本文主要是介绍Debezium发布历史163,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文地址: https://debezium.io/blog/2023/09/23/flink-spark-online-learning/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
Online machine learning with the data streams from the database
September 23, 2023 by Vojtěch Juránek
machine-learning flink spark online-learning examples apache-kafka
在…中 先前的博客帖子 我们已经展示了如何利用Debezns利用数据库中的现有数据来培训神经网络模型,并使用这个预先培训的模型来分类新存储到数据库中的图像。在这篇博文中,我们将进一步推进它–我们将使用Debezum从数据库中创建多个数据流,并使用其中一个流进行持续学习和改进我们的模型,而第二个流用于对数据进行预测。当模型不断改进或调整以适应最近的数据样本时,这种方法称为 在线机器学习.在线学习只适合于某些用例,而实现某一特定算法的在线变体可能具有挑战性甚至是不可能的。然而,在可以在线学习的情况下,它成为一种非常强大的工具,因为它使人们能够对数据的实时变化作出反应,避免重新培训和部署新模型的需要,从而节省硬件和业务成本。随着数据流变得越来越普遍,例如。随着在线学习的到来,我们可以期待在线学习变得越来越受欢迎。在可能的情况下,它通常是分析流数据的最佳工具。
正如在前一个博客中提到的,我们这里的目标不是为给定的用例构建可能的最佳模型,而是研究我们如何能够构建一个完整的管道,从将数据插入数据库到模型并将其用于模型培训和预测。为了保持简单,我们将使用另一个通常在ML教程中使用的众所周知的数据示例。我们将探讨如何使用网上变异的虹膜花,对不同种类的虹膜花进行分类。 K-元聚类算法 .我们用的 阿帕奇电汇 和 阿帕奇火花处理数据流。这两个框架都是非常流行的数据处理框架,包括一个机器学习库,除其他外,它还实现在线k-均值算法。因此,我们可以专注于构建一个完整的管道,将数据从数据库传递到给定的模型,实时处理它,而不必处理算法的实现细节。
本博客文章后面提到的所有代码都可以作为一个德贝齐姆示例在 去贝兹示例存储库 ,所有其他有用的东西,如码头制造和逐步指令在 自述 文件。
数据集准备
我们会利用 网花数据集 .我们的目标是根据对虹膜花的几种测量来确定虹膜的种类:它的花瓣长度,花瓣宽度,花瓣宽度。
图片来自官网原文

花色的
石竹色,来源 维基百科
数据集可从各种来源下载。我们可以利用这一事实,即它已经被预先处理过了。 学习 工具包从那里开始使用。每个样本行包含一个数据点(花被长度、花被宽度、花瓣长度和花瓣宽度)和一个标签。标签编号0,1,或2,其中0代表虹膜,1代表虹膜花色,2代表虹膜。数据集很小,只包含150个数据点。
当我们将数据加载到数据库时,我们将首先准备SQL文件,然后将其传递到数据库。我们需要把原始数据样本分成三个子样本–两个用于培训,一个用于测试。初步培训将使用第一个培训数据样本。当我们第一次测试该模型时,这个数据样本故意小到不能产生好的预测,这样我们就可以看到,当我们向模型提供更多的数据时,该模型的预测会如何实时增加。
您可以使用所附演示存储库中的下列组脚本生成所有三个SQL文件。
$ ./iris2sql.py
…postgres 目录包含了这个演示使用的文件。train1.sql 会自动加载到该数据库的开始。test.sql 和train2.sql 稍后将手动加载到数据库中。
与阿帕奇的分类链接
首先,让我们来看看如何做网上的虹膜花分类和学习阿帕奇。下图描述了整个管道的高层架构。
图片来自官网原文
