本文主要是介绍【C/C++】结构体内存对齐 ----- 面试必考(超详细解析,小白一看就懂!!!),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、前言
二、引出 ---- 结构体内存对齐
🍎结构体偏移量计算:offsetof
🥝结构体内存对齐详解
💦规则介绍(重点!!)
💦例题解析
三、习题演练
🍍练习①
🍐练习②
四、为什么存在内存对齐?
1、平台原因(移植原因)
2、性能原因
五、如何修改默认对齐数
六、实战演练
七、共勉
一、前言
结构体 大家都应该了解过,可是大家是否会去深究结构体中的---结构体内存问题呢?由于最近在找实习的过程中,每次都会被问到结构体内存大小的问题,每次都是以回答错误而结束面试。
所以现在现在才醒悟过来,才知道这些知识点有多么的重要,所以咬紧牙,把这个内容的知识点记录下来!
二、引出 ---- 结构体内存对齐
在结构体章节,我们掌握了结构体的基本使用,但是现在我要你去计算一个结构体的大小,你会怎么做呢?
- 现在我定义了两个结构体,通过观察可以发现它们内部的成员变量都是一样的,均有
c1、c2、i三个成员变量,那此时分别去计算它们两个结构体的大小, 最后的结果会是多少呢?会是一样的吗
struct S1 {char c1;int i;char c2;
};struct S2 {char c1;char c2;int i;
};int main(void)
{printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));return 0;
}
- 通过运行可以发现两者是不一样的,这是为什么呢?如果你没有结构体内存对齐的相关知识,那相信你一定会这么去计算:
- 在结构体S1中,
c1的类型为【char】,是1个字节;i的类型是【int】,是4个字节c2的类型为【char】,是1个字节;
- 那么最后的结果就是
1 + 4 + 1 = 6B,可事实呢,原不止这些。

大家仔细的想一下,为什么会出现这样的结果呢?这与结构体内存有什么关系呢?下面我用结构体偏移量计算:offsetof 来给大家详细的解释一下!!
🍎结构体偏移量计算:offsetof
就上面的内容,大家会产生很大的困惑?下面给大家介绍一个宏叫做
offsetof,它可以用来计算结构体成员相对于起始位置的偏移量

它的第一个参数是结构体类型,第二个参数是结构体成员
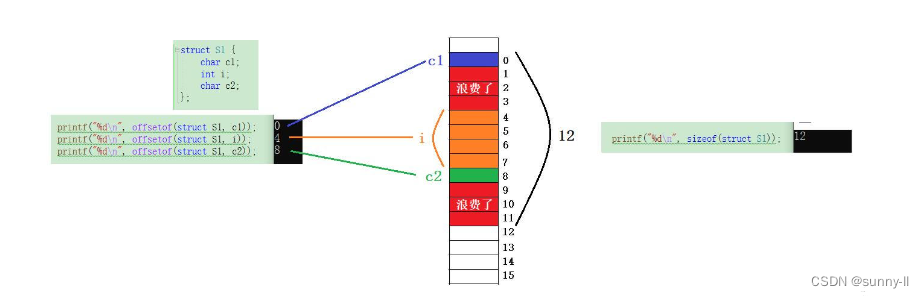
printf("%d\n", offsetof(struct S1, c1));
printf("%d\n", offsetof(struct S1, i));
printf("%d\n", offsetof(struct S1, c2));

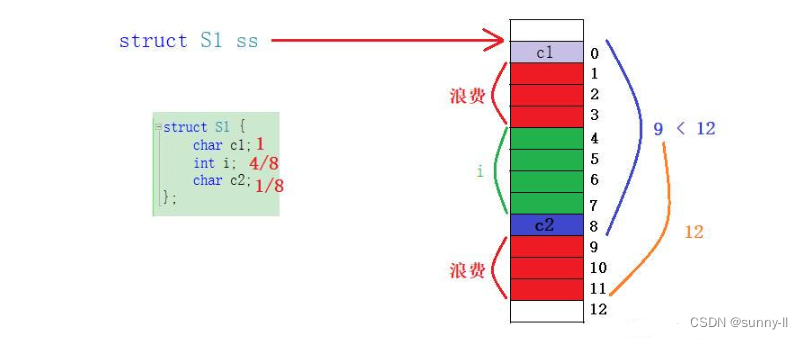
- 最后,计算出来的结果分别是【0】【4】【8】,那我们可以通过画内存图来看看结构体中的三个成员变量在内存中究竟是如何分布的
- 可以看出,因为总的结构体大小为12B,可是在放完这3个成员后中间空出了三个位置,并且对于最后在c放完之后还没有到达12B,所以还得再浪费3个空间的废位置
为什么会出现上面这样的现象呢?对于结构体内存对齐的规则是怎样,让我们继续看下去👇
🥝结构体内存对齐详解
💦规则介绍(重点!!)
