本文主要是介绍从零开始学习Netty - 学习笔记 -Netty入门【ByteBuf】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
5.2.4.ByteBuf
ByteBuf 是 Netty 框架中用于处理字节数据的一个核心类。它提供了一个灵活而高效的方式来处理字节数据,适用于网络编程和其他需要处理字节数据的场景。
ByteBuf的特点
- 可扩展性: ByteBuf 支持动态扩容,可以根据需要自动增长容量。
- 快速索引: 通过索引可以快速访问数据,而不需要像 ByteBuffer 那样手动调整 position 和 limit。
- 直接内存访问: 可以使用基于直接内存的 ByteBuf,这在某些情况下可以提高性能。
- 支持复合缓冲区: ByteBuf 支持将多个 ByteBuf 组合成一个逻辑上的 ByteBuf,这对于处理复杂的数据结构非常有用。
- 丰富的操作: 提供了许多方便的方法来读写不同类型的数据,如字节、整数、长整数、字符串等。
5.2.4.1.创建
// 默认容量是256
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer();
// 如果不传参数 那么就是默认10 (池化基于直接内存的ByteBuf)
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer(10);
public class ByteBufTest {private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());@Test@DisplayName("测试ByteBuf")public void test1() {// 可以动态扩容的缓冲区,相对于ByteBuffer来说,更加灵活,ByteBuffer如果超过容量那么就会抛出异常// 默认容量是256ByteBuf buf = ByteBufAllocator.DEFAULT.buffer();logger.error("buf = {}", buf);// 模拟数据 此时 写入 400个字节StringBuffer sb = new StringBuffer();for (int i = 0; i < 400; i++) {sb.append(i);}// 向缓冲区写入数据buf.writeBytes(sb.toString().getBytes());// 再次观察ByteBuf容量logger.error("buf = {}", buf);}
}
5.2.4.2.直接内存 VS 堆内存
// 创建池化 基于堆的ByteBuf
ByteBuf buf = ByteBufAllocator.DEFAULT.heapBuffer(10);// 创建基于直接内存的ByteBuf
ByteBuf buf1 = ByteBufAllocator.DEFAULT.directBuffer(10);
- 直接内存 创建和销毁代价昂贵,但是读写性能高,少一次内存复制,适合池化功能一起使用
- 直接内存对GC压力小,因为这部分不受JVM垃圾回收管理,但是也要注意及时主动释放
- netty中默认使用的是直接内存(就是 .buffer())
5.2.4.3.池化 VS 非池化