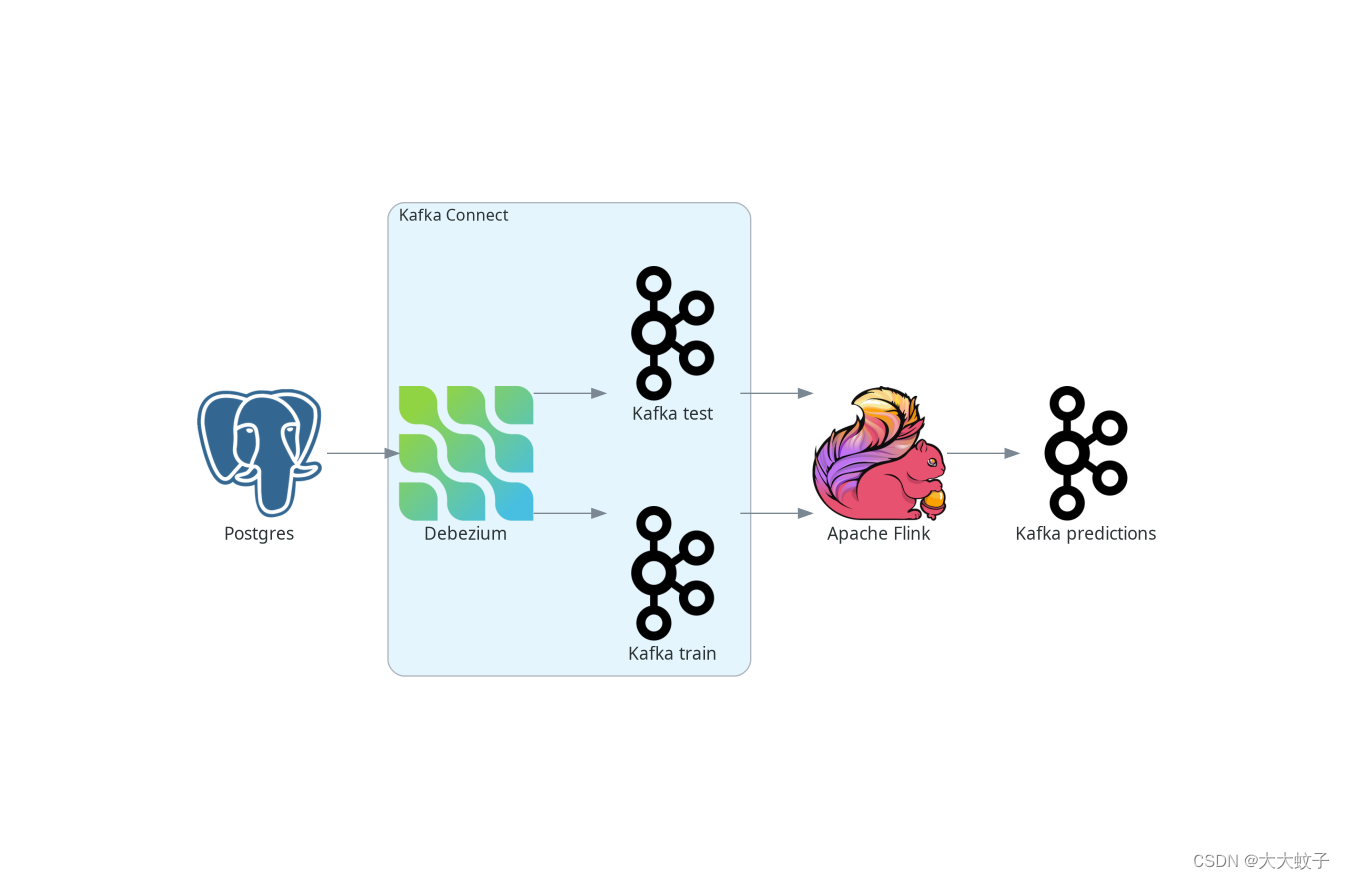
后调到FLK架构
我们将使用波斯特格雷斯作为我们的源数据库。作为卡夫卡连接源连接器部署的Debezum跟踪数据库中的变化,并创建从新插入的数据发送到卡夫卡的数据流。卡夫卡将这些流发送到阿帕奇弗林克,后者采用流K平均算法进行模型拟合和数据分类。对测试数据流模型的预测是作为另一个流生成的,并发送给卡夫卡。
您也可以不使用卡夫卡就直接吸收数据库更改到FINK中。VERVEREKA的实现的疾病预防控制中心的源连接器嵌入德贝佐姆直接进入FLINK。请参阅FLINC连接器 文件 更多的细节。
我们的数据库里有两张表。第一个存储我们的训练数据,第二个存储测试数据。因此,有两个数据流,每个数据流对应一个表–一个用于学习的数据流和一个需要分类的数据点。在实际应用程序中,您只能使用一个表,或者相反地,更多的表。您甚至可以部署更多的德贝齐亚连接器,从而合并来自多个数据库的数据。
使用德贝兹和卡夫卡作为源数据流
阿帕奇·弗林克与卡夫卡有着极好的融合。我们可以通过德贝司记录。JSON记录。对于创建FLINK表,它甚至支持Debezum的记录格式,但是对于流,我们需要提取部分Debezns消息,其中包含表中新存储的行。不过,这很容易,因为德贝兹提供SMT, 提取新记录状态SMT ,正是它做到了这一点。完全的德贝兹配置可以是这样的:
{
“name”: “iris-connector-flink”,
“config”: {
“connector.class”: “io.debezium.connector.postgresql.PostgresConnector”,
“tasks.max”: “1”,
“database.hostname”: “postgres”,
“database.port”: “5432”,
“database.user”: “postgres”,
“database.password”: “postgres”,
“database.dbname” : “postgres”,
“topic.prefix”: “flink”,
“table.include.list”: “public.iris_.*”,
“key.converter”: “org.apache.kafka.connect.json.JsonConverter”,
“value.converter”: “org.apache.kafka.connect.json.JsonConverter”,
“transforms”: “unwrap”,
“transforms.unwrap.type”: “io.debezium.transforms.ExtractNewRecordState”
}
}
这个配置捕捉了public 以表开头的架构iris_ 前缀。因为我们将训练和测试数据存储在两个表中,两个卡夫卡主题被命名为flink.public.iris_train 和flink.public.iris_test 分别被创造出来。弗林克的DataStreamSource 表示传入的数据流。当我们将记录编码为JSON时,它将是一个JSON流ObjectNode 东西。构造源流非常简单:
KafkaSource train = KafkaSource.builder()
.setBootstrapServers(“kafka:9092”)
.setTopics(“flink.public.iris_train”)
.setClientIdPrefix(“train”)
.setGroupId(“dbz”)
.setStartingOffsets(OffsetsInitializer.earliest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new JSONKeyValueDeserializationSchema(false)))
