本文主要是介绍跨网络传输的大致过程+图解(软件虚拟层),ip地址介绍,ip地址和mac地址对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
跨网络传输
引入
举例 -- 唐僧西天取经
结论
介绍
ip地址
引入
介绍
类型
公有ip
私有ip
版本
ipv4
ipv6
ip地址和mac地址的唯一性问题
数据包转发的过程
引入
思考 -- 如何跨子网
过程
图解
封装和解包
去掉差异
ip地址/协议的重要性
注意
ip vs mac
跨网络传输
引入
举例 -- 唐僧西天取经
唐僧要从长安到西天,他无法直接到达,只能一步一步走向目的地,他途中会经历很多国家
类似于下图这样:
而跨网络传输大致流程也是这样
- 数据无法直接传输给对方主机,必须经过不同设备(也就是中转站,相当于唐僧每次落脚的国家)的转发
他每次到达一个地方,都要说一句经典台词 -- 我从东土大唐而来,前往西天取经
为什么要说这句话?
- 一是为了说明自己的来历
- 二是需要根据最终目的地来确定下一站 (每当要动身离开某地时,都要根据"西天"来确定自己的下一站)
- 那么,网络通信中,肯定也会有类似的设计 -- 需要一个最终地址来确定自己传输的方向

结论
所以,这里有两个地址是关键
- 一个不变的地址(最开始从哪来,最终要到哪去) -- ip地址
- 一个随着当前位置变化而变化的地址(上一站从哪来,下一站到哪去) -- mac地址(熟悉吗,就是在局域网通信中用到的那个)
- 而地址变化的依据 -- 最终目的地
- 正是因为唐僧心里有这两个地址,最终他成功到达西天,所以网络传输只要有ip地址和mac地址,也可以成功将数据传输给正确的主机
具体怎么使用,将会在数据包的转发过程里介绍
总之,这个例子是为了让我们简单地描摹出跨网络传输的过程
介绍
指在不同网络之间传递数据或信息的过程
数据在网络之间传输时需要经过路由器
- 路由器是网络设备,负责决定数据包在网络中的最佳路径,并进行转发
- 它级联了左右两个子网(局域网),帮助数据跨越不同的网络边界
ip地址
引入
我们再次明确一下,为什么会有ip地址?
- ip地址是ip协议定义出来的,而ip协议在网络层,是用来解决主机定位的问题
- 类比唐僧取经: ip地址相当于某地的地址,它的存在是为了进行路径选择 (如果没有目的地的话,所谓路径又从何而来呢)
- ip地址也像是我们每个人定下的目标,为了某个目标,我们是有规划地去完成的
- 比如:你想要找到工作,就得去学习知识,做项目,投简历,去面试等等,这都是通往"找到工作"这个目标的道路上必要的结点
介绍
ip地址是在互联网协议(IP协议)中用于唯一标识和定位网络上设备的数值标签
- 它允许网络中的计算机、服务器、路由器等设备进行通信,并确保数据能够正确地从一个设备传输到另一个设备
- 有两个主要版本的ip地址:ipv4(主流使用)和ipv6
类型
公有ip