池化的最大意义可以重复使用ByteBuf
- 减少内存碎片化: 重复使用已分配的内存可以减少内存碎片化,因为不需要频繁地申请和释放小块内存,从而提高了内存利用率。
- 降低内存分配和释放的开销: 内存分配和释放是一项开销较大的操作。通过池化,可以避免频繁地进行这些操作,从而减少了系统的负担。
- 提高性能: 重复使用已分配的 ByteBuf 可以减少系统调用,并且能够更好地利用缓存,从而提高了系统的整体性能。
- 避免内存泄漏: 在某些情况下,由于未正确释放内存,会导致内存泄漏问题。通过使用池化,可以更好地控制和管理内存的生命周期,避免内存泄漏的发生。
- **重用ByteBuf:**有了池化重用ByteBuf实例,并且采用了和 jemalloc类似的内存分配算法提高效率
-Dio.netty.allocator.type = {unpooled | pooled}
# 默认是开启的// 创建池化 基于堆的ByteBuf
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer(10);
// 通过打印class 可以观察是否池化
logger.error("{}", buf.getClass());
// 创建池化 基于堆的ByteBuf
ByteBuf buf2 = ByteBufAllocator.DEFAULT.heapBuffer(10);
// 通过打印class 可以观察是否池化
logger.error("{}", buf2.getClass());

5.2.4.3.组成
ByteBuf有四部分组成 最开始读写指针都在0的位置
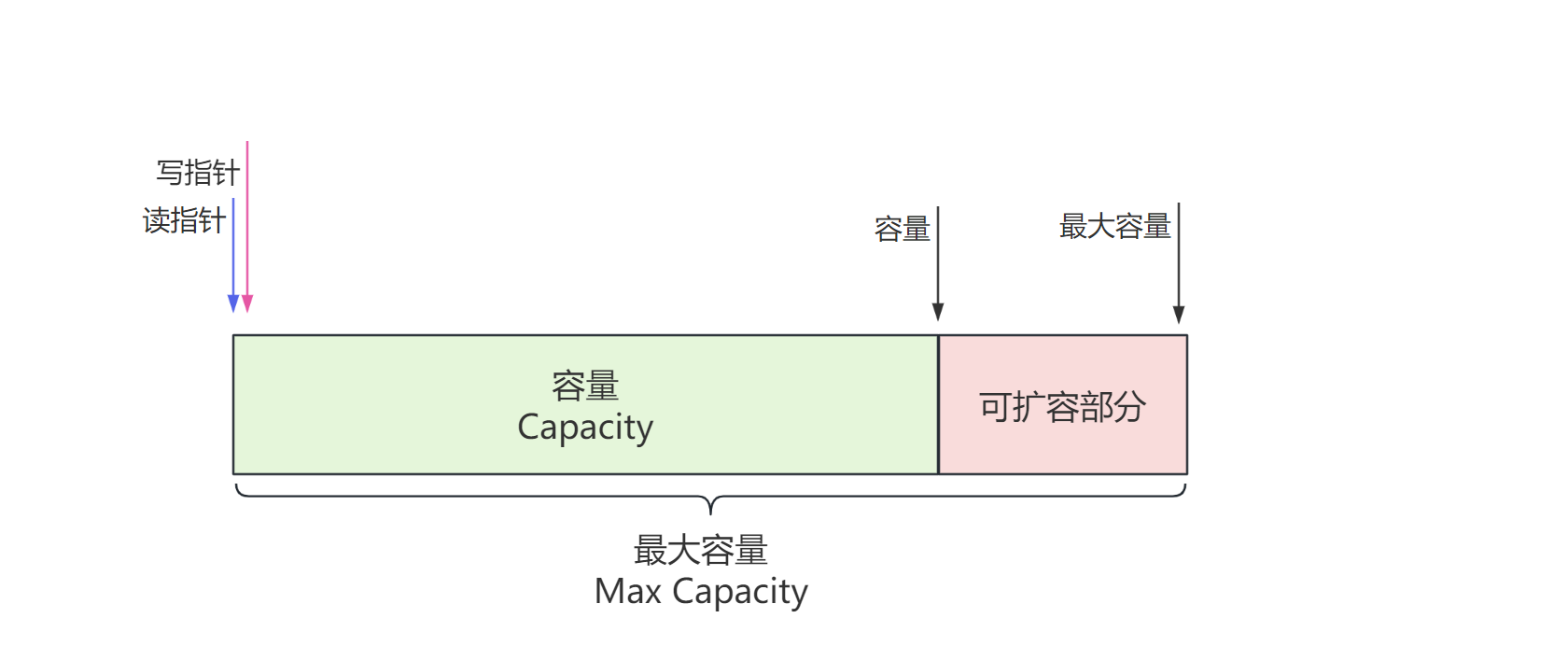
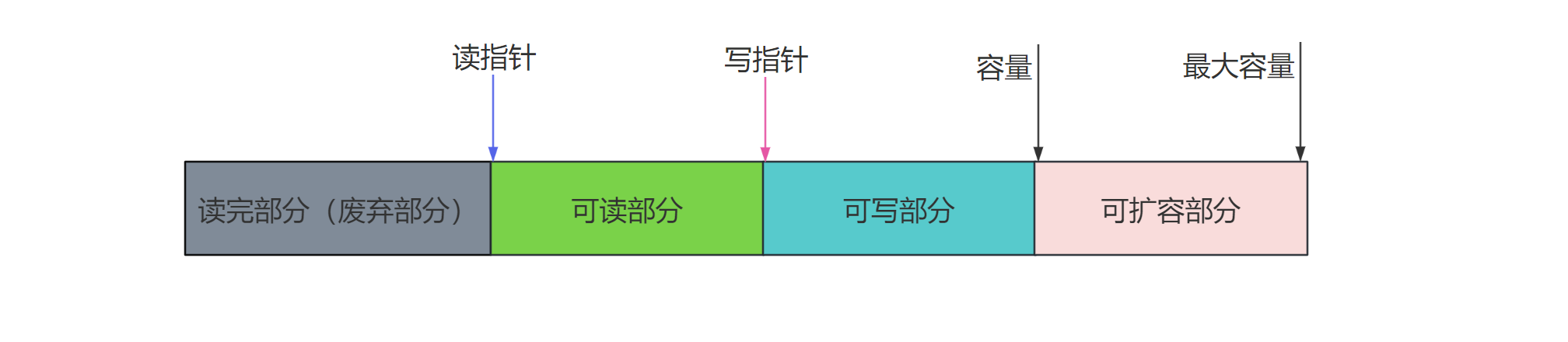
5.2.4.4.写入
下面是常用的ByteBuf写入方法
| 方法 | 描述 |
|---|---|
| writeBoolean(boolean value) | 写入一个布尔值。 01 代表True 00 代表 False |
| writeByte(int value) | 写入一个字节。 |
| writeShort(int value) | 写入一个短整型值(2个字节)。 |
| writeMedium(int value) | 写入一个中等长度的整型值(3个字节)。 |
| writeInt(int value) | 写入一个整型值(4个字节)。 大端写,先写入高位(一般采用大端写) |
| writeLong(long value) | 写入一个长整型值(8个字节)。 |
| writeFloat(float value) | 写入一个单精度浮点数值(4个字节)。 |
| writeDouble(double value) | 写入一个双精度浮点数值(8个字节)。 |
| writeBytes(byte[] src) | 将字节数组的所有字节写入此缓冲区。 |
| writeBytes(ByteBuf src) | 将另一个ByteBuf的所有字节写入此缓冲区。(可以写入Nio中的ByteBuffer) |
| writeBytes(ByteBuf src, int length) | 将另一个ByteBuf的指定长度字节写入此缓冲区。 |