- 第一个成员在与结构体变量偏移量为0的地址处
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
【VS中默认的值为8、Linux环境默认不设对齐数(对齐数是结构体成员自身的大小)】- 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
💦例题解析
知晓了上面这些规则后,大部分老铁呢肯定还是会有点懵逼,接下来我们通过例题来回顾上面的规则,这样大家能更好的理解 ----- 结构体的大小该如何计算
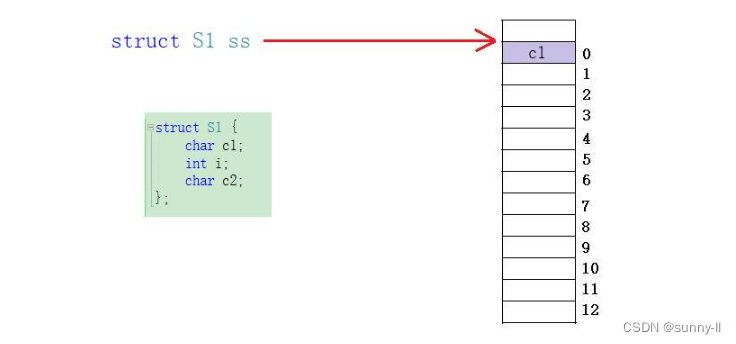
- 假设我这里创建一个结构体变量叫做
ss,它的起始地址就从0开始,所以根据第一条规则,第一个成员变量在与结构体变量偏移量为0的地址处,而且它的类型还是char,所以只占1个内存单元
- 接下去看第二个成员变量
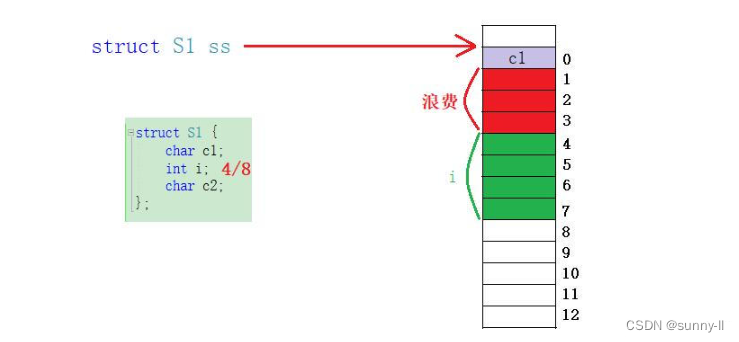
i,其为整型所以在内存中就需要存储4个字节的大小,此时便要拿其和VS下默认对齐数8去进行比较,取较小的值4
- 算出来【4】之后便要对齐到4整数倍的地址处,那就是4这块空间,往下一直占用4个字节,这就是成员变量i在这个结构体中的内存占用分布
- 那既然这个
i是从4的位置开始放的,中间空出来的位置就不会再放置其他成员变量了,那么这个3个空间也就浪费了
- 接下去放置第三个成员变量
c2,char类型的变量为1个字节,和8比较取小就是1,那就要将其放到1整数倍的地址处,那其实任何空间都是可以的,直接放到这个【8】的位置就行 - 那截止目前为止这个结构体中的所有成员变量都放置完了,此时去计算一个所占的内存空间就可以发现只有9个字节。但是在一开始我们计算的这个结构体的大小为12个字节,可是现在还差3个字节,所以最后就要去进行一个填充。但是,为什么呢?
