本文主要是介绍第7章“链接”:静态链接、符号表、符号解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 7.2 静态连接
- 7.3 目标文件
- 7.4 可重定位目标文件
- 7.5 符号和符号表
- 7.6 符号解析
- 7.6.1 链接器如何解析多处定义的全局符号
- 7.6.2 与静态库链接
- 7.6.3 链接器如何使用静态库来解析引用
7.2 静态连接
像 Unix ld 程序这样的静态链接器(static linker)以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的可以加载和运行的可执行目标文件作为输出。
输入的可重定位目标文件由各种不同的代码 和 数据节(section)组成。指令在一个节中,初始化的全局变量在另一个节中,而未初始化的变量又在另一个节中。
为了创建可执行文件,链接器必须完成两个主要任务:
- 符号解析(symbol resolution)。目标文件定义和引用符号。符号解析的目的是将每个符号引用和一个符号定义联系起来。
- 重定位(relocation)。编译器和汇编器生成从地址零开始的代码和数据节。链接器通过把每个符号定义与一个存储器位置联系起来,然后修改所有这些符号的引用,使得它们指向这个存储器位置,从而重定位这些节。
关于链接器的一些基本事实:目标文件纯粹是字节块的集合。这些块中,有些包含程序代码,有些则包含程序数据,而其他的则包含指导链接器和加载器的数据结构。链接器将这些块连接起来,确定被链接块的运行时位置,并且修改代码和数据块中的各种位置。链接器对目标机器了解甚少,产生目标文件的编译器和汇编器已经完成了大部分工作。
7.3 目标文件
目标文件有三种形式:
- 可重定位目标文件。包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行目标文件。
- 可执行目标文件。包含二进制代码和数据,其形式可以被直接拷贝到存储器并执行。
- 共享目标文件。一种特殊类型的可重定位目标文件,可以在加载或运行时,被动态地加载到存储器并链接。
编译器和汇编器生成可重定位目标文件(包括共享目标文件)。链接器生成可执行目标文件。
从技术上来说,一个目标模块(object module)就是一个字节序列,而一个目标文件(object file)就是一个存放在磁盘文件中的目标模块。
各个系统之间,目标文件格式都不相同。
- 第一个从贝尔实验室诞生的Unix 系统使用的是
a.out(至今,可执行文件仍然指的是a.out文件)。 - System V Unix 的早期版本使用的是 COFF(Common Object File format,一般目标文件格式)。
- Windows 使用的是 COFF 的一个变种,叫做 PE(Portable Executable,可移植可执行)格式。
- 现代Unix系统——比如Linux,还有System V Unix 后来的版本,各种 BSD Unix,以及 SUN Solaris——使用的是Unix ELF(Executable and Linkable Format,可执行和可链接格式)。
不管是哪种格式,基本的概念是相似的。
7.4 可重定位目标文件
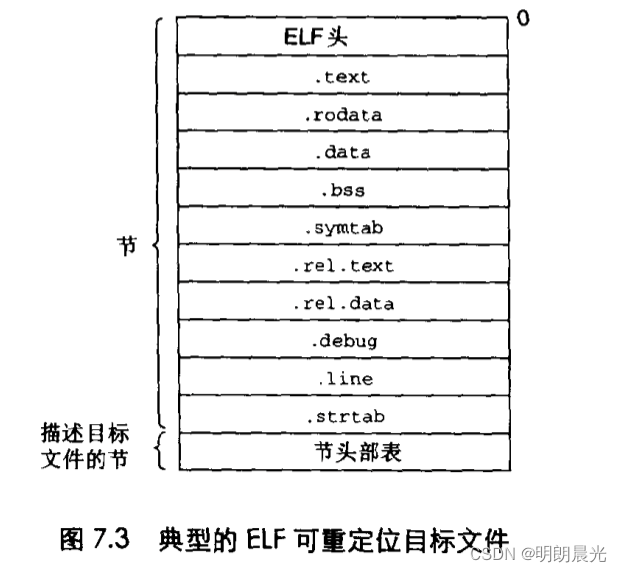
上图展示了一个典型的 ELF 可重定位目标文件。
ELF头(ELF header)以一个 16 字节的序列开始,该序列描述了字的大小和生成该文件的系统的字节顺序。ELF 头剩下的部分包含帮助链接器解析和解释目标文件的信息。其中包括 ELF 头的大小、目标文件的类型(如可重定位、可执行或共享)、机器类型(如IA32)、节头部表(section header table)的文件偏移,以及节头部表中的表目大小和数量。不同节的位置和大小是由节头部表描述的,其中目标文件中每个节都有一个固定大小的表目(entry)。
夹在 ELF 头和节头部表自检的都是节。一个典型的 ELF 可重定位目标文件包含下面几个节:
.txt:已编译程序的机器代码。.rodata:只读数据,比如printf语句中的格式串和开关(switch)语句的跳转表。.data:已初始化的全局 C 变量。局部 C 变量在运行时被保存在栈中,既不出现在.data节中,也不出现在.bss节中。.bss:未初始化的全局 C 变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。目标文件格式区分初始化和未初始化变量是为了空间效率:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。.symtab:一个符号表(symbol table),它存放在程序中被定义和引用的函数和全局变量的信息。并非必须通过-g选项来编译一个程序得到符号表信息,实际上,每个可重定位目标文件在.symtab中都有一张符号表。然而,和编译器的符号表不同,.symtab符号表不包含局部变量的表目。.rel.text:当链接器把这个目标文件和其他文件结合时,.text节中的许多位置都需要修改。一般而言,任何调用外部函数或者引用全局变量的指令都需要修改。另一方面,调用本地函数的指令则不需要修改。注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非使用者显式地指示链接器包含这些信息。.rel.data:被模块定义或引用的任何全局变量的信息。一般而言,任何已初始化全局变量的初始值是全局变量或者外部定义函数的地址都需要被修改。.debug:一个调试符号表,其有些表目是程序中定义的局部变量和类型定义,有些表目是程序中定义和引用的全局变量,有些是原始的C源文件。只有以-g选项调用编译驱动程序时,才会得到这张表。.line:原始 C 源程序中的行号和.text节中机器指令之间的映射。只有以-g选项调用编译驱动程序时,才会得到这张表。.strtab:一个字符串表,其内容包括.symtab和.debug节中的符号表,以及节头部中的节名字。字符串表就是以null结尾的字符串序列。
bss本是汇编语言中 “块存储开始(Block Storage Start)” 指令的首字母缩写,沿用至今,一个记住区分 .data 和 .bss 节的简单方法是把 “bss” 看成是 “更好地节省空间(Better Save Space)” 的缩写。
7.5 符号和符号表
每个可重定位目标模块 m 都有一个符号表,它包含 m 定义和引用的符号的信息。在链接器上下文中,有三种不同的符号:
-
由
m定义并能被其他模块引用的全局符号。全局链接器符号对应于非静态的 C 函数 以及 被定义为不带 C 的 static 属性的全局变量。 -
由其他模块定义并被模块
m引用的 全局符号。这些符号称为 外部符号(external),对应于定义在其他模块中的 C 函数和变量。 -
只被模块
m定义和引用的本地符号。有的本地链接器符号对应于带 static 属性的 C 函数和全局变量。这些符号在模块m中的任何地方都是可见的,但是不能被其他模块引用。目标文件中对应于模块m的节和相应源文件的名字也能获得本地符号。
认识到本地链接器符号和本地程序变量的不同是很重要的。.symtab 中的符号表不包含对应于本地非静态程序变量的任何符号。这些符号在运行时在栈中被管理,链接器对此类符号不感兴趣。
有趣的是,定义为带有 C static 属性的本地过程变量是不在栈中管理的。取而代之,编译器在 .data 和 .bss 中为每个定义分配空间,并在符号表中创建一个有唯一名字的本地链接器符号。比如,假设在同一模块中的两个函数定义了一个静态本地变量 x x x:
int f()
{static int x = 0;return x;
}int g()
{static int x = 1;return x;
}
在这种情况下,编译器在 .bss 中为两个整数分配空间,并引出(export)两个唯一的本地链接器符号给汇编器。比如,它可以用 x.1 表示函数 f 中的定义,而用 x.2 表示函数 g 中的定义。
!!! 利用 static 属性隐藏变量和函数的名字!!!
