本文主要是介绍Great Dubbo--上,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
序
初次接触dubbo是在2011年,当时公司项目出于成本考虑容器从Weblogic改为Tomcat,部署方式由单机改为单体多机的部署方式。对一个从没读过半本计算机书籍的人,不了解协议,不懂规范只知道SSH的菜鸟而言,完全不理解分布式的方式是如何做到互通的。晚期强迫症逼迫我一定要弄懂这其中的原理,百度、google各种关键字后找到了dubbo,于是开始了dubbo的源码研究之路。中间断断续续看了两遍。11年的时候第一遍弄明白了rpc、spi、软负载、集群、备援等等分布式相关的概念。前年又重新看了一遍,开始能有些体系化的思考。
Dubbo官方文档已经非常详细,我这里再做画蛇添足的描述,主要是基于以下两方面原因:
1. 向我的偶像梁飞致敬,11年读dubbo源码的时候真的很崇拜他,也希望我写得足够好,最好能被他点赞。
2. Dubbo和hsf比较相似,因为实在抽不出时间去仔细翻hsf的源码(还有那么多优秀的中间件要去学习呢),所以用dubbo来映射一下hsf技能栈。
Dubbo的大部分特性都在在客户端,因此本文对客户端重点描述,服务端会稍做提及。
地图
在mac上实在找不到一个可用的工具去做主题域划分,没绘画和书法天赋的博主只能勉为其难,献上鬼画符,强迫症患者们请忍受下博主拙劣的画功和字迹吧。

整个dubbo分成4个主题域,当然如果将边界继续缩小会有更多。领域的精髓就在于找好视角、选定边界,在边界内再设定更小的边界,分而治之,最后突破全局。博主也会遵循该脉络,从整体到各个主题域依次细化。
本文将分成上下两篇,上篇主要聚焦在通用域,描述《整体架构》和《SPI》;下篇则集中在《逻辑集群》、《注册中心》和《RPC》三个主题域。
客户端整体架构
技术原型
Dubbo本质上还是RPC,RPC主题是让远程调用看上去像本地调用一样,用户不需要关心各种通讯协议。
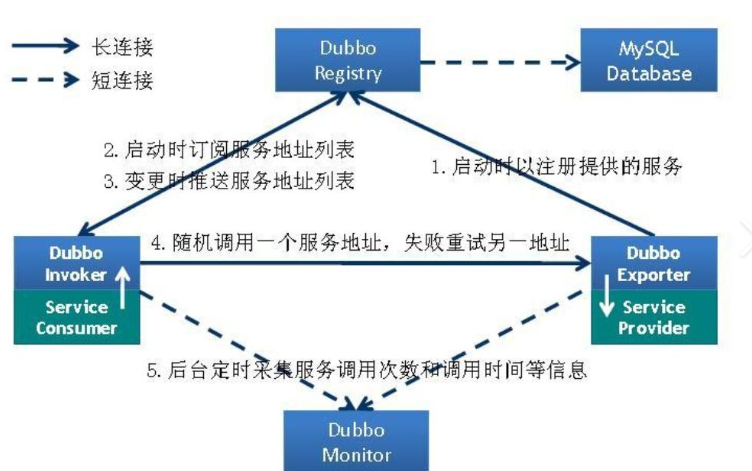
Dubbo在此基础上引入注册中心管理服务,使服务地址透明化并能及时感知服务的状态。服务端和客户端只需要遵循接口契约,而服务的发现和发布则由注册中心来负责。这是dubbo的技术原型,也是理解dubbo的出发点。

客户端启动时向注册中心注册说明需要哪种服务,服务端启动时也向注册中心注册说明提供哪种服务,注册中心将需求和供给进行匹配并推送给客户端提供方地址等信息,最终客户端请求被序列化传输到远程节点,反序列化出服务、方法和参数信息,在节点并发起本地调用,返回值序列化后再传回客户端。
客户端整体架构
不管服务端还是客户端都依赖protocol和SPI两个通用组件。因为只聚焦在客户端建模,所以对服务端除这两个通用组件以外都黑盒化,约定服务端具有以下能力:
1. 正确接收到客户端消息/报文
2. 正确解析消息并能逆序列化,解析出本次调用的服务、方法及参数
3. 正确调用,并能在调用后可以正确响应
以下是客户端的组件视图,从上到下是调用关系,上面调用下面。

