本文主要是介绍Solr4.0的tomcat部署及Solrj的简单使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文地址:http://www.huqiwen.com/2012/12/03/solr4-tomcat-deploy-and-how-to-use-solrj/
Solr简介
Solr是一个非常流行的,高性能的开源企业级搜索引擎平台,属于Apache Lucene项目。主要功能包括强大的全文检索、结果高亮、切面检索、动态聚类、数据库整合、富文本(例如Word,PDF)的处理,以及地理信息搜索。Solr是高度可扩展的,提供分布式检索和索引复制,并为世界上众多的大型网站提供搜索和导航功能。
Solr使用Java编写,可运行于servlet容器(如Tomcat)作为一个独立的全文搜索服务器。Solr以Lucene 为核心来创建索引和进行搜索,并提供类似REST的HTTP / XML和JSON API,这些API可以在任何编程语言中使用。通过Solr强大的扩展配置可适应几乎任何类型非Java编写应用程序,同时拥有丰富的插件来扩展高级功能。
Solr特性
- 先进的全文检索功能
- 专为高通量的网络流量进行的优化
- 基于标准的开放接口 - XML,JSON和HTTP
- 综合的HTML管理界面
- 暴露JMX接口以方便监控服务器统计
- 可扩展性 - 有效地复制到其他Solr搜索服务器
- 使用XML配置达到灵活性和适配性
- 可扩展的插件体系结构
Solr使用Lucene并进行了扩展
- 一个真正的拥有动态域(Dynamic Field)和唯一键(Unique Key)的数据模式(Data Schema)
- 对Lucene的查询语言进行了强大的扩展
- 切面搜索和过滤
- 地理空间信息搜索
- 先进的,可配置的文本分析
- 高度可配置、可扩展的缓存机制
- 性能优化
- 支持通过XML配置
- 提供管理界面
- 可监控日志记录
- 支持高速增量式更新(Fast incremental Updates)和快照发布(Snapshot Distribution)
- 高度可扩展的分布式搜索,片式指数在多台主机
- JSON,XML,CSV /分隔的文本和二进制更新格式
- 使用简单的方法即可从数据库、XML文件数据、本地磁盘、HTTP等来源获取数据
- 基于Apache Tika对富文本进行解析和索引(PDF,WORD,HTML等)
- Apache UIMA集成的可配置的元数据提取
- 支持多个搜索索引
以上的介绍翻译自:http://lucene.apache.org/solr/。大概的翻译,如有错误欢迎指出。
Solr的运行
从Solr的官方网站上下载的Solr包里面有一个基于jetty的示例运行环境。下载Solr包,打开里面的example目录,点击里面的start.jar。在浏览器里面输入http://localhost:8983/solr,可以看到如下界面。
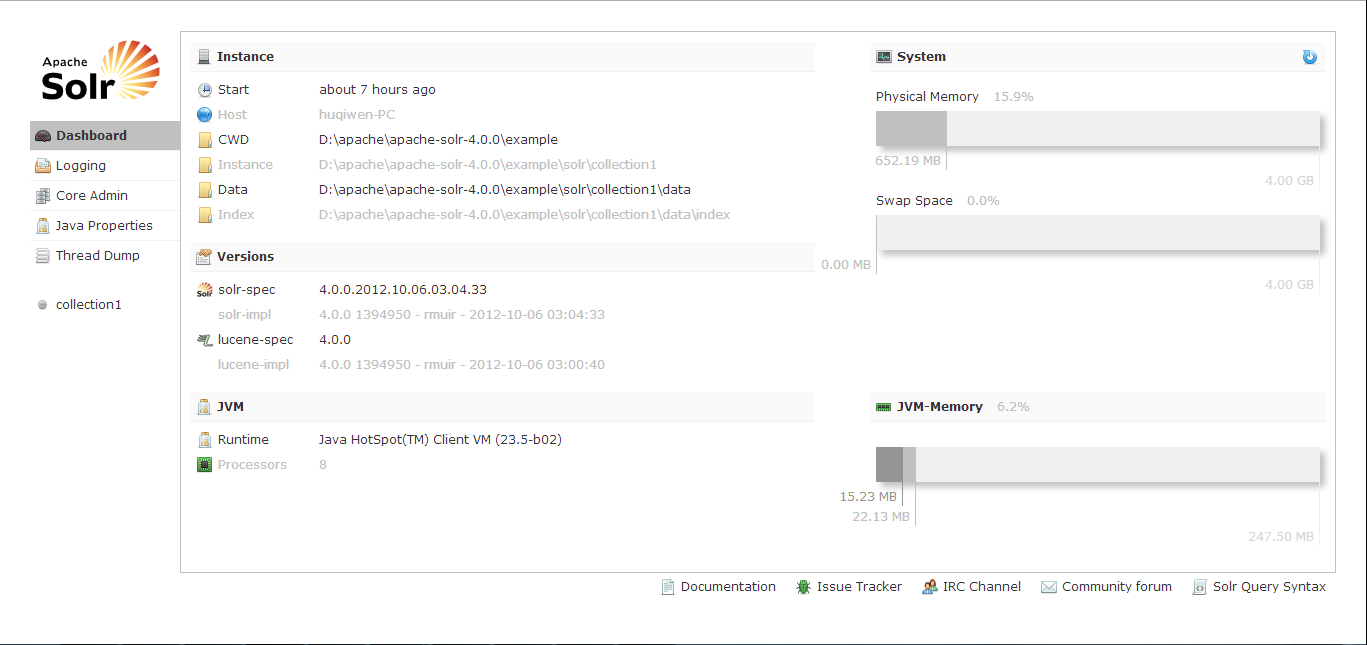
以上是Solr管理控制台的主页,左边是导航。可以使用http://localhost:8983/solr/#/collection1/query进行查询结果的查看。这里提供的是一个方便示例界面。现在应该是没有数据的,因为没有向里面添加索引。可以使用solr提供的post.jar包进行简单的索引添加。这里不再介绍此方法,后面使用Solrj进行操作。具体的可以查看Solr目录下面的/docs/tutorial.html文档。
在Tomcat中部署Solr
上面的运行是Solr默认绑定的一个jetty,如果需要在tomcat中运行solr,方法如下:
1、将Solr/dist/apache-solr-4.0.0.war此war包复制到tomcat的webapps目录下面,并重命名成solr。
2、点击tomcat/bin/startup.bat运行tomcat,这时tomcat会解压solr.war包到webapps目录下面。看到控制台里面会有报错提示,是找不到solr的实例运行环境。这时关闭tomcat。
3、删除webapps目录下面的solr.war包。将下载的solr目录下面的example下面的solr目录复制到tomcat的webapps/solr下面。下面的目录结构大概是这样的webapps/solr/solr/collection1类似这样的。
4、打开webapps/solr/WEB-INF/web.xml文件,在里面添加如下内容。env-entry-value这个目录是指向上一个步骤中的目录。这里使用的是相对目录(相对于tomcat的bin目录),也可以使用绝对路径,如d:/solr等。步骤3中的目录不一定要位于tomcat中,只要此步骤中将路径配置正确即可。
