̩͙̭̲͓͈̈̀͑̆͋̚͢͜m̷̛͙̝̣̲̭͍͉̊̓̾̈̋̿̚͢͟͠s̷̡̩͔̮͈̜̊̽͂̆̈́̃̓͋̏
热҈的҈字҈都҈出҈汗҈了҈
你的屏幕被蓝翔挖掘机给挖坏了不信你看;̷̸̨̀͒̏̃ͦ̈́̾̀́̎͢҉̵̶͚̼͉͖̺̥͔͇̰̹̮͙͉̻̼̭̻͕̮͇ͨͬͪ͗̇̑̽͋̀̋̊͌ͧͨͭ̓̅͐ͥ̂̔̊ͧ͊҉̶̵̷̞̩̦̳̺̳̬̬̩̣̫͇̯̥͖͍͕̠̦̼̗ͯ̽͌̔ͪͯ́́͋̍ͨ̿̿̎͒ͤ̓̅̀͂ͧ͋̏ͫͣ̔͘͜͠͏̶̵̸̧̧̥̺͓̘̺͎̜̥͕͈̝̫͎̺̮̱̤̠̠͖̳̻̥̣̪͍͕͇̮͙̹̪ͮͧͫ͂͒ͤͣ̌̽ͨͪ͒̄̄̉̒̊ͩ̅͆͘̚͘͘̚͟͟͝ͅ
今天我们就来探讨一下这些奇怪的字符。
一、文字可以戴帽子和穿鞋子
提起泰文,很多朋友都会立即想到:萨瓦迪卡(你好)。
但这句话是怎么写的呢?
其实这句你好,男生和女生之间还有差异,男生写法是:สวัสดีครับ,女生则是:สวัสดีค่ะ。
不过这并不重要,重要的是,我们发现某些字的上面,还带了特殊的符号。就好像是戴上了帽子。
事实上,泰文字符不仅会“戴帽子”,偶尔还会“穿鞋子”。
比如下面三个字符:ผ ผู ผู้
如果脑洞再大一点,有人就会想,那是不是还可以戴多顶帽子呢?
的确如此…泰文允许你穿一双鞋子,并且戴两顶帽子。完整的形式是这样的:
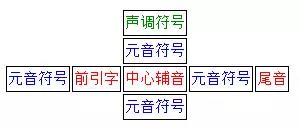
所以,平时看惯了中英文的我们,需要改变一下思路了。
世界上的文字,并不全是规规整整横向排列的格子,也存在像泰文这种变形金刚组合式的文字。
虽然标准的泰文里,“帽子”和“鞋子”的数量是有限制的,但由于国际码的迷之设计(先卖个关子),在计算机里显示的泰文字符,却可以拥有无数的帽子和鞋子。也就是说,它变成了一款可以在Y轴无限拓展的文字!
并且,咱不光可以往上喷,还可以有一定角度…