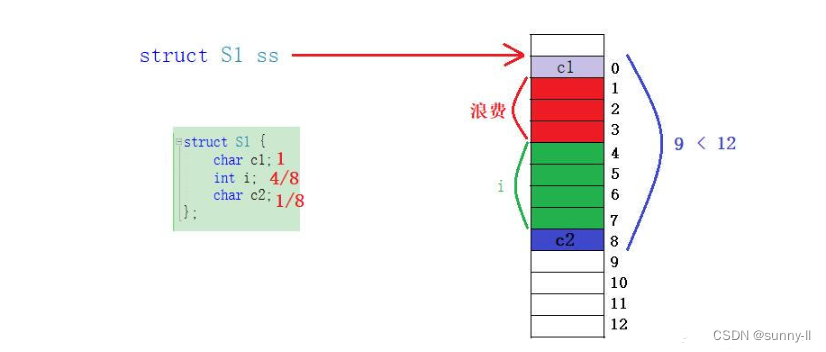
- 这就要用到第三条规则了:结构体总大小为最大对齐数的整数倍
- 那在这么计算下来之后,就可以知道结构体中的最大对齐数为4,那么【9】、【10】、【11】都不是它的整数倍,只有【12】是它的整数倍的地址处(注意这里是地址处!),因此我们需要填充3个字节,此时从0 ~ 11就有12个字节了,便为4的整数倍 👉这就是【12】如何被计算出来的全过程,你听懂了吗?
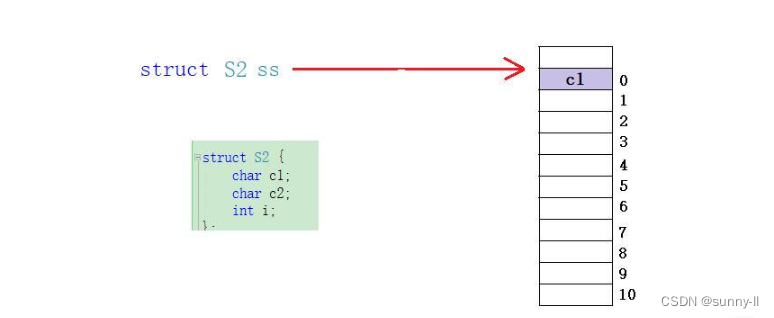
看完了,这个结构体后,还记得结构体S2吗,我再来讲一道,当然你也可以试着自己写写画画看👈
- 首先还是一样,
c1放在这个与结构体变量偏移量为0的地址处,而且它的类型还是char,所以只占1个内存单元
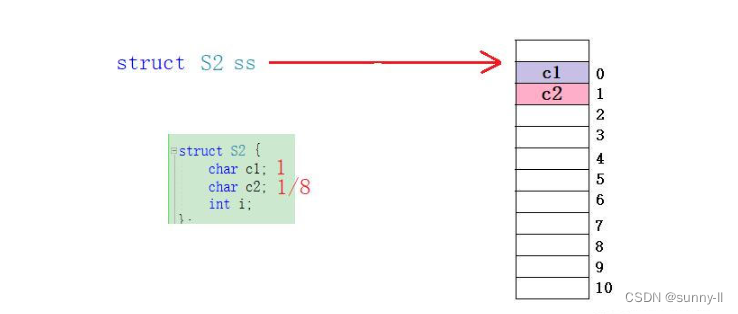
- 接下去还是一样,在放置第二个成员变量开始就要考虑【对齐数】了,
char所占的字节为1B,与8去进行比较一下就可以知道1来得小,那我们直接放在偏移处为1的地方就可以了,此时在内存中也只占了1个字节
- 接下去放置第三个成员变量【i】,大小为4个字节小于8因此选择在4的整数倍的地址处开始放置这个变量,整型占4个字节,所以一直占用到偏移量为7的地方
- 接下去就是计算整个结构体的大小,最大对齐数为4,所以要为4的整数倍,此时去计算一下得知从0 ~ 7偏移了7个字节,占用了8个空间,刚好为4的整数倍,所以结构体S2的大小为【8】是这么算出来的,你明白了吗?

