本文主要是介绍wy的leetcode刷题记录_Day84,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
wy的leetcode刷题记录_Day84
声明
本文章的所有题目信息都来源于leetcode
如有侵权请联系我删掉!
时间:2024-3-10
前言
目录
- wy的leetcode刷题记录_Day84
- 声明
- 前言
- 299. 猜数字游戏
- 题目介绍
- 思路
- 代码
- 收获
- 430. 扁平化多级双向链表
- 题目介绍
- 思路
- 代码
- 收获
- 445. 两数相加 II
- 题目介绍
- 思路
- 代码
- 收获
- 面试题 02.01. 移除重复节点
- 题目介绍
- 思路
- 代码
- 收获
- 1171. 从链表中删去总和值为零的连续节点
- 题目介绍
- 思路
- 代码
- 收获
- 283. 移动零
- 题目介绍
- 思路
- 代码
- 收获
- 11. 盛最多水的容器
- 题目介绍
- 思路
- 代码
- 收获
- 15. 三数之和
- 题目介绍
- 思路
- 代码
- 收获
299. 猜数字游戏
今天的每日一题是:
299. 猜数字游戏
题目介绍
你在和朋友一起玩 猜数字(Bulls and Cows)游戏,该游戏规则如下:
写出一个秘密数字,并请朋友猜这个数字是多少。朋友每猜测一次,你就会给他一个包含下述信息的提示:
- 猜测数字中有多少位属于数字和确切位置都猜对了(称为 “Bulls”,公牛),
- 有多少位属于数字猜对了但是位置不对(称为 “Cows”,奶牛)。也就是说,这次猜测中有多少位非公牛数字可以通过重新排列转换成公牛数字。
给你一个秘密数字 secret 和朋友猜测的数字 guess ,请你返回对朋友这次猜测的提示。
提示的格式为 “xAyB” ,x 是公牛个数, y 是奶牛个数,A 表示公牛,B 表示奶牛。
请注意秘密数字和朋友猜测的数字都可能含有重复数字。
示例 1:
输入:secret = “1807”, guess = “7810”
输出:“1A3B”
示例 2:
输入:secret = “1123”, guess = “0111”
输出:“1A1B”
注意,两个不匹配的 1中,只有一个会算作奶牛(数字猜对位置不对)。通过重新排列非公牛数字,其中仅有一个 1 可以成为公牛数字。
思路
第一个想到的就是用哈希表来解决,主要思路就是:首先将secret和guess中同时存在的字符串(不管位置是否相同)算出来b,最后枚举secret和guess找到位置相同元素也相同的数目a,最后b-a就是位置不同但元素相同的个数。
代码
class Solution {
public:string getHint(string secret, string guess) {int n=secret.size();int a_num=0;int b_num=0;unordered_map<char,int> hash;for(int i=0;i<n;i++){if(!hash.count(secret[i]))hash[secret[i]]=1;else{ if(hash[secret[i]]<0){b_num++;} hash[secret[i]]++;}if(!hash.count(guess[i]))hash[guess[i]]=-1;else{ if(hash[guess[i]]>0){b_num++;} hash[guess[i]]--;}}for(int i=0;i<n;i++){if(secret[i]==guess[i]){a_num++;}}b_num=b_num-a_num;string ans=to_string(a_num)+"A"+to_string(b_num)+"B";return ans;}
