本文主要是介绍Linux调试器-gdb使用与冯诺依曼体系结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
Linux调试器-gdb使用
1. 背景
2. 开始使用
冯诺依曼体系结构
总结
前言
世上有两种耀眼的光芒,一种是正在升起的太阳,一种是正在努力学习编程的你!一个爱学编程的人。各位看官,我衷心的希望这篇博客能对你们有所帮助,同时也希望各位看官能对我的文章给与点评,希望我们能够携手共同促进进步,在编程的道路上越走越远!
提示:以下是本篇文章正文内容,下面案例可供参考
Linux调试器-gdb使用
1. 背景
- 程序的发布方式有两种,debug模式和release模式
- Linux gcc/g++出来的二进制程序,默认是release模式
- 要使用gdb调试,必须在源代码生成二进制程序的时候, 加上-g选项
debug版本可调试,那是因为编译器形成可执行程序的时候,会给可执行程序添加添加调试信息;而release版本不能调试。


2. 开始使用
gdb binFile(文件) 退出:ctrl + d 或 quit
调试命令:
- list/l (list简写) + 行号:显示binFile源代码,接着上次的位置往下列,每次显示10行(一般是从这一行的上下文的代码开始显示);如果向继续显示下面的代码,可以按回车,每次显示10行。
- list / l + 函数名 : 行号:默认从函数名的第几行号开始,默认显示10行。
- list / l + 文件名 : 行号:默认从文件的第几行开始,默认显示10行。
- r或run:(或重新)运行程序。(相当于F5,要和断点一块使用)
- break(b) + (文件名) + 行号:在(文件的)某一行设置断点。
- break + (文件名) :函数名:在某个函数开头设置断点。
- info / (简写i) break(简写b) :查看打的断点的信息。
- delete / (d) breakpoints n(序号为n的断点):删除序号为n的断点。
- disable breakpoints(n:序号为n的断点):禁用断点。(序号为n的断点不想用,但是又不想删除掉)
- enable breakpoints(n:序号为n的断点):启用断点。
- n 或 next:单条执行。(逐过程)
- s或step:进入函数调用。(逐语句)
- p(print) + 变量名/取地址变量名:打印变量值。(可以在查看循环中的值)
- display + 变量名/取地址变量名:跟踪查看一个变量,每次停下来都显示它的值。(常显示)
- undisplay + 变量前面的编号:取消对先前设置的那些变量的跟踪。
- 断点的本质:是帮我们缩小出问题的范围。
- continue(或c):从当前位置开始连续而非单步执行程序。(从当前断点直接执行到下一个断点处。)
- finish:执行到当前函数返回(也就是结束),然后挺下来等待命令。
- until + X行号:跳转至指定行,中间的代码都是运行了的。比如:在循环的函数里面。
- set var + 变量=你想要改成的值:修改变量的值。
- delete breakpoints:删除所有断点。
- info(i) locals:查看当前栈帧局部变量的值。
- quit:退出gdb。
- breaktrace(或bt):查看各级函数调用及参数。
冯诺依曼体系结构
我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。
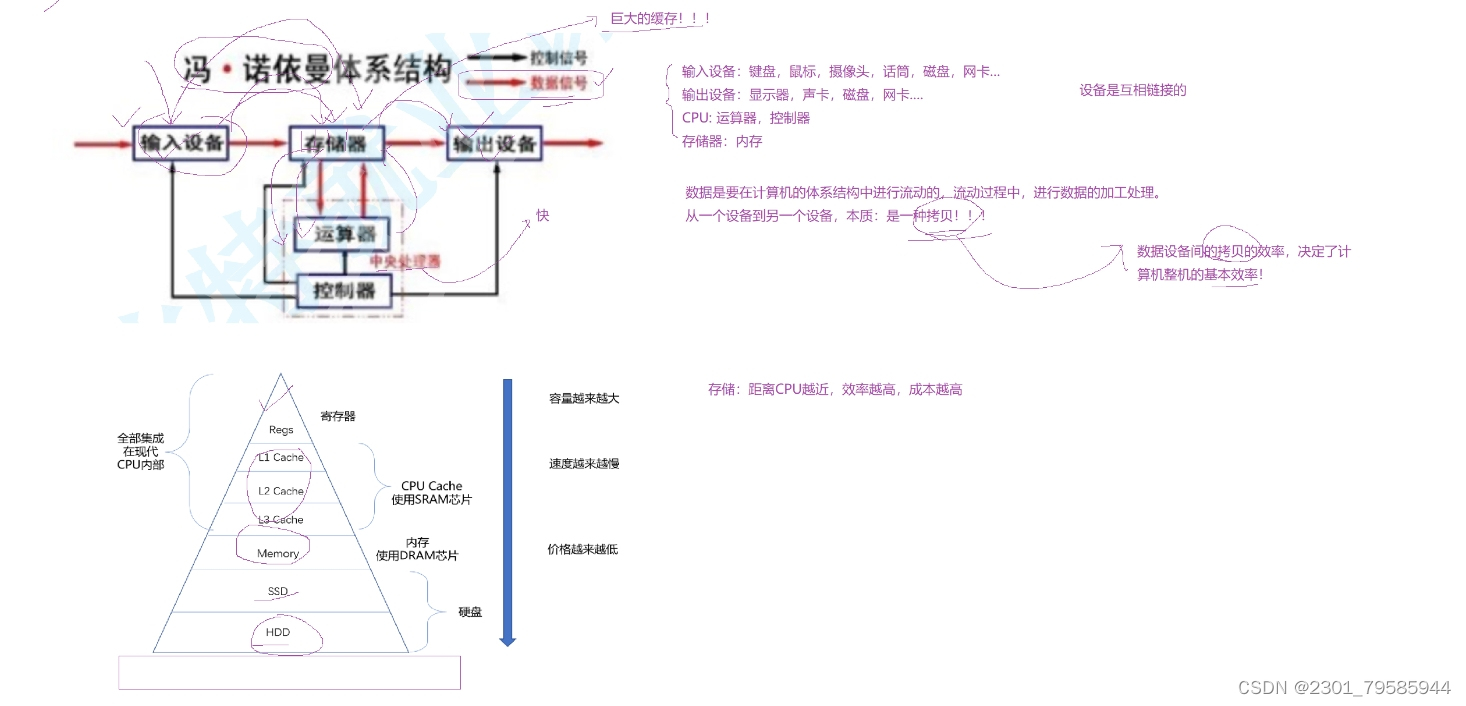
截至目前,我们所认识的计算机,都是有一个个的硬件组件组成
- 输入单元:包括键盘, 鼠标,扫描仪, 写板等
- 中央处理器(CPU):含有运算器和控制器等
- 输出单元:显示器,打印机等
关于冯诺依曼,必须强调几点:
- 这里的存储器指的是内存
- 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备)
- 外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。
- 一句话,所有设备都只能直接和内存打交道。
为什么要加储存器呢?
