本文主要是介绍【MIT 6.S081】2020, 实验记录(7),Lab: Multithreading,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Task 1: Uthread: switching between threads
- Task 2:Using threads
- Task 3:Barrier
Task 1: Uthread: switching between threads
这个实验是要求实现用户级线程的创建和调度,有点类似于有栈协程。非常有意思,值得多学习。
在完成这个实验前,需要了解 XV6 如何实现的进程的调度,然后通过在模拟进程切换的逻辑实现用户级线程的创建和切换。
在 kernel 调度进程时,会使用 context 来保存被挂起的进程的寄存器上下文,我们这里也需要一个类似的结构体来保存这些上下文(在 uthread.c 中声明):
// 模仿 kernel/proc.h 中的 struct context
// 保存用户线程的上下文
struct thread_context {uint64 ra;uint64 sp;// callee-saveduint64 s0;uint64 s1;uint64 s2;uint64 s3;uint64 s4;uint64 s5;uint64 s6;uint64 s7;uint64 s8;uint64 s9;uint64 s10;uint64 s11;
};
然后将我们声明的 thread_context 结构体放入 struct thread 中:

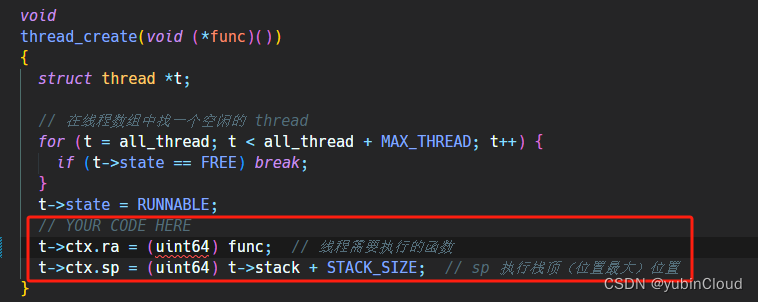