三、习题演练
通过上面两道例题的讲解,相信你对如何去计算结构体大小一定有了一个自己的认识,接下去就让我们趁热打铁🔥来做两道题目再练一练,看看自己是否真的掌握了
🍍练习①
你可以先试着自己做一做,然后和我对一下是否正确
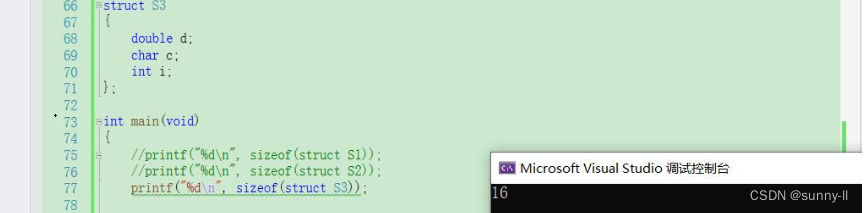
struct S3
{double d;char c;int i;
};
printf("%d\n", sizeof(struct S3));
【分析】:
- 首先看到第一个成员变量,从偏移量为0的地址处开始放起,因为
double类型的数据在内存中占8个字节,所以一直占用偏移处为7的地方

- 对于第二个成员变量【c】,类型为
char,所以在内存中占用1个字节,那直接放在偏移量为8的地址处即可


- 接下去来安排第三个成员变量【i】,整型占用4个字节,比VS下默认对齐数8来得小所以【对齐数为4】,去寻找4整数倍的地址处,【9】、【10】、【11】都不是,【12】是4的整数所偏移的地址处,从此处开始往下数4个字节的空间,刚好放满15
- 最后我们便去计算整个结构体的大小,为最大对齐数的整数倍,最大对齐数是8,计算一下放置三个成员变量占了16个空间,刚好是8的整数倍,因此16即为结构体的大小

运行结果如下:
🍐练习②
接下去再来做一道练习,涉及结构体嵌套的问题,对应的需要使用到规则4,忘记了可以翻上去看看👈
struct S3
{double d;char c;int i;
};struct S4