C 程序员使用 static 属性在模块内部隐藏变量和函数声明,就像在 Java 和 C++ 中使用 public 和 private 声明一样。C源代码文件扮演模块的角色,任何声明带有 static 属性的全局变量或者函数都是模块私有的。 类似地,任何声明为不带 static 属性的全局变量和函数都是公共的,可以被其他模块访问。 尽可能用 static 属性来保护你的变量和函数是很好的编程习惯。
符号表是由汇编器构造的,使用编译器输出到汇编语言 .s 文件中的符号。.symtab 节中包含 ELF 符号表。这张符号表包含一个关于表目的数组。
下图展示了每个表目 (entry) 的格式:

type 和 binding 都是 4 位的。
-
name是字符串表中的字节偏移,指向符号的以null结尾的字符串名字。 -
value是符号的地址。对于可重定位的模块来说,value 是距定义目标的节的起始位置的偏移。对于可执行目标文件来说,该值是一个绝对运行时地址。 -
size是目标的大小(以字节计算)。 -
type通常要么是数据,要么是函数。符号表还可以包含各个节的表目,以及对应原始源文件的路径名的表目。所以这些目标的类型也有所不同。 -
binding域表示符号是本地的还是全局的。
每个符号都和目标文件的某个节相关联,由 section 域表示,该域也是一个到节头表的索引。
有三个特殊的伪节(pseudosection),它们在节头表中是没有表目的:
- ABS 代表不该被重定位的符号,
- UNDEF 代表未定义的符号(如在本目标模块中引用,但是却在其他地方定义的符号),
- COMMON 表示还未被分配位置的未初始化的数据目标。对于 COMMON 符号,value 域给出对齐请求,而 size 给出最小的大小。
比如,下面是 main.o 的符号表中的最后三个表目,通过 GNU READELF 工具显示出来。开始的 8 个表目没有显示出来,是链接器内部使用的本地符号。

该例中:
- 看到一个关于全局符号
buf定义的表目,它是一个位于.data节中偏移为零(即value)处的 8 字节目标。 - 其后跟随着的是全局符号
main的定义,它是一个位于.text节中偏移为零处的 17 字节函数。 - 最后一个表目来自对外部符号
swap的引用。 - READELF 通过一个整数索引来标识每个节。
Ndx = 1表示.text节,而Ndx = 3表示.data节。
相似地,下面是 swap.o 的符号表表目:

- 一个关于全局符号
bufp0定义的表目,它是从.data中偏移为零处开始的一个 4 字节的已初始化目标。 - 下一个符号来自
bufp0的初始化代码中的对外部符号buf的引用。 - 紧随的是全局符号
swap,它是一个位于.text中偏移为零处的 39 字节的函数。 - 最后一个表目是全局符号
bufp1,它是一个未初始化的 4 字节数据目标(要求4字节对齐),最终当这个模块被链接时它将作为一个.bss目标分配。
7.6 符号解析
链接器解析符号引用的方法是将每个引用与它输入的可重定位目标文件的符号表中的一个确定的符号定义联系起来。
对那些和引用定义在相同模块中的本地符号的引用,符号解析是非常简单明了的。编译器只允许每个模块中的每个本地符号只有一个定义。编译器还确保静态本地变量,它们也会有本地链接器符号,拥有唯一的名字。
不过,对全局符号的引用解析就棘手得多。当编译器遇到一个不是在当前模块中定义的符号(变量或函数名)时,它会假设该符号是在其他某个模块中定义的,生成一个链接器符号表表目,并把它交给链接器处理。如果链接器在它的任何输入模块中都找不到这个被引用的符号,它就输出一条错误信息并终止。
举个例子:
void foo();int main()
{foo();return 0;
}
编译器会没有障碍地运行,但是当链接器无法解析对 foo 的引用时,它会终止:
unix> gcc -Wall -O2 -o linkerro linkerro.c
/tmp/ccRLzOtK.o: In function `main':
linkerro.c:(.text.startup+0x7): undefined reference to `foo'
collect2: error: ld returned 1 exit status
