本文主要是介绍PMDK的笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PMDK
pmemobj_create 创建
NVM作为一种快速、可字节寻址、持久型的存储,在被以DAX暴露在用户态以后,可以在其上创建很多被mmap的文件,这些被mmap的文件就称之为内存池(Memory pools),当然,有了pmdk之后,内存池的创建就不需要我们自己手动mmap了,可以使用pmemobj_create来完成,接口定义:
#define pmemobj_create pmemobj_createW
PMEMobjpool *pmemobj_createW(const wchar_t *path, const wchar_t *layout,size_t poolsize, mode_t mode);
path是要创建的文件的路径(及NVM被挂载的文件系统路径),layout可以理解为布局,它作为该pool的唯一标志,poolsize是要创建的pool的大小,mode为文件的读写权限。
pmemobj_open 打开
如果要打开一个已经存在的pool文件,那么可以使用pmemobj_open,接口定义:
#define pmemobj_open pmemobj_openU
PMEMobjpool *pmemobj_openU(const char *path, const char *layout);
pmemobj_create和pmemobj_open都会返回一个PMEMobjpool指针,它就是创建或打开的pool的句柄(定义在pmdk/src/libpmemobj/obj.h).
pmemobjpool中提到的几个持久化函数,由于pmdk运行在模拟NVM的环境上运行,因此对于是否是pmem分别会有两种不同的缓存刷新策略,如下:
if (rep->is_pmem) {//如果是持久型内存rep->persist_local = pmem_persist; //将缓冲区的内容刷新到PM中 ,等待排空缓冲区rep->flush_local = pmem_flush; //flush操作rep->drain_local = pmem_drain; //sfence操作rep->memcpy_persist_local = pmem_memcpy_persist; //这是啥意思??rep->memset_persist_local = pmem_memset_persist;} else {// 否则就是普通内存,易失性内存rep->persist_local = (persist_local_fn)pmem_msync;rep->flush_local = (flush_local_fn)pmem_msync;rep->drain_local = obj_drain_empty;rep->memcpy_persist_local = obj_nopmem_memcpy_persist;rep->memset_persist_local = obj_nopmem_memset_persist;} /** pmem_persist -- make any cached changes to a range of pmem persistent*/
void
pmem_persist(const void *addr, size_t len)