};
收获
哈希表的应用
430. 扁平化多级双向链表
430. 扁平化多级双向链表
题目介绍
你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一个或多个自己的子列表,以此类推,以生成如下面的示例所示的 多层数据结构 。
给定链表的头节点 head ,将链表 扁平化 ,以便所有节点都出现在单层双链表中。让 curr 是一个带有子列表的节点。子列表中的节点应该出现在扁平化列表中的 curr 之后 和 curr.next 之前 。
返回 扁平列表的 head 。列表中的节点必须将其 所有 子指针设置为 null 。
示例 1:
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:输入的多级列表如上图所示。 扁平化后的链表如下图:
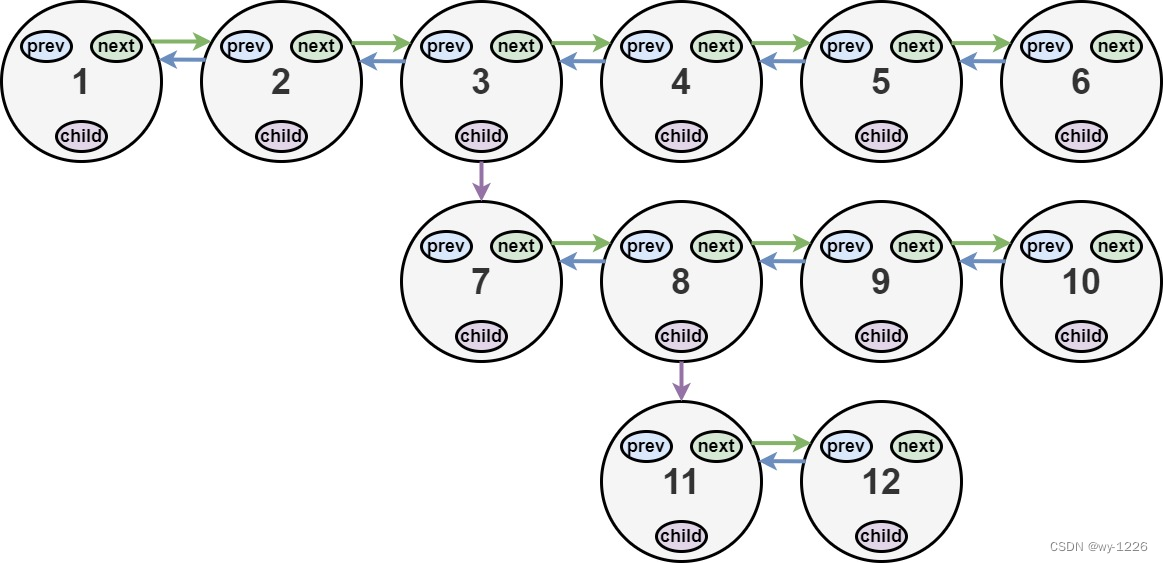

示例 2:
输入:head = [1,2,null,3]
输出:[1,3,2]
解释:输入的多级列表如上图所示。 扁平化后的链表如下图:
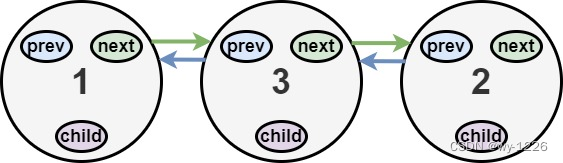
示例 3:
输入:head = []
输出:[]
说明:输入中可能存在空列表。
思路
DFS:本题旨在将child插入在当前节点与下一节点的中间,因此我们需要当前节点和下一节点以及子链头节点以及子链的尾节点。具体细节如下:当前节点无child的时那么继续向下遍历;当前节点有child时,那么通过dfs也就是当前函数继续寻找child的下一个节点(若中途也有child则继续child)直至尾节点,最后连接。
代码
/*
// Definition for a Node.
class Node {
public:int val;Node* prev;Node* next;Node* child;
};
*/class Solution {
public:Node* dfs(Node* head){Node* cur=head;Node* last=nullptr;while(cur){Node* nextt=cur->next;if(cur->child){Node* child_last=dfs(cur->child);cur->next=cur->child;cur->child->prev=cur;if(nextt){child_last->next=nextt;nextt->prev=child_last;}cur->child=nullptr;last=child_last;}else{last=cur;}cur=nextt;}return last;}Node* flatten(Node* head) {dfs(head);return head;}};
先序遍历
/*
// Definition for a Node.