- 在全球范围内唯一标识一个设备的地址,用于在互联网上进行直接通信
- 由互联网服务提供商分配
- eg: xshell连接云服务器时输入的ip
私有ip
- 在私有网络内使用的地址,不直接暴露在互联网上
- 有可能重复
版本
ipv4
- 32位的二进制整数,类似可以被书写为xxx.xxx.x.x(十进制)
- 分为网络地址和主机地址两部分,用于区分网络和主机,通过子网掩码来划分这两个部分
- 主流使用的ip地址
- ipv4的地址空间有限,约有42亿个可用的唯一地址,导致ipv4地址枯竭
ipv6
- 采用128位的二进制数表示,通常以冒号分隔的十六进制数表示
ip地址和mac地址的唯一性问题
- ip地址(需要保证主机在全网内的唯一性)
- 而mac地址只需要保证局域网内的唯一性 (理论上他也可以保证全网内的唯一性,但以太网是局域网的技术实现,不需要太大)
数据包转发的过程
引入
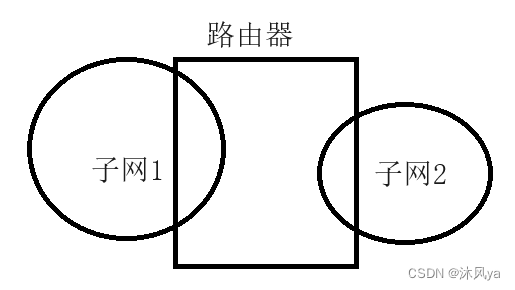
通过路由器实现跨网络传输(这里以只经过一个路由器为例),其原理类似于下图(要通信的两个子网之间必须要横跨一个路由器)
我们在已经了解了局域网内的通信流程的基础上,来理解一下如何通过路由器实现跨网络传输
思考 -- 如何跨子网
先不管那些专业知识,我们先自己思考一下,如何从子网1到子网2
- 因为我们的目的ip并不在局域网内,所以首先要出自己的局域网 -- 这需要借助路由器实现
路由器也属于局域网内的一个普通设备
- 它可以帮我们转发给其他局域网,而该局域网内的其他设备不行
- 把数据交给路由器的过程,本质上就是局域网通信
- 路由器再将数据交给主机,也是局域网通信
所以,图中其实就是两次局域网通信:
过程
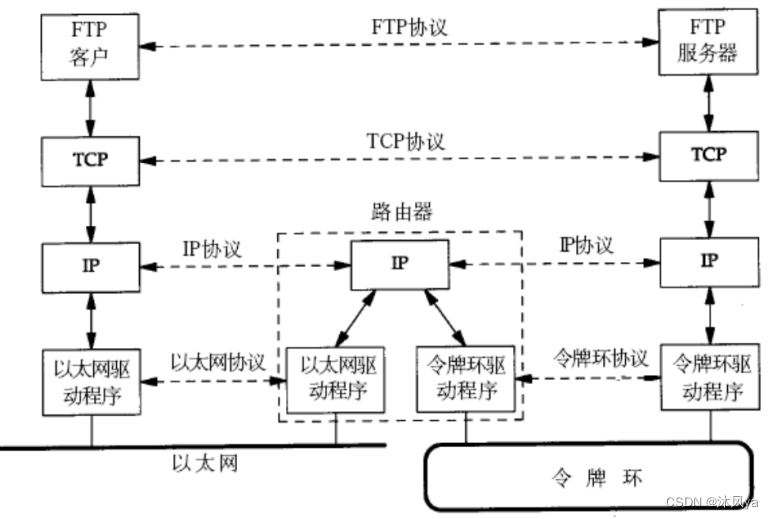
我们将用户向服务器发送请求,看作是[子网1内的一台主机a] 和 [子网2内的主机b]通信
首先,a发送的数据被层层封装
- 其中网络层协议的报头中包含<来源ip和目的ip>
- 链路层协议的报头有<来源mac地址和目的mac地址>(指示物理层将报文发送给哪个设备)
- 注意,这里要经过路由器,所以目的mac地址=路由器mac地址
然后这条报文被发送给子网1内的所有主机
- 每台主机收到数据,上传至链路层被解析后,只有路由器保留了这条报文,且上传到网络层
- 经过网络层(路由器就在网络层工作)的解析,路由器发现目的ip并不是自己,且识别到是与自己相连的子网2内的主机,就会将其转换为子网2内部的通信
所以它会向下传输(因为通信最终必须要通过物理层),交给自己的链路层
- 这里假设子网2内部用的是令牌环网络
- 路由器内部的链路层会将自己的报头封装进去(包含<自己的mac地址+目的设备的mac地址>),然后通过物理层传输给子网2的所有主机
- 最终只有目的ip对应的主机会保留该报文,且经过一层层解析
- 最终,目的主机就可以收到消息了