.build();
DataStreamSource trainStream = env.fromSource(train, WatermarkStrategy.noWatermarks(), “Debezium train”);
传真业务主要由Table 抽象对象。另外,ML模型只接受表作为输入,预测也是作为表生成的。因此,我们必须首先将输入流转换为Table 反对。我们将首先将输入数据流转换为表行流。我们需要定义一个映射函数来返回Row 具有包含一个数据点的向量的对象。因为K平均值算法属于 无监督学习 算法,即模型不需要对应的"正确答案",我们可以跳过label 矢量的场:
private static class RecordMapper implements MapFunction<ObjectNode, Row> {
@Override
public Row map(ObjectNode node) {
JsonNode payload = node.get(“value”).get(“payload”);
StringBuffer sb = new StringBuffer();
return Row.of(Vectors.dense(
payload.get(“sepal_length”).asDouble(),
payload.get(“sepal_width”).asDouble(),
payload.get(“petal_length”).asDouble(),
payload.get(“petal_width”).asDouble()));
}
}
内部的FLINK管道的各个部分可以在不同的工作节点上运行,因此,我们也需要提供有关表的类型信息。因此,我们准备创建表对象:
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
TypeInformation<?>[] types = {DenseVectorTypeInfo.INSTANCE};
String names[] = {“features”};
RowTypeInfo typeInfo = new RowTypeInfo(types, names);
DataStream inputStream = trainStream.map(new RecordMapper()).returns(typeInfo);
Table trainTable = tEnv.fromDataStream(inputStream).as(“features”);
建筑物的K型均值
一旦我们有了Table 目标,我们可以把它传给我们的模型。所以让我们创建一个并通过一个火车流到它进行持续的模型训练:
OnlineKMeans onlineKMeans = new OnlineKMeans()
.setFeaturesCol(“features”)
.setPredictionCol(“prediction”)
.setInitialModelData(tEnv.fromDataStream(env.fromElements(1).map(new IrisInitCentroids())))
.setK(3);
OnlineKMeansModel model = onlineKMeans.fit(trainTable);
为了使事情更简单,我们直接将所需集群的数目设置为3个,而不是通过挖掘数据(例如使用数据)找到最佳集群的数目。 肘法 )。我们还为集群的中心设置了一些初始值,而不是使用随机数(FLINT提供了一种方便的方法-KMeansModelData.generateRandomModelData() 如果你想尝试随机中心)。
为了获得测试数据的预测,我们再次需要将测试流转换为表。模型将带有测试数据的表转换为带有预测的表。最后,将预测转化为流并持续进行,例如。在卡夫卡语中:
DataStream testInputStream = testStream.map(new RecordMapper()).returns(typeInfo);
Table testTable = tEnv.fromDataStream(testInputStream).as(“features”);
Table outputTable = model.transform(testTable)[0];
DataStream resultStream = tEnv.toChangelogStream(outputTable);
resultStream.map(new ResultMapper()).sinkTo(kafkaSink);
现在,我们已经准备好构建我们的应用程序,并且几乎准备好将它提交给FL链接以供执行。在这样做之前,我们需要首先创建所需的卡夫卡主题。虽然主题可能是空的,但FLINK要求它们至少存在。当数据库启动时,我们将一个小的数据集包含在该数据库中,当在卡夫卡连接中注册该数据集连接器时,该数据将创建一个相应的主题。由于测试数据表还不存在,我们需要手动创建卡夫卡中的主题:
$ docker compose -f docker-compose-flink.yaml exec kafka /kafka/bin/kafka-topics.sh --create --bootstrap-server kafka:9092 --replication-factor 1 --partitions 1 --topic flink.public.iris_test
现在,我们准备将我们的申请提交给弗林克。完整代码,请参阅德贝齐姆的相应源代码 示例存储库
如果您不使用作为本演示的源代码的一部分提供的DOCer,请包括 方格语言库 在闪光中lib 文件夹,因为ML库不是默认的链接分发的一部分。
提供友好的用户界面,可在 http://localhost:8081/ .在那里,你可以检查,除其他事项外,你的工作状况,也,例如。出色的图形化执行计划:
图片来自官网原文
后调到FLK架构
评估模型
从用户的角度来看,所有与我们的模型的交互都是通过在数据库中插入新的记录或者用预测来阅读卡夫卡主题来实现的。当数据库开始时,我们已经在数据库中创建了一个非常小的初始训练数据样本,我们可以通过将测试数据样本插入数据库直接检查模型预测:
$ psql -h localhost -U postgres -f postgres/iris_test.sql
插入结果产生了卡夫卡测试数据的即时数据流,将其传递到模型中,并将预测发送到iris_predictions 卡夫卡主题。当将模型训练在只有两个集群的非常小的数据集上时,预测是不准确的。以下是我们最初的预测:
[5.4, 3.7, 1.5, 0.2] is classified as 0
[4.8, 3.4, 1.6, 0.2] is classified as 0
[7.6, 3.0, 6.6, 2.1] is classified as 2
[6.4, 2.8, 5.6, 2.2] is classified as 2
[6.0, 2.7, 5.1, 1.6] is classified as 2
[5.4, 3.0, 4.5, 1.5] is classified as 2
[6.7, 3.1, 4.7, 1.5] is classified as 2
[5.5, 2.4, 3.8, 1.1] is classified as 2
[6.1, 2.8, 4.7, 1.2] is classified as 2
[4.3, 3.0, 1.1, 0.1] is classified as 0
[5.8, 2.7, 3.9, 1.2] is classified as 2
对我们来说,正确的答案应该是:
[5.4, 3.7, 1.5, 0.2] is 0
[4.8, 3.4, 1.6, 0.2] is 0
