本文主要是介绍4、pod运维replicationCtroller、replicaSet、DeamonSet、Job、Cronjob,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、kubenetes 会自动重新运行失败的pod应用
pod运行失败,会自动重启,但是节点失败,pod会被移除,
除非配置了relicationController来管理资源2、保持pod的健康存活
配置探针,发送http请求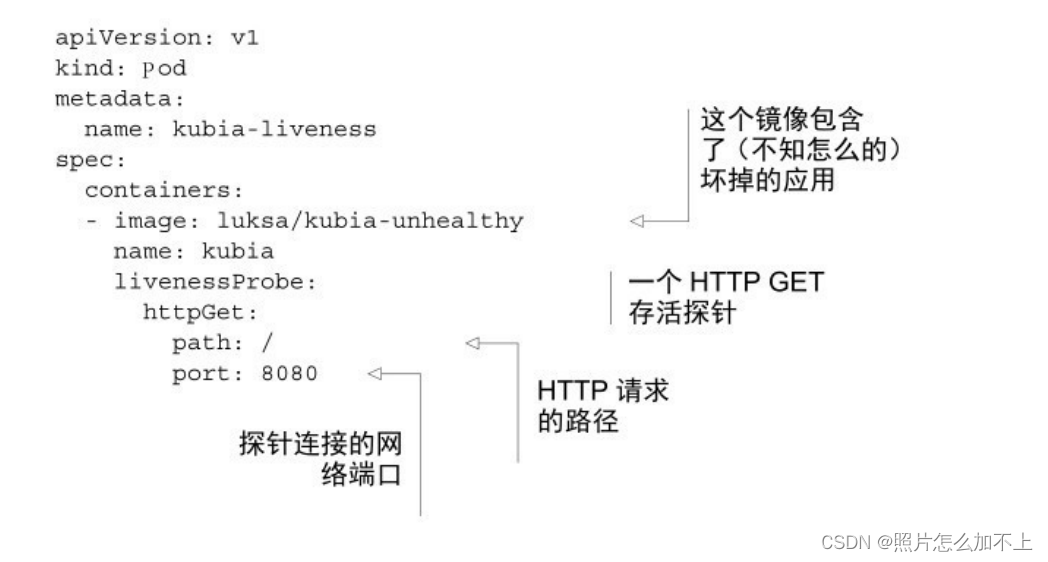
3、查看前一个pod的运行日志
kubectl logs <pod_name> --previous4、查看容器重启的运行状态
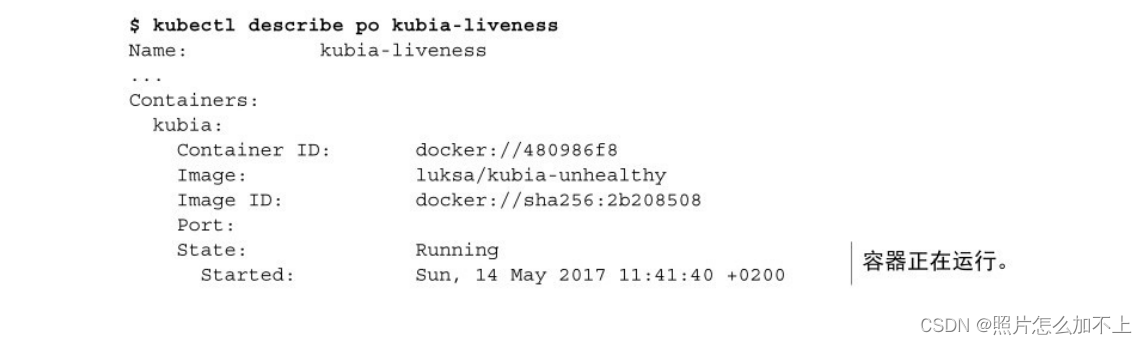
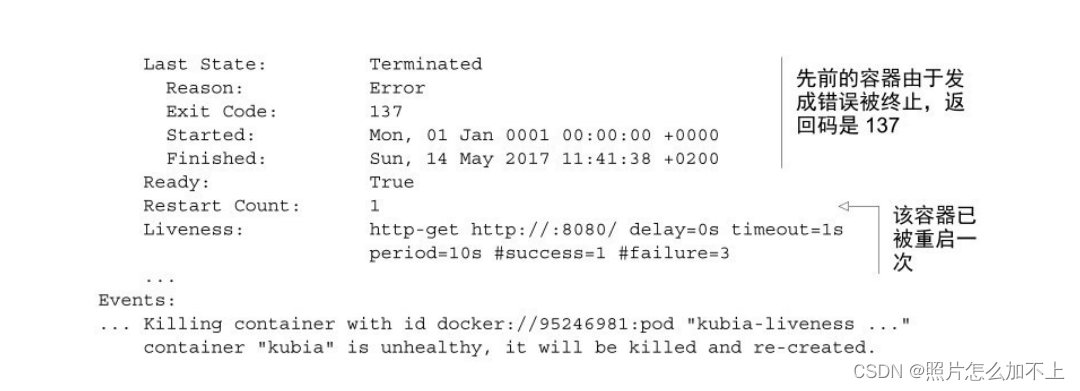
kubectl describe po <pod_name>delay(延迟)、timeout(超时)、period(周期)等。delay=0s部分显
⽰在容器启动后⽴即开始探测。timeout仅设置为1秒,因此容器必须在
1秒内进⾏响应,不然这次探测记作失败。每10秒探测⼀次容器
(period=10s),并在探测连续三次失败(#failure=3)后重启容器。退出代码
为137,这有特殊的含义 —— 表⽰该进程由外部信号终⽌。数字137是
两个数字的总和:128+x,其中x是终⽌进程的信号编号。在这个例⼦
中,x等于9,这是SIGKILL的信号编号,意味着这个进程被强⾏终
⽌
5、pod 探针配置探测延迟
如果没有设置初始延迟,探针将在启动时⽴即开始探测容器,这
通常会导致探测失败,因为应⽤程序还没准备好开始接收请求。如果
失败次数超过阈值,在应⽤程序能正确响应请求之前,容器就会重
启。
6、replicationController的作用
ReplicationController是⼀种Kubernetes资源,可确保它的pod始终保
持运⾏状态。如果pod因任何原因消失(例如节点从集群中消失或由于
