本文主要是介绍软件设计师考点明细总结(二) 笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
持续更新中···
2021年4月6日 小雨
数据结构与算法基础
数组
稀疏矩阵
数据结构的定义
概念:数据结构是指数据元素的集合及元素间的相互关系和构造方法。元素之间的相互关系是数据的逻辑结构,数据元素及元素之间关系的存储称为存储结构
非线性结构又可分为树结构和图结构
线性表
常采用顺序结构和链式存储,主要的基本操作是插入、删除和查找
线性表的顺序存储:线性表的顺序存储是指用一组地址连续的存储单元依次存储线性表中的数据元素,从而使得逻辑上相邻的两个元素在物理位置上也相邻
优点:可以随机存取表中的元素
缺点:插入和删除操作需要移动元素
线性表的链式存储:使用通过指针链接起来的结点来存储数据元素。
结点结构:
数据域用于存储数据元素的值,指针域存储当前元素的直接前驱或直接后继的位置信息,指针域中的信息称为指针
顺序存储与链式存储对比




2021年4月7日 依旧是小雨
队列与栈
栈:栈是只能通过访问它的一端来实现数据存储和检索的一种线性数据结构。遵循“后进先出”
队列:队列只允许在表的一端插入元素,而在表的另一端删除元素。遵循“先进先出”
循环队列:队空条件----head=tail 队满条件---(tail+1)%size=head(拿一个空间不存储,放尾指针)
广义表
广义表是线性表的推广,是由0个或多个单元素或子表组成的有限序列
广义表与线性表的区别在于:线性表的元素都是结构上不可分的单元素,而广义表的元素既可以是单元素,也可以是有结构的表。
广义表的长度是指广义表中元素的个数。广义表的深度是指广义表展开后所含的括号的最大层数
取表尾:在非空广义表中,除表头元素之外,由其余元素所构成的表称为表尾。非空广义表的表尾必定是一个表。
树与二叉树
结点的度:一个结点的子树的个数
叶子结点:叶子结点也称为终端结点,指度为0的结点
内部结点:度不为0的结点,也称为分支结点或非终端结点
满二叉树:若深度为k的二叉树有
-1个结点,则其为满二叉树
完全二叉树:深度为k、有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时,称之为完全二叉树