| writeChar(int value) | 写入一个字符值(2个字节)。 |
| writeCharSequence(CharSequence sequence, Charset charset) | 使用指定的字符集编码将字符序列写入缓冲区。(写入的时候需要指定字符集) |
| writeShortLE(int value) | 将一个短整型值(2个字节)以little-endian顺序写入。 |
| writeMediumLE(int value) | 将一个中等长度的整型值(3个字节)以little-endian顺序写入。(小端写,先写低位) |
| writeIntLE(int value) | 将一个整型值(4个字节)以little-endian顺序写入。 |
| writeLongLE(long value) | 将一个长整型值(8个字节)以little-endian顺序写入。 |
| writeCharSequence(CharSequence sequence, Charset charset) | 使用指定的字符集编码将字符序列写入缓 |
测试
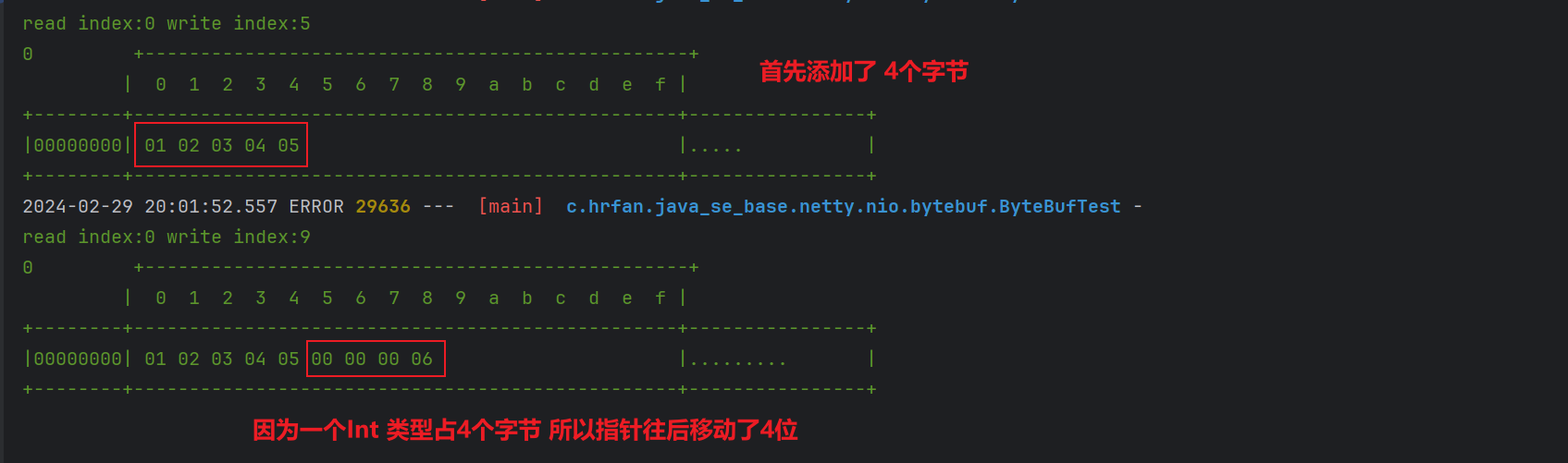
write方法
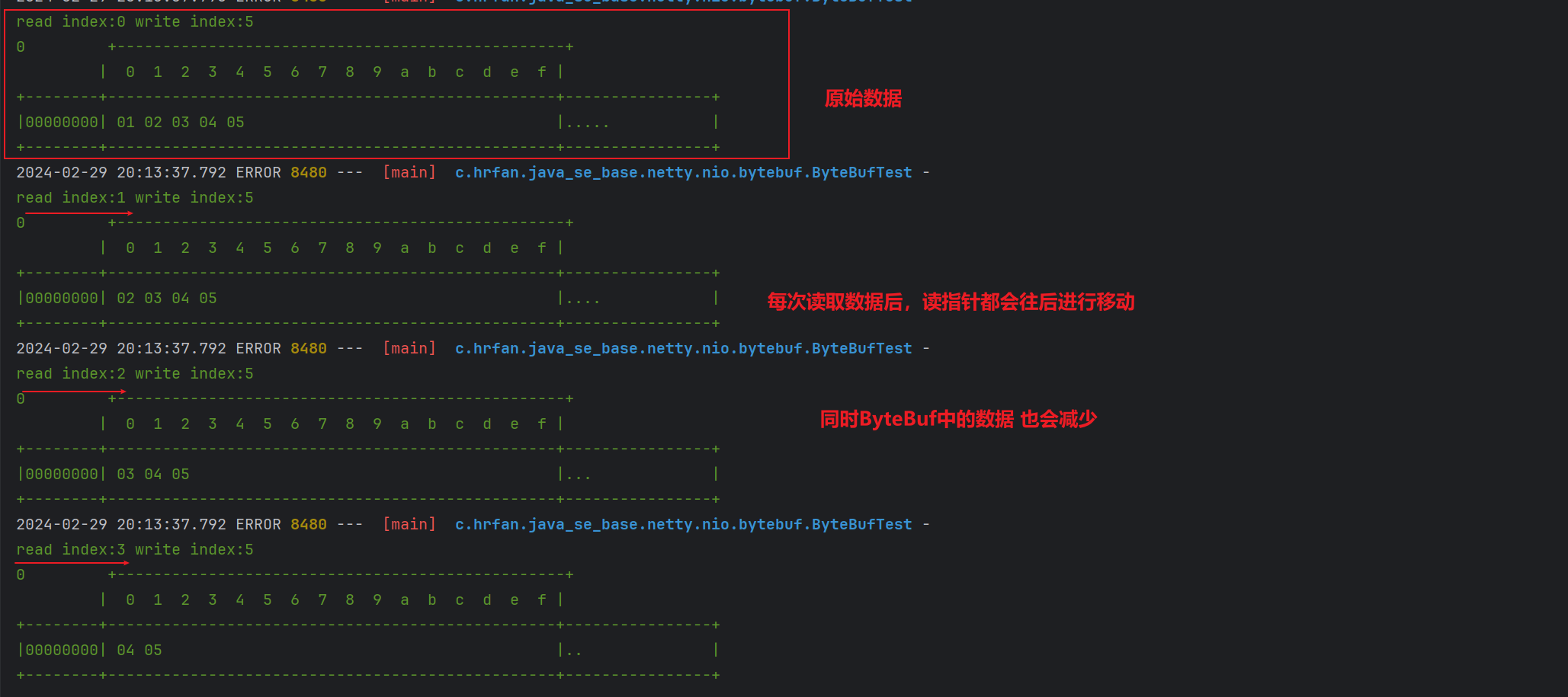
@Testpublic void testWrite() {ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);// 写入数据ByteBuf buf = buffer.writeBytes(new byte[]{1, 2, 3, 4, 5});log(buf);// 再次写入ByteBuf buf1 = buf.writeInt(6);log(buf1);}public void log(ByteBuf buf) {// 可以打印二进制的 工具类 方便查看ByteBufint lengths = buf.readableBytes();int rows = lengths / 16 + (lengths % 15 == 0 ? 0 : 1) + 4;StringBuilder sb = new StringBuilder(rows * 80 * 2);sb.append("read index:").append(buf.readerIndex()).append(" write index:").append(buf.writerIndex()).append("\n").append(NEWLINE);appendPrettyHexDump(sb, buf);logger.error("\n{}", sb.toString());}
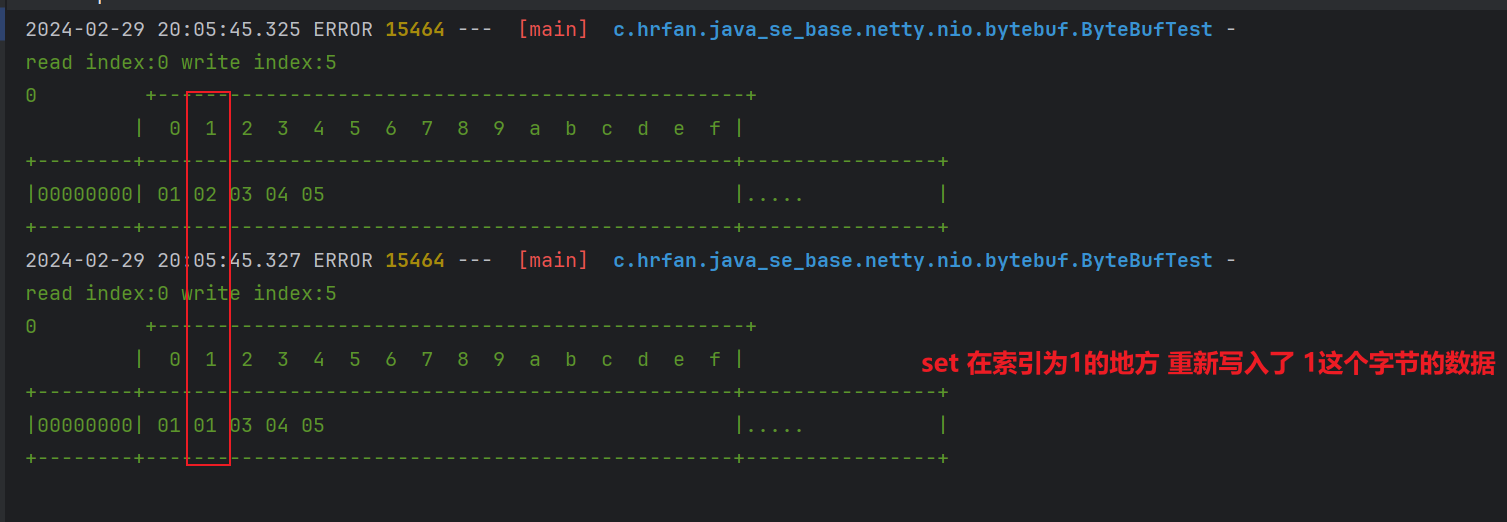
set方法,也可以写入数据 但是不会改变指针的位置
@Testpublic void testWrite2() {ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);// 写入数据ByteBuf buf = buffer.writeBytes(new byte[]{1, 2, 3, 4, 5});log(buf);// 在指定位置写入ByteBuf buf1 = buf.setByte(1, 1);log(buf1);}