{LOG(15, "addr %p len %zu", addr, len);// 将缓冲区中的内容刷新到NVM中pmem_flush(addr, len);// 等待排空缓冲区,本质是一个存储内存屏障pmem_drain();
}
pmem_drain --相当于sfence
由于CLFLUSHOPT不在保证顺序顺序,因此对于上面的代码,需要在为valid置1之前加一个内存屏障,保证之前的CLFLUSHOPT操作全部完成(前文所说的pmem_drain就是完成这个功能)。
CLWB和CLFLUSHOPT完成的功能类似,唯一不同的是,CLWB在把缓存中的数据刷新之后,并不会失效它, 因此后续的读还是可以读到缓存中的数据,因此性能会好一些。
pmemobj_close 关闭
和操作系统中的其它资源一样,pool作为一种资源,在使用完成之后也需要进行关闭操作,该操作使用pmemobj_close函数完成:
/** pmemobj_close -- close a transactional memory pool*/
void
pmemobj_close(PMEMobjpool *pop)
持久化指针
对于传统的指针而言,它只是一个在虚拟地址空间的相对(0地址)偏移量。但是由于这里的pool可能会有很多个,因此持久化的指针没办法只使用一个简单的偏移量来表示,在pmdk中,持久化指针占用两个64 bit,定义如下:
typedef struct pmemoid {uint64_t pool_uuid_lo;// 每一个pool都有一个uuid唯一标识自己uint64_t off;// 对象在该pool中的偏移量
} PMEMoid;
pmemobj_direct 将持久化指针转为直接指针,原理:(void *)((uint64_t)pool + oid.off)
根对象
找到写在PM当中的对象。
PMEMoid root = pmemobj_root(pop, sizeof (struct my_root));
其中,pop是我们使用前文所述方式创建的PMEMobjpool指针,my_root是我们自己定义的数据结构,返回值就是持久指针。其实这个可以类比c++中的placement new操作,在指定位置分配一个对象。需要注意的是,pmemobj_root分配的对象内存已经自动被初始化为0,如果你想重新调整对象的大小,只需要改变size参数就好了,如果使用新的size无法完成就地分配,那么一个新的对象将被创建,因此它在pool中的偏移也将被改变,所以,千万不要在使用过程中把持久指针保存在任何地方,因为它是可变的。
在pmdk中,所有以_persist结尾的接口都会确保它们所操作的内存都会从cpu cache中刷新到NVM中。
事务实现方式–PMDK事务接口
在pmdk中,事务操作都是使用以pmemobj_tx_前缀开始的接口完成的,一个事务是分阶段执行的,各阶段具体定义在pobj_tx_stage枚举中:
/** Transactions** Stages are changed only by the pmemobj_tx_* functions, each transition* to the TX_STAGE_ONABORT is followed by a longjmp to the jmp_buf provided in* the pmemobj_tx_begin function.*/