class Node {
public:int val;Node* prev;Node* next;Node* child;
};
*/class Solution {
public:Node* flatten(Node* head) {//BFSNode* newHead=head;// if(head==nullptr)// return head;for (; head;head = head->next) {if(head->child){Node* node=head;//记录当前节点Node* nexxt=head->next;if(nexxt) nexxt->prev=nullptr;head->next=head->child;head->child->prev=head;head->child=nullptr;while(node->next){node=node->next;}node->next=nexxt;if(nexxt){ nexxt->prev=node;}}}return newHead;}};
收获
DFS在链型树上的应用
445. 两数相加 II
445. 两数相加 II
题目介绍
给你两个 非空 链表来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
你可以假设除了数字 0 之外,这两个数字都不会以零开头。
示例1:
输入:l1 = [7,2,4,3], l2 = [5,6,4]
输出:[7,8,0,7]
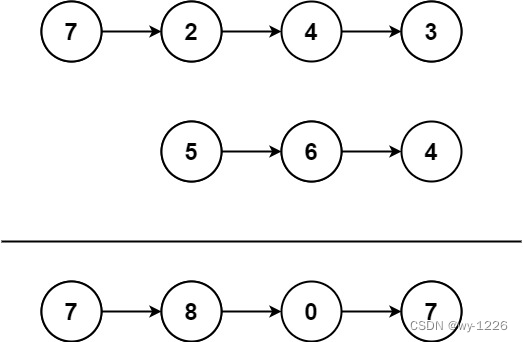
示例2:
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[8,0,7]
示例3:
输入:l1 = [0], l2 = [0]
输出:[0]
思路
方法一:先将两个链表反转,最后相加,使用一个用头插法建立的新链表来保存。细节:每10进1,使用一个flag来表示是否需要进位,最高位进位需要单独判断。(ps:我写的巨丑的代码)
方法二:题解用的两个栈,先将两个链表元素分别入栈,然后出栈一一相加。其中细节做的比我好太多了:对于进位的处理使用carry=(a+b+carry)/10来判断(不需要用flag,其实计组里面的加法器也讲过这样的逻辑结构),其次在循环内部就判断了较长和较短在遍历完相同长度剩下多余长度时的情况。
代码
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* reverse(ListNode* head){ListNode* pre=nullptr;while(head){ListNode* next=head->next;head->next=pre;pre=head;head=next;}return pre;}ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {l1=reverse(l1);l2=reverse(l2);ListNode* head=new ListNode(0);int flag=0;//将长度相等的部分先加起来while(l1!=nullptr&&l2!=nullptr){ListNode* node=new ListNode(0);node->val=l1->val+l2->val;if(flag==1){flag=0;node->val=node->val+1;}if(node->val>=10){flag=1;node->val=node->val%10;}l1=l1->next;l2=l2->next;node->next=head->next;head->next=node;}//统一判断l1if(l2)l1=l2;//剩余部分加起来while(l1){ListNode* node=new ListNode(l1->val); if(flag==1){flag=0;node->val=node->val+1;}if(node->val>=10){flag=1;node->val=node->val%10;}l1=l1->next;node->next=head->next;head->next=node;}//最高位的进位情况if(flag==1){ListNode* node=new ListNode(1); node->next=head->next;head->next=node;}return head->next;}
};
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {stack<int>s1,s2;while(l1){s1.push(l1->val);l1=l1->next;}while(l2){s2.push(l2->val);l2=l2->next;}ListNode* head=new ListNode(0);int carry=0;while(!s1.empty()|| !s2.empty()||carry!=0){int a=s1.empty()?0:s1.top();int b=s2.empty()?0:s2.top();if(!s1.empty()) s1.pop();if(!s2.empty()) s2.pop();int cur=a+b+carry;carry=cur/10;cur%=10;ListNode* node=new ListNode(cur);node->next=head->next;head->next=node;}return head->next;}