假如我们的输入设备和输出设备直接和CPU连接起来,会怎么样呢?数据从一个设备流到另一个设备,本质是拷贝过去的,而输入设备和输出设备的效率是非常低的,CPU的拷贝效率是非常高的,两者之间的效率差是非常大的。(想一想木桶效应,木桶存储水的多少,取决于最低的竹板,两者是一样的道理)
这时候加上存储器的话,让输入设备给存储器拷贝数据,存储器给CPU拷贝数据,CPU对数据紧进行处理后,返回给存储器,然后存储器将数据拷贝到输出设备上。以前CPU是直接在外设上拷贝数据,现在变成了CPU直接从存储器上拷贝数据(这两的拷贝效率会更快),而外设的拷贝只用作用到存储器就可以了。而存储器一次性可以存储大量的数据,大大提高了运行的效率。存储器比寄存器的内存容量更大,价格更低,性价比更高,适合广大民众。
结论:
在硬件数据流动角度,在数据层面:
1、CPU不和外设直接打交道,CPU只和内存打交道;
2、外设(输入和输出设备)的数据,不是直接给CPU的,而是要先放入到内存中。
程序运行,为什么要加载到内存?(冯诺依曼体系规定这么做的!!!)
程序=代码+数据:程序的“代码和数据”都要被CPU访问;CPU只会从内存中读取代码和数据
程序还没有加载到内存中的时候,在哪里?
在磁盘(外部设备),当前是二进制文件。
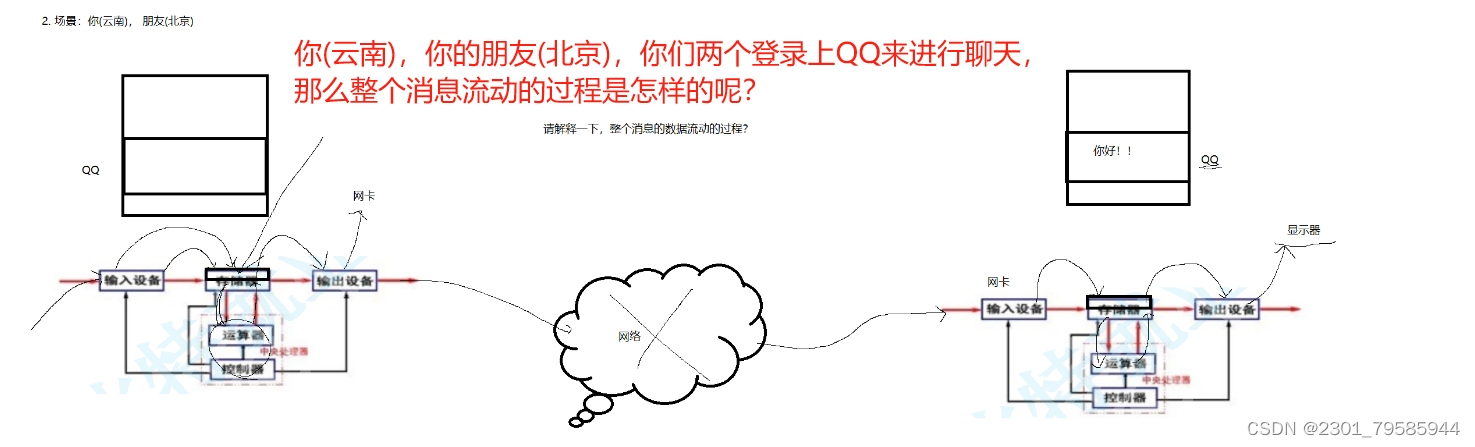
登录上QQ,就代表着QQ的 .exe 的可执行程序被加载到内存当中了。
我们发的信息“你好!”,在输入设备上会直接拷贝到内存中 ------> 存储器将数据拷贝到CPU ----> CPU对数据进行加密运算 -----> 再返回到存储器中 ------> 拷贝到输出设备(网卡) ------> 通过网络传到你朋友的输入设备(网卡) -----> 拷贝到内存的可执行程序中 ------> 拷贝到CPU来进行解密运算 -------> 再拷贝到内存当中 -----> 拷贝到输出设备(显示器)上。
总结
好了,本篇博客到这里就结束了,如果有更好的观点,请及时留言,我会认真观看并学习。
不积硅步,无以至千里;不积小流,无以成江海。
这篇关于Linux调试器-gdb使用与冯诺依曼体系结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