2021年4月8日 今天学校开运动会,还出了一点点太阳
树转二叉树
孩子结点-左子树结点 兄弟节点-右孩子结点
连线法:每层只要最左边的,其余的都舍弃,将最左与其他结点连线
查找二叉树
删除节点:若待删除的结点P有两个子节点,则在其左子树上,用中序遍历寻找关键值最大的结点S,用结点S的值代替点P的值,然后删除结点S
最优二叉树
路径:从树中一个结点到另一个结点之间的通路
树的路径长度:从树根到每一个叶子之间的路径长度之和
带权路径长度:从该结点到树根之间的路径长度与该结点权值的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和
线索二叉树
先将二叉树遍历出来,结点的前驱指向遍历结果结点的前面,后继指向遍历结果节点的后面
平衡二叉树
任意结点的左右子树深度相差不超过1、每个结点的平衡度(左子树个数-右子树个数)只能为-1、0或1
越平衡,查找效率越高
图
所有边都有方向的图称为有向图
每条边都没有方向的图称为无向图
若一个无向图具有n个顶点,而每一个顶点与其他n-1个顶点之间都有边,则称之为无向完全图,有n(n-1)/2条边
如果无向图中任意两个顶点都是连通的,则称其为连通图
有向图中任意两个顶点都是连通的,则为强连通图
2021年4月9日 运动会第二天,阴
图的遍历
深度优先:该方法类似于树的先根遍历。
步骤:(1)设置搜索指针P,使P指向顶点V (2)访问P所指顶点,并使P指向与其相邻接的且尚未被访问过的顶点。(3)若P所指顶点存在,则重复步骤(2),否则执行步骤(4) (4)沿着刚才访问的次序和方向回溯到一个尚有邻接顶点且未被访问过的顶点,并使P指向这个未被访问的顶点,然后重复步骤(2),直到所有的顶点均被访问为止。
广度优先:从图的某个顶点v出发,在访问了v之后依次访问v的各个未被访问过的邻接点,然后分别从这些邻接点出发依次访问他们的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直到图中所有已被访问的顶点的邻接点都被访问到。若此时还有未被访问的顶点,则另选图中的一个未被访问的顶点作为起点,重复上述过程,直到图中所有的顶点都被访问到为止
拓扑排序
在有向图中,若以顶点表示活动,用有向边表示活动之间的优先关系,则称这样的有向图以顶点表示活动的网(Activity On Vertex network,AOV网)。
图的最小生成树
树没有环路,图有环路
算法的特性
有穷性:一个算法必须总是(对任何合法的输入值)在执行有穷步之后结束,且每一步都在又穷时间内完成
确定性:算法中的每一条指令必须有确切的含义,理解时不会产生二义性。并且在任何条件下,算法只有唯一的一条执行路径,即对于相同的输入只能得出相同的输出
可行性:一个算法是可行的,即算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。
输入:一个算法有零个或多个输入,这些输入取自于某个特定的对象的集合
输出:一个算法有一个或多个输出,这些输出是同输入有着某些特定关系的量。
算法的复杂度
时间复杂度:指程序运行从开始到结束所需要的时间
空间复杂度:指对一个算法在运行过程中临时占用存储空间大小的度量
2021年4月10日 依旧是阴天
查找
顺序查找的基本思想:从表的一端开始,逐个进行记录的关键字和给定值的比较,若找到一个记录的关键字与给定值相等,则查找成功;若整个表中的记录均比较过,仍未找到关键字等于给定值的记录,则查找失败
平均查找长度:
时间复杂度:O(n)
折半查找的基本思想:在表中的元素已经按关键字递增方式排序的情况下,首先将待查元素的关键字(key)值与表r中间位置上(下表为mid)记录的关键字进行比较,若相等,则查找成功;若key>r[mid].key,则说明待查记录只可能在后半个子表r[mid+1..n]中,下一步应在后半个子表中进行查找;若key<r[mid].key,说明待查记录只可能在前半个子表r[1..mid-1]中,下一步应在r的前半个子表中进行查找,逐步缩小范围,直到查找成功或子表为空时失败为止。
关键字的比较次数最多为
时间复杂度:O(
)
散列表的基本思想是:已知关键字集合U,最大关键字为m,设计一个函数hash,它以关键字为自变量,关键字的存储地址为因变量,将关键字映射到一个有限的、地址连续的区间T[0..n-1](n<<m)中,这个区间就称为散列表,散列查找中使用的转换函数称为散列函数
散列表处理冲突的机制:线性探测法、伪随机数法
线性探测法:
排序
稳定排序:若在待排序的一组序列中,
和
的关键字相同,即
=
,且在排序前
不稳定排序:在排序后的序列中有可能出现
内部排序:指待排序记录全部存放在内存中进行排序的过程
外部排序:指待排序记录的数量很大,以至于内存不能容纳全部记录,在排序过程中尚需对外存进行访问的排序过程
直接插入排序
在插入第i个记录时,
、
、···、
已经排好序,这时将
、
等进行比较,从而找到应该插入的位置并将
希尔排序
直接选择排序
通过n-i(1
i
元素的总比较次数:
简单排序是一种不稳定的排序方法,时间复杂度为O(
)。
堆排序
基本思想:对一组待排序记录的关键字,首先按堆的定义排成一个序列(即建立初始堆),从而可以输出堆顶的最大关键字(对于大根堆而言),然后将剩余的关键字再调整成新堆,便得到次大的关键字,如此反复,直到全部关键字排成有序序列为止
应用场景:在一大堆元素中选出前几名
为序列(55,60,40,10,80,65,15,5,75)建立初始大根堆
冒泡排序
基本思想:通过相邻元素之间的比较和交换,将排序码较小的元素逐渐从底部移向顶部。由于整个排序的过程就像水底下的气泡一样逐渐向上冒,因此称为冒泡算法
快速排序
基本思想:通过一趟排序将待排的记录划分为独立的两个部分,其中一部分记录的关键字均不大于另一部分记录的关键字,然后再分别对这两部分记录继续进行快速排序,以达到整个序列有序。采用的是分治法。
用一维数组存储记录,一趟快速排序的具体做法是:附设两个指针i和j,它们的初值分别指向第一个记录和最后一个记录。设枢轴记录(通常是第一个记录)的关键字为pivotkey,则首先从j所指位置起向前搜索,找到第一个关键字小于pivotkey的记录与枢轴记录互相交换,然后从i所指位置起向后搜索,找到第一个关键字大于pivotkey的记录与枢轴记录互相交换,重复这两步直到i等于j时为止
快速排序是不稳定的排序方法,其平均时间复杂度为O(n
),空间复杂度为O(











2021年4月11日 阴,四天小长假的最后一天
归并排序
基数排序
总结
程序设计语言与语言处理程序基础
编译过程
编译程序的功能是把某高级语言书写的源程序翻译成与之等价的目标程序
词法错误:非法字符,关键字或标识符拼写错误
语法错误:语法结构出错,if endif不匹配,缺分号,只能识别出部分错误
语义错误:死循环、零除数,其他逻辑错误
文法
定义:描述语言语法结构的形式规则
语法推导树
有限自动机
有限自动机是一种识别装置的抽象概念,它能准确地识别正规集。有限自动机分为两类,确定的有限自动机和不确定的有限自动机
中间代码
常见的中间代码有后缀式(逆波兰式)、三元式、四元式和树等形式
常见的语法结构主要有算术表达式、布尔表达式、赋值语句和控制语句
传值与传址
传值调用:形参取的是实参的值,形参的改变不会导致调用点所传的实参的值发生改变
引用(传址)调用:形参取得是实参的地址,即相当于实参存储单元的地址引用,因此其值的改变同时就改变了实参的值