};
收获
自己写的话巩固了反转链表以及对两个链表进行操作的熟练度,看了题解后发现,像这种反向或者从底部开始的操作可以使用栈来操作。
面试题 02.01. 移除重复节点
面试题 02.01. 移除重复节点
题目介绍
编写代码,移除未排序链表中的重复节点。保留最开始出现的节点。
示例1:
输入:[1, 2, 3, 3, 2, 1]
输出:[1, 2, 3]
示例2:
输入:[1, 1, 1, 1, 2]
输出:[1, 2]
思路
方法一:遍历链表时使用哈希表来保存已经出现过的元素,如果出现重复的则删掉,否则加入哈希表。
方法二:来自题解中的挑战部分,不适用额外空间来记录,但是需要提升时间复杂度。使用双重循环枚举元素,外层循环枚举需查重的元素,内层循环进行遍历,若相同则删除。
代码
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution {
public:ListNode* removeDuplicateNodes(ListNode* head) {ListNode* newHead=head;ListNode* pre=nullptr;unordered_map<int,int> hash;while(head){if(!hash.count(head->val)){hash[head->val]=1;pre=head;head=head->next;}else{pre->next=head->next;head=head->next;}}return newHead;}
};
class Solution {
public:ListNode* removeDuplicateNodes(ListNode* head) {ListNode* ob = head;while (ob != nullptr) {ListNode* oc = ob;while (oc->next != nullptr) {if (oc->next->val == ob->val) {oc->next = oc->next->next;} else {oc = oc->next;}}ob = ob->next;}return head;}
};收获
简单题
1171. 从链表中删去总和值为零的连续节点
1171. 从链表中删去总和值为零的连续节点
题目介绍
给你一个链表的头节点 head,请你编写代码,反复删去链表中由 总和 值为 0 的连续节点组成的序列,直到不存在这样的序列为止。
删除完毕后,请你返回最终结果链表的头节点。
你可以返回任何满足题目要求的答案。
(注意,下面示例中的所有序列,都是对 ListNode 对象序列化的表示。)
示例 1:
输入:head = [1,2,-3,3,1]
输出:[3,1]
提示:答案 [1,2,1] 也是正确的。
示例 2:
输入:head = [1,2,3,-3,4]
输出:[1,2,4]
示例 3:
输入:head = [1,2,3,-3,-2]
输出:[1]
思路
前缀和+Hash:为了确保某一连续的子串满足某种条件我们一般使用前缀和。本题我们以前缀和为key,对于的value为node,二次遍历链表时重新计算前缀和,并以此为key在hash表中寻找,寻找到的就是对应子串和为0的末尾节点。
代码
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* removeZeroSumSublists(ListNode* head) {ListNode* newHead=new ListNode(0,head);int sum=0;unordered_map<int,ListNode*> hash;head=newHead;while(head){sum+=head->val;hash[sum]=head;head=head->next;}sum=0;head=newHead;while(head){sum+=head->val;head->next=hash[sum]->next;head=head->next;}return newHead->next;}
};
收获
熟练了前缀和的应用
283. 移动零
283. 移动零
题目介绍
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
输入: nums = [0,1,0,3,12]
输出: [1,3,12,0,0]
示例 2:
输入: nums = [0]
输出: [0]
思路
方法一:使用两个指针,a指针用来寻找0,b指针用来寻找1。这里非0值我统称为1
- 若a寻找到0,b寻找到1那么交换值,a++,b++;
- 若a未寻找到0,b寻找到1,同样的a++,b++,因为通常a在b后面,而在a之前的所有元素都是1;
- 若a寻找到0,b未寻找到1,b++继续寻找1,这些情况违反了上述的通常情况一般是000开头这样的数组;
- 若a未寻找到0,b未寻找到1同样的a++,b++;
方法二:同样时双指针,指针j统计0的个数,第一次遍历时将前几个元素值为非零元素,第二次遍历将后j个元素置为0即可。
代码
class Solution {