全局符号的引用解析棘手还因为相同的符号会被多个目标文件定义。 在这种情况下,链接器必须要么标志一个错误,要么以某种方法选出一个定义并抛弃其他定义。Unix 系统采纳的方法包括编译器、汇编器和链接器之间的协作,这样也可能给不知情的程序员带来一些令人烦恼的问题。
对C++和Java中链接器符号的毁坏(mangling)
C++ 和 Java 都允许重载方法,这些方法在源代码中有相同的名字,却有不同的参数列表。链接器是如何区别这些不同的重载方法之间的差异呢?C++ 和 Java 中能使用重载函数,是因为编译器将每个唯一的方法和参数列表组合编码成一个对链接器来说唯一的名字。 这种编码过程叫做毁坏(mangling),而相反的过程叫做恢复(demangling)。
幸运的是,C++ 和 Java 使用兼容的毁坏策略。一个已毁坏类的名字是由名字中字符的整数数量,后面跟原始名字组成的。 比如,类 Foo 被编码成 3Foo。方法被编码为原始方法名,后面加上__,加上已毁坏类的类名,再加上每个参数的一个字母。 比如,Foo::bar(int, long)被编码为bar__3Fooil。毁坏全局变量和模板名字的策略是相似的。
7.6.1 链接器如何解析多处定义的全局符号
在编译时,编译器输出每个全局符号给汇编器,或者是强(strong),或者是弱(weak),而汇编器把这个信息隐含地编码在可重定位目标文件的符号表里。
函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
//main.c
void swap();int buf[2] = {1, 2};int main()
{swap();return 0;
}
//swap.c
extern int buf[];int *bufp0 = &buf[0];
int *bufp1;void swap()
{int temp;bufp1 = &buf[1];temp = *bufp0;*bufp0 = *bufp1;*bufp1 = temp;
}
对于上述两个源文件,buf、bufp0、main 和 swap 是强符号,bufp1 是弱符号。
根据强弱符号的定义,Unix 链接器使用下面的规则来处理多处定义的符号:
- 规则1:不允许有多个强符号
- 规则2:如果有一个强符号和多个弱符号,那么选择强符号
- 规则3:如果有多个弱符号,那么从这些弱符号中任意选择一个
下面举例说明各个规则使用的例子
- 规则1
举个例子,假设我们试图编译和链接下面两个 C 模块:
//foo1.c
int main()
{return 0;
}
//bar1.c
int main()
{return 0;
}
该例子将会使得链接器生成一条错误信息,因为强符号 main 被定义了多次(规则1):
/tmp/ccaW04iW.o: In function `main':
bar1.c:(.text+0x0): multiple definition of `main'
/tmp/ccllxhpg.o:foo1.c:(.text+0x0): first defined here
collect2: error: ld returned 1 exit status
类似地,链接器对下面的模块也会生成一条错误信息,因为强符号 x 被定义了两次(规则1):
//foo2.c
int x = 15213;int main()
{return 0;
}
//bar2.c
int x = 15213;void f()
{}
错误信息:
/tmp/ccpiODcR.o:(.data+0x0): multiple definition of `x'
/tmp/cc1erLo2.o:(.data+0x0): first defined here
collect2: error: ld returned 1 exit status
- 规则2
然而,如果在一个模块里 x 未被初始化,那么链接器将安静地选择定义在另一个模块中的强符号(规则2):
//foo3.c
#include<stdio.h>void f(void);int x = 15213;int main()
{f();printf("x = %d\n", x);return 0;
}
//bar3.c
int x;void f()
{x = 15212;
}
没有任何错误出现,运行时,函数 f 将 x 的值由15213 改为 15212,surprise!?