[7.6, 3.0, 6.6, 2.1] is 2
[6.4, 2.8, 5.6, 2.2] is 2
[6.0, 2.7, 5.1, 1.6] is 1
[5.4, 3.0, 4.5, 1.5] is 1
[6.7, 3.1, 4.7, 1.5] is 1
[5.5, 2.4, 3.8, 1.1] is 1
[6.1, 2.8, 4.7, 1.2] is 1
[4.3, 3.0, 1.1, 0.1] is 0
[5.8, 2.7, 3.9, 1.2] is 1
在比较结果时,我们只有11个数据点中的5个由于初始样本训练数据的大小而正确分类。另一方面,由于我们没有从完全随机集群开始,我们的预测也并非完全错误。
让我们看看,当我们向模型提供更多的训练数据时,情况会发生什么变化:
$ psql -h localhost -U postgres -f postgres/iris_train2.sql
为了看到更新的预测,我们将相同的测试数据样本再次插入数据库:
$ psql -h localhost -U postgres -f postgres/iris_test.sql
下面的预测是更好的,因为我们有所有三个类别。我们还正确地将11个数据点中的7个分类。
[5.4, 3.7, 1.5, 0.2] is classified as 0
[4.8, 3.4, 1.6, 0.2] is classified as 0
[7.6, 3.0, 6.6, 2.1] is classified as 2
[6.4, 2.8, 5.6, 2.2] is classified as 2
[6.0, 2.7, 5.1, 1.6] is classified as 2
[5.4, 3.0, 4.5, 1.5] is classified as 2
[6.7, 3.1, 4.7, 1.5] is classified as 2
[5.5, 2.4, 3.8, 1.1] is classified as 1
[6.1, 2.8, 4.7, 1.2] is classified as 2
[4.3, 3.0, 1.1, 0.1] is classified as 0
[5.8, 2.7, 3.9, 1.2] is classified as 1
由于整个数据样本很小,为了进一步的模型训练,我们可以重新使用第二列数据样本:
$ psql -h localhost -U postgres -f postgres/iris_train2.sql
$ psql -h localhost -U postgres -f postgres/iris_test.sql
这将导致下列预测。
[5.4, 3.7, 1.5, 0.2] is classified as 0
[4.8, 3.4, 1.6, 0.2] is classified as 0
[7.6, 3.0, 6.6, 2.1] is classified as 2
[6.4, 2.8, 5.6, 2.2] is classified as 2
[6.0, 2.7, 5.1, 1.6] is classified as 2
[5.4, 3.0, 4.5, 1.5] is classified as 1
[6.7, 3.1, 4.7, 1.5] is classified as 2
[5.5, 2.4, 3.8, 1.1] is classified as 1
[6.1, 2.8, 4.7, 1.2] is classified as 1
[4.3, 3.0, 1.1, 0.1] is classified as 0
[5.8, 2.7, 3.9, 1.2] is classified as 1
我们现在发现11个数据点中有9个是正确分类的。虽然这仍然不是一个很好的结果,我们只期望部分准确的结果,因为这只是一个预测。这里的主要动机是展示整个管道,并证明该模型在添加新数据时无需重新训练和重新部署该模型,即可改进预测。