该pod已从节点中逐出),则ReplicationController会注意到缺少了pod并
创建替代pod
7、replicationController 创建
# 查看rc列表
kubectl get rc# 查看现有rc的yaml文件
kubectl get rc <rc_name> -o yaml# 创建一个rc的yaml
kubectl create -f kubectl-rc.yaml创建成功就会执行
⼀个ReplicationController有三个主要部分:
label selector(标签选择器),⽤于确定ReplicationController作⽤
域中有哪些pod
replica count(副本个数),指定应运⾏的pod数量
pod template(pod模板),⽤于创建新的pod副本spec containers ,容器相关
8、查看rc的状态
kubectl describe rc <rc_name>
9、pod 删除rc流程
10、kubernetes进入node节点
#创建节点
gcloud container clusters create <node_name> --num-nodes <node_num>#获取节点列表
kubectl get nodes#查看node详细信息
kubectl describe node <node_name>#进入node节点
gcloud compute ssh <node_name> #节点重置
gcloud compute instances reset <node_name>11、replicationController 中的pod移动和删除(原pod需要手动删除,才行)
#更新pod中一个标签
kubectl label pod kubia app=foo --overwrite# 展示所有标签
kubectl get pods --show-lables# 展示特定标签
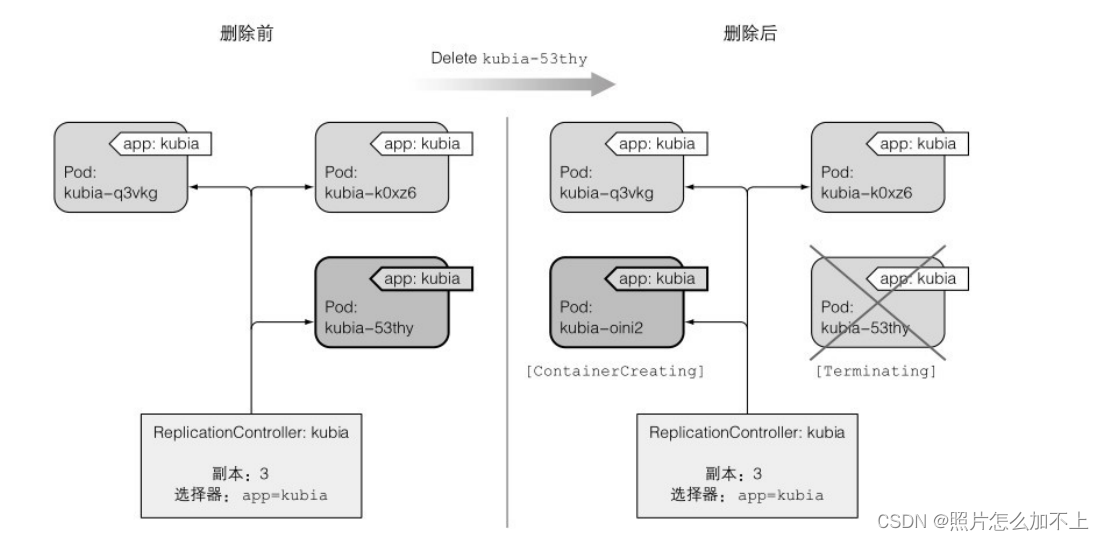
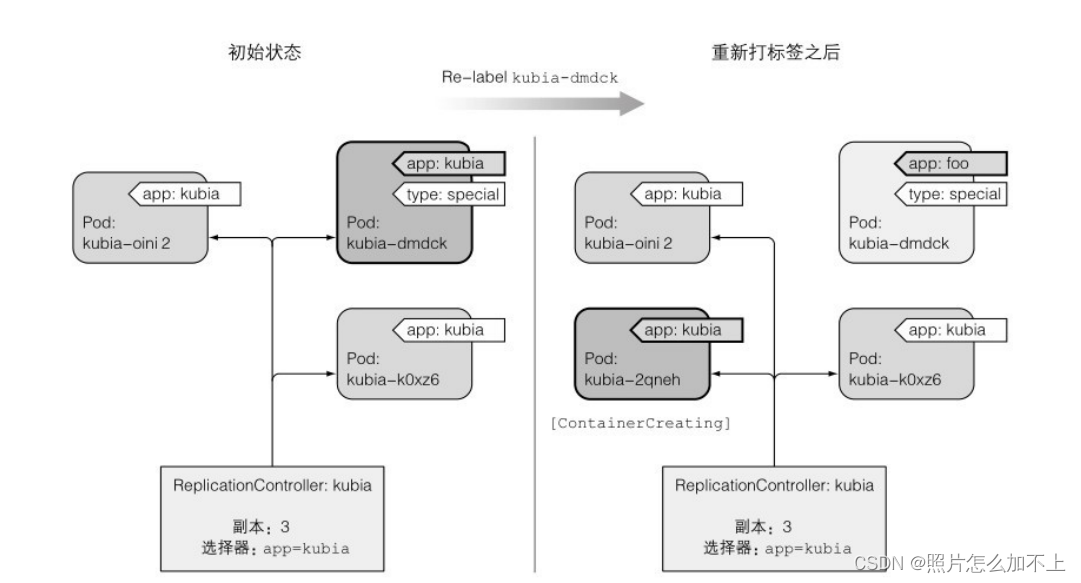
kubectl get pods -L app当 你 更 改 pod 的 标 签 , 使 得 它 们 不 再 与
