本文主要是介绍没经验学历的外教竟然这么吃香,我酸了!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
背景:
介绍说明:
总览
外语培训表格数据
幼儿园表格数据
职业学院表格数据
中小学数据表格
数据处理
数据表格合并
教师数据清洗
清洗经验、学历
清洗出工资
JobLeadChina数据清洗
数据分析
洋外教的工资真的高吗
不同级别和工作年限的工资比较
学历水平对薪资的影响
什么机构在招聘洋外教?
洋外教来源真的很乱吗?
总结:
背景:
这几天拿到了一份关于“英语外籍老师与本土老师招聘数据在中国的工作情况”的数据(没经验没学历的外教为啥能拿1.4W+的高薪?),这些数据是我在Github上找到的,有需要的可以留言,后面可以把相关数据分享和你们,大家也可以关注原作者的微信公众号“[Alfred数据室]”查看相关数据。
介绍说明:
首先我们先看下这几个excel表格,“外语培训”是记录一些培训院校对外语教师的招聘添加、城市、经验和学历要求,“幼儿园”表格是记录幼儿园学校对外语教师的招聘要求,同理“职业学院”和“中小学”也是对外语教师的招聘要求、包括工作经验、学历、薪资等,具体所图所示:
总览

外语培训表格数据

幼儿园表格数据

职业学院表格数据
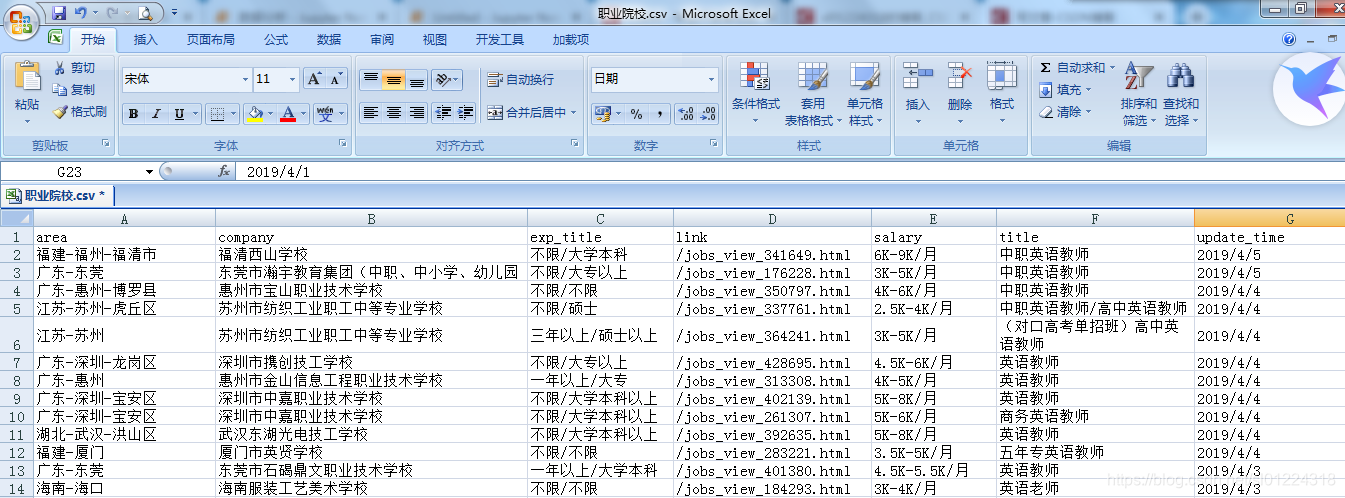
中小学数据表格

数据处理
数据表格合并
首先第一步是使用concat方法把“幼儿园、中小学、外语培训、职业学院”数据进行合并成一个表格,具体代码如下:
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#import seaborn as snsplt.style.use('ggplot')
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题
plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点
plt.rcParams["figure.dpi"] =mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
%matplotlib inline# 把来自万行教师的四个数据集组合成一个Dataframe
data_kdgd['type'] = '幼儿园'
data_pmsc['type'] = '中小学'
data_trn['type'] = '外语培训'
data_clg['type'] = '职业院校'
data_wx = pd.concat([data_kdgd, data_pmsc, data_trn, data_clg])
data_wx.info()实际运行结果:

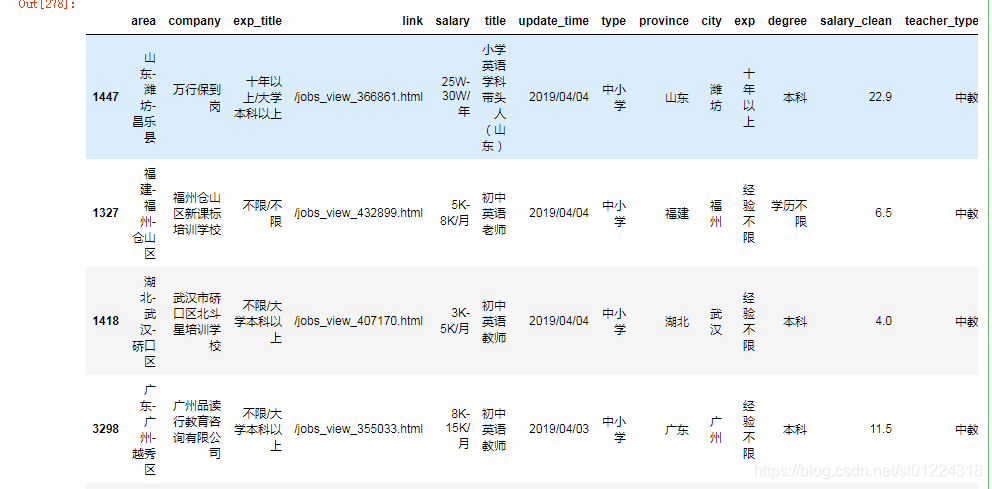
再看一下表格的具体内容是什么样子的:
#sample方法是随机选取若干行的内容
data_wx.sample(5) #随机选取5行内容结果:
教师数据清洗
- 清洗出省份、城市
- 经验、学历
- 工资
表格合并之后,从上图可以看到有些数据是多余的,还有一些数据的单位不一致,部分数据还有空值,我们要接着对数据进行进一步处理,在这里我们从“省份、城市”、“经验、学历”、“工资”这几个维度来处理,。
首先进行清洗出省份、城市,我们看到省份、城市的数据格式是不一致的,我们在这里要统一格式,代码如下:

#把数据内容转换为str类型,然后使用split方法通过“-”符号进行分割
data_wx['area'].str.split("-", expand=True)运行结果:

在这里我们把data_wx数据新增两列分别为“province、city”
data_wx['province'] = data_wx['area'].str.split("-", expand=True)[0]data_wx['city'] = data_wx['area'].str.split("-", expand=True)[1]
# print(data_wx)
# 把北京、天津、上海、重庆的城市改为原来的名字
data_wx.loc[data_wx['province'] == '北京', 'city'] = '北京'
data_wx.loc[data_wx['province'] == '上海', 'city'] = '上海'
data_wx.loc[data_wx['province'] == '天津', 'city'] = '天津'
data_wx.loc[data_wx['province'] == '重庆', 'city'] = '重庆'清洗经验、学历
原始数据:

数据清洗,新增经验年限、学历要求,清洗后的数据如下图所示:
#获取经验年限
data_wx['exp'] = data_wx['exp_title'].str.split("/", expand=True)[0]#获取学历要求
data_wx['degree'] = data_wx['exp_title'].str.split("/", expand=True)[1]
#进行去重
data_wx['exp'].unique()
print(data_wx.head(5))exp_map = {'不限':'经验不限', '一年以上':'一到三年', '三年以上':'三到五年', '两年以上':'一到三年','五年以上':'五到十年', '应届毕业生':'经验不限', '六年以上':'五到十年', '四年以上':'三到五年','九年以上':'五到十年', '七年以上':'五到十年', '十年以上':'十年以上', '在读学生':'经验不限', '八年以上':'五到十年'}data_wx['exp'] = data_wx['exp'].map(exp_map)
#data_wx.sample(5)degree_map = {'大专':'大专', '不限':'学历不限', '大学本科以上':'本科', '大学本科':'本科', '大专以上':'大专', '不限以上':'学历不限', '中专以上':'中专', '硕士以上':'硕士', '硕士':'硕士', '高中以上':'高中', '中专':'中专'}
data_wx['degree'] = data_wx['degree'].map(degree_map)
data_wx.sample(5)运行结果:

清洗出工资
data_wx['salary'].unique()#定义一个函数用来清洗工资
def get_salary(data):pat_K = r"(.*)K-(.*)K"pat_W = r"(.*)W-(.*)W"pat = r"(.*)-(.*)/"if "面议" in data :return np.nanif "享公办教师薪资待遇" in data :return np.nanif 'K' in data and '月' in data:
# low ,high = re.findall(pattern = pat_K,string = data)[0]
# return (float(low) + float(high))/2low, high = re.findall(pattern=pat_K, string=data)[0]return (float(low)+float(high))/2if 'W' in data and '年' in data:
# low,high = re.findall(pattern = pat_W,string = data)[0]
# return (float(low) + float(high))/2*10/12low, high = re.findall(pattern=pat_W, string=data)[0]return (float(low)+float(high))/2*10/12if 'K' not in data and '月' in data:low,high = re.findall(pattern = pat,string = data)[0]return (float(low) + float(high))/2/1000data_wx['salary_clean'] = data_wx['salary'].apply(get_salary)
#round() 方法返回浮点数x的四舍五入值,这里设置的是保留一位小数
data_wx['salary_clean'] = np.round(data_wx['salary_clean'], 1)
data_wx.sample(5)运行结果:

JobLeadChina数据清洗
我们上边把我们合并的表格数据已经清洗好了,接下来我们接着对“JobLeadChina”数据进行清洗、整理,我们先看一下数据内容。
data_jlc = pd.read_csv(r'E:\DataAnalysis\interesting-python-master\interesting-python-master\ESL\jobleadchina.csv')
data_jlc.sample(5)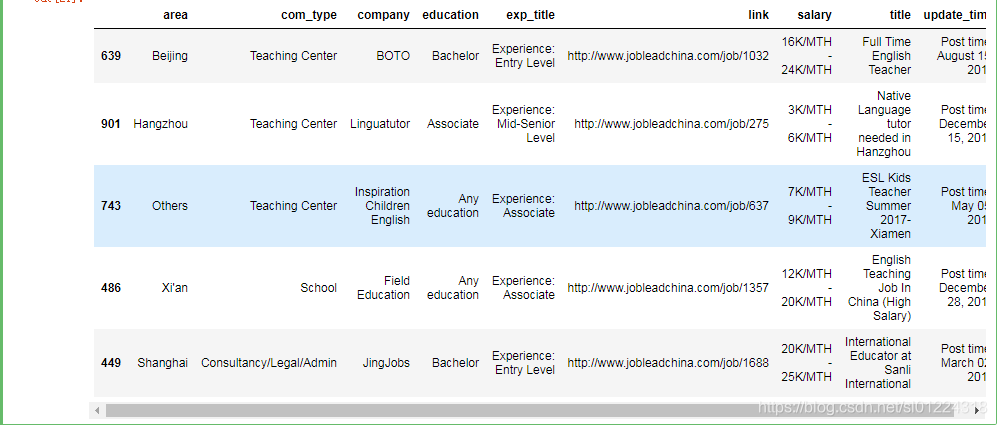
接着清洗出exp_title列的数据
#进行去重操作
data_jlc['exp_title'].unique()
data_jlc['exp_title_clean'] = data_jlc['exp_title'].str.split(':',expand = True)[1]
data_jlc.sample(5)清洗后结果:

清洗出salary:
data_jlc['salary'].unique()def get_salary_jlc(data):#正则表达式pat_jlc = r"(.*)K/MTH - (.*)K/MTH"if '00' in data:low,high = re.findall(pattern = pat_jlc,string = data)[0]return (float(low) + float(high))/2/1000else:low,high =re.findall(pattern = pat_jlc,string = data)[0]return (float(low) + float(high))/2data_jlc['salary_clean'] = data_jlc['salary'].apply(get_salary_jlc)
data_jlc.sample(5)清洗结果:

数据分析
洋外教的工资真的高吗
#删除data_wx中“salary_clean”> 40的值
data_wx.drop(data_wx[data_wx['salary_clean']>40].index, inplace=True)
#data_wx.sample(5)
data_wx['teacher_type'] = '中教'
data_jlc['teacher_type'] = '外教'
#把data_wx和data_jlc中的salary_calen和teacher_type的列进行连接
data_salary = pd.concat([data_wx[['salary_clean', 'teacher_type']],data_jlc[['salary_clean', 'teacher_type']]])
print(data_salary.sample(5))
#修改data_salary的行名称
data_salary.rename(columns={'salary_clean':'工资', 'teacher_type':'教师类型'}, inplace=True)
#print(data_salary.sample(5))#求外教工资平均值
np.round(data_jlc['salary_clean'].mean(), 1)
#中教工资平均值
np.round(data_wx['salary_clean'].mean(), 1)从图片中可以看出,外教薪资平均水平要高于中教薪资很高。

不同级别和工作年限的工资比较
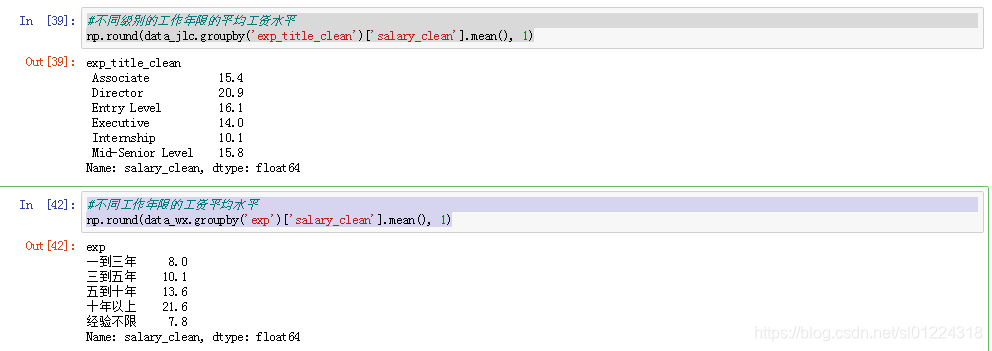
#不同级别的工作年限的平均工资水平
np.round(data_jlc.groupby('exp_title_clean')['salary_clean'].mean(), 1)#不同工作年限的工资平均水平
np.round(data_wx.groupby('exp')['salary_clean'].mean(), 1)比较不同工作年限和经验的做个比较,从下图中可以看出,工作经验10年以下的薪资水平外普遍比国内高,10年工作以上的中教工资水平略高一些。
#图形绘制比较不同工作经验的英语外教与中教工资对比
from pyecharts import Barattr = ['经验不限\nInternship', '一到三年\nEntry Level', '三到五年\nExecutive','五到十年\nMid-Senior', '十年以上\nDirector']