与阿帕奇火花分类
从用户的角度来看,阿帕奇火花公司非常类似于FLINK,实现也非常类似。本章更简短,使这篇博文更容易理解。
火花有两种流线型:老的 驱动器 ,目前仍处于传统状态,以及最近的建议 结构性流 .然而,由于SARSHML库中所包含的流式K-均值算法仅用于D流,为了简单起见,本示例中使用了D流。一个更好的方法是使用结构化的流媒体,并实现流媒体的k意味着我们自己。然而,这超出了这篇博文的范围和主要目标。
火花支持流来自卡夫卡使用d流。然而,将DLULHUK写回卡夫卡并没有得到支持,尽管它是可能的,但并不是简单的。
结构化流支持双向,读和写卡夫卡,非常容易。
再次,为了简单起见,我们跳过了最后的部分,只将预测写到控制台,而不是写到卡夫卡。我们管道的总体情况如下:
图片来自官网原文
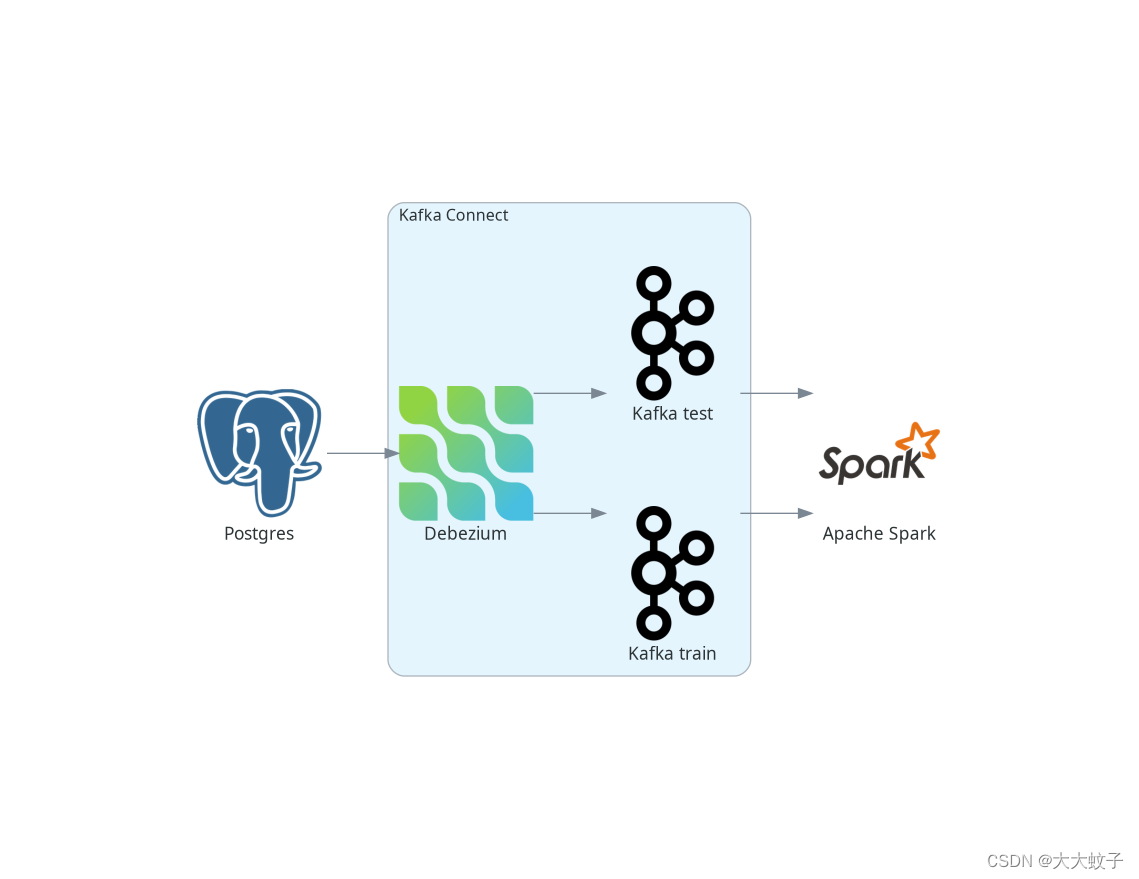
后推以激发架构
定义数据流
同样,从卡夫卡流中创建火花流也很简单,大多数参数都是不言而喻的:
Set trainTopic = new HashSet<>(Arrays.asList(“spark.public.iris_train”));
Set testTopic = new HashSet<>(Arrays.asList(“spark.public.iris_test”));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, “kafka:9092”);
kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, “dbz”);
kafkaParams.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, “earliest”);
kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
JavaInputDStream<ConsumerRecord<String, String>> trainStream = KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(trainTopic, kafkaParams));
JavaDStream train = trainStream.map(ConsumerRecord::value)
.map(SparkKafkaStreamingKmeans::toLabeledPointString)
.map(LabeledPoint::parse);
在最后一行中,我们将卡夫卡流转换为标记的点流,这是星火XML库用于其ML模型的工作。标记点被期望为字符串格式化为数据点标签,用逗号与空间分隔的数据点值分开。所以地图功能是这样的:
private static String toLabeledPointString(String json) throws ParseException {
JSONParser jsonParser = new JSONParser();
JSONObject o = (JSONObject)jsonParser.parse(json);
return String.format("%s, %s %s %s %s",
o.get(“iris_class”),
o.get(“sepal_length”),
o.get(“sepal_width”),
o.get(“petal_length”),
o.get(“petal_width”));
}
它仍然使用k平均值是一个无监督的算法,不使用数据点标签。不过,把它们传给LabeledPoint 稍后的课程中,我们可以用模型预测来展示它们。
我们将一个映射函数链接起来,以解析字符串并从中创建一个标记数据点。在这种情况下,它是星火的内置功能LabeledPoint .