5.2.4.5.扩容
ByteBuf 的扩容计算公式通常遵循一个指数级增长的规律,即每次扩容后的容量是前一次的两倍。通常情况下,ByteBuf 的扩容计算公式可以用以下简单的表达式表示:
如果当前容量(capacity)小于 512 字节,则每次扩容的增量为 16 字节。
如果当前容量大于等于 512 字节,但小于 1024 字节,则每次扩容的增量为 64 字节。
如果当前容量大于等于 1024 字节,但小于 2048 字节,则每次扩容的增量为 128 字节。
对于更大的容量,增量的大小也会相应增加,但增长速率仍然保持指数级增长的规律。
ByteBuf 的扩容计算公式可以简化为以下形式:
# 扩容后的容量 = 上一次容量 * 2扩容不能超过最大容量 max capacity 默认最大容量是整数的最大值
5.2.4.6.读取
以下是常用的 ByteBuf 读取数据的方法
| 方法 | 描述 |
|---|---|
| readBoolean() | 从缓冲区读取一个布尔值。 |
| readByte() | 从缓冲区读取一个字节。 |
| readShort() | 从缓冲区读取一个短整数值(2个字节)。 |
| readMedium() | 从缓冲区读取一个中等长度的整数值(3个字节)。 |
| readInt() | 从缓冲区读取一个整数值(4个字节)。 |
| readLong() | 从缓冲区读取一个长整数值(8个字节)。 |
| readFloat() | 从缓冲区读取一个单精度浮点数值(4个字节)。 |
| readDouble() | 从缓冲区读取一个双精度浮点数值(8个字节)。 |
| readBytes(int length) | 从缓冲区读取指定长度的字节数组。 |
| readBytes(byte[] dst) | 从缓冲区读取字节数组,将读取的数据写入给定的目标字节数组。 |
| readBytes(ByteBuf dst) | 从缓冲区读取数据,并将读取的数据写入给定的目标 ByteBuf。 |
| readChar() | 从缓冲区读取一个字符值(2个字节)。 |
| readCharSequence(int length, Charset charset) | 从缓冲区读取指定长度的字符序列,使用指定的字符集解码。 |
| readShortLE() | 以 little-endian 顺序从缓冲区读取一个短整数值(2个字节)。 |
| readMediumLE() | 以 little-endian 顺序从缓冲区读取一个中等长度的整数值(3个字节)。 |
| readIntLE() | 以 little-endian 顺序从缓冲区读取一个整数值(4个字节)。 |
| readLongLE() | 以 little-endian 顺序从缓冲区读取一个长整数值(8个字节)。 |
@Testpublic void read1() {ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);// 写入数据ByteBuf buf = buffer.writeBytes(new byte[]{1, 2, 3, 4, 5});log(buf);// 读取数据// 例如读取一个字节 读取一个字节后,读指针会向后移动一个字节byte s1 = buf.readByte();log(buf);byte s2 = buf.readByte();log(buf);byte s3 = buf.readByte();log(buf);}