ReplicationController的pod选择器匹配时,发⽣的事情。可以看到三个
pod和ReplicationController。在将pod的标签从app=kubia更改为app=foo
之后,ReplicationController就不管这个pod了。由于控制器的副本个数
设 置 为 3 , 并 且 只 有 两 个 pod 与 标 签 选 择 器 匹 配 , 所 以
ReplicationController 启 动 kubia-2qneh pod , 使 总 数 回 到 了 三 。
kubiadmdck pod现在是完全独⽴的,并且会⼀直运⾏直到你⼿动删除它
12、修改pod 模板
更改pod的标签和更改replicationController的选择器标签,都会重新创建新的pod,
rc就不会管理对应的pod,但是新创建的pod,还是原来的模板pod,如果想要pod的模板
更新,就需要配置replicationController的模板,要修改旧的pod,你需要删除它们,
并让ReplicationController根据新模板将其替换为新的pod。配置kubectl edit使⽤不同的⽂本编辑器
可以通过设置KUBE_EDITOR环境变量来告诉kubectl使⽤你期望的
⽂本编辑器。例如,如果你想使⽤nano编辑Kubernetes资源,请执⾏以
下命令(或将其放⼊~/.bashrc或等效⽂件中):
export KUBE_EDITOR="usr/bin/nano"# 查看rc列表
kubectl get rc# 修改pod模板
kubectl edit rc <rc_name>13、pod的扩容缩放(修改保存后,会立即生效)
# 副本数改为10
kubectl scale rc <rc_name> --replicas=10# 编辑yaml文件
kubectl edit rc <rc_name>
14、删除一个rc
删除rc rc下管理的pod将不被管理kubectl delete rc <rc_name> --cascade=false15、relicaSet与replicationController的区别