与弗林克的情况相反,"星火"并不要求卡夫卡主题事先存在,所以在部署模型时,我们不必创建主题。一旦创建了带有测试数据的表并填充了数据,我们就可以让Debezum创建它们。
定义和评价模型
对K-均值流模型的定义非常类似于FLINK:
StreamingKMeans model = new StreamingKMeans()
.setK(3)
.setInitialCenters(initCenters, weights);
model.trainOn(train.map(lp -> lp.getFeatures()));
此外,在这种情况下,我们直接将集群的数目设置为3个,并为集群提供相同的初始中心点。我们也只是通过了训练的数据点,而不是标签。
如前所述,我们可以使用标签显示它们和预测:
JavaPairDStream<Double, Vector> predict = test.mapToPair(lp -> new Tuple2<>(lp.label(), lp.features()));
model.predictOnValues(predict).print(11);
我们用预测将11个流元素打印到结果流上的控制台,因为这是我们测试样本的大小。像FLINK一样,在非常小的数据样本上进行初步训练后的结果会更好。数据元组中的第一个数字是数据点标签,而第二个数字是我们模型所做的相应预测:
spark_1 | (0.0,0)
spark_1 | (0.0,0)
spark_1 | (2.0,2)
spark_1 | (2.0,2)
spark_1 | (1.0,0)
spark_1 | (1.0,0)
spark_1 | (1.0,2)
spark_1 | (1.0,0)
spark_1 | (1.0,0)
spark_1 | (0.0,0)
spark_1 | (1.0,0)
然而,当我们提供更多的培训数据时,预测会更好:
spark_1 | (0.0,0)
spark_1 | (0.0,0)
spark_1 | (2.0,2)
spark_1 | (2.0,2)
spark_1 | (1.0,1)
spark_1 | (1.0,1)
spark_1 | (1.0,2)
spark_1 | (1.0,0)
spark_1 | (1.0,1)
spark_1 | (0.0,0)
spark_1 | (1.0,0)
如果我们再次通过第二个训练数据样本进行训练,我们的模型对整个试验样本作出正确的预测:
spark_1 | (0.0,0)
spark_1 | (0.0,0)
spark_1 | (2.0,2)
spark_1 | (2.0,2)
spark_1 | (1.0,1)
spark_1 | (1.0,1)
spark_1 | (1.0,1)
spark_1 | (1.0,1)
spark_1 | (1.0,1)
spark_1 | (0.0,0)
spark_1 | (1.0,1)
该预测是一个集群中的一些k平均值算法创建,并与我们的数据样本中的标签无关。这意味着。(0.0,1) 不会是个错误的预测。可能发生的情况是,标签0的数据点被分配给了正确的集群,然而,SASS内部将其标记为集群编号1。在评估模型时需要牢记这一点。
因此,类似于FLINK,当我们通过了更多的培训数据而无需重新培训和重新部署模型时,我们得到了更好的结果。在这种情况下,我们得到的结果甚至比弗林克的模型更好。
结论
在这篇博文中,我们继续探索Debezns如何帮助将数据吸收到各种ML框架中。我们已经展示了如何将数据从数据库传递到阿帕奇弗林克和阿帕奇火花实时数据流。在这两种情况下,集成都很容易建立,而且效果很好。我们在一个例子中演示了它,使我们能够使用在线学习算法,即在线k-均值算法,以突出数据流的力量。在线机器学习使我们能够对数据流进行实时预测,并在新的培训数据到来时立即改进或调整模型。模型调整不需要在一个单独的计算集群上进行任何模型重新训练,也不需要重新部署一个新的模型,这使得ml-osps更加简单,更具成本效益。
像往常一样,我们将非常感谢这篇博文的反馈。你有没有想过在这个领域如何改变数据捕获的方法?什么将有助于调查,是否集成到另一个ML框架,集成到特定的ML特性存储等。?如果你对此有任何意见,请立即联系我们。 郁金香聊天 , 邮寄清单 或者你可以直接把你的想法变成 吉拉功能请求 .
这篇关于Debezium发布历史163的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