还可以
(由于一些系统会崩溃,这里使用截图)
二、人与机器的矛盾
然后我们会质问Unicode,你为何不讲道理?
如此的设计,近乎是一个bug;但即使是bug,也应该早就修复了呀。
事实上,这样的设计,是为了解决一个问题:人与机器的矛盾。
首先是存储的矛盾。
如果把每个组合好的泰文用一个编码来表示,那么至少需要44×21×4=3696个编码(实际上可能要比这还多)。用如此多的编码来处理基本元素只有69个的文字是非常浪费的,因此电脑采用一套称为复杂文字编排(CTL)的设计来解决矛盾。
简单的说,泰文的每个基本字符对应一个编码,用户在输入法里依次输入多个基本字符进行拼合,最后敲一个特殊的“结束字符”;这时前面输入的基本字符,就拼合成了一个单独的泰文字符,在屏幕中显示。 这样就解决了存储的空间浪费问题。
但这样就带来了第二个矛盾,识别的问题。
人可以轻松地识别一个泰文合字是否拼写正确、有意义;但机器在显示时却很难进行判断,即使可以也会带来相应的性能问题。
如何解决呢?如今会在输入法上做一些文章,比如打一个声调符号后就不能再输入了。不过,由于泰文这种基于结束标志合成字符的本质,你还是没法避免“艺术家”们使用复制粘贴、手工撰改字符位置等方式去进行创造,只能起到一些限制作用。
其次,在比较新版本的Webkit里,在显示上会阻止这种往上下冒的字符,这样至少不影响排版。所以有部分字符已经不会出现上下叠加的情形了,你可以在不同浏览器,观察一下这个字符的显示:ส็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็็
三、萌即正义的颜文字 (ง •̀_•́)ง
也许你觉得泰文奇葩,但它的声调就在文字里,看到就能准确地读出来。这样更容易传播,是不是也没了你读文言文要查字典的烦恼呢?所以文字的设计各有优劣。
这样的设计不止泰文,它只是一个典型的例子。除此之外常见的还有老挝文、藏文。
脑洞大开的艺术家们,又会想到另外一个好玩的事情:我能不能拿老挝文的“帽子”,组合“藏文”的鞋子,合成一个独立的字符呢?
他们赢了。不久,颜文字开始流行。
比如,这个表情:(;´༎ຶД༎ຶ`)
里面有眼睛流泪的一个字符:༎ຶ
它是什么语言呢?
事实上,它并不属于世界上任何一种语言!眼睛部分是老挝文,泪水部分属于藏文。
但是,你在复制它的时候,可以发现它却是一个单独的字符,这就非常的神奇。原因我们在第二部分已经讲过了。
我是如何知道的呢?当然我并不是个语言学家,我们可以转码一下,发现༎ຶ对应的编码是༎ຶ,再到 unicode-table 里去查看就清楚了。
除此之外——
-
▷ˋε´◁ 中 ε 是希腊字母
-
ʕ-'ᴥ’-ʔ 中 ʕᴥʔ 是国际音标
-
(·ཀ·」∠) 中 ཀ 是藏文
-
(ง •̀_•́ )ง 中 ง 是泰文
-
罒 д 罒 中 罒 是中文(同网),д 是俄语西里尔字母
看来如果你会发颜文字,就是名副其实的会“十八国语言”了呢 (๑✦ˑ̫✦)✧
四、字体的错位
前面我们一直在谈字符的本质,但字符在屏幕中的展示,还有一个关键的因素:字体。
相同的字符,使用了不同的字体,它们的显示也会有差别。
一行中文,你设置“黑体”或“草书”,它大体来看还是规整的;
但如果你设置一行英文为“草书”,可能就会有问题。
在浏览器里,如果对应编码在字体文件里为空,一般会展示成一个方格,起码不会影响其他正常字符的排版。但我们知道,Unicode的林子实在太大了…
在某些字体里,就会对一些特殊的字符产生错误的排版。
比如:热҈的҈字҈都҈出҈汗҈了҈
把它转义一下,就得到编码是: 热҈的҈字҈都҈出҈汗҈了҈
其中0488就是҈这个字符的编码,它是一个组合用的西里尔文百千符号。
它在大部分常用字体里,都有错位问题;而其他一些字体,比如 Courier New 字体,则是分开的展示:
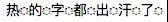
那么,这两种展示哪种才是正常的呢?其实都不正常。
我们查看西里尔文计数法的wiki,可以看到它只有配合西里尔数字时,才能展示正常:

至于你把它跟其他语言组合在一起时,我们要么看到错位,要么看到分离的展示。而且国际上并没有一个组织,去规定要怎么展示。事实上文字这么多,根本也管不过来,所以这也是混乱的原因。
最后补充一点,另外一小撮别有心裁的艺术家,还习惯使用这个字符去突破敏感词过滤…
五、混乱与创新?
值得一提的是,Unicode是不可阻挡的潮流,它也一直在更新。比如我们常用的Emoji表情,就已经是Unicode的标准字符集。
而前面我们说到,大家在玩这些奇奇怪怪的字符时,都是基于“类似bug”的设定在搞事情。这就有很大的局限性。
那“艺术家”们又会有些大胆的想法:我能不能主动创造一些新字符,就是为了错位和组合呢?
我也不清楚这是创新,还是会带来更多的混乱。但事实是,iOS系统自带的字符,已经有这样的尝试了。并且搜狗输入法在iOS系统提供的诸多符号里,挑选了一些,可供用户去使用。这个功能的名字,叫做花漾字。
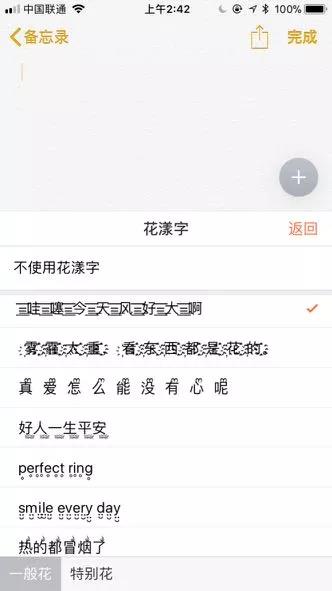
还是得感慨艺术家们的视角是多么独特。
既然都这样了…最后,希望我们的国产表情包能有朝一日打入Unicode吧。

这篇关于人人都是艺术家!谈谈那些奇怪的字符的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