value1 = [10.1, 15.8, 14.0, 15.8, 20.9]
value2 = [7.8, 8.0, 10.1, 13.6, 21.6]bar = Bar("不同工作经验的英语外教与中教工资对比", width = 700,height=500)
bar.add("外教", attr, value1, xaxis_label_textsize=18, legend_top=30,yaxis_label_textsize=20, is_label_show=True)
bar.add("中教", attr, value2, xaxis_label_textsize=18, legend_top=30,yaxis_label_textsize=20, is_label_show=True)
bar.render('不同工作经验的英语外教与中教工资对比.html')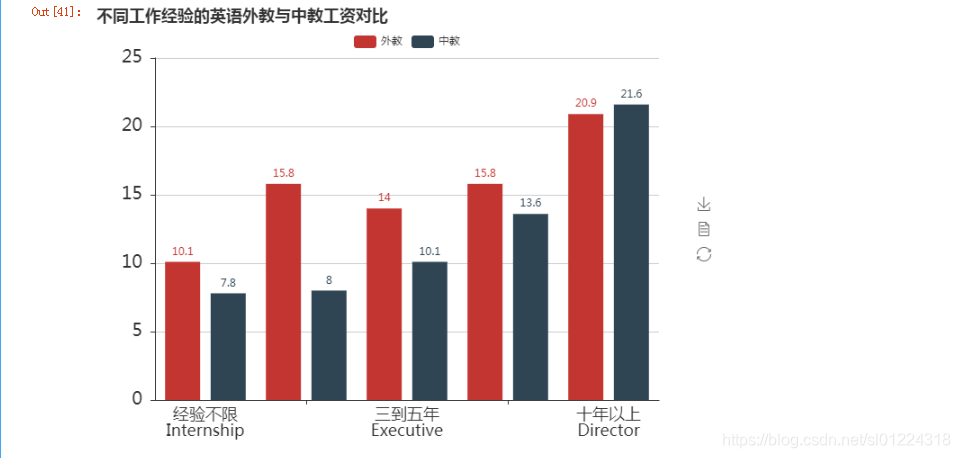
学历水平对薪资的影响
都说学历是个敲门砖,那这个敲门砖对薪资的影响大吗?经过代码处理和图片展示,可以看出学历对中教有很大的影响,对外教的影响不是很大,看到这我酸了,一个“哎”字来表达此刻心情。
# 通过学历进行对比,即学历对工资水平的影响
#data_jlc.sample(5)
#data_jlc.groupby('education')['salary_clean'].count().mean()
# t = data_jlc.groupby('education')['salary_clean'].value_counts()
# print(t)
np.round(data_jlc.groupby('education')['salary_clean'].mean(),1)data_wx.loc[data_wx['degree']=='中专', 'degree'] = '高中'
np.round(data_wx.groupby('degree')['salary_clean'].mean(),1)#绘制条形图比较不同学历的英语外教与中教工资对比
attr = ['学历不限\nAny education', '高中', '大专\nAssociate','本科\nBachelor', '硕士\nMaster']
value1 = [13.9, np.nan, 12.8, 16.3, 21.3]
value2 = [7.5, 4.4, 6.4, 9.2, 11.0]bar = Bar("不同学历的英语外教与中教工资对比", width = 700,height=500)