在 thread_create() 中初始化这个字段,让其中的 ra 字段指向线程需要执行的函数(因为线程切换后会执行 ra 寄存器所指向的位置),让其中的栈指针指向合适的位置:
然后模仿 kernel 中用来切换进程的 swtch 函数,实现线程切换时上下文的切换(也就是保存现有的各个寄存器值到 context 中,把新线程的 context 中保存的各个寄存器的值写入寄存器中),函数 thread_switch() 已经声明在了 uthread.c 中,但这部分的实现需要我们模仿 kernel/swtch.S 使用汇编语言实现在 uthread_switch.S 中:
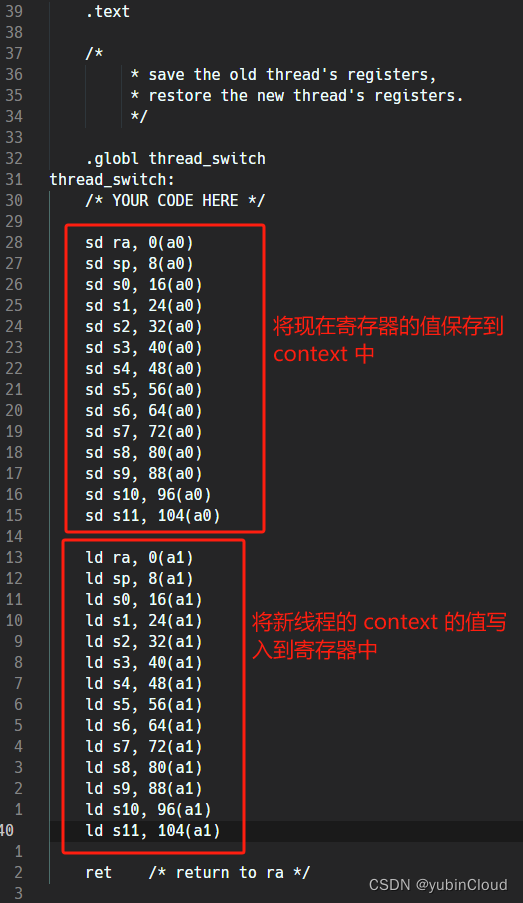
这个最后的 ret 会回到 ra 寄存器所指向的位置,也就是我们想让这个线程所执行的函数。
最后在线程调度的函数中加入 thread_switch() 的调用,参数就是现在线程和新线程的 context 指针:
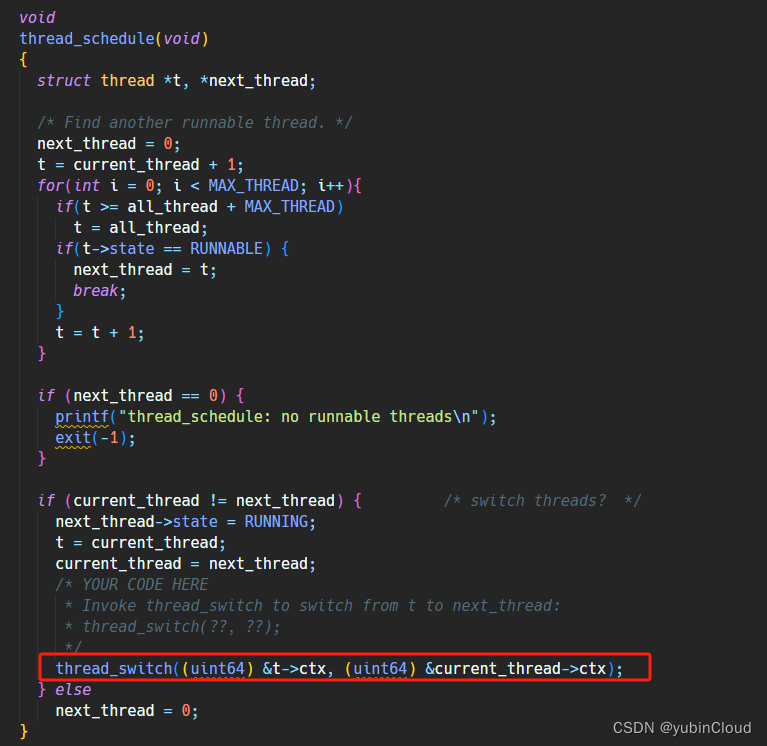
至此,第一个 task 就完成了。
Task 2:Using threads
这个 task 就不是在 xv6 中写代码了,而是使用 Unix 提供的 pthread 及相关工具来实现一个并发安全的 hash map。
最简单的思路就是有一个 lock,每一次对 hash map 的读写都需要先获取这个 lock 再操作。但是这会存在效率问题,因为一个 map 有很多 buckets,而大多数情况下两个线程同时写 hash map 时涉及的 buckets 并没有关联。为了解决这个问题,可以让每个 bucket 都关联一个 lock,需要访问一个 bucket 时就需要先获取这个 bucket 所关联的 lock。