5.2.4.7.内存释放
retain & release
涉及到 Netty 中的堆外内存和堆内内存的 ByteBuf 实现时,需要注意以下几点:
- 堆外内存的 ByteBuf 实现:
- 使用操作系统的内存而不是 JVM 堆内存。
- 需要手动释放资源,最好不要依赖 Java 垃圾回收机制。
- 调用
release()方法来释放资源,确保在适当的时候释放内存。
- 堆内内存的 ByteBuf 实现(例如
UnpooledHeapByteBuf):- 使用 JVM 堆内存。
- 内存分配和释放受 Java 垃圾回收器的管理。
- 不需要手动调用
release()方法来释放资源,可以依赖于 Java 垃圾回收器的自动内存管理。
- 直接内存的ByteBuf实现(例如
UnpooledDirectByteBuf)UnpooledDirectByteBuf是 Netty 提供的另一种 ByteBuf 实现,它使用的是堆外内存,即直接内存,而不是 JVM 堆内存。- 直接内存分配在堆外,可以通过系统调用直接与物理内存交互,因此避免了数据在堆内存和直接内存之间的复制开销,提高了 I/O 操作的效率。
- 与
UnpooledHeapByteBuf不同,UnpooledDirectByteBuf的内存分配和释放不受 Java 垃圾回收器的管理,因此需要手动调用release()方法来释放资源。 UnpooledDirectByteBuf适用于需要处理大量数据或者对内存使用有严格要求的场景,可以有效地提高系统的性能和吞吐量。
- 池化机制(例如
PooledByteBuf和他的子类使用了池化机制)PooledByteBuf及其子类是 Netty 中使用池化机制的实现。- 它们继承自
ByteBuf,提供了一种基于池化技术的内存分配和管理方式。 - 当需要创建新的 ByteBuf 实例时,
PooledByteBufAllocator会从预先分配的池中获取已分配的 ByteBuf 实例,而不是每次都进行新的内存分配。 - 当 ByteBuf 实例不再被使用时,它们会被归还给池,而不是被立即释放,以便重复利用。
- 释放堆外内存的建议:
- 在处理堆外内存的 ByteBuf 时,及时调用
release()方法是非常重要的。 - 如果不及时释放资源,可能会导致内存泄漏或者系统内存耗尽的问题。
- 在处理堆外内存的 ByteBuf 时,及时调用
- 注意事项:
- 要注意在使用完毕后调用
release()方法释放资源。 - 对于堆外内存的 ByteBuf,要注意避免资源泄漏,及时释放资源是必要的。
- 对于堆内内存的 ByteBuf,则可以依赖 Java 垃圾回收器的自动管理,不需要手动释放资源。
- 要注意在使用完毕后调用
Netty 中的引用计数(Reference Counting)机制是一种用于管理资源的技术,它主要用于管理 ByteBuf 和其他对象的生命周期,确保资源在合适的时候释放,以避免内存泄漏和错误的引用。(原理如下)
- 初始引用计数为 1: 当创建一个新的对象(如 ByteBuf)时,它的引用计数会初始化为 1。
