本文主要是介绍Java集合详解(单列集合 | 双列集合 | Collections集合工具类),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
○ 前言:
- 在开发实践中,我们需要一些能够动态增长长度的容器来保存我们的数据,java中为了解决数据存储单一的情况,java中就提供了不同结构的集合类,可以让我们根据不同的场景进行数据存储的选择,如Java中提供了 数组实现的集合,链表实现的集合,哈希结构,树结构等。
体系图
○ Java中的集合体系如图:
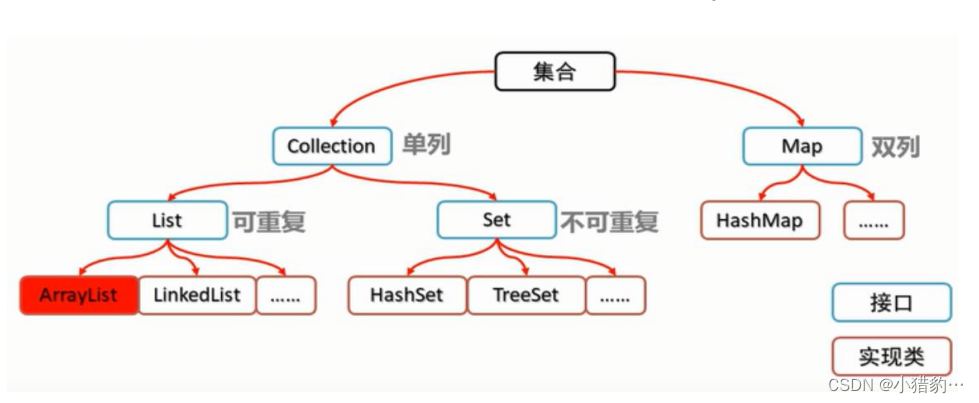
○ 集合的分类:
• 集合可以分为单列集合和双列集合.
单列集合
● Collection接口定义了单列集合共有的方法,其子接口Set和List分别定义了存储方式。
● List接口继承了Collection接口,有三个实现的类,分别是:ArrayList (数组列表) | LinkedList
(链表列表) | Vector 数组列表 (且线程安全).
● Set接口继承了Collection接口,有两个实现的类,分别是:HashSet | TreeSet .
○ 区别:
• List:可以有重复元素 • Set:不可以有重复元素
List 接口的实现类
● ArrayList
• 底层有一个数组,可以动态扩展数组长度 ; 查询快,在中间增加 / 删除慢.(特点)
• 常用方法:
ArrayList<String> s=new ArrayList<>();s.add("a");s.add("b");s.add("c");s.add("d");System.out.println(s.get(2));//根据索引得到指定位置的元素s.remove(0);//删除并返回指定位置的元素System.out.println(s);s.set(0,"X");//替换指定元素并返回数组System.out.println(s);s.size();System.out.println(s.size());//返回实际元素个数s.addFirst("X");s.addLast("X");● LinkedList
• 底层是一个链表结构 ; 查询慢,但增加 / 删除元素快(特点)
○ 我们发现ArrayList和LinkedList的特点正好相反,原因如图:

● Vector
• 和ArrayList一样,底层也是数组实现,不同的是Vector的方法默认加了锁,线程是安全的。
Set 接口及实现类
○ 特点:
• Set中所储存的元素是不重复的,无序的,且Set中的元素没有索引。
• 由于Set中元素无索引,所有其实现类中没有get() [通过索引获取指定位置元素] 并且不能通过for 循环进行遍历。
● HashSet
• HashSet 是一个不允许有重复元素的集合,是无序的,不是线程安全的。
public static void main(String[] args) {HashSet set =new HashSet<>();set.add("a");set.add("a");set.add("b");set.add("c"); //元素是不重复的System.out.println(set);//输出:[a,b,c]HashSet set1 =new HashSet<>();set1.add("c");set1.add("s");set1.add("x");set1.add("d"); //元素是无序的System.out.println(set1);//输出:[c,s,d,x]}
★ HashSet在添加元素时,是如何判断元素重复的? (面试高频题)
- 在底层会先调用hashCode(),注意,Object中的hashCode()返回的是对象的地址,此时并不会调用;此时调用的是类中重写的hashCode(),返回的是根据内容计算的哈希值,遍历时,会用哈希值先比较是否相等,会提高比较的效率;但哈希值会存在问题:内容不同,哈希值相同;这种情况下再调equals比较内容,这样既保证效率又确保安全。
● TreeSet
• TreeSet可以根据值进行排序,底层使用了树形结构,树结构本身就是有序的。
TreeSet<Integer> treeSet =new TreeSet<>();treeSet.add(2);treeSet.add(1);treeSet.add(4);treeSet.add(4);treeSet.add(3);System.out.println(treeSet);//输出[1,2,3,4]★ 向树形结构中添加元素时,如何判断元素大小以及元素是否重复?
