本文主要是介绍趁着课余时间学点Python(五)用课余时间提升自己关于高级数据类型的知识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 前言
- 练习代码
- 高级数据类型
- 1. 字符串
- 1.1 遍历
- 1.2 格式化字符串
- 1.3 原生字符串
- 2. 列表
- 2.1 往袋子里放东西
- 2.2 把袋子里的东西拿出来
- 2.3 把袋子里的东西拿出来换个东西
- 看看袋子里的东西
- 3.集合
- 3.1增加元素
- 3.2删除元素
- 3.3 修改元素
- 4. 元组
- 4.1 查看元组
- 4.2 删除
- 5. 字典
- 5.1 增加元素
- 5.2 删除元素
- 5.3 修改元素
- 5.4 查找元素
- 结语
前言
经过这几次的学习,想必大家都对Python的基础语法有了一定的了吧,不知道你是否会被Python的简洁性所折服,反正我写 Python代码就挺舒服的!
那么学了基本数据类型和分支控制语句后,那么来看看高级数据类型都有些什么吧
练习代码
- 数学流程图代码
题目:
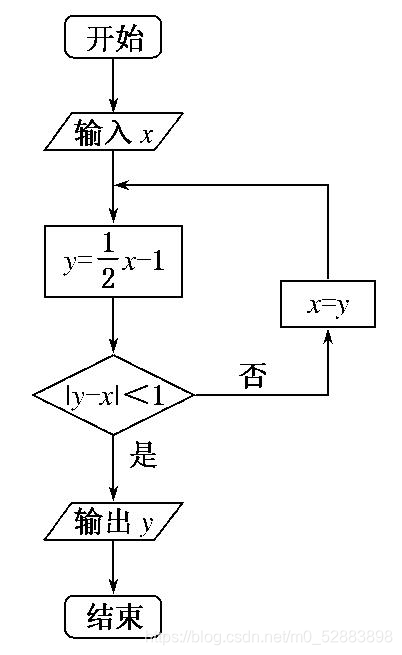
代码:
x = int(input()) # 接收键盘输入的值
while True: # 定义一个循环使判断一直进行,直到满足条件停止y = x/2 - 1 # 给y赋值if abs(y-x)<1: # 判断绝对值之差print(y) # 满足条件打印y值break # 打破循环else: x = y # 不满足就把y的值赋给x
- 题目:99乘法表
代码:
for x in range(9): # 99乘法表,9列,循环9次i = x+1 # 因为x从0开始,所以令x+1# 每行都有数据,且不一样,因此也需要嵌套for y in range(i): # 每行都需要i个结果j = y+1print(f"{i}*{j}={i*j}", end=" ") # 打印每行数据,后面的end=" "实现不换行输出print() # 每行结束换行
- 题目:输入一个数,判断是不是水仙花数
水仙花数,每个位数的三次方之和=本身,例子:153 1**3+5**3+3**3=153
num = input()
# 接收一个字符串
sum = 0
# 表示和
for i in num:x = int(i)y = x**3sum+=y# 将输入的数拆开分别三次方,求和
if sum == int(num):print(num, "是水仙花数!")
else:print(num, "不是水仙花数!")
做不出来也说明不了什么,需要多做练习
高级数据类型
何为高级数据?为何对这种类型冠以高级之名?之前一篇篇也都说过了——基础语法
不过为了凑字数 没看上一篇的小伙伴,还是说一下吧
高级数据类型,就是相比于基本数据类型来说的,因为他们都有着较为复杂的操作,而最为值得说,也是最应该值得掌握的便是增删改查的操作了。当然,相比于基本数据类型一次只能储存一个数据,高级数据类型可以储存更多的数据。
增删改查:增加 删除 修改 查找(查看)
高级数据类型有:字符串(没想到我学编程第一个接触的竟然是高级数据类型)、列表、集合、元组、字典、类(这个暂时不去了解,后面会详细去说,是难点)
1. 字符串
字符串就类似于我们平时说的话,就是字符串在一起,叫做字符串,字符就是一个一个的
1.1 遍历
首先呢,字符串可以遍历取值,也就是可以利用我们的循环来将其中的所有元素,一个一个的展现出来,拿出来,可以进行各种操作
当然别的高级数据类型也都可以遍历,只不过字典会有所区别
代码展示
str_ = "Hello World!"
for i in str_:print(i)
运行结果:

可以看到,循环将我们的字符串拆开一个一个的拿了出来,并且输出
1.2 格式化字符串
什么是格式化字符串?就是可以让我们的代码更加简单
以问题理解
怎么输出一句话,包含变量
例子:给出一个变量a = 1 怎么让输出的结果为:“a的值为:1”
- 第一个方法:print(“a的值为:”, a)
- 第二个方法:print(“a的值为:{}”.format(a))
- 第三个方法:print(“a的值为:%d”%a)
- 第四个方法:print(f"a的值为:{a}")
其实就是让我们的字符串中可以添加变量,而第一种的方法在处理一个字符串中的多个变量时是较为麻烦的,这时候就需要用到下面三个,比较简单,我最喜欢的是第四个方法。因为写出来简单
1.3 原生字符串
原生字符串就是只含字符串,和格式化不同,原生字符串引号里面的所有都是字符串,不会被机器认识成别的
比如我们的转义符\
\t 表示我们的tab \n表示换行
那么怎么定义呢?只需要在字符串前面的括号前加上r就可以了
我们来看看这个代码,结果会是如何
print(r"你好\t世界")
print(r"你好\n世界")
运行结果:

可以看到,我们的转义符并没有什么作用,他被原原本本的表现了出来,这就是我们的原生字符串的作用
关于转义符,我就不多说了,像了解的可以去搜索一下
关于字符串呢,还有更多的操作,比如什么判断是否是数字,判断大小写,转大小写什么的,想了解可以去搜索一下字符串的所有操作,本篇作为入门篇,就不多说那么多了。
2. 列表
list 列表
列表是用中括号括起来的以一组数据
比如说这个 [1, 2, 3, 4, 5,] 就是一个列表
这个就是储存了1-5 五个整型数据的 一个列表
用变量接受一个列表:li = []
作为高级数据类型,列表可以增删改查。
至于遍历,就不说了和字符串是一样的
你也不需要深刻理解,你只需要知道,列表是个袋子,他可以帮助我们存储更多的东西。
而我们也可以通过这个袋子去操作里面的东西,比如上述的增删改查,不就是往袋子里放东西,把袋子里的东西拿出来,把袋子里的东西拿出来换个东西,看看袋子里的东西
2.1 往袋子里放东西
往列表增加元素:li.append()
举例:
li = [1, 2, 3, 4]
li.append(5)
print(li)
结果:[1, 2, 3, 4, 5]
而作为高级数据类型,你可以往列表里面添加一切数据类型
2.2 把袋子里的东西拿出来
删除列表指定元素:li.remove()
举例:
li = [1, 2, 3, 4]
li.remove(1)
print(li)
结果为:[2, 3, 4]
就是把袋子里的1拿了出来,至于放在哪,那肯定是扔了啊。
2.3 把袋子里的东西拿出来换个东西
查找元素:
列表支持查找元素,不过是利用下标查找,python下标从0开始,当然,字符串也支持下标取值
举例:
li = [1, 2, 3, 4]
print(li[0])
结果为:1
既然说到了下表取值,那就说一下切片与步长吧
切片:可以限制取哪些下标范围的数据
步长:几个元素几个元素的取
列表[下标:下表:步长] 1表示正值一个一个取,-1表示倒着取,不写默认为1,2表示隔一个取一次
比如我们只取1,3(不包含3,这里指得也是下标)的元素
a = [1, 2, 3, 4, 5, 6]
print(a[1:3])
# 结果为:[2, 3]
print(a[::2])
# 结果为:[1, 3, 5]
print(a[;;-1])
# 结果为:[6, 5, 4, 3, 2, 1]
看看袋子里的东西
修改元素:
同样,修改元素需要通过下标来实现
举例:
li = [1, 2, 3, 4]
li[0] = 2
print(li)
结果为: [2, 2, 3, 4]
3.集合
集合:set
集合具有无序性,和不可重复性
无序性:没有顺序
当然集合也可以创建一个空集合,但是不能这样创建s = {}
因为这样是定义一个空字典的,我们应该这样set(s)
格式(长什么样):
s = {1, 2, 3, 4, 5}
3.1增加元素
往集合添加元素s.add()ands.update()
s = {1, 2, 3, 4, 5}
s.add(6)
s.upadte(7)
print(s)
结果为: {1, 2, 3, 4, 5, 6, 7}
3.2删除元素
s = {1, 2, 3, 4, 5}
s.remove(1)
print(s)
结果为:{2, 3, 4, 5, 6}
全部删除:s.clear()
3.3 修改元素
没这个功能,因为元素是无序的,没法通过下标查找和修改
也没事,因为你在程序中,用列表和字典比较多
4. 元组
元组与别的不同,他是不可变的,意思就是无法添加,无法修改,无法删除
元组使用小括号定义 tu = (1, 2, 3, 4)
元素之间和列表,集合,字典一样,每组元素之间通过英文逗号,分隔开
可以参考列表,只不过元组和集合一样无法修改,但是并不是因为无序性,元组可以通过下标取值
4.1 查看元组
我们可以直接打印元组,也可通过下标取值,也可以使用切片和步长
tu = (1, 2, 3, 4, 5)
print(tu)
print(tu[0:4:1])
结果:(1, 2, 3, 4, 5)
(1, 2, 3, 4)
4.2 删除
虽然元组是不可变的,但是我们可以直接把整个元组删除
tu = (1, 2, 3, 4, 5)
del tu
print(tu)
结果为:()
5. 字典
为什么把字典返回在最后?因为字典是键值对的形式。
格式:dic = {"key": value}
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
在字典中,通过访问key以得到value
5.1 增加元素
我们可以定义一个空字典,也可以定义一个有元素的
我们会分别举例
空字典:
di = {}
di["name"] = "Tom"
di["age"] = 18
print(di)
结果:{“name”: “Tom”, “age”: 18}
有元素的字典:
di = {"name": "Tom"}
di["age"] = 18
print(di)
结果为:{“name”: “Tom”, “age”: 18}
之所以能用这样的方法,是因为我们的键是唯一的,所以可以通过这种方法添加元素
5.2 删除元素
还是通过唯一的键来确定,然后删除
di = {"name": "Tom", "age": 18}
del di["age"]
print(di)
结果为:{“name”: “Tom”}
5.3 修改元素
通过键来重新赋值以修改元素,我就不多做解释和示范了
5.4 查找元素
查找元素就不能通过下标了,需要通过键来获取
di = {"name": "Tom", "age": 18}
print(di["name"])
结果为:“Tom”
结语
兴趣是最好的老师,坚持是不变的真理。
学习不要急躁,一步一个脚印,踏踏实实的往前走。
每天进步一点点,日积月累之下,你就会发现自己已经变得很厉害了。
我是布小禅,一枚自学萌新,跟着我每天进步一点点吧!
说了这么多暂时也就够了,那么就告辞吧

这篇关于趁着课余时间学点Python(五)用课余时间提升自己关于高级数据类型的知识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