ReplicationController是⽤于复制和在异常时重新调度节点的
唯⼀Kubernetes组件,后来又引⼊了⼀个名为ReplicaSet的类似资源。它
是 新 ⼀ 代 的 ReplicationController , 并 且 将 其 完 全 替 换 掉
(ReplicationController最终将被弃⽤)。
ReplicaSet的⾏为与ReplicationController完全相同,但pod选择器的
表达能⼒更强。虽然ReplicationController的标签选择器只允许包含某个
标签的匹配pod,但ReplicaSet的选择器还允许匹配缺少某个标签的
pod,或包含特定标签名的pod,不管其值如何。
另外,举个例⼦,单个ReplicationController⽆法将pod与标签
env=production和env=devel同时匹配。它只能匹配带有env=devel标签的
pod或带有env=devel标签的pod。但是⼀个ReplicaSet可以匹配两组pod
并将它们视为⼀个⼤组。
同样,⽆论ReplicationController的值如何,ReplicationController都
⽆法仅基于标签名的存在来匹配pod,⽽ReplicaSet则可以。例如,
ReplicaSet可匹配所有包含名为env的标签的pod,⽆论ReplicaSet的实际
值是什么(可以理解为env=*)。16、replicaSet相关操作
# 查看replicaSet列表
kubectl get rsreplicaSet的所有操作和replicationController操作一致
17、使用replicaSet的标签
In:Label的值必须与其中⼀个指定的values匹配。
NotIn:Label的值与任何指定的values不匹配。
Exists:pod必须包含⼀个指定名称的标签(值不重要)。使⽤此运
算符时,不应指定values字段。
DoesNotExist:pod不得包含有指定名称的标签。values属性不得指
定。
如果你指定了多个表达式,则所有这些表达式都必须为true才能使