- retain() 方法增加引用计数: 每当有一个新的引用指向该对象时,可以调用对象的
retain()方法来增加引用计数。这样,对象的引用计数就会增加,表示有多个引用指向了该对象。 - release() 方法减少引用计数: 当不再需要该对象时,可以调用对象的
release()方法来减少引用计数。每次调用release()方法,引用计数会减一。当引用计数减少到 0 时,表示没有任何引用指向该对象,可以释放该对象的资源了。 - 释放资源: 当对象的引用计数减少到 0 时,表示没有任何引用指向该对象,可以安全地释放该对象的资源,例如释放 ByteBuf 的内存资源。
在 Netty 中,Pipeline 中的数据处理遵循一定的规则。这些规则有助于确保数据在 Pipeline 中的正确处理和传递。以下是一些常见的规则:
-
顺序处理: 数据在 Pipeline 中按照添加 ChannelHandler 的顺序依次处理。即数据从头部(入站)或尾部(出站)进入 Pipeline,然后依次经过每个 ChannelHandler 处理。
-
入站和出站分离: Pipeline 中的 ChannelHandler 可以处理入站数据、出站数据,或同时处理两者。入站数据指的是从远程端到本地端的数据流,而出站数据则相反。
-
适配器模式: Netty 中的 ChannelHandler 通常采用适配器模式实现,这意味着你只需要实现你感兴趣的方法,而不需要实现所有的方法。例如,
ChannelInboundHandlerAdapter和ChannelOutboundHandlerAdapter提供了默认的方法实现,你只需要覆盖你关心的方法即可。 -
数据流向: 在 Pipeline 中,数据的流向可以是双向的,也可以是单向的。双向的数据流向允许数据在入站和出站之间相互传递,而单向的数据流向只允许数据在一个方向上传递。
-
最后处理者负责: Pipeline 中的最后一个 ChannelHandler 负责处理最终的数据。这意味着在 Pipeline 中,最后一个 ChannelHandler 是最后的处理者,负责生成最终的响应或执行最终的操作。
例如:因为pipeline的存在,一般需要将ByteBuf传递给下一个ChannelHandler,如果再finally中release了,那么就失去了传递性,如果当前ChannelHandler的ByteBuf已经完成了使命,那么就不需要传递了
基本规则是:谁最后使用,谁负责release
-
异常处理: Pipeline 中的异常处理也遵循一定的规则,异常会被传递给 Pipeline 中的下一个异常处理器,直到被处理或者传递到 ChannelPipeline 的末端。
这些规则帮助开发者更好地理解和管理 Pipeline 中的数据处理流程,确保数据能够正确地在 Pipeline 中流动和被处理。
5.2.4.8.零拷贝
slice
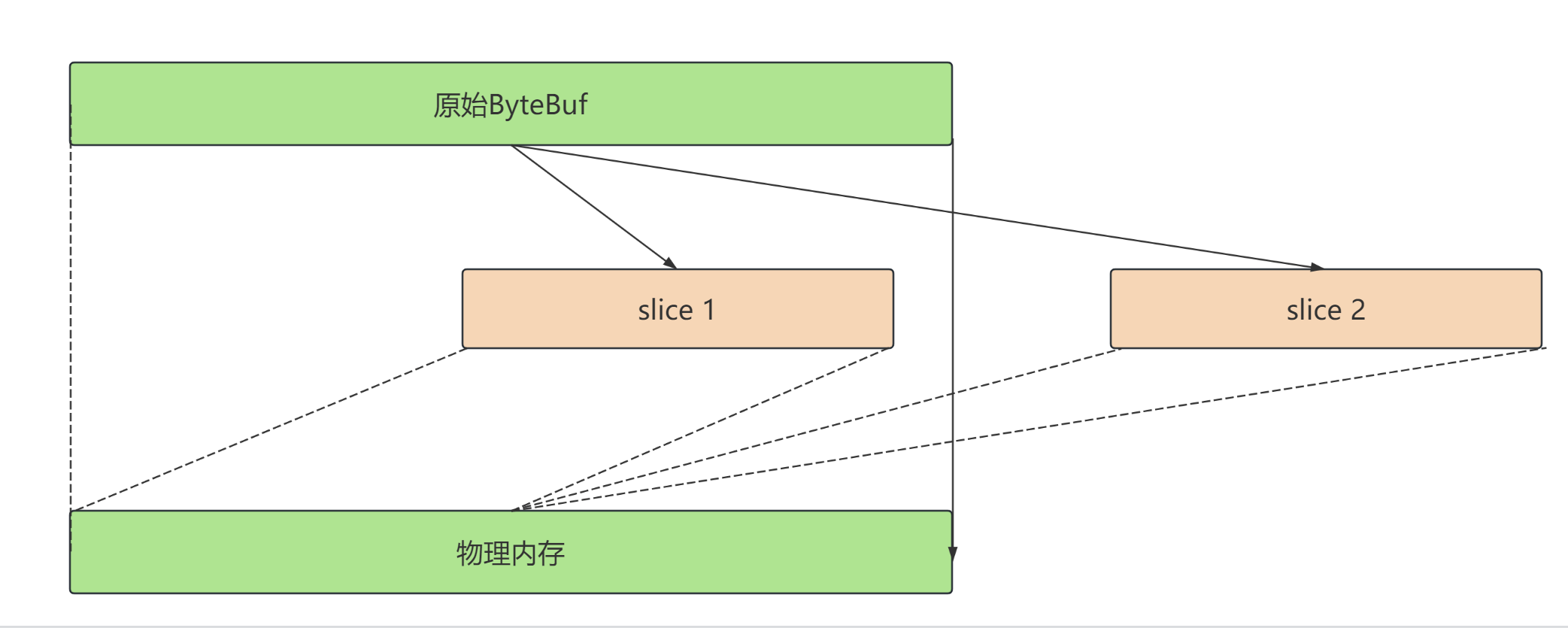
零拷贝的体现之一,对原始ByteBuf进行切片成多个ByteBuf,切片后的ByteBuf并没发生内存复制,还是要使用原始的ByteBuf的内存,切片后的ByteBuf维护独立的read,write指针