enum pobj_tx_stage {TX_STAGE_NONE, /* no transaction in this thread */TX_STAGE_WORK, /* transaction in progress */TX_STAGE_ONCOMMIT,/* successfully committed */TX_STAGE_ONABORT, /* tx_begin failed or transaction aborted */TX_STAGE_FINALLY, /* always called */MAX_TX_STAGE
};
上述各个事务阶段按照一定的逻辑进行组合、运转,最后性能一个完成的事务生命周期,如下图所示:
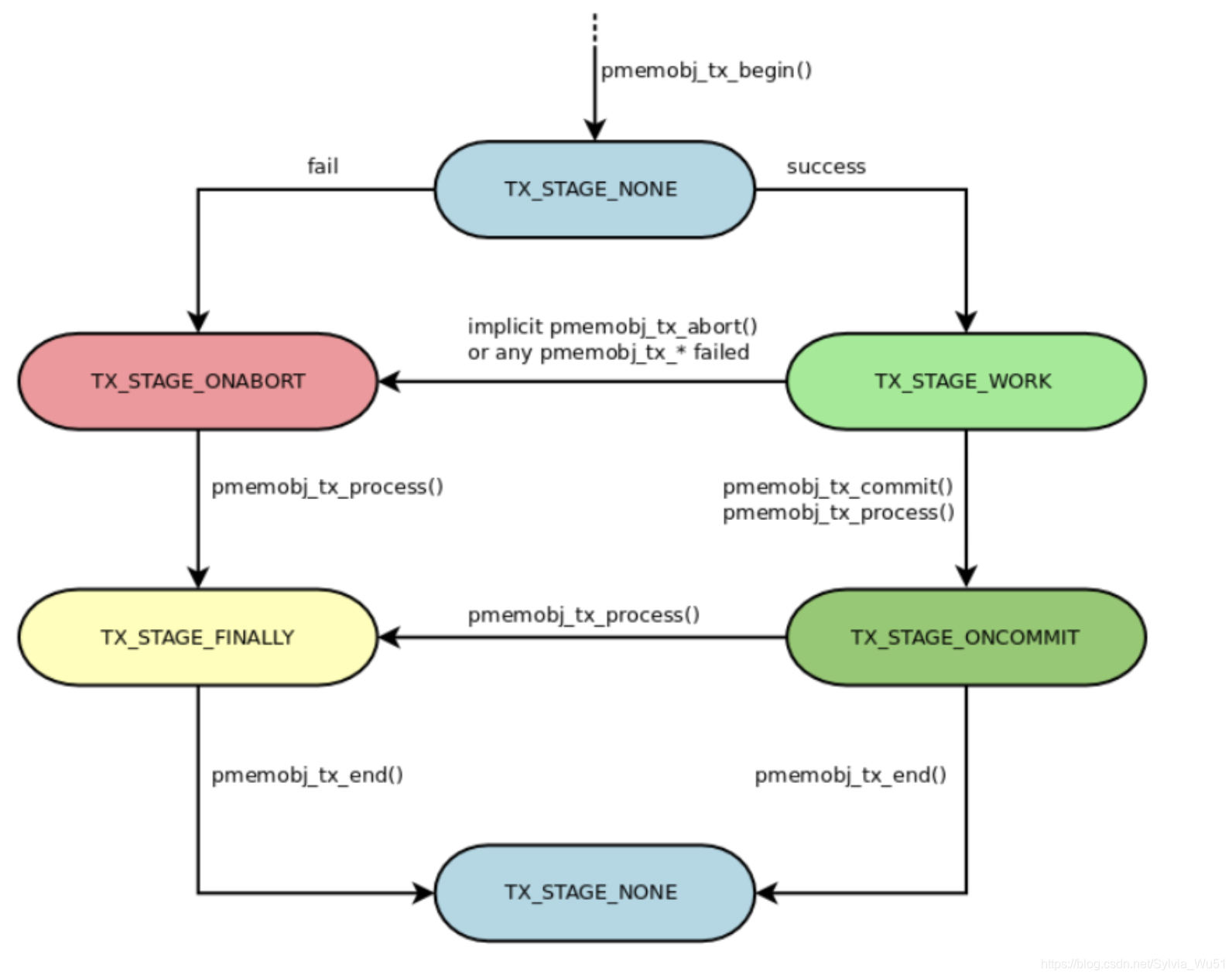
pmemobj_tx_process接口可以在你不知道事务当前所处阶段的情况下驱动事务继续执行到下一个阶段。事务声明周期可以这样来表示:
/* TX_STAGE_NONE */TX_BEGIN(pop) {/* TX_STAGE_WORK */
} TX_ONCOMMIT {/* TX_STAGE_ONCOMMIT */
} TX_ONABORT {/* TX_STAGE_ONABORT */
} TX_FINALLY {/* TX_STAGE_FINALLY */
} TX_END/* TX_STAGE_NONE */
上面的代码中,除了TX_BEGIN和TX_END是必须的之外,其他的阶段都是可选的。
凡是会被用在TX_STAGE_ONABORT/TX_STAGE_FINALLY阶段的局部变量,建议都要加上volatile修饰。
事务操作
pmdk将事务分为三种基本操作:分配(allocation),释放(free),设置(set),本文就先介绍一下set的事务操作,它就是用来安全可靠的将一段内存设置为某一个值。先大概介绍一下其原理:pmdk会先将要操作的内存的一个快照(snapshot)保存在undo log中,之后应用程序可以随意修改原来的那块内存,过程中一旦出现任何失败,所有的操作就被回滚。
内存的设置操作一共由两个接口实现:pmemobj_tx_add_range 和 pmemobj_tx_add_range_direct,根据上面的原理介绍,这两个函数中的任何一个被调用的时候,一个新的对象将会被创建,然后会将原内存块的内容拷贝过来,除非用于事务回滚,否则原来的对象将被丢弃。并且需要注意的是,pmdk会假设你要分配的内存都是用来写的,因此在事务提交时它默认会自动被持久化,所以你不需要再自己手动调用pmemobj_persist接口。
clflushopt和clwb指令是Intel为了支持NVM特地加入的两条优化指令,他们都是用来将CPU多级缓存刷新到NVM中,下面先看看应用程序在向NVM中刷新一条数据时的过程。
首先,数据开始的时候被存储在cpu的多级缓存中,在执行CLFLUSH/CLFLUSHOPT/CLWB缓存刷新指令的时候,缓存中的数据会被刷新到内存控制器的写队列里面WPQ(也就是没有最终写到介质上),因此,理论上如果此时系统掉电,那么将会出现数据丢失的现象。但是在ADR(异步内存刷新)的保证下,即使掉电,写队列里面的数据也会在超级电容的作用下(电容里面存有足够的电量)安全的写到介质上。
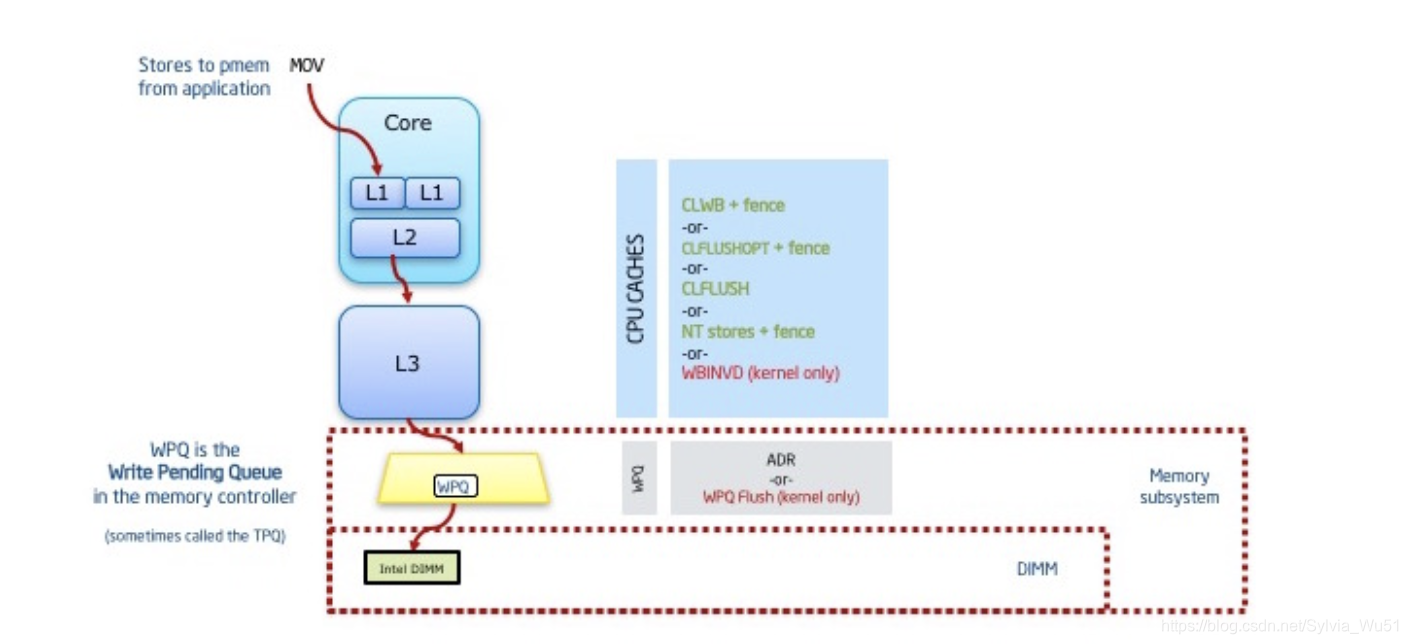
//转自:https://my.oschina.net/fileoptions/blog/1629405
这篇关于PMDK的笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