图解
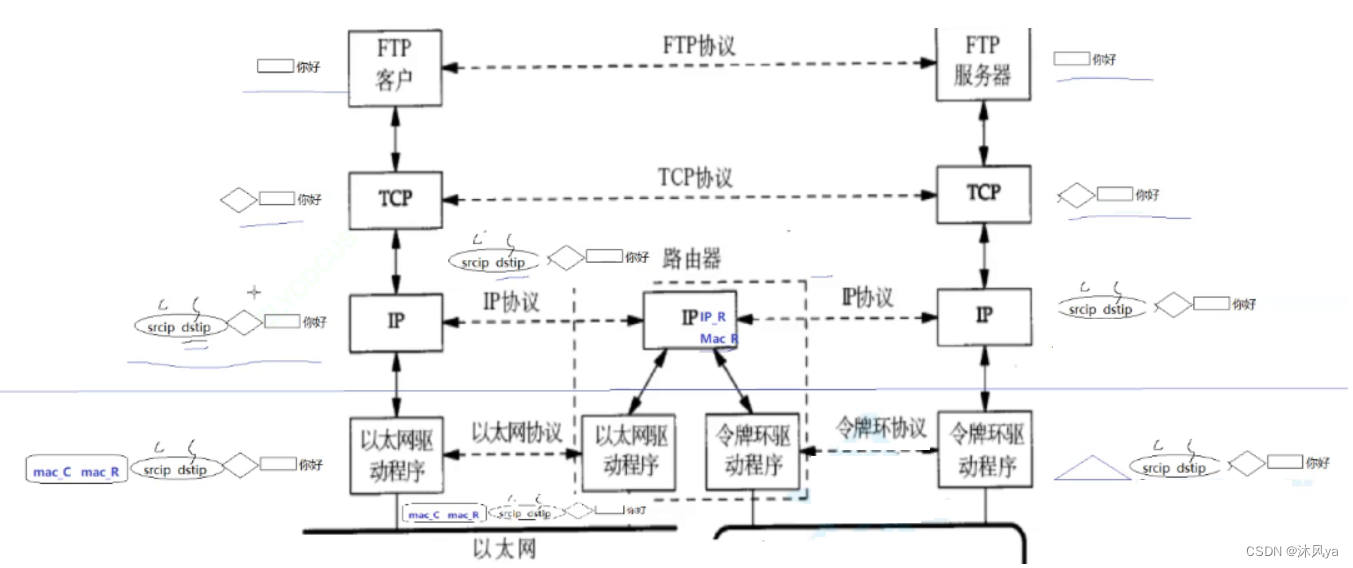
封装和解包
到一个新局域网后,路由器会帮我们去掉老的链路层报头,换成新的报头
- 这个过程也可以叫封装和解包
- 路由器内部的局部封装/解包,贯穿协议栈的封装/解包,都叫做封装/解包
去掉差异
注意看图,前三层同层之间收到的报文都是一样的,但是在链路层,其链路层封装的报头有区别
- 说明网络层及其以上的协议要使用一样的,但网络层以下可以是不同的
- 所以局域网的类型(比如以太网/令牌环网/无线网等等)已经不重要了,因为他底层的差异已经被路由器去掉了(路由器会帮我们进行报头的更新)
因为是路由器帮助我们横跨网络
- 所以其内部必须既要有以太网协议,又要有令牌环协议,或者其他协议
- 同理,网卡也需要配齐(也就是物理层,它因不同的局域网类型而有所不同)
ip地址/协议的重要性
还记得我们捋出来的过程吗,ip地址是其中的关键
- 有了ip地址,我们才可以指导路由器进行转发设备的选择,路由器去进行实际的定位和转发工作
- 相当于ip地址是最初的1,有了1才会有之后
- 而ip地址是ip协议定义的
- 所以可以说,是ip协议屏蔽了底层网络的差异(靠的就是工作在网络层的路由器)
- 那么,ip报文就可以被看作是一种在全球范围内设备之间进行通信的软件虚拟层
- 它隐藏了底层网络技术的细节,使得不同类型的设备都能够在同一个网络中进行通信,只要它们支持ip协议,就可以在这个虚拟层上互相交流(无需关心它们之间的物理连接、链路层协议或其他底层细节)
- 这样抽象后,跨网络通信是不是就和之前学习过的局域网通信很像?
- 所以,他们都可以用统一的传输流程
- 这个理念和linux系统中的一切皆文件非常相似 -- 文件对象让我们忽略硬件的差异,ip地址让我们忽略底层网络的差异
- 而这也体现了软件分层的优越性(正是因为分了层,才有机会忽略差异),在系统和网络上都有使用该思想,它大大简化了我们的操作难度
- 也正是因为ip协议的好用,所以网络技术可以很快普及


注意
但即使上层玩出花来,也必须得经过实际的物理层传输(因为一切的网络通信,本质上都是操作网卡)
所以可以看到,图中的a主机和b主机想跨网络交流的话,这条数据运输线必然是将他俩相连的,而不能断掉
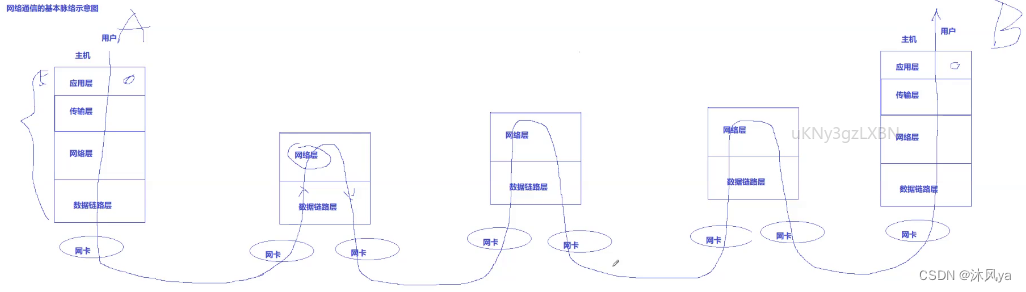
ip vs mac
从上面的过程梳理中我们就可以发现,这两个地址还是有很多不同的:
- ip地址是不会发生改变的,尤其我们需要目的ip来协助我们进行路径选择
- 而mac地址是局域网内部使用的,相当于临时地址,一旦出局域网,源和目的mac地址都会被丢弃,由路由器在链路层为其重新封装
这篇关于跨网络传输的大致过程+图解(软件虚拟层),ip地址介绍,ip地址和mac地址对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