unix> gcc -o foobar3 foo3.c bar3.c
unix> ./foobar3
x = 15212
- 规则3
如果 x 有两个弱定义,也会发生相同的事情(规则3):
//foo4.c
#include <stdio.h>
void f(void);int x;int main()
{x = 15213;f();printf("x = %d\n", x);return 0;
}
//bar4.c
int x;void f()
{x = 15212;
}
运行结果:
unix> gcc -o foobar4 foo4.c bar4.c
unix> ./foobar4
x = 15212
规则2 和 规则3 的应用会造成一些不易察觉的运行时错误,对于不知情的程序员来说,是很难理解的,尤其是如果重复的符号定义还有不同的类型时。看如下这个例子,x 在一个模块中定义为 int,另一个模块中定义为double:
//foo5.c
#include<stdio.h>void f(void);int x = 15213;
int y = 15212;int main()
{f();printf("x = 0x%x y = 0x%x \n", x, y);
}
//bar5.c
double x;void f()
{x = -0.0;
}
在一台IA32/Linux 机器上,double 类型是 8 个字节,而 int 类型是 4 个字节。因此,bar5.c 的第6行中的赋值 x = -0.0 将用负数的双精度浮点表示覆盖存储器中 x 和 y 的位置(foo5.c 中的第6行和第7行)!
运行结果:
unix> gcc -o foobar5 foo5.c bar5.c
unix> ./foobar5
x = 0x0 y = 0x80000000
因为它是默默发生的,编译系统不会给出警告,且通常要在程序执行很久之后才表现出来,且远离错误的发生地。在一个拥有几百个模块的大型系统中,这种类型的错误非常难以修正,尤其因为许多程序员并不知道链接器是如何工作的。当你怀疑有此类错误时,带像 GCC-warn-common 这样的选项调用链接器,这个选项告诉链接器,在解释多定义的全局符号定义时,输出一条警告信息。
7.6.2 与静态库链接
迄今为止,都是假设链接器读取一组可重定位目标文件,并把它们链接起来,称为一个输出的可执行文件。
实际上,所有的编译系统都提供一种机制,将所有相关的目标模块打包为一个单独的文件,称为静态库(static library) ,它可以用作链接器的输入。当链接器构造一个输出的可执行文件时,它只拷贝静态库里被应用程序引用的目标模块。
为什么系统要支持库的概念?
以 ANSI C 为例,它定义了一组广泛的标准 I/O、串操作和整数算术函数,例如 atoi、printf、scanf 和 random。它们在 libc.a 库中,对每个 C 程序来说都是可用的。ANSI C 还在 libm.a 库中定义了一组广泛的算术函数,例如 sin、cos 和 sqrt。
如果不使用静态库,编译器开发人员会使用什么方法来向用户提供这些函数?
- 一种方法是让编译器辨认出对标准函数的调用,并直接生成相应的代码。Pascal,只提供了一小部分标准函数,采用的就是这种方法,但该方法对C而言不合适,因为C 标准定义了大量的标准函数。这种方法给编译器增加显著的复杂性,且每次添加、删除或修改一个标准函数时,就需要一个新的编译器版本。然而,对应用程序员而言,这种方法会是非常方便的,因为标准函数将总是可用的。
- 另一种方法是将所有的标准 C 函数都放在一个单独的可重定位目标模块中——比如
libc.o中——应用程序员可以把这个模块链接到他们的可执行文件中:
这种方法的优点是它将编译器的实现与标准函数的实现分离开来,并且仍然对程序员保持适度的便利。然而,一个很大的缺点是系统中每个可执行文件现在都包含着一份标准函数集合的完全拷贝,这对磁盘空间是极大的浪费。(在一个典型系统上,unix> gcc main.c /usr/lib/libc.olibc.a大约是 8 MB,而libm.a大约是 1MB)更糟的是,每个正在运行的程序都将它自己的这些函数拷贝放在存储器中,这又是极度浪费存储器的。另一个大的缺点是,对任何标准函数的任何改变,无论大小,都要求库的开发人员重新编译整个源文件,这是一个非常耗时的操作,使得标准函数的开发和维护变得复杂。 - 还有一种方法是通过为每个标准函数创建一个分离的可重定位文件,把它们存放在一个为大家所知的目录中来解决其中一些问题。然而,这种方法要求应用程序员显式地链接合适的目标模块到它们的可执行文件中,这是一个容易出错且耗时的过程:
unix> gcc main.c /usr/lib/printf.o /usr/lib/scanf.o
静态库概念被提出来以解决这些不同方法的缺点。相关的函数可以被编译为独立的目标模块,然后封装成一个单独的静态库文件。然后,应用程序可以通过在命令行上指定单独的文件名字来使用这些在库中定义的函数。比如,使用标准 C 库和数学库中函数的程序可以用形式如下的命令行来编译和链接:
unix> gcc main.c /usr/lib/libm.a /usr/lib/libc.a ...