{char c1;struct S3 s3; //成员变量为另一个结构体double d;
};
因为本题的结构体比较大,所以就标出4的整数倍所在的地址
- 首先还是一样,来看到第一个成员变量【c1】,放到与结构体变量偏移量为0的地址处,又因为类型为
char,所以只占一个字节的空间

- 接下去,就是嵌套的结构体s3,此时我们要对齐到s3这个结构体中最大对齐数的整数倍处,那么最大对齐数就是【8】,所以要从8的地址处开始往下放置,那要占用多少空间呢?这就是s3这个结构体的大小【16】,所以一直往下数16个空间即可,一直到23这个地址处
- 那么中间的这7个位置就算是浪费了👈
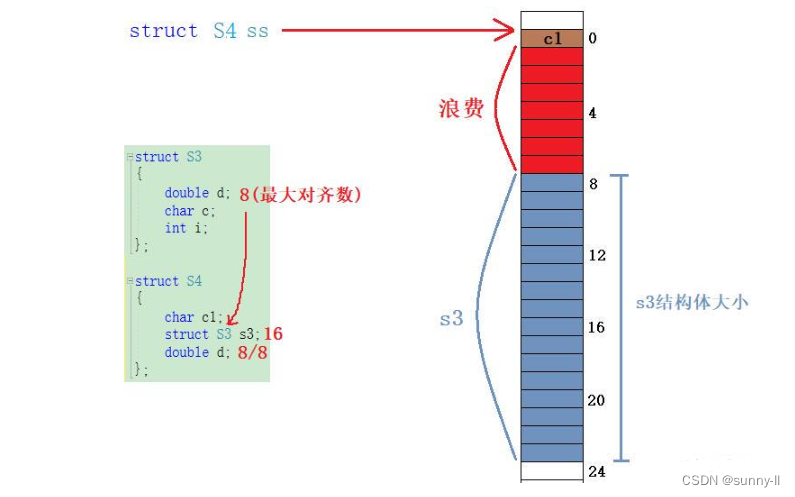
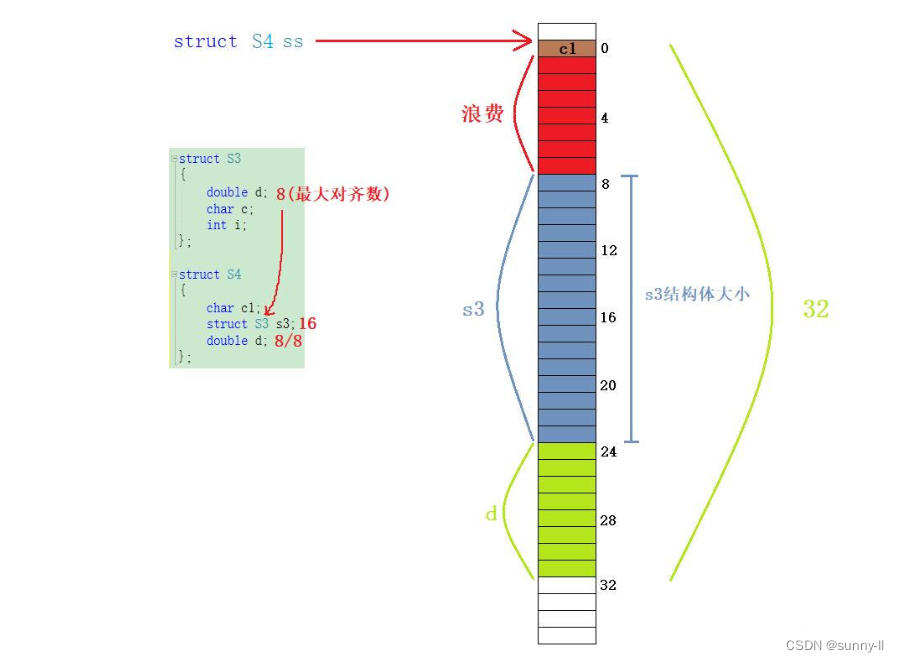
- 最后就是这个【d】,与VS中的默认对齐数一致,所以为【8】,下一个24刚好为8整数倍的地址处,所以从这开始放,
double类型的数据在内存中占8个字节,所以一直到31的地址处 - 然后来算整个结构体s4的大小,为所有最大对齐数(含嵌套结构体的对齐数)的整数倍,也就是取s3和s4中的最大对齐数,那也就是【8】,计算一下结构体s4所占的内存空间为32,刚好为8的整数倍,所以整个结构体的大小即为32
运行结果如下:
四、为什么存在内存对齐?
经过了两道例题和两道练习题的训练,相信你对如何计算结构体的大小一定是心中有数了,但在阅读的过程中你是否有疑惑为什么会存在这个【结构体内存对齐】呢?有什么实际意义吗?