- SPI是公共通用组件,Protocol基于spi可以动态生成特定协议的invoker以及服务端的exporter
- 请求被委托给逻辑集群,集群从目录中list所有invoker,负载均衡组件从中select出一个可用的,invoker再通过exchange发送请求,请求被序列化(codec)后以特定的传输协议(transporter)发送,在每一个事件处理成功后 –比如连接、发送、应答等等,都会通知handler处理相应事件,handler依赖特定dispatcher的能力对该次处理做线程分发或同步分布。
配置动态化
Dubbo的配置是动态且可传递的,它在Dubbo中会被抽象成URL对象用于流转。
URL对象可以被序列化,因此它可以在端和端之间传输,客户端依据接受到的配置正确感知服务端的配置变化。典型的URL结构会是
协议://用户名:密码@host:port/group/path?参数path一般是service:version,因此客户端可以从服务端的URL配置上获得地址等信息,从而正确引用它。URL被流转于几乎所有调用链路的上下文,因此dubbo扩展点在做动态决策时可以参考URL中的参数信息从而做出正确委派。比如动态决策使用哪种codec时,会依据URL中的codec参数值在运行期动态匹配codec实体对象。
SPI
上一章提到codec的动态决策,其实不仅codec,dubbo还支持传输、应用等等的动态决策。Dubbo里几乎每个组件都支持多种协议,在这幕后的英雄就是SPI组件,完全可以说SPI是dubbo里最了不起并且没有之一的组件,如果稍微打磨更加通用和人性化一些再作为单独项目开源,必定能繁荣一片生态,即使目前它也是dubbo的基石,所以在本章会花较大篇幅来描述它。
进入正题前,还是先介绍下java的spi机制,方便理解spi是什么、为什么要用spi以及java spi的利弊。
Java spi
SPI是service provider interface的缩写,字面翻译就是服务提供者接口,是上游产商给服务供应商提供的接口,供应商遵循接口契约提供自己的实现。注意和dubbo provider的区别,dubbo provider并不是SPI服务,但在概念上一致的,也特指供应商的服务实现。Dubbo以自己的机制能保证指定供应商的调用能请求到正确的provider,这将在集群篇重点讲述,这里只指出区别,防止混淆。
Jdk有自带的spi实现,应用可以发布不同供应商的服务,但一般一个应用至少是一个虚拟机进程中只能有一种,发布者通过在meta-inf/services添加名称为接口全路径的文件,并在这个文件里加入provider全路径声明当前只提供该供应商服务,相应的消费者也只会消费该供应商的服务。在需要更换提供者时,需要修改对应文件就行并重启进程。
我们把这类比成一家商店,商店可以便利的上架各种商品,客户来消费时只需要指定需要哪种商品,商家就把指定商品售卖给客户。但这其实有点问题,这只能解决消费者只关心要什么,而不关心具体品牌的场景。而现实中客户往往对牌子是有偏好的 ,比如舒肤佳的肥皂又或者杜蕾斯的tt等等。
在平台性应用中,参与方很多,调用者往往会指定提供者,比如在多租户的saas系统中,调用者会指定特定租户。显然java spi无法满足或者很难满足这种场景,因为他的策略是一种静态策略,而dubbo却能很好的支持这类场景。
Dubbo SPI
要声明服务为dubbo spi服务首先需要通过@SPI声明接口是SPI;并在META-INF/dubbo或者META-INF/dubbo/internal下定义接口全路径的同名配置文件,配置文件内容为name->implementation class,可以声明多个提供者。
Dubbo spi也兼容jdk范式的spi,其name会被默认为class#simpleName,也可以通过@Extension在提供者上声明name(已经Deprecated)
下面以Cluster为例,说明下spi是怎么使用的。
@SPI(FailoverCluster.NAME)
public interface Cluster以上代表Cluster是一个SPI,后面的value标识默认实现为failover。Dubbo有多种集群实现,配置在/META-INF/dubbo/internal/com.alibaba.dubbo.rpc.cluster.Cluster中。以下截取其中4种,分别是备援、快速失败、安全失败和回滚。
failover=com.alibaba.dubbo.rpc.cluster.support.FailoverCluster
failfast=com.alibaba.dubbo.rpc.cluster.support.FailfastCluster
failsafe=com.alibaba.dubbo.rpc.cluster.support.FailsafeCluster
failback=com.alibaba.dubbo.rpc.cluster.support.FailbackClusterSPI容器容纳这4种集群实现,并提供动态机制针对单次调用决策提供具体实现。比如,如果声明的当次调用协议为快速失败<dubbo:reference cluster="failfast" />或<dubbo:provider cluster="failfast" />则相应会决策FailfastCluster来提供集群功能,如果当次调用没有声明则使用默认的备援实现也就是FailoverCluster。
扩展容器
SPI组件在dubbo称为ExtensionLoader–扩展容器,它主要有4个重要实体:
扩展点Extension,可以理解为是预留的一排插座,按照插座规格制造出来的插头就可以无缝插入。类似的,只需要遵循扩展点规范出来的组件都可以集成进应用中。用户可以通过容器提供的getExtension方法直接获取扩展点,参数是spi配置文件中的key;或者使用getAdaptiveExtension得到一个adaptive,在调用时动态决策当次的扩展点。后者被广泛用于dubbo框架中,使dubbo可以方便的动态扩展,本章开篇的动态多协议仅仅只是动态扩展的一个方面。
Wrapper,包装类,如果声明了包装类的提供者,则默认将当次决策的provider包装起来并返回包装类。容器判定是否为包装类的依据为是否有一个参数为接口类型的构造参数。Wrapper可以有多个,会被按顺序依次嵌套
假设spi定义如下:
A=a.b.c
B=a.b.wrapper1
C=a.b.wrapper2
则返回的wrapper的最终结构为B–C–AActivate,代表是一个激活点,单从字面上理解有些诧异,它的意思其实是条件激活。激活点首先还是个扩展点,是使用@Activate注解的扩展点。容器提供getActivateExtension(URL url, String[] values, String group)方法获取激活点。激活点的激活获得需要满足以下两个条件
- 方法参数中的group和注解声明的group一致,如果前者为空则对所有group有效。
- 满足条件1的情况下用户可以通过方法中的values参数指定需要激活的激活点的扩展点名称,多个用逗号隔开。
- 满足条件1的情况下,当次调用的配置里有注解声明的value片段。
激活点一般配合Filter和Invokelistener使用,声明他们的使用场景,比如@Activate(group = {Constants.CONSUMER}, value = Constants.CACHE_KEY)用来声明拦截器使用场景是”在客户端并且当次调用需要带有cache配置“。
Adatpive,字面意思是适配,但其实是代理,意思是适配合适的实体对象处理请求。它类似jdk的动态代理,但因为dubbo几乎需要为每个服务都生成adaptive,所以出于性能考虑默认使用javassist编译生成一个adaptive。用户可以实现自己的adaptive,只要对provider打上@adaptive即可,例如dubbo的AdaptiveExtensionFactory类。
容器自动生成adaptive的方案,需要@Adaptive标注接口上的adaptive方法,没被标注的方法不能动态决策,需先通过容器获得扩展点后再进行调用。
Adaptive的决策过程,最终还是会通过容器获得当次调用的扩展点来完成调用。