在链接时,链接器只拷贝被程序引用的目标模块,这就减少了可执行文件在磁盘和存储器中的大小。另一方面,应用程序员只需要包含较少的库文件的名字(实际上,C编译器驱动总是传送 libc.a 给链接器,所以前面提到的对 libc.a 的引用是不必要的)。
在 Unix 系统中,静态库以一种称为存档(archive)的特殊文件格式存放在磁盘中。存档文件是一组连接起来的可重定位目标文件的集合,有一个头部描述每个成员目标文件的大小和位置。存档文件名由后缀 .a 标识。
举个例子,假设想在一个叫做 libvector.a 的静态库中提供如下的向量例程:
//vector.h
#ifndef _VECTOR_H
#define _VECTOR_H
void addvec(int *, int *, int *, int);
void multvec(int *, int *, int *, int);
#endif
//addvec.c
void addvec(int *x, int *y, int *z, int n)
{int i;for (i = 0; i < n; i++)z[i] = x[i] + y[i];
}
//multvec.c
void multvec(int *x, int *y, int *z, int n)
{int i;for (i = 0; i < n; i++)z[i] = x[i] * y[i];
}
创建库 libvector.a,使用AR工具,如下:
unix> gcc -c addvec.c multvec.c
unix> ar rcs libvector.a addvec.o multvec.o
为使用这个库,编写一个应用 main2.c,它调用 addvec 库例程:
//main2.c
//此程序调用了静态libvector.a库中的成员函数
#include<stdio.h>
#include "vector.h"int x[2] = {1, 2};
int y[2] = {3, 4};
int z[2];int main()
{addvec(x, y, z, 2);printf("z = [%d %d]\n", z[0], z[1]);return 0;
}
为创建这个可执行文件,将编译和链接输入文件 main.o 和 libvector.a:
unix> gcc -O2 -c main2.c
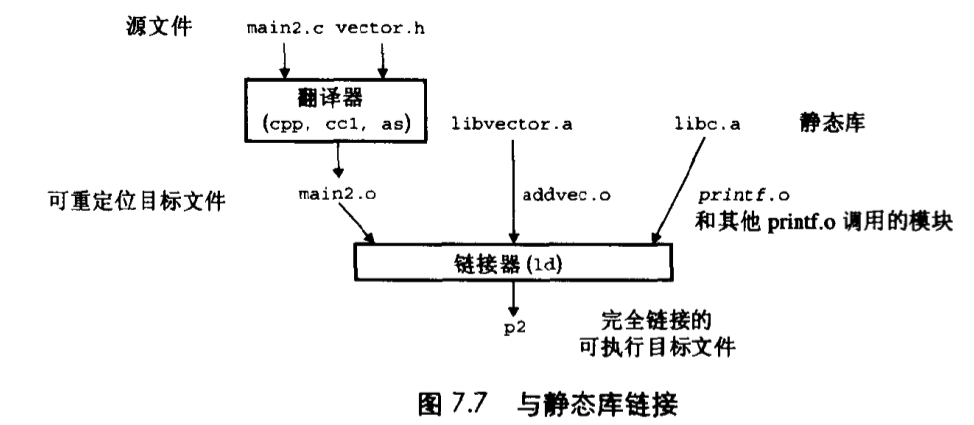
unix> gcc -static -o p2 main2.o ./libvector.a
-static 参数告诉编译器驱动程序,链接器应该构建一个完全链接的可执行目标文件,它可以加载到存储器运行,在加载时无须更进一步的连接了。当链接器运行时,它判定addvec.o 定义的 addvec 符号是被 main.o 引用的,所以它拷贝 addvec.o 到可执行文件。因为程序不引用任何由 multvec.o 定义的符号,所以链接器就不会拷贝这个模块到可执行文件。链接器还会从 libc.a 拷贝 printf.o 模块,以及许多 C 运行时系统中的模块。
下图概括了链接器的行为:
7.6.3 链接器如何使用静态库来解析引用
虽然静态库是很有用且重要的工具,但是它们同时也是令人迷惑的源头,因为Unix 链接器使用它们解析外部引用的方式是令人困惑的。在符号解析阶段,链接器从左到右按照它们在编译器驱动程序命令行上出现的相同顺序来扫描可重定位目标文件和存档文件。(驱动程序自动将命令行中所有的.c 文件翻译为 .o 文件。)