• 向TreeSet中添加的元素类型必须实现Comparable接口,重写compareTo() ; 每次添加元素时,调 用compareTo()进行元素大小判断 (小于0放左子结点,等于0表示重复,大于0放右子节点)
○ TreeSet集合的遍历只能通过 增强for循环 和 迭代器(Iterator) 遍历. (元素没有索引)
双列集合
特点:
○ 数据存储是以 ( 键,值 ) 形式存储
○ 键不能重复,值可以重复。
○ 通过键找到值,一个键只能映射到一个值。
○ 键和值被称为键值对,java中叫Entry对象
Map接口的实现类
● HashMap
○ HashMap中的键是无序的
//可以存储两组值(键K,值V)HashMap<String,String> map =new HashMap<>();map.put("a","aa"); //put() 向map中添加一组键 值对map.put("w","ww");map.put("c","cc");map.put("s","ss");map.put("a","aaa"); /* 替代之前的键a */System.out.println(map); //键是无序的输出:{a=aaa, c=cc, s=ss, w=ww}
○ 常用方法:
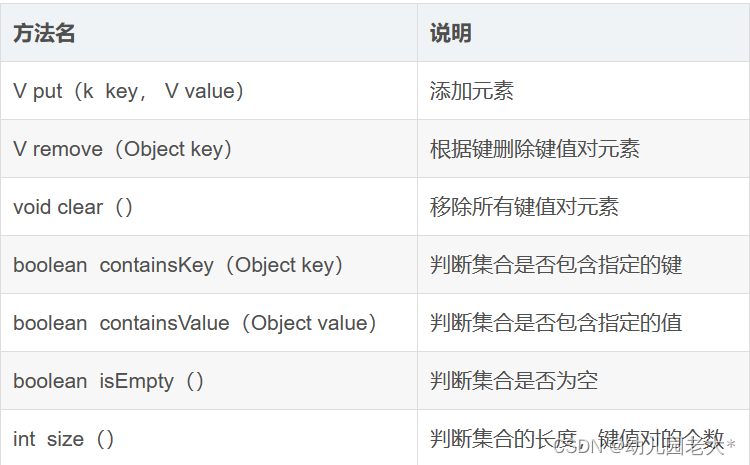
○ 代码实现:
//常用方法HashMap<String,String> map =new HashMap<>();map.put("a","aa"); //put() 向map中添加一组键 值对map.remove("a"); //删除指的的键,返回对应的值map.clear(); //清空键值对map.isEmpty(); //判断键值对的个数是否为空map.containsKey("a"); //是否含对应键map.containsValue("aaa");//是否含对应值map.get("s"); //传键返值map.size(); //有几组键值对★ HashMap底层存储数据的结构 : (面试高频题)
○ 底层使用了一个长度默认为16的哈希数组,用来确定元素的位置,每次用key计算出哈希值,再 用哈希值%数组长度确定元素位置,将元素放在哈希表中指定的位置。
○ 后来继续添加元素,如果出现位置相同且不重复的元素,那么将后来元素添加到之前元素的next 节点。
○ 当链表长度等于8且哈希数组的长度大于64时链表会自动转为红黑树。
补充: 哈希表负载因子为0.75 , 当哈希表使用数组的0.75倍时会自动扩容为原来数组长的2倍。
● TreeMap
○ 底层使用树形结构存储键值
○ 键可以排序
○ 键元素类型必须实现Comparable接口,重写compareTo()
注意: TreeMap和TreeSet一样,底层都是红黑树结构
● Hashtable
○ 底层实现也是用到key的哈希值计算位置判断元素是否重复。
○ 方法上都添加了synchronized,线程是安全的。
HashMap和Hashtable的区别:
● Hashtable中不能存储为null的键和为null值,但HashMap中可以。
HashMap<Integer,String> map =new HashMap<>();map.put(1,"a");map.put(2,null);map.put(null,null);System.out.println(map); //输出:{null=null, 1=a, 2=null}Hashtable<String,String> table =new Hashtable<>();table.put(null,"a"); //报错 System.out.println(table);Collections类
概述:Collections是集合类的工具类,与数组的工具类Arrays类似.
常用方法:
1. sort(Comparator<? super E>):void List
对集合中的元素排序。
2.reverse(List<?>):void
反转集合中的元素。
3.shuffle(List<?>):void
打乱元素中的元素。
4.fill(List<? super T>,T):void
用T元素替换掉集合中的所有的元素。
5.copy(List<? super T>,List<? extend T>):void
复制并覆盖相应索引的元素
6.swap(List<?>,int,int):void
交换集合中指定元素索引的位置.
7.replaceAll(List,T,T):boolean
替换成指定的元素。
代码演示:
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;public class collections {public static void main(String[] args) {ArrayList<Integer> list =new ArrayList<>();list.add(1);list.add(2);/* addAll(Collection<? super T> c, T... elements); */Collections.addAll(list,3,4,5,6);//将指定的可变长度参数添加到指定集合中System.out.println(list);Collections.sort(list); //排序(默认升序)System.out.println("升序:"+list);//Collections.binarySearch() 二分查找System.out.println(Collections.binarySearch(list,5));//二分查找//创建了一个实现Comparator接口的匿名内部类对象,省去了创建一个类简化语法Collections.sort(list, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2.intValue()- o1.intValue(); //降序}});System.out.println("降序:"+list);ArrayList<Integer> list1 =new ArrayList<>();Collections.addAll(list1,1,2,3,4);Collections.fill(list1,5);System.out.println(list1);Collections.replaceAll(list1,5,6);// Collections.swap(list,0,1);//交换指定位置上元素//System.out.println(list); // 2134//copy(list2,list1) 集合复制 目标集合size > 原集合size//fill(list,v)用指定的值填充集合//max / min//replaceAll//reverse 逆序//Collections.shuffle(list); 随机排序}
}
这篇关于Java集合详解(单列集合 | 双列集合 | Collections集合工具类)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