选择器与pod匹配。如果同时指定matchLabels和matchExpressions,则所
有标签都必须匹配,并且所有表达式必须计算为true以使该pod与选择
器匹配。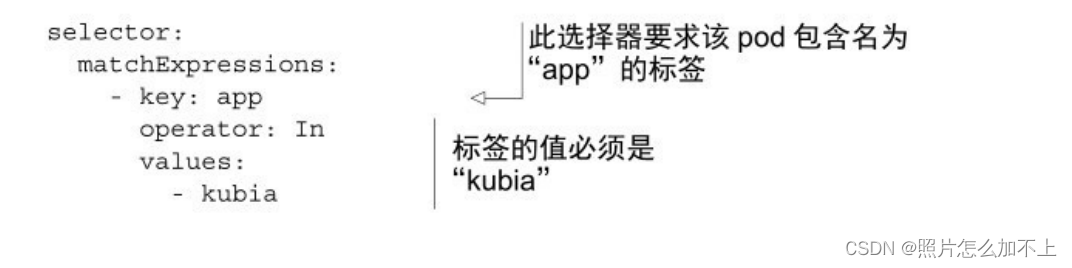
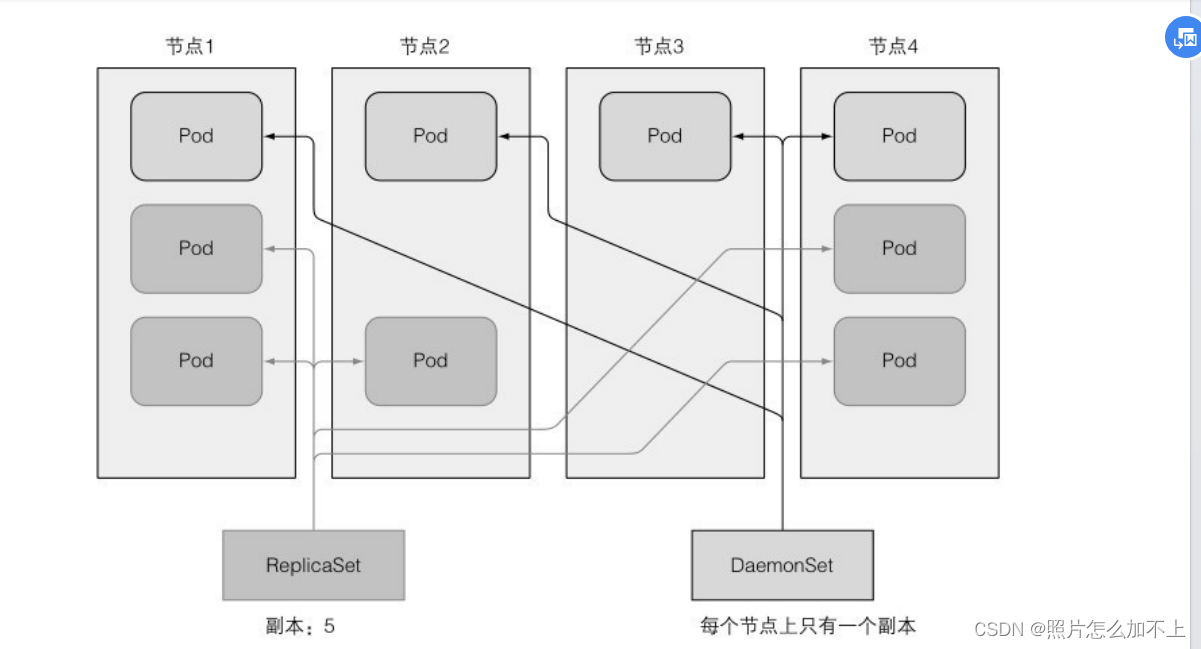
18、deamonSet (确保⼀个pod匹配它的选择器并在每个节点上运⾏)
Replicationcontroller和ReplicaSet都⽤于在Kubernetes集群上运⾏部
署特定数量的pod。但是,当你希望pod在集群中的每个节点上运⾏时
希望在每个节点上运⾏⽇志收集器和资源监控器。另⼀个典型的例⼦
是Kubernetes⾃⼰的kube-proxy进程,它需要运⾏在所有节点上才能使
服务⼯作19、replicaSet和DeamonSet的区别
20、创建一个deamonSet
创建⼀个DaemonSet,它在标
记为具有SSD的所有节点上运⾏这个守护进程。集群管理员已经向所有
此类节点添加了disk=ssd的标签,因此你将使⽤节点选择器创建
DaemonSet# 查看ds列表
kubectl get ds# 创建ds
kubectl create -f ds.yaml# 查询node列表
kubectl get node# 给node添加disk=ssd标签kubectl label mode <node_name> disk=ssd
21、移除deamonSet中的pod(立即生效,会删除node下对应节点,不需要手动在删除)
# 修改node标签
kubectl label node <node_name> disk=hdd --overwrite21、Job维护pod(只执行一次,临时任务)
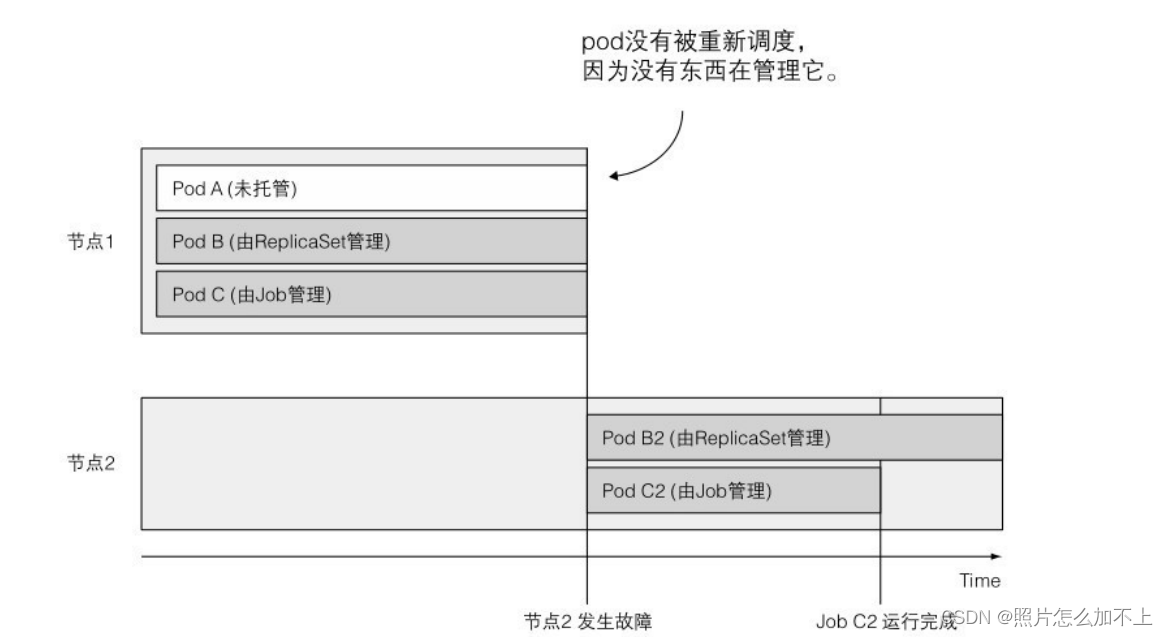
运⾏⼀种pod,该pod在内部进程成功
结束时,不重启容器。⼀旦任务完成,pod就被认为处于完成状态。
在发⽣节点故障时,该节点上由Job管理的pod将按照ReplicaSet的
pod的⽅式,重新安排到其他节点。如果进程本⾝异常退出(进程返回
错误退出代码时),可以将Job配置为重新启动容器。