在这次扫描中,链接器维持三个集合:
① 可重定位目标文件的集合 E,这个集合中的文件会被合并起来形成可执行文件;
② 一个未解析的符号(也就是,引用了但是尚未定义的符号)集合 U
③一个在前面输入文件中已定义的符号集合 D。
初始地,E、U 和 D 都是空的。
- 对于命令行上的每个输入文件
f,链接器会判断f是一个目标文件还是一个存档文件(carchive)。如果f是一个目标文件,则链接器把f添加到 E,修改 U 和 D 来反映f中的符号定义和引用,并继续下一个输入文件。 - 如果
f是一个存档文件,那么链接器就尝试匹配 U 中未解析的符号和由存档文件成员定义的符号。如果某个存档文件成员m,定义了一个符号来解析 U 中的一个引用,那么就将m加到 E 中,并且链接器修改 U 和 D 来反映m中的符号定义和引用。对存档文件中所有的成员目标文件都反复进行这个过程,直到 U 和 D 都不再发生变化。在此时,任何不包含在 E 中的成员目标文件都丢弃,而链接器将继续下一个输入文件。 - 如果当链接器完成对命令行上输入文件的扫描后,U 是非空的,那么链接器就会输出一个错误并终止。否则,它会合并和重定位 E 中的目标文件,从而构建输出的可执行文件。
不幸的是,这种算法会导致一些令人困扰的链接时错误,因为命令行上的库和目标文件的顺序非常重要。如果在命令行中,定义一个符号的库出现在引用这个符号的目标文件之前,那么引用就不能被解析,链接会失败。
比如,考虑下面的命令行发生了什么?
unix> gcc -static ./libvector.a main2.c
/tmp/cc6HvjOW.o: In function `main':
main2.c:(.text+0x1f): undefined reference to `addvec'
collect2: error: ld returned 1 exit status
在处理 libvector.a 时,U 是空的,所以没有 libvector.a 中的成员目标文件会添加到 E 中。因此,对 addvec 的引用是绝不会被解析的,所以链接器会产生一条错误信息并终止。
关于库的一般准则是将它们放在命令行的结尾。如果各个库的成员是相互独立的——也就是说没有成员引用另一个成员定义的符号——那么这些库就可以以任何顺序放置在命令行的结尾处。
另一方面,如果库不是相互独立的,那么它们必须排序,使得对于每个被存档文件的成员外部引用的符号 s,在命令行中至少有一个 s 的定义是在对s 的引用之后。比如,假设 foo.c 调用 libx.a 和 libz.a 中的函数, 而这两个库又调用liby.a 中的函数。那么命令行中 libx.a 和 libz.a 必须处在 liby.a 之前:
unix> gcc foo.c libx.a libz.a liby.a
如果需要满足依赖需求,可以在命令行上重复库。比如,假设 foo.c 调用 libx.a 中的函数,该库又调用 liby.a 中的函数,而 liby.a 又调用 libx.a 中的函数。那么 libx.a 必须在命令行上重复出现:
unix> gcc foo.c libx.a liby.a libx.a
这篇关于第7章“链接”:静态链接、符号表、符号解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



