本文主要是介绍阿里又放大招:Emo!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是程序员牛牛,《AI超级个体: ChatGPT与AIGC实战指南》的参与人,10年Java编程程序员。
我们先来看几张图
马斯克和库克跳科目三

慈禧跳舞

这是前段时间很火的通义舞王生成的,只需要一张图片,就能让人物跳舞,如果你没玩过,赶紧试试!
但最近阿里又放大招了!
阿里巴巴智能计算研究所发布了一款全新的生成式AI模型EMO(Emote Portrait Alive)。EMO仅需一张人物肖像照片和音频,就可以让照片中的人物按照音频内容“张嘴”唱歌、说话,且口型基本一致,面部表情和头部姿态非常自然。
只需要一个音频+一张图片,就能让图片根据音频进行讲话或者唱歌!
前面给大家分享过Sora,里面的AI角色,我们也可以让她讲话
声音来源:Dua Lipa - Don't Start Now
蒙娜丽莎讲话

声音来源:莎士比亚的独白II 皆可:罗莎琳德“是的,一个;并且以这种方式。”
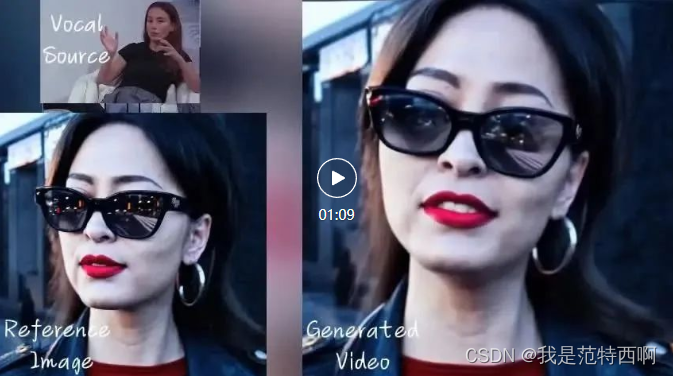
哥哥张国荣唱歌,看到这里快泪崩了
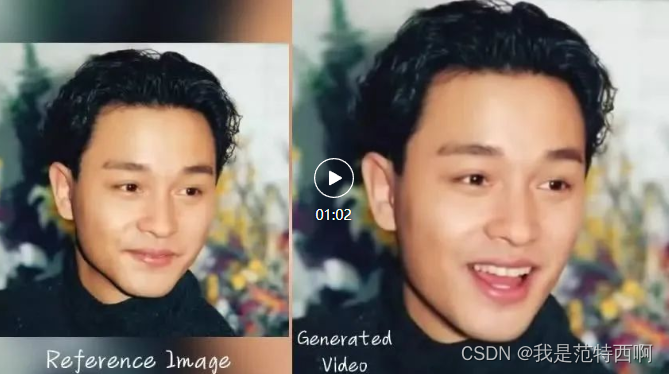
声音来源:陈奕迅 - Eason Chan - Unconditional. Covered by AI (粤语)
还有让强哥模仿法外狂徒讲课

声音来源:法外狂徒-法律考试在线课程
可以看到,上面生成的视频,具有表情丰富的面部表情和各种头部姿势,前不久的sora目前还只能支持1分钟的视频,但这个更牛逼了,可以根据输入音频的长度生成任意持续时间的视频。
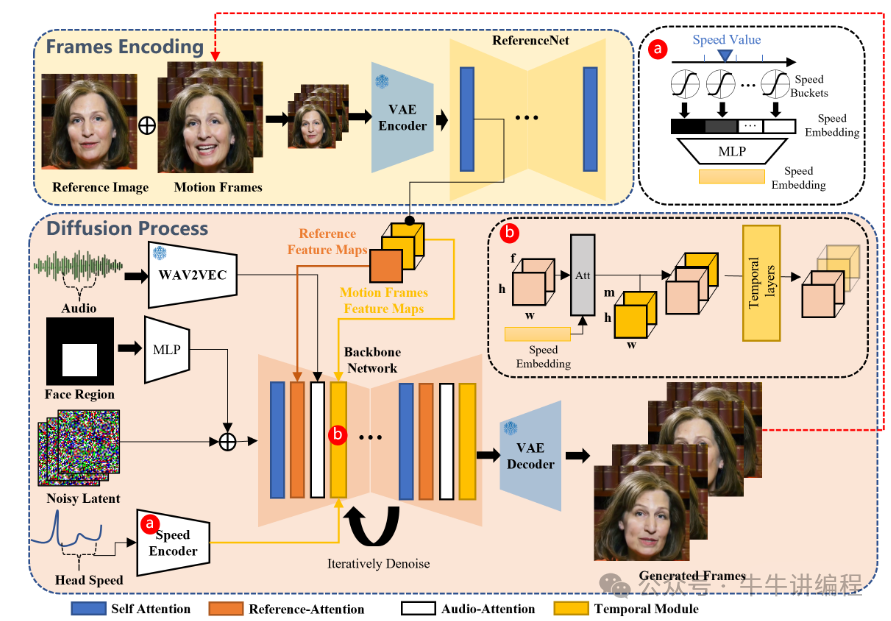
EMO的工作过程分为两个主要阶段:首先,利用参考网络(ReferenceNet)从参考图像和动作帧中提取特征;然后,利用预训练的音频编码器处理声音并嵌入,再结合多帧噪声和面部区域掩码来生成视频。该框架还融合了两种注意机制和时间模块,以确保视频中角色身份的一致性和动作的自然流畅。
这个过程相当于,AI先看一下照片,然后打开声音,再随着声音一张一张地画出视频中每一帧变化的图像。
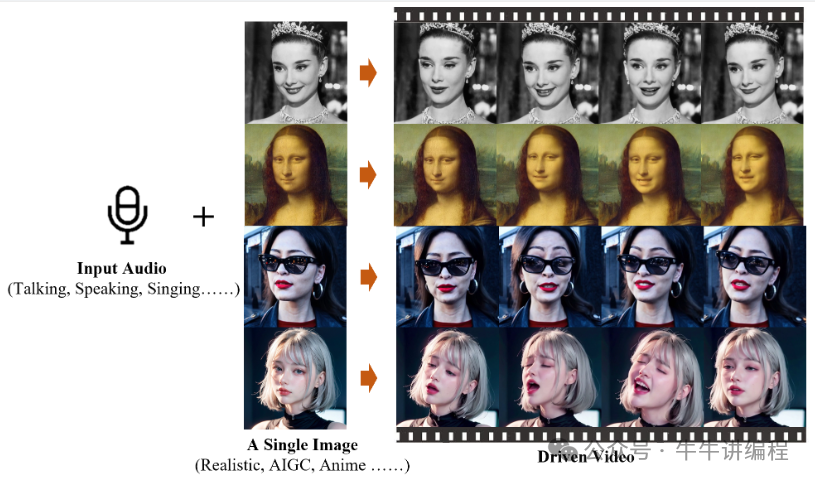
不过目前这个技术还没有开源,我们可以保持持续关注,期待国产AI的崛起!
最后附上EMO的原理图
欢迎大家转发关注我的公众号,我将持续为大家分享编程前沿技术及日常编程技巧!
到公众号上可以查看视频文件!点击此处查看原文

这篇关于阿里又放大招:Emo!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[SaaS] 阿里妈妈-万相营造](https://i-blog.csdnimg.cn/direct/b2582bfe2fb14cb2a208554f77b6546a.png)