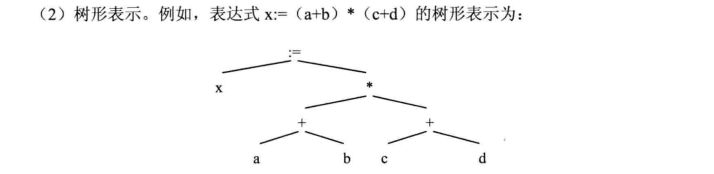


2021年4月15日 阴,害,连续三天的课都超级满 ,今天就多看一点叭
标准化和软件知识产权基础知识
保护期限
知识产权人确定
侵权判定
发表权:指决定软件作品是否公之于众的权力,即指软件作品完成后,以复制、展示、发行或者翻译等方式使软件作品在一定数量不特定人的范围内公开
侵权判定
标准的分类
标准的编号
多媒体基础
基本概念
媒体的分类
①感觉媒体。指直接作用于人的感觉器官,使人产生直接感觉的媒体。如视觉、听觉、触觉、嗅觉和味觉
②表示媒体。指传输感觉媒体的中介媒体,即用于数据交换的编码。
③表现媒体(显示媒体)。指进行信息输入和输出的媒体 。输入输出设备,如键盘、鼠标、麦克风、打印机、音箱
④交换媒体。指用来在系统之间进行数据交换的媒体,包括存储媒体(用于存储表示媒体的物理介质,如硬盘)和传输媒体 (指传输表示媒体的物理介质,如电缆)
媒体的特征:多样性、集成性、交互性、非线性、实时性、信息使用的方便性、信息结构的动态性
声音
人耳能听到的声音信号的频率范围是20Hz~20KHz,在这个频率范围内的信号称为音频信号,小于20Hz的声波信号称为亚音信号(也称次声波),高于20KHz的信号称为超音频信号(也称超声波)。
说话的声音信号的频率范围是300~3400Hz。乐器的声音信号的频率范围是20Hz~20KHz(不存在狮吼功哈哈哈哈哈)
声音信号的数字化
①采样。采样是把时间连续的模拟信号在时间轴上离散化的过程。在某些特定的时刻获取声音信号幅值称为采样,由这些特定时刻采样得到的信号称为离散时间信号。采样频率应为声音最高频率2倍(固定电话的采样频率为8k,大约为3400Hz的两倍)
②量化。量化处理是把幅度上连续取值(模拟量)的每一个样本转换为离散值(数字量)表示。量化后的样本是用二进制数来表示的,二进制数位数的多少反映了度量声音波形幅度的精度,称为量化精度,也称为量化分辨率
③编码。经过采样和量化处理后的每个声音采样信号已经是数字形式了,为了便于计算机存储、处理和传输,还必须按照一定的格式要求进行数据编码,再按照某种规定的格式将数据组织成为文件,还可以选择某一种或者几种方法对它进行数据压缩编码,以减少数据量
图像
颜色的三要素
①色调。色调是指颜色的类别,如红色、绿色、蓝色等不同颜色,大致对应光谱分布中的主波长
②饱和度。饱和度是指某一颜色深浅程度(或浓度)。对于同一种色调的颜色,色调越高,饱和度越高。饱和度可以用某色调的纯色掺入白色光的比例来表达
③亮度。亮度是描述光作用于人眼时引起的明暗程度感觉,是指彩色明暗深浅程度
三基色
从理论上讲,任何一种颜色都可以用3种基本颜色(红、绿、蓝)按不同比例混合得到
颜色模型
HSV颜色模型:艺术家彩色空间 YIQ:电视可以使用
计算
多媒体标准
数据压缩:














2021年4月17日 阴,时间好紧迫呀,每次周末都要花一上午的时间在这个上面。还有好多事情要做。。。
软件开发模型
瀑布模型
瀑布模型一般用户结构化开发,是以文档作为驱动、适合于软件需求很明确的软件项目的模型。
在瀑布模型中,需求或设计中的错误往往只有到了项目后期才能够被发现,对于项目风险的控制能力较弱,从而导致项目常常延期完成,开发费用超出预算
螺旋模型
工作步骤:
V模型
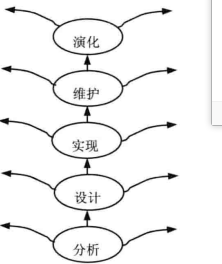
喷泉模型
喷泉模型是一种以用户需求为动力,以对象作为驱动的模型,适合于面向对象的开发方法。
喷泉模型使开发过程具有迭代性和无间隙性。迭代意味着模型中的开发活动常常需要重复多次,在迭代过程中不断地完善软件系统。无间隙是指在开发活动之间不存在明显的边界
构建组装模型(CBSD)
统一过程
敏捷开发方法
信息系统开发方法
结构化设计
基本原则
内聚和耦合
软件测试
测试用例设计
测试阶段
系统运行与维护 !
完善性维护:使变得更好。
CMMI
项目管理
















这篇关于软件设计师考点明细总结(二) 笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





