本文主要是介绍初露锋芒,多本SCI首年中科院分区为1区(附名单),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
12月27日,2023年中科院分区正式发布。2023年期刊分区表在秉承方法科学、数据客观的基础上,发布基于“期刊超越指数(JSI)”的升级版。今年期刊分区表包括SCIE、SSCI、A&HCI,以及ESCI中国期刊,共设置了包括自然科学、社会科学和人文科学在内的21个大类。
据统计,目前有1区期刊944本,2区期刊1683本,3区期刊2343本,4区期刊4564本。
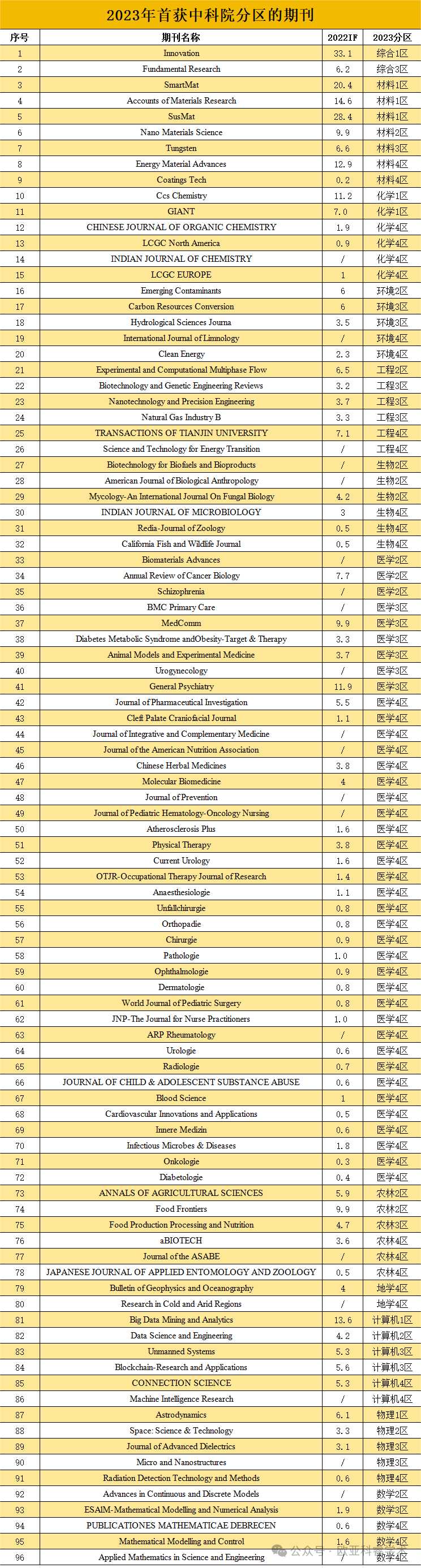
期刊分区有升有降,小编发现今年首次获得中科院分区的期刊,共计有96本,具体名单如下:
更多学术热点尽在GZ号“欧亚科睿学术”
版权声明:本文信息来源中科院文献情报中心分区表。
分享只为学术交流,如涉及侵权问题请联系我们,我们将及时修改或删除。
这篇关于初露锋芒,多本SCI首年中科院分区为1区(附名单)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