22、创建一个Job
# 查看job列表
kubectl get jobs# 查询job的yaml
kubectl get po <po_name> -o yaml在⼀个pod的定义中,可以指定在容器中运⾏的进程结束时,
Kubernetes会做什么。这是通过pod配置的属性restartPolicy完成的,默
认为Always。Job pod不能使⽤默认策略,因为它们不是要⽆限期地运
⾏。因此,需要明确地将重启策略设置为OnFailure或Never。

23、设置job的运行次数及并行数量
Job将⼀个接⼀个地运⾏五个pod。它最初创建⼀个pod,当pod的
容器运⾏完成时,它创建第⼆个pod,以此类推,直到五个pod成功完
成。如果其中⼀个pod发⽣故障,⼯作会创建⼀个新的pod,所以Job总
共可以创建五个以上的pod
24、Job 的扩容缩放
kubectl scale job <job_name> --replicas 325、设置Job的运行过期时间
通过在pod配置中设置activeDeadlineSeconds属性,可以限制pod的
时间。如果pod运⾏时间超过此时间,系统将尝试终⽌pod,并将Job标
记为失败。
注意 通过指定Job manifest中的spec.backoffLimit字段,可以配置
Job在被标记为失败之前可以重试的次数。如果你没有明确指定它,则
默认为626、cronJob(定时执行、或将来运行一次pod)

可能发⽣Job或pod创建并运⾏得相对较晚的情况。你可能对这项
⼯作有很⾼的要求,任务开始不能落后于预定的时间过多。在这种情
况下,可以通过指定CronJob规范中的startingDeadlineSeconds字段来指
定截⽌⽇期
⼯作运⾏的时间应该是10:30:00。如果
因为任何原因10:30:15不启动,任务将不会运⾏,并将显⽰为Failed。
这篇关于4、pod运维replicationCtroller、replicaSet、DeamonSet、Job、Cronjob的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