slice() 方法是 Netty 中 ByteBuf 类提供的一个功能强大的方法,它允许你创建一个新的 ByteBuf 实例,该实例与原始的 ByteBuf 共享数据,但是具有自己的读写指针。这意味着你可以在不复制数据的情况下,使用相同的数据块来创建一个新的 ByteBuf 实例,从而节省内存和提高性能。
以下是关于 slice() 方法的详细说明:
- 创建新的 ByteBuf 实例: 调用
slice()方法将会创建一个新的ByteBuf实例,这个新实例与原始的ByteBuf共享相同的数据数组。 - 共享数据: 切片(sliced)的
ByteBuf与原始的ByteBuf共享相同的数据,这意味着它们指向相同的内存区域。 - 独立的读写指针: 尽管切片
ByteBuf与原始的ByteBuf共享相同的数据,但它们具有独立的读写指针。这意味着对切片ByteBuf的读写操作不会影响原始ByteBuf的读写指针位置,反之亦然。 - 修改数据的影响: 如果你修改了切片
ByteBuf中的数据,那么对应位置的数据也会在原始的ByteBuf中被修改,因为它们共享相同的数据数组。 - 切片范围: 可以通过传递参数来定义切片的范围。如果没有指定参数,切片将从原始
ByteBuf的读指针位置到其写指针位置。
使用 slice() 方法,你可以非常高效地操作数据,尤其是在需要处理大数据块时。然而,需要注意的是,对切片 ByteBuf 中的数据的修改可能会影响原始 ByteBuf 中相应位置的数据,因为它们共享相同的数据。
简单使用
@Test
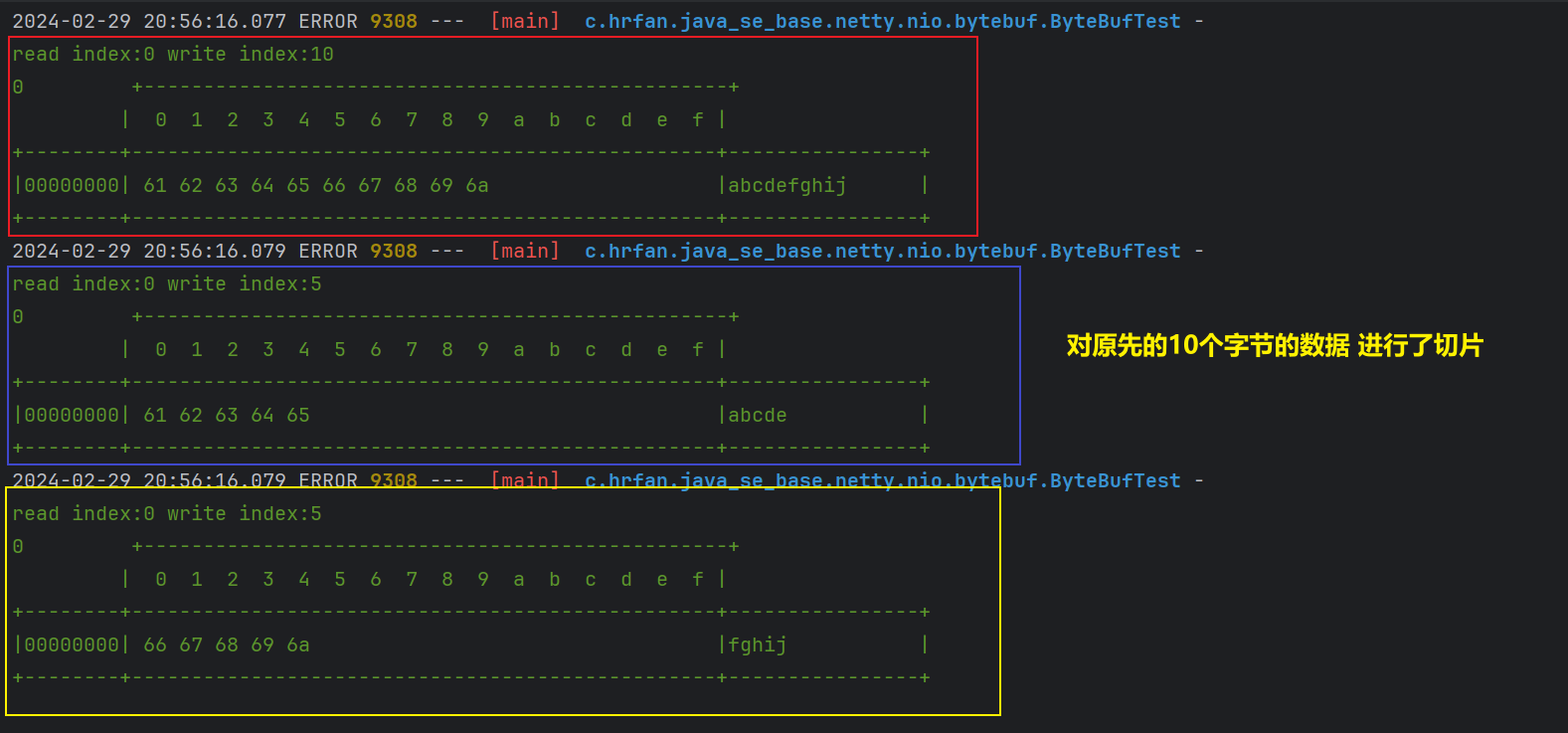
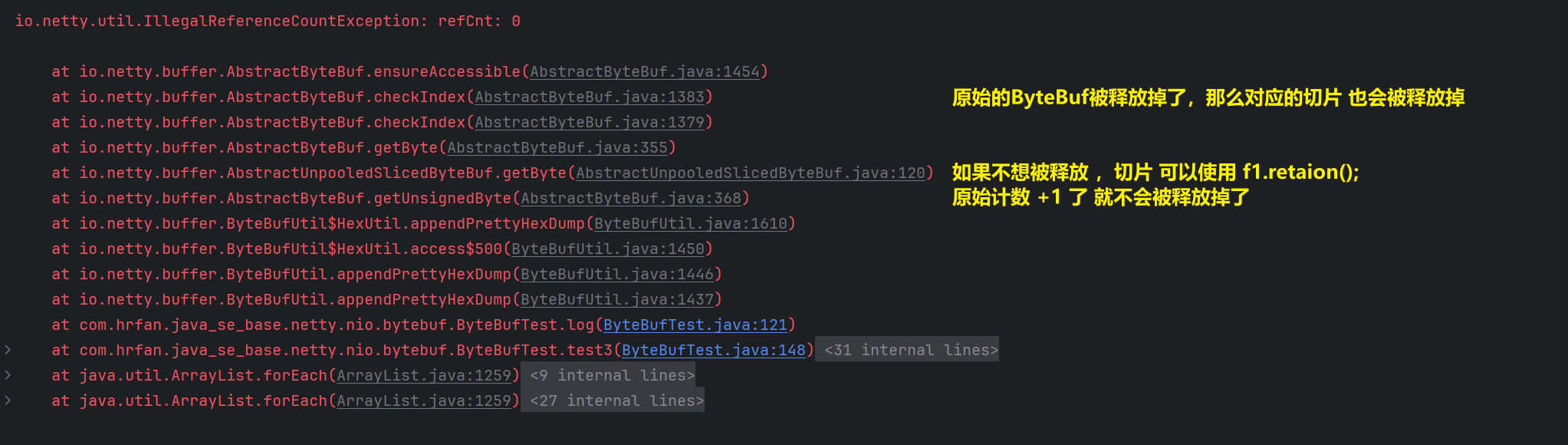
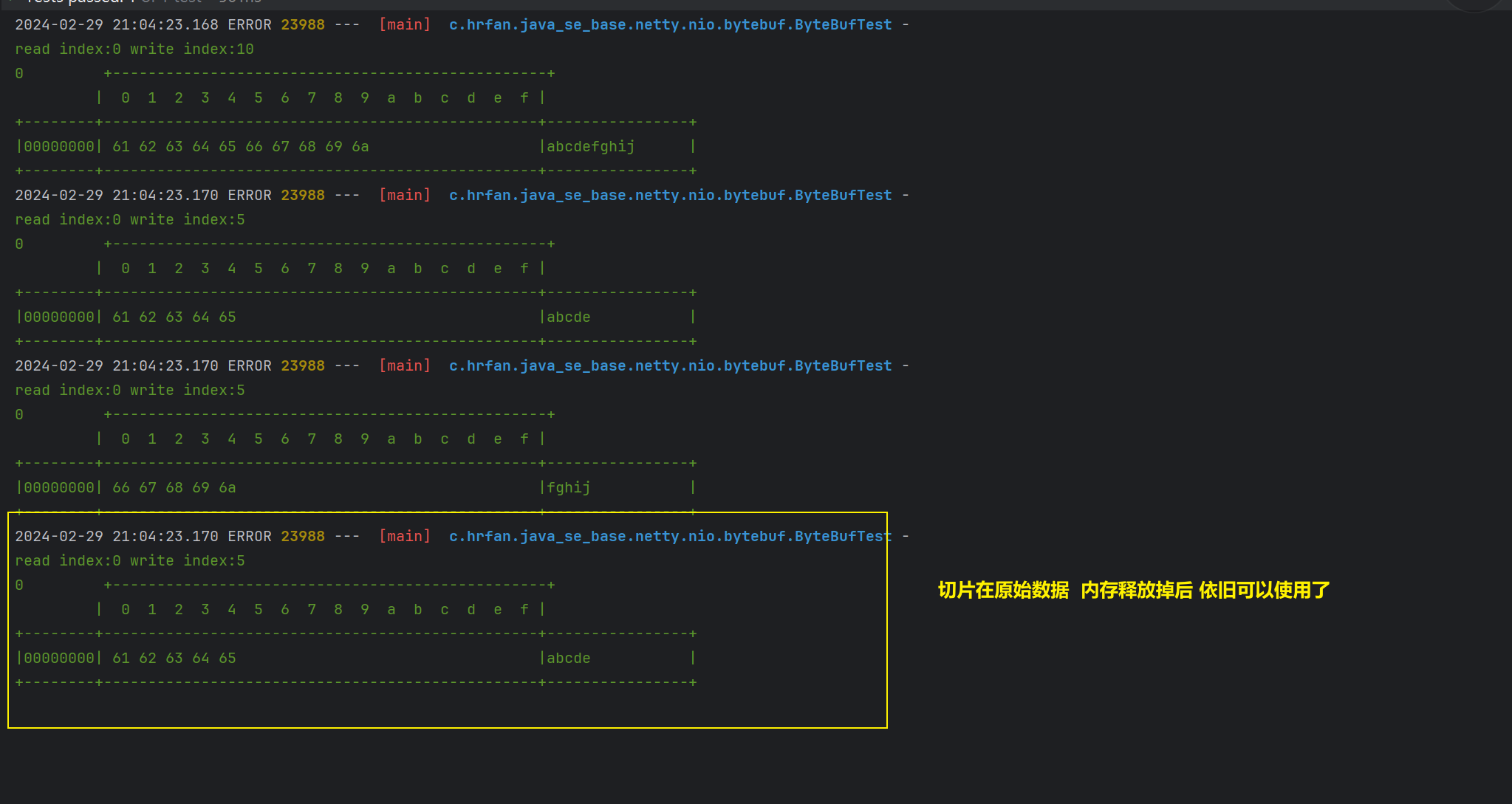
public void test3() {// 创建莫模拟数据ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);buffer.writeBytes(new byte[]{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'});log(buffer);// 对数据进行切片// 在切片的过程中,并没发生数据复制 效率更高ByteBuf f1 = buffer.slice(0, 5);// 新加f1.retain();ByteBuf f2 = buffer.slice(5, 5);log(f1);log(f2);// 释放原有ByteBuf内存buffer.release();// 切片的数据会被释放,原始的数据被释放掉,切片的数据也会被释放掉log(f1);}
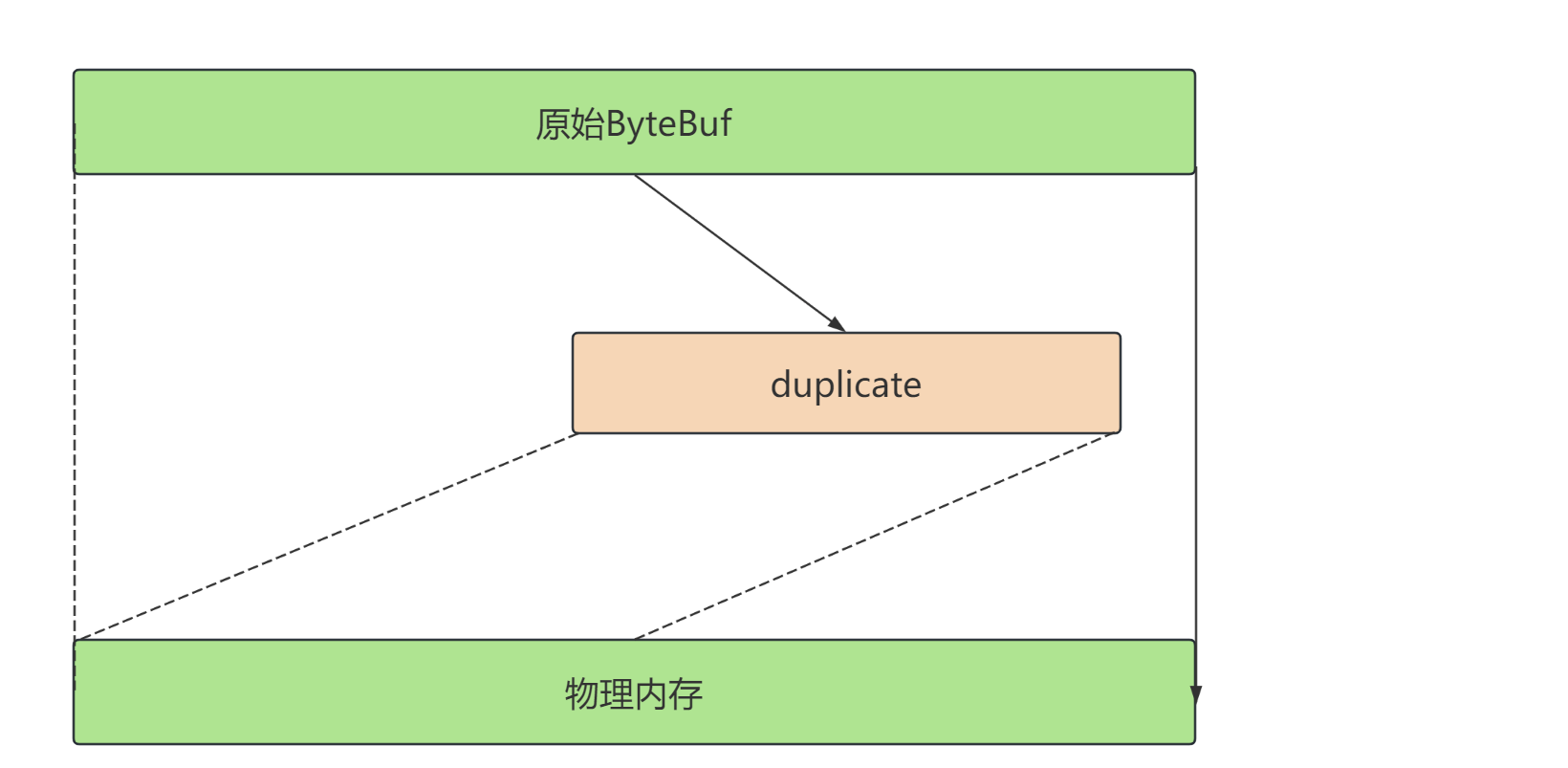
duplicate
duplicate() 方法是 Netty 中 ByteBuf 类提供的一个重要方法,它用于创建一个当前 ByteBuf 的副本。这个副本包含了与原始 ByteBuf 相同的数据,但具有独立的读写指针。换句话说,duplicate() 方法允许你创建一个与原始 ByteBuf 共享数据,但具有自己的读写指针的新 ByteBuf 实例。
以下是关于 duplicate() 方法的一些关键点:
- 创建副本: 调用
