本文主要是介绍波奇学Liunx:信号的产生,保存,处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
信号的产生,信号的保存,信号的处理
在操作系统中进程接受到信号会保存,产生
进程必须识别和能够处理信号,处理信号是进程的内置功能
进程收到信号时不一定会立即执行,所以进程必然有一套识别,保存,处理信号操作
前后台进程
前后台进程:前台进程可以用ctrl + C删掉,后台进程用kill指令。
前后台的区别是进程能否获取键盘输入,且前台进程允许会阻止命令行输入。
(当进程运行,bash进程是后台的,所以无法输入命令)
前台和后台进程是一个bash进程,前台只有一个,后台进程可以有多个。
键盘输入首先是被前台进程收到的,ctrl + C首先是被前台收到的,本质上是2号信号
进入后台进程

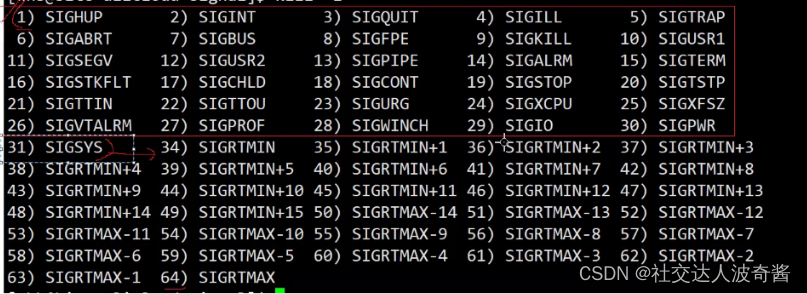
信号
没有0号,32,33信号
1~31信号是普通信号,34~64是实时信号不考虑。
信号在linux系统中是宏。
接收到信号的操作三选一
默认动作
忽略
自定义动作
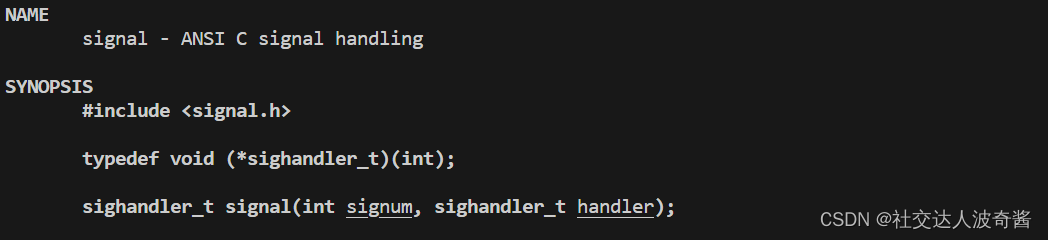
自定义收到信号的动作
signum:接收到的信号
handler 函数指针,接收到信号signum时,调用的函数
#include<iostream>
#include<unistd.h>
#include<signal.h>using namespace std;void myhandler(int signo)
{cout<<"Process get a signal"<<signo <<endl;exit(1);
}
int main()
{signal(SIGINT,myhandler); //signal只用设置一次while(true){cout<<"hello linux"<<std::endl;sleep(1);}return 0;
}这么看来signal函数不是创建新的进程,内部调用回调函数,而是一种设置,一种相关联。面向是一整个进程的。
键盘数据是如何输入给内核的,ctrl+C是如何变成信号的?
键盘是OS先知道,OS是怎么知道键盘上有数据?
键盘上有数据通过硬件中断发送信号到CPU,不同的硬件有不同的中断号。发送中断号的过程就是向cpu某个针角充放电,向寄存器上写入数据。
内核中有中断向量表里都是方法地址,方法是访问外设的方法,主要是磁盘,显示器,键盘
键盘有数据->发送中断号到cpu->cpu通知->操作系统读取中断向量表的方法->读取外设数据。
操作系统不再需要轮询外设,只需要等待CPU信号
信号是对这个套方法的模拟
信号是进程之间的事件异步通知的一种方式,属于软中断
软中断相对于硬中断而言,前者是对后者模拟
异步通知:等待信号和代码运行并行的,进程一边等待着信号,一边运行代码
不是所有信号都可以被signal捕捉的,如19号(暂停进程),9号(杀掉进程)
产生信号的方式
键盘
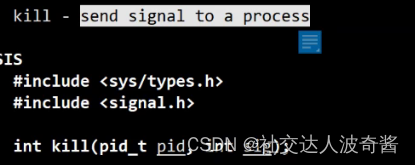
命令行kill命令
kill -9 pid //向进程发送信号9系统调用
kill函数
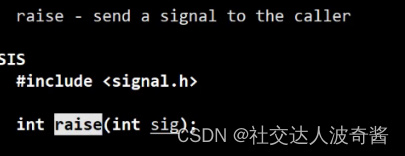
raise发送一个信号给调用该函数的进程
abort终止程序
无论信号如何产生,最终都一定是操作系统发送给进程的。
这篇关于波奇学Liunx:信号的产生,保存,处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




