本文主要是介绍【论文速读】| DeepGo:预测式定向灰盒模糊测试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本次分享论文为:DeepGo: Predictive Directed Greybox Fuzzing
基本信息
原文作者:Peihong Lin, Pengfei Wang, Xu Zhou, Wei Xie, Gen Zhang, Kai Lu
作者单位:国防科技大学计算机学院
关键词:Directed Greybox Fuzzing, Path Transition Model, Reinforcement Learning, Deep Neural Networks
原文链接:
https://www.ndss-symposium.org/wp-content/uploads/2024-514-paper.pdf
开源代码:
https://gitee.com/paynelin/DeepGo
论文要点
论文简介:本文提出了一种名为DeepGo的预测式定向性灰盒模糊测试方法,通过结合历史和预测信息,利用深度神经网络和强化学习技术,有效地引导模糊测试达到目标路径,优化测试效率。
研究背景:定向性灰盒模糊测试(DGF)是一种高效的代码测试技术,通过定义可测量的适应性指标,选取潜在的种子进行变异,以逐渐接近目标站点。然而,现有的DGF技术主要依赖于启发式算法进行适应性指标的优化,缺乏对未执行路径的预见性。
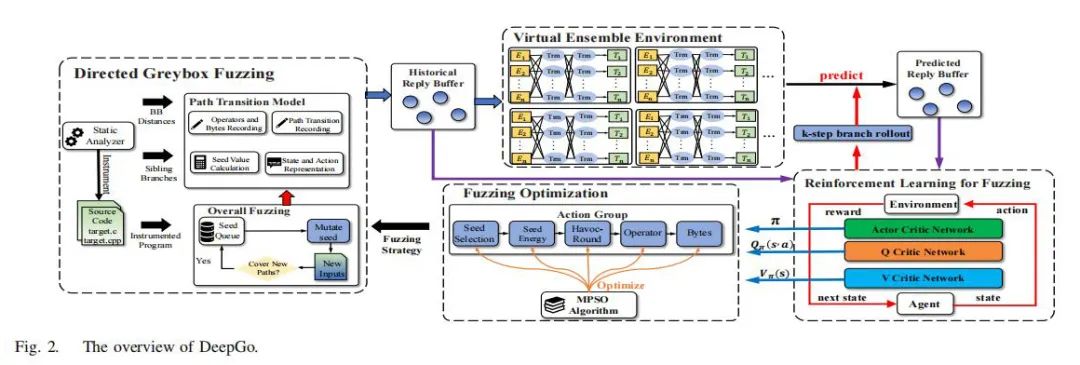
研究贡献:
a.提出了路径转换模型,将DGF视为通过特定路径转换序列达到目标站点的过程,并使用序列奖励作为适应性指标。
b.构建了虚拟集成环境(VEE)使用深度神经网络(DNNs)来模仿路径转换模型并预测潜在路径转换及其对应的奖励。
c.开发了一种强化学习模糊测试(RLF)模型,结合历史和预测的路径转换来生成最优路径转换序列。
d.通过行为群组的概念综合优化模糊测试的关键步骤,提高了测试效率。
引言
DeepGo的研究背景基于现有定向性灰盒模糊测试(DGF)技术的局限性,特别是在优化适应性指标时的缺乏预见性和效率低下的问题。通过引入路径转换模型、虚拟集成环境(VEE)、强化学习模糊测试(RLF)模型和行为群组优化策略,DeepGo能够预测和优化模糊测试过程,实现更高效和精确的测试目标达成。
背景知识
研究讨论了定向性灰盒模糊测试的基本概念、深度神经网络在模拟程序分支行为中的应用、强化学习在序列决策问题解决中的作用、基于模型的策略优化和粒子群优化算法在提高模糊测试效率中的应用。
论文方法
理论背景:通过深入分析DGF的限制,提出一种新的模型——路径转换模型,使用序列奖励作为新的适应性指标。
方法实现:
a.虚拟集成环境(VEE):利用深度神经网络模仿路径转换模型,预测未执行路径的潜在转换及其奖励。
b.强化学习模糊测试(RLF)模型:结合历史和预测信息,优化路径选择策略,生成最优路径转换序列。
c.行为群组优化:通过多元素粒子群优化算法同时优化模糊测试的关键步骤,提高测试效率。
实验
实验设置:在两个基准测试套件上评估DeepGo,包含25个程序和100个目标站点。
实验结果:DeepGo与现有技术相比,在达到目标站点和暴露已知漏洞方面显示出显著的速度提升,证明了其预测能力和效率。
论文结论
DeepGo通过引入路径转换模型、虚拟集成环境(VEE)、强化学习模糊测试(RLF)模型和行为群组优化策略,显著优化了定向性灰盒模糊测试的效率和精度。实验结果证明了DeepGo在提高目标站点达成速度和暴露已知漏洞方面的优势,为未来的模糊测试技术发展提供了新的方向。
原作者:论文解读智能体
润色:Fancy
校对:小椰风

这篇关于【论文速读】| DeepGo:预测式定向灰盒模糊测试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






