本文主要是介绍AutoGPT实现原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AutoGPT是一种利用GPT-4模型的自动化任务处理系统,其主要特点包括任务分配、多模型协作、互联网访问和文件读写能力以及上下文联动记忆性。其核心思想是通过零样本学习(Zero Shot Learning)让GPT-4理解人类设定的角色和目标,并通过多任务学习(Multi-task Learning)实现任务拆解和子任务分配。
AutoGPT利用GPT-4的零样本学习能力,让模型在没有接触过特定类别样本的情况下,仍然能够识别和处理这些类别的数据。例如,如果一个零样本学习模型被训练识别动物,并已经学会识别“猫”和“狗”这两个类别,那么当它遇到一个未见过的动物类别(如“狼”)时,可以根据“狼”和已知类别的语义表示之间的相似性,正确地识别出“狼”。
在任务分配方面,AutoGPT利用多任务学习的方法,通过让模型在一个统一的框架下学习多个相关任务,实现知识的共享和迁移,从而提高模型的性能。例如,在自然语言处理(NLP)领域,一个多任务学习模型可能需要同时学习词性标注(Part-of-speech tagging)、命名实体识别(Named Entity Recognition)和情感分析(Sentiment Analysis)等任务。
AutoGPT还具备提示生成能力,它可以通过少量样本学习的方法自动生成提示,从而完成更多任务。例如,如果想要GPT帮我制作一个关于AIGC科普类的视频,我们可以先给它一些关于AIGC的文章、或者其他科普类视频的结构,让它学习到什么是aigc、什么是科普,然后利用这些知识来创作一个全新的AIGC相关的科普视频。
在评估子任务是否达标方面,AutoGPT能够利用元学习(Meta-learning)自我评估和改进,从而实现更复杂和多步骤的任务,降低对人类提示的依赖。例如,我让它写一个营销文案,根据结果给出反馈:“文案写得很好,但有些地方不够吸引人,没有触达用户的决策点,希望你可以再详细一些。”Auto GPT 根据这个反馈修改和完善文案。
AutoGPT优势
- 用于搜索和信息收集的互联网接入 / Internet access for searches and information gathering
- 长期和短期内存管理 / Long-term and short-term memory management
- 用于文本生成的 / GPT-4实例GPT-4 instances for text generation
- 访问热门网站和平台 / Access to popular websites and platforms
- 使用GPT-3.5进行文件存储和摘要 / File storage and summarization with GPT-3.5
- 插件扩展性 / Extensibility with Plugins
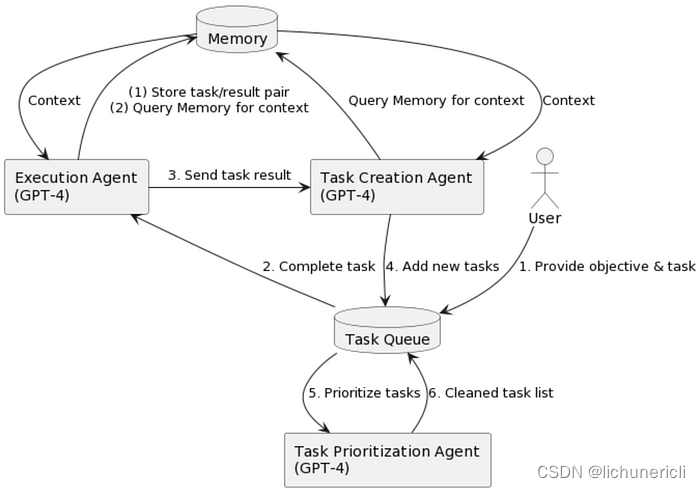
- 首先,用户需要提供一个任务和目标,然后这个任务会被添加到任务队列中。
- 接下来,执行代理(Execution Agent)会从任务队列中取出任务,并将其发送给任务创建代理(Task Creation Agent)。任务创建代理会查询内存中的上下文信息,并根据这些信息来创建一个新的任务。
- 然后,这个新创建的任务会被存储在内存中,并且执行代理会将任务的结果发送回任务队列中。
- 最后,任务优先级代理(Task Prioritization Agent)会根据任务的优先级来清理任务列表,并将清理后的任务列表返回给用户。
- 整个过程都是通过内存来实现的,内存可以存储任务/结果对,并且可以根据上下文信息来查询任务。
AutoGPT 利用 GPT-4 来实现自动任务处理和目标达成的高级应用。其主要特点包括:
- 零样本学习(Zero-Shot Learning):AutoGPT 能够理解并执行未曾训练过的特定角色和目标,这是通过 GPT-4 的零样本学习能力来实现的。这种能力使得模型无需接触过某个任务的具体样例,仅凭概念描述或定义就能理解和生成相应内容。
- 多任务处理与拆解:对于人类设定的目标,AutoGPT 利用多任务学习的方法将其分解成一系列子任务。可以通过对任务目标的理解以及内在的推理能力,将复杂任务结构化为可执行的多个步骤。
- 互联网访问与文件操作:AutoGPT 具备直接访问互联网资源及读写文件的能力,这有助于在执行任务时获取必要信息和保存进度。
- 上下文联动记忆性:能够捕捉和利用之前交互的上下文信息,以维持连贯的任务执行过程。
- 提示自动生成:AutoGPT 使用了类似“few-shot learning”的技术,通过元学习、数据增强等策略,在有限的示例基础上生成新的提示,让 GPT-4 完成更多复杂的任务。
- 自我评估与改进:Auto GPT 可以通过元学习进行自我评估,并基于任务表现结果不断优化自己的提示生成和执行策略。当分配给 GPT-4 的子任务完成后,会根据反馈和结果调整后续步骤,例如从用户评价中学习如何改进文案写作。
- 子任务达标评估:Auto GPT 根据预先设定的目标,结合来自数据库的数据,生成并执行针对 GPT-4 的提示。同时,它也会利用生成的输出和外部反馈(如用户的评价)判断子任务是否完成,从而进行迭代改进。
- 核心代码在于prompt构造:尽管 AutoGPT 在演示上很吸引人,但其核心技术在于如何构建有效的提示信息,即将用户输入的角色、目标等合并到默认的提示消息中。
- 局限性与CoT方法:AutoGPT 在推理能力方面未充分利用“链式思考转换”(Chain of Thought, CoT) 方法,导致在解决需要复杂推理的问题时表现出一定的局限性,可能会陷入循环或重复操作,尤其是在token计费背景下,这一问题更为突出。
这篇关于AutoGPT实现原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