duplicate()方法将会创建一个新的ByteBuf实例,这个实例包含了与原始ByteBuf相同的数据。 - 共享数据: 新创建的
ByteBuf实例与原始的ByteBuf共享相同的数据,这意味着它们指向相同的内存区域。 - 独立的读写指针: 尽管副本
ByteBuf与原始的ByteBuf共享相同的数据,但它们具有独立的读写指针。这意味着对副本ByteBuf的读写操作不会影响原始ByteBuf的读写指针位置,反之亦然。 - 修改数据的影响: 如果你修改了副本
ByteBuf中的数据,那么对应位置的数据也会在原始的ByteBuf中被修改,因为它们共享相同的数据数组。 - 创建快照:
duplicate()方法可以用于创建当前ByteBuf的一个快照,允许你在不影响原始ByteBuf的情况下进行读写操作。
使用 duplicate() 方法,你可以非常方便地操作数据,尤其是在需要在不同的位置同时读取相同数据或者处理部分数据时。然而,需要注意的是,对副本 ByteBuf 中的数据的修改可能会影响原始 ByteBuf 中相应位置的数据,因为它们共享相同的数据。因此,在修改副本数据时需要谨慎操作,确保不会产生意外的结果。
copy
copy() 方法是 Netty 中 ByteBuf 类提供的另一个重要方法,它用于创建一个当前 ByteBuf 的完全独立的副本。与 duplicate() 方法不同,copy() 方法创建的副本包含了与原始 ByteBuf 相同的数据,但是数据存储在完全不同的内存区域,而且副本具有独立的读写指针。
以下是关于 copy() 方法的要点:
- 创建完全独立的副本: 调用
copy()方法将会创建一个新的ByteBuf实例,这个实例包含了与原始ByteBuf相同的数据,但是数据存储在完全不同的内存区域。 - 独立的数据存储: 新创建的
ByteBuf实例与原始的ByteBuf完全独立,它们的数据存储在不同的内存区域,相互之间不共享任何数据。 - 独立的读写指针: 新创建的
ByteBuf实例具有独立的读写指针,因此对副本ByteBuf的读写操作不会影响原始ByteBuf的读写指针位置,反之亦然。 - 数据复制操作:
copy()方法会将原始ByteBuf中的数据复制到新创建的副本ByteBuf中,这意味着对副本ByteBuf的任何修改都不会影响原始ByteBuf中的数据。
使用 copy() 方法,你可以创建一个完全独立的副本 ByteBuf,并对副本进行任何修改操作,而不会影响原始 ByteBuf。这对于需要在不同的上下文中独立处理相同数据的情况非常有用。然而,需要注意的是,由于数据的复制操作,copy() 方法可能会产生额外的内存开销,因此在处理大数据量时需要谨慎使用。
5.2.4.9.ByteBuf 的优势包括:
- 灵活性: 提供了丰富的 API,便于数据操作。
- 可扩展性: 支持多种实现,适用于不同的场景需求。
- 内存管理: 提供了灵活的内存管理机制,避免了内存泄漏和频繁的垃圾回收操作。
- 性能优化: 考虑了性能优化,能够在高并发、大数据量的情况下保持较好的性能。
- 附加功能: 提供了许多附加功能,如编解码支持、访问控制、数据合并等,方便数据处理和操做
这篇关于从零开始学习Netty - 学习笔记 -Netty入门【ByteBuf】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