bar.add("外教", attr, value1, xaxis_label_textsize=15, legend_top=30,yaxis_label_textsize=20, is_label_show=True)
bar.add("中教", attr, value2, xaxis_label_textsize=15, legend_top=30,yaxis_label_textsize=20, is_label_show=True)
bar.render("不同学历的英语外教与中教工资对比.html")
bar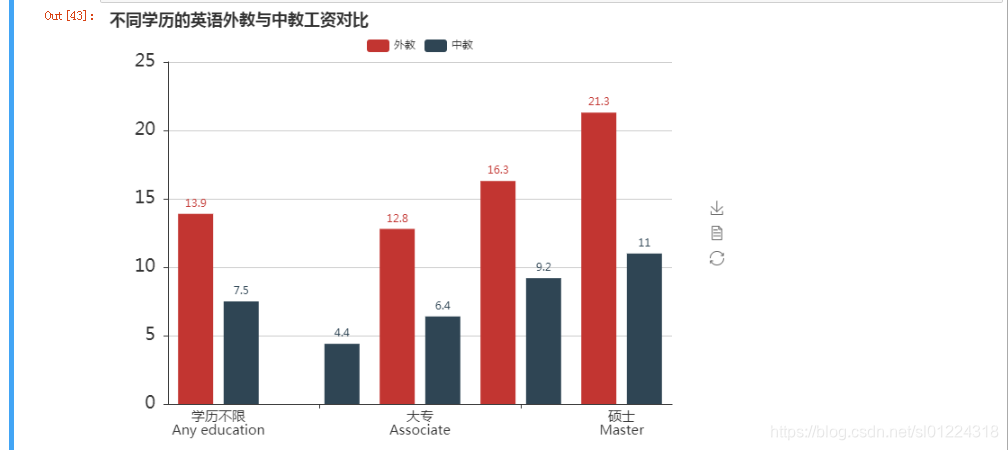
什么机构在招聘洋外教?
到底是哪些人和公司需要外教呢? 通过分析可知培训机构和学校对外教需求量最大,这是因为什么导致的,结果不得而知,大家可以YY一下。
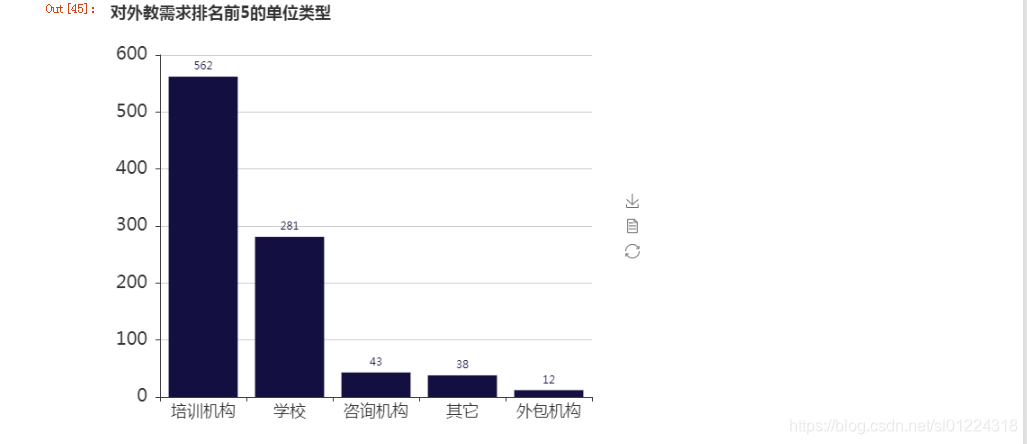
洋外教来源真的很乱吗?
外教一般以上的是男性,外教男性看来还是比女性吃香的,哈哈。
data_gm.sample(5)
sex = data_gm['Sex'].value_counts()
#data_gm['Sex']#外教性别比例
from pyecharts import Piepie =Pie('性别比例',background_color = 'white', width=500, height=500)
pie.add('',['男性', '女性', '未知'],sex.values, center = [50,50],radius=[25, 50],rosetype='radius', is_label_show=True,legend_text_size=16, label_text_size=16)
pie.render('外教性别比例.html')
pie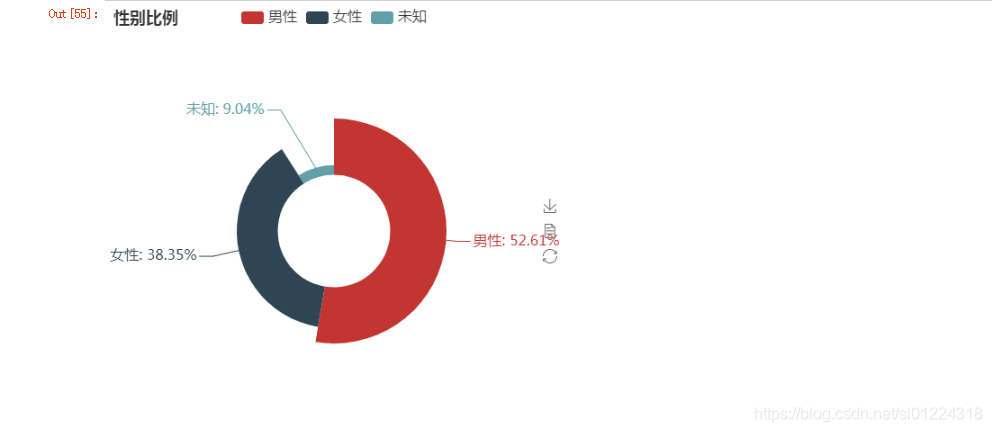
总结:
从以上分析看出,在不同工作年限和学历大致相同的情况下,外教工资更高一些,期中培训机构和学校对外教的需求量更大, 而且男性外教比女性外教多。
这个和大家分享的内容,我大概用了4天时间来完成,完整代码和数据有需要的可以私信给我,我看到后会及时发给各位,文章写得不好的地方请大家海涵并且嘴下留情,如果能给本人提出一些改进意见的话是再好不过了,在此谢谢大家!
这篇关于没经验学历的外教竟然这么吃香,我酸了!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!