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>../webapps/solr/solr</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>5、再次运行tomcat,输入http://localhost:8080/solr即可访问在tomcat中运行的solr环境。
使用Solrj操作Solr
从上面的步骤中可以看出Solr提供了一个企业搜索引擎平台的核心,可以通过他的接口进行索引的创建、修改、删除。并提交关键字进行搜索。但如果要真正的投入使用,还是有不和工作需要做,如:
1、对向Solr提交索引进行一定的封装以方便业务系统进行操作
2、对搜索进行封装,以方便结果的展现分析等等。
Solrj是使用java编写的一个操作Solr的工具,方便于进行索引的更新、搜索结果的获取等等。
在Solr的发布包里面有Solrj的相关jar包。Solrj需要的jar包为:
apache-solr-solrj-4.0.0.jar和他的依赖包solr/dist/solrj-lib
如果是使用maven,可以添加:
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>4.0.0</version>
</dependency>使用Solrj更新索引
使用Solrj是首先我们实例化一个SolrServer,这里使用HttpSolrServer。我们再创建一个SolrInputDocument以方便来添加要索引的数据。这里的Field是在\solr\solr\collection1\conf\schema.xml里面定义的,如果里面没有定义的字段在这里是不能添加的,除非是使用动态字段。示例代码如下:
String url = "http://localhost:8080/solr";
SolrServer server = new HttpSolrServer(url);
SolrInputDocument doc1 = new SolrInputDocument();
doc1.addField("id", "1");
doc1.addField("title", "云南xxx科技");
doc1.addField("cat", "企业信息门户,元数据,数字沙盘,知识管理");
SolrInputDocument doc2 = new SolrInputDocument();
doc2.addField("id", "2");
doc2.addField("title", "胡启稳");
doc2.addField("cat", "知识管理,企业信息门户,云南,昆明");
SolrInputDocument doc3 = new SolrInputDocument();
doc3.addField("id", "3");
doc3.addField("title", "liferay");
doc3.addField("test_s", "这个内容能添加进去么?这是动态字段呀");
List<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
docs.add(doc1);
docs.add(doc2);
docs.add(doc3);
server.add(docs);
server.commit();到此就添加了三个document到solr的索引库里面。下面介绍如何进行搜索。
使用Solrj进行搜索
搜索的第一步和上面一样,先取得一个SolrServer。然后创建一个SolrQuery进行搜索,搜索取得的数据已经封装在QueryResponse里面,通过相关API获取结果数据。示例代码如下:
String url = "http://localhost:8080/solr";
SolrServer server = new HttpSolrServer(url);
SolrQuery query = new SolrQuery("云南");
try {QueryResponse response = server.query(query);SolrDocumentList docs = response.getResults();System.out.println("文档个数:" + docs.getNumFound()); System.out.println("查询时间:" + response.getQTime());
for (SolrDocument doc : docs) { System.out.println("id: " + doc.getFieldValue("id")); System.out.println("name: " + doc.getFieldValue("title")); System.out.println(); }这篇关于Solr4.0的tomcat部署及Solrj的简单使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