public:void moveZeroes(vector<int>& nums) {int n=nums.size();int a=0,b=1;while(a<n&&b<n){if(nums[a]==0&&nums[b]!=0){int temp=nums[a];nums[a]=nums[b];nums[b]=temp;a++;b++;}else if(nums[a]==0&&nums[b]==0){b++;}else if(nums[a]!=0&&nums[b]!=0){a++;b++;}else if(nums[a]!=0&&nums[b]==0){a++;b++;}}}
};
class Solution {
public:void moveZeroes(vector<int>& nums) {// int a=0,b=0;int n=nums.size();int j=0;for(int i=0;i<n;i++){if(nums[i]!=0){nums[j++]=nums[i];}}for(int i=j;i<n;i++){nums[i]=0;}}
};
收获
简单模拟。
11. 盛最多水的容器
11. 盛最多水的容器
题目介绍
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明:你不能倾斜容器。
示例 1:
输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
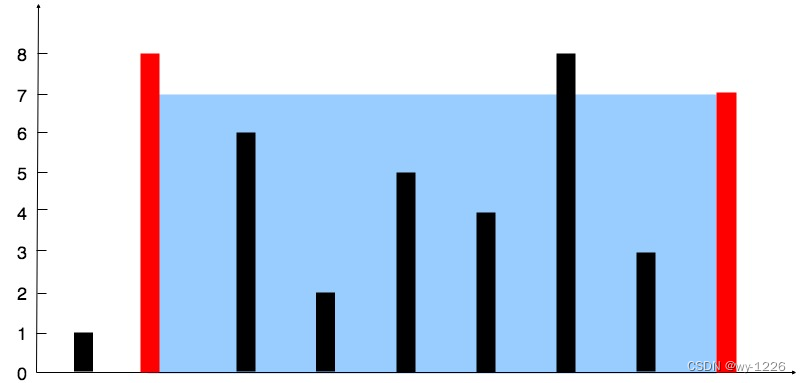
示例 2:
输入:height = [1,1]
输出:1
思路
方法一(时间超限):暴搜,直接嵌套两个循环维护一个最大面积变量即可。
ans=max(ans,min(height[i],height[j])*(j-i));
方法二:双指针,分别从开头和末尾开始遍历,取水的面积取决于较小的高度,每次更新两个指针中最短的并维护最大面积即可。
代码
class Solution {
public:int maxArea(vector<int>& height) {int ans=0;int n=height.size();for(int i=0;i<n;i++){for(int j=i;j<n;j++){ans=max(ans,min(height[i],height[j])*(j-i));}}return ans;}
};
class Solution {
public:int maxArea(vector<int>& height) {int ans=0;int n=height.size();int a=0,b=n-1;while(a<b){ans=height[a]<height[b]?max(ans,(b-a)*height[a++]):max(ans,(b-a)*height[b--]);}return ans;}
};
收获
无
15. 三数之和
15. 三数之和
题目介绍
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0+ 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。 注意,输出的顺序和三元组的顺序并不重要。
示例 2:
输入:nums = [0,1,1]
输出:[]
解释:唯一可能的三元组和不为 0 。
示例 3:
输入:nums = [0,0,0]
输出:[[0,0,0]]
解释:唯一可能的三元组和为 0 。
思路
一开始可以用三重循环但是效率太低了,参照题解发现第三重循环其实可以优化跟第二重循环平行,因为第三重循环找的c本身就大于b只需要在b的左边找,所以在找b的时候顺便就把c给找了。
代码
class Solution {
public:vector<vector<int>> threeSum(vector<int>& nums) {int n=nums.size();sort(nums.begin(),nums.end());vector<vector<int>> ans;for(int first=0;first<n;first++){if(first>0&&nums[first]==nums[first-1]){continue;//与上一个数字相同不要}int third=n-1;//c对应的指针在数组最右端开始遍历int target=-nums[first];//bfor(int second=first+1;second<n;second++){//同fitst不能与上一个数相同if(second>first+1&&nums[second]==nums[second-1]){continue;}while(second<third&&nums[second]+nums[third]>target)//保证third在second右边{--third;}if(second==third)break;if(nums[second]+nums[third]==target){ans.push_back({nums[first],nums[second],nums[third]});}}}return ans;}
};
收获
有点不会说实话
这篇关于wy的leetcode刷题记录_Day84的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