首先声明 locks,锁的数量与 bucket 的数量相同:
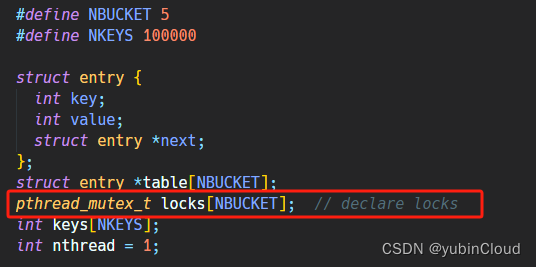
然后初始化 locks:
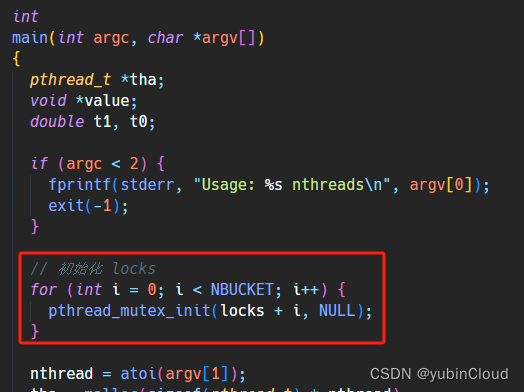
然后在 hash map 的 get 和 put 函数操作内加锁。
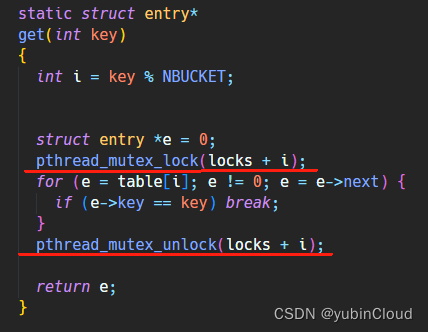
get 函数中,首先计算出在 entry 哪个 bucket 中,然后对这个 bucket 相关联的 lock 上锁,操作完成后再解锁:
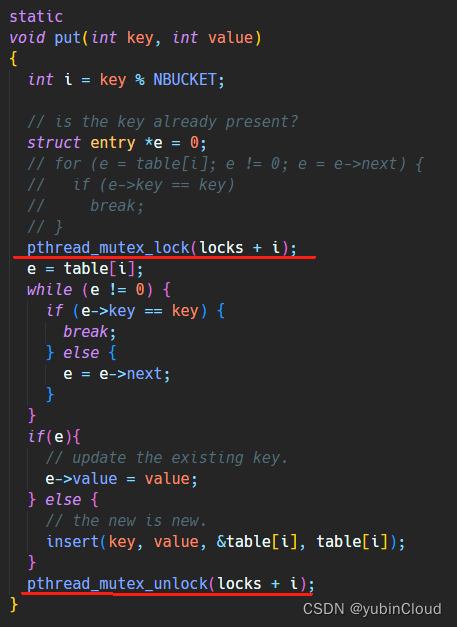
put 函数也是类似:
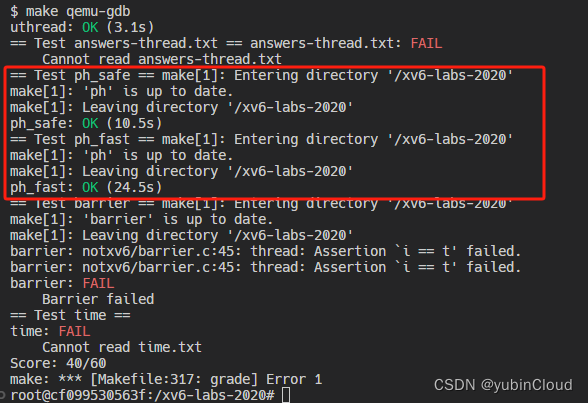
上面完成后,这个 task 就通过了:
Task 3:Barrier
最后一个 task 的难度也不大,主要考察 pthread 中条件变量的使用,task 是实现 barrier() 函数,一共有 n 个进程,每个进程调用了 barrier() 后会等待,直到所有 n 个进程都调用了 barrier() 后才能继续进行下去。
实现难度不大,利用好 mutex 和 cond 就行:
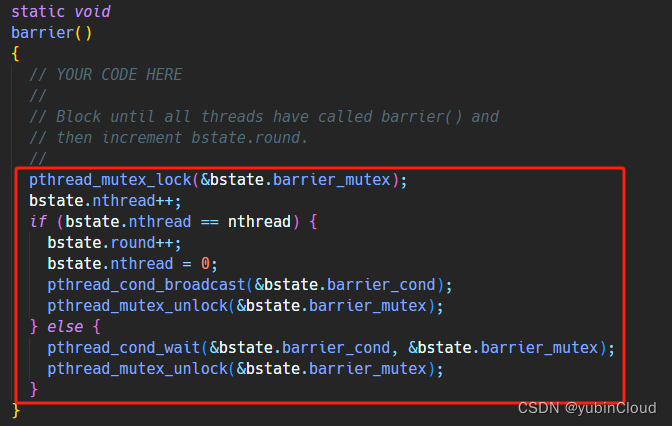
实现好这个函数后,就可以通过测试了。

这篇关于【MIT 6.S081】2020, 实验记录(7),Lab: Multithreading的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