- 取得扩展点的key
1. Adaptive方法必须保证方法参数中有一个参数是URL类型或存在能返回URL对象的方法,容器通过反射探测并自动获取。
2. key默认是接口类型上的@SPI#value,方法上的@Adaptive#value有更高的优先级。
3. 如果2都为空则以interface class#simpleName为key, key生成规则:”AbcAbcAbc”=>”abc.abc.abc”
- 如果key值是protocol,则直接调用URL#getProtocol方法获取扩展点名称,如果不是则使用URL#getMethodParameter(key)或getParameter(key),其返回值作为扩展点名称,这里的URL是在步骤1获得的
- 通过ExtensionFactory获取扩展点。ExtensionFactory用于获取指定名称的扩展点,它最终还是通过容器的getExtension去获取或生成。如果用户声明的provider里有wrapper,则返回的是被包装过的实体对象。
扩展点机制
本章开篇介绍过dubbo对多协议的动态支持,最后以它为例,总结下dubbo扩展点机制。
@SPI("dubbo")
public interface Protocol {int getDefaultPort();@Adaptive<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;@Adaptive<T> Invoker<T> refer(Class<T> type, URL url) throws RpcExceptionvoid destroy();
}通过@SPI声明Protocol为SPI,默认扩展点是dubbo,也就是默认协议是dubbo。
Protocol spi配置文件的其中一段:
filter=com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper
listener=com.alibaba.dubbo.rpc.protocol.ProtocolListenerWrapper
dubbo=com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol因为不存在被@Adaptive注解的实现类,则首先容器会为Protocol自动生成adaptive,以在运行期通过动态决策委派provider处理,基于以上配置,委派的提供者将是一个包装类,且为多层包装,顺序应为ProtocolFilterWrapper–>ProtocolListenerWrapper–>DubboProtocol。
我打了个断点,截取了Protocol的进程结构

Protocol是个多层包装类,相应的调用也将会是多层逐级调用的过程。
为了配合说明activate,以下使用Protocol#refer的过程举例:
Refer代表引用提供者,其会产生invoker,关于invoker在逻辑集群一章将会重点讲述,目前只需要知道所有remote访问最后都会由它发起即可。

Refer到达adaptive,由后者做动态决策交由哪个提供者处理。一般的调用不涉及到wrapper,直接委派给provider就处理结束,但是对于Protocol,因为有wrapper所以先会委派给wrapper:
- ProtocolFilterWrapper对Filter类型激活点进行顺序编排,编成调用链:
filter1->filter2->…-> ListenerInvokerWrapper->invoker
最后置入匿名invoker的invoke方法后再返回给调用者:
ProtocolListenerWrapper生成的一个ListenerInvokerWrapper,后者也是Invoker类型,其结构如下
ListenerInvokerWrapper
|
|————invoker: DubboInvoker
|
|————invokerListeners: List< InvokerListener>
invokerListeners是类型为InvokerListener的activate集合。Protocol被refer后由它回调所有listener的referred方法,invoker被destroy时由它执行所有listener的destroyed方法。用户可以方便的定制自己的拦截器和监听器,只需声明为激活点且定义好适用条件即可,dubbo在构建invoker过程中会自动将符合条件的激活点纳入其中。
- InvokerListener并不关心组别,只需要1)扩展点名称=invoker.listener参数值;2)注解里的value参数中任意一个出现在当次调用的配置里
- Filter会关心组别,组别只支持consumer或provider,分别代表客户端还是服务端的拦截器,两者分别由refer和export过程构建;2)扩展点名称=refrence.filter参数值;3) value参数同上
这篇关于Great Dubbo--上的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!