1、平台原因(移植原因)
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常
2、性能原因
- 假设下面有一个结构体,内部有两个成员变量
c和i,然后要在内存中存储它们,我分为了两种,一个是【无内存对齐】,呈现的是紧密存放;一个是【内存对齐】,需要考虑到最大对齐数 - 然后在32位平台下去分别访问结构体中的成员,假设现在读取数据的时候一次性读四个字节。
- 首先看到的是【无内存对齐】的结构体内存分布,读一次就能读到 c,但是若要全部读取完 i,就还需要再读取一次,那访问到所有的成员变量就需要两次;
- 接下去看到的是【内存对齐】的结构体内存分布,因为内存对齐的缘故,所有两个成员变量 c和i互不干扰,此时再看到成员变量 i,从它的初始地址处开始读取,一次读4个字节,那么读1次就刚刚好可以读完这个变量了,而不是像上面那样还需要再读一次
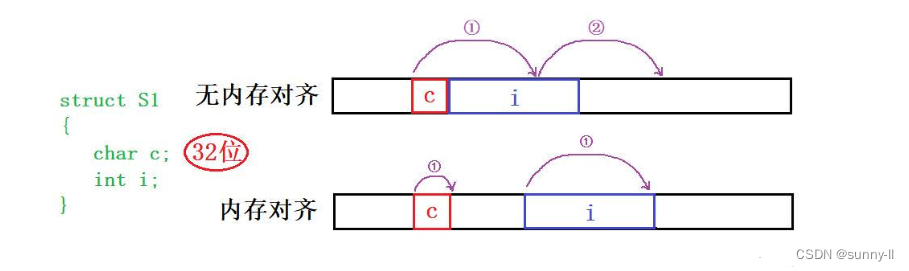
- 所以原因就在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
总体来说:
结构体的内存对齐是拿空间来换取时间的做法
struct S1 {char c1;int i;char c2;
};struct S2 {char c1;char c2;int i;
};
了解了为什么会存在内存对齐之后,我们再回到一开始的这两个结构体,你是否有想过为什么两个结构体的成员变量都一模一样但是大小却是一个【12】,一个【8】呢?
- 没错,就是你想到的它们所存放的位置不一样罢了。因为要存在内存对齐,所以若两个对齐数大的成员变量定义在一起的话为了满足规则就可能会浪费很多空间的内存。
- 但若是两个对齐数较小甚至相同规定的变量定义在一块的话,可能它们就是挨着放的,占用的空间少了↓,那最后结构体的大小就变小了
所以,那在设计结构体的时候,我们既要满足对齐,又要节省空间,就要让占用空间小的成员尽量集中在一起
五、如何修改默认对齐数
之前我们见过了 #pragma 这个预处理指令
#pragma comment,用来链接函数的静态库。这里我们再次使用,可以改变我们的默认对齐数
- 用法很简单
#pragma pack(1)就可以设置默认对齐数为1,#pragma pack()就可以取消设置的默认对齐数,还原为默认。到它为止的默认对齐数还是被修改后的对齐数
- 接下去就来看下面这个修改完默认对齐数后的结构体,它的大小会是多少呢?
#pragma pack(1)//设置默认对齐数为1
struct S1
{char c1;int i;char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认int main()
{//输出的结果是什么?printf("%d\n", sizeof(struct S1));return 0;
}
- 可以看到,若是默认的对齐数设置为1的话,那其实可以看出每个成员变量的对齐数就都是1了,那么也就不存在浪费的现象,因为任何数都是1的整数倍,所以3个成员变量的内存分布如下,大小即为【6】

运行结果如下:
结论:
结构在对齐方式不合适的时候,我么可以自己更改默认对齐数
六、实战演练
💬两道高频面试题
💦结构体怎么对齐? 为什么要进行内存对齐?
- 第一个成员在与结构体变量偏移量为0的地址处
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
【VS中默认的值为8、Linux环境默认不设对齐数(对齐数是结构体成员自身的大小)】- 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
为什么要进行内存对齐呢?原因有两个,一个是平台本身的原因,任意地址上的任意数据是不能随意访问的,如果不正确访问可能会造成硬件异常。第二个就是性能原因,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问
💦如何让结构体按照指定的对齐参数进行对齐?能否按照3、4、5即任意字节对齐?
可以的,只需要使用一个预处理指令
#pragma pack(3)便可以将默认对齐数修改为3,其他的也是同理,因为结构体默认对齐数发生了变化,此时就会导致结构体大小发生变化
七、共勉
以下就是我对结构体内存对齐的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对【C/C++】的理解,请持续关注我哦!!!!! 
这篇关于【C/C++】结构体内存对齐 ----- 面试必考(超详细解析,小白一看就懂!!!